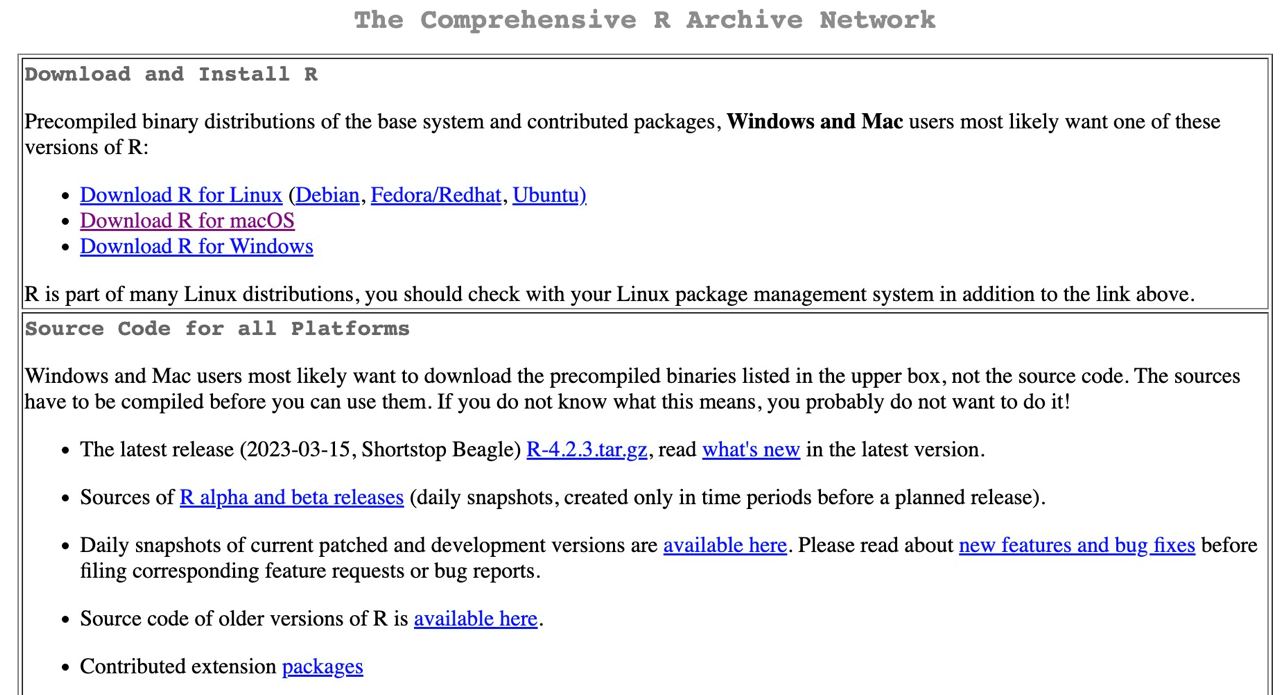
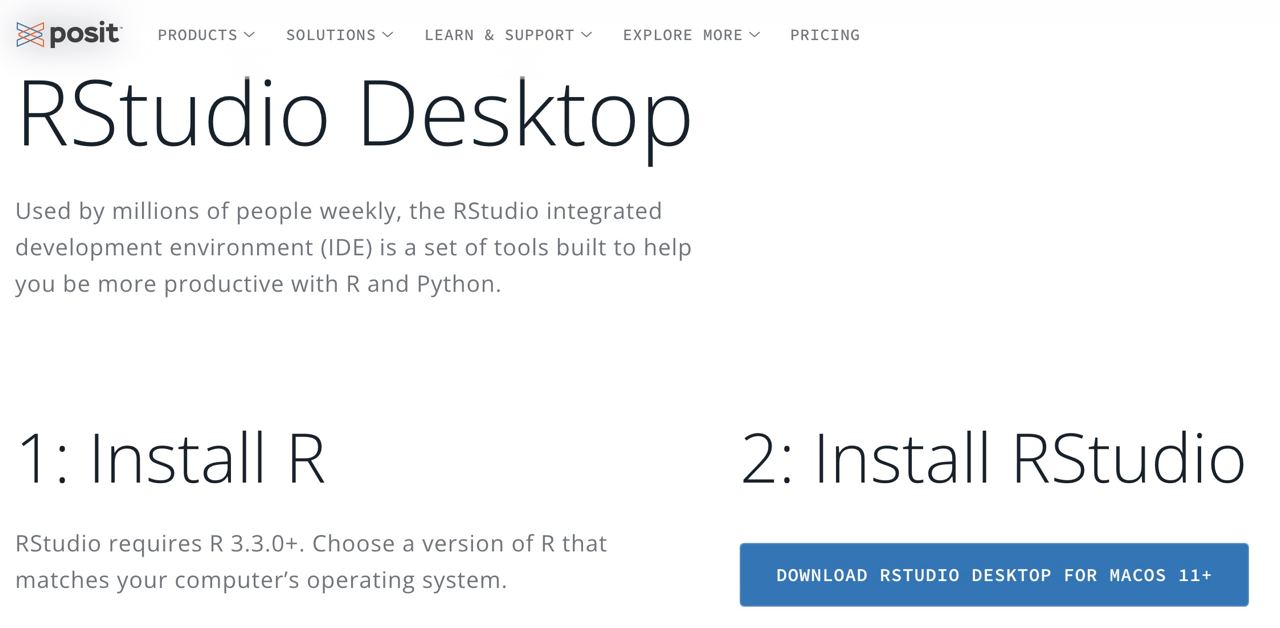
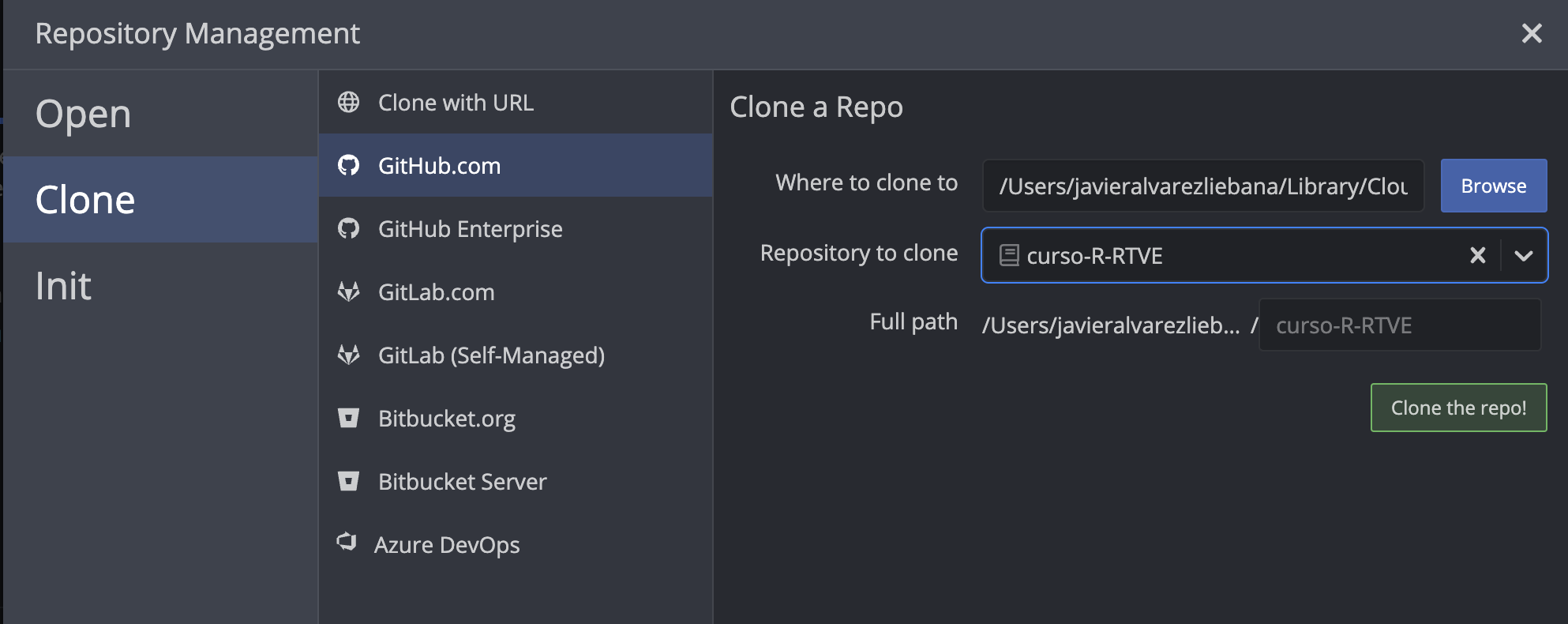
Paso 2: para Mac basta con que hacer click en el archivo .pkg, y abrirlo una vez descargado. Para sistemas Windows, debemos clickar en install R for the first time y después en Download R for Windows. Una vez descargado, abrirlo como cualquier archivo de instalación.
Paso 3: abrir el ejecutable de instalación.
Importante
Siempre que tengas que descargar algo de CRAN (ya sea el propio R o un paquete), asegúrate de tener conexión a internet.
Primera operación
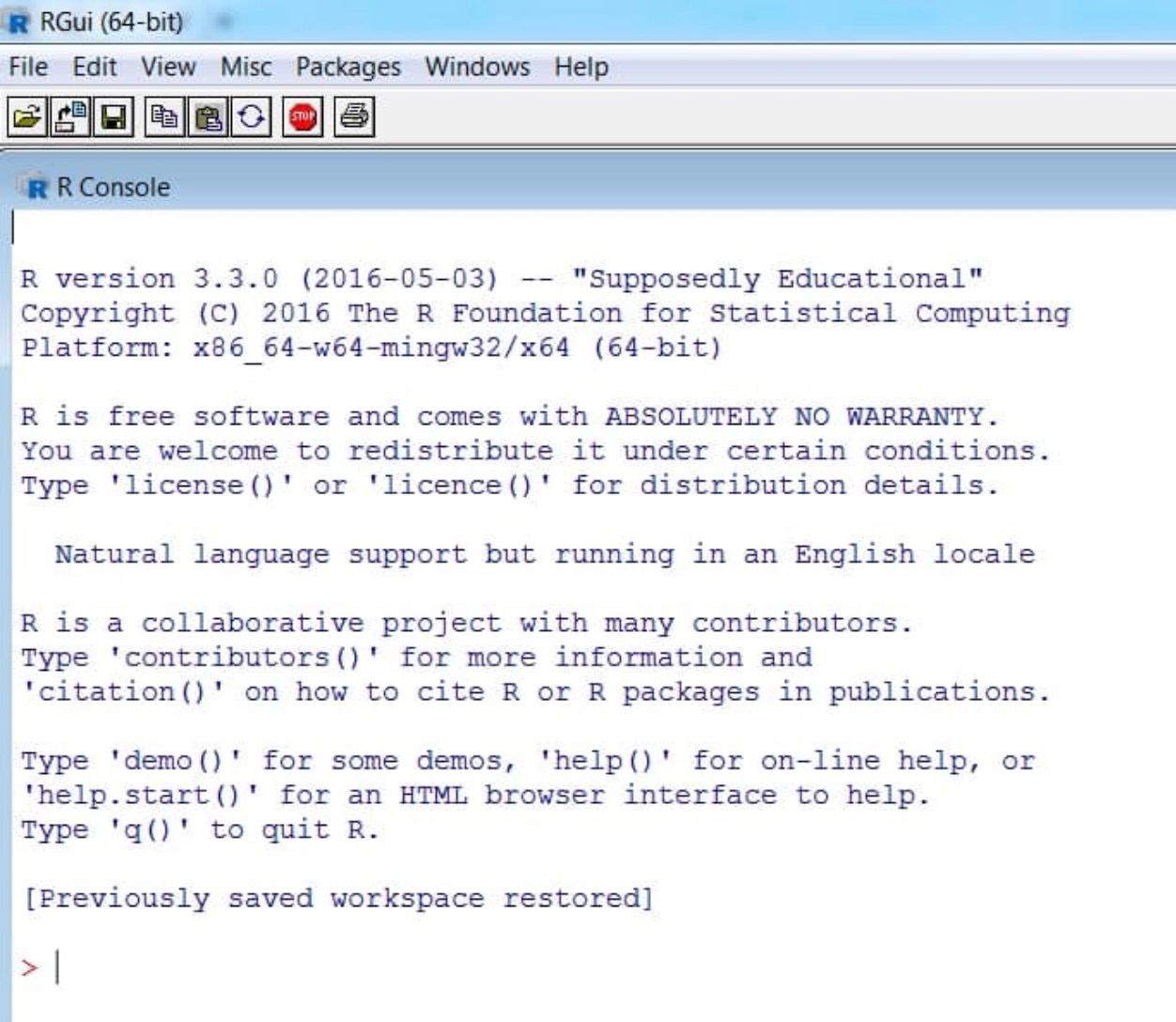
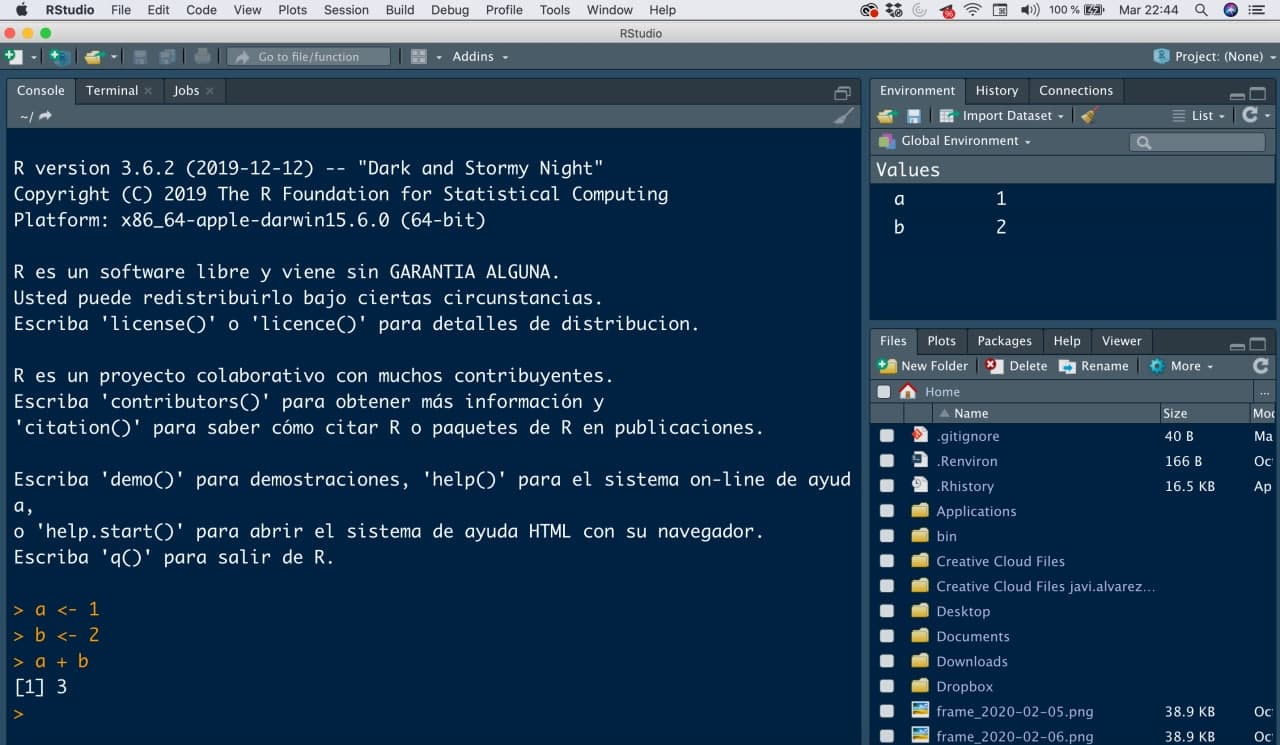
Para comprobar que se ha instalado correctamente, tras abrir R, deberías ver una pantalla blanca similar a esta.
Esa «pantalla blanca» se llama consola y podemos hacer un primer uso de ella como una calculadora.
Idea: a una variable llamada a le asignaremos el valor 1 (escribiremos el código de abajo en la consola y daremos «enter»)
a <-1
Primera operación
Para comprobar que se ha instalado correctamente, tras abrir R, deberías ver una pantalla blanca similar a esta.
Esa «pantalla blanca» se llama consola y podemos hacer un primer uso de ella como una calculadora.
Idea: definiremos otra variable llamada b y le asignaremos el valor 2
a <-1b <-2
Fíjate que…
En R usaremos <- como una flecha: la variable a la izquierda de dicha flecha le asignamos el valor que hay a la derecha (por ejemplo, a <- 1)
Primera operación
Para comprobar que se ha instalado correctamente, tras abrir R, deberías ver una pantalla blanca similar a esta.
Esa «pantalla blanca» se llama consola y podemos hacer un primer uso de ella como una calculadora.
Idea: haremos la suma a + b y nos devolverá su resultado
a <-1b <-2a + b
[1] 3
Instalación de R Studio
RStudio será el Word que usaremos para escribir (lo que se conoce como un IDE: entorno integrado de desarrollo).
Paso 1: entra la web oficial de RStudio (ahora llamado Posit) y selecciona la descarga gratuita.
Paso 2: selecciona el ejecutable que te aparezca acorde a tu sistema operativo.
Paso 3: tras descargar el ejecutable, hay que abrirlo como otro cualquier otro y dejar que termine la instalación.
Organización de RStudio
Al abrir RStudio seguramente tengas tres ventanas:
Consola: es el nombre para llamar a la ventana grande que te ocupa buena parte de tu pantalla. Prueba a escribir el mismo código que antes (la suma de las variables) en ella. La consola será donde ejecutaremos órdenes y mostraremos resultados.
Organización de RStudio
Al abrir RStudio seguramente tengas tres ventanas:
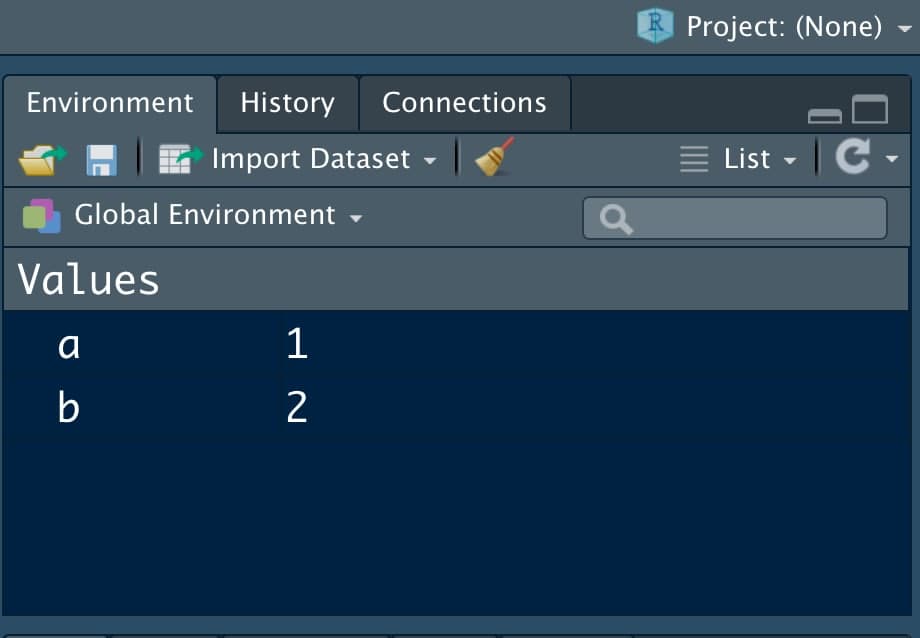
Environment: la pantalla pequeña (puedes ajustar los márgenes con el ratón a tu gusto) que tenemos en la parte superior derecha. Nos mostrará las variables que tenemos definidas.
Organización de RStudio
Al abrir RStudio seguramente tengas tres ventanas:
Panel multiusos: la ventana que tenemos en la parte inferior derecha no servirá para buscar ayuda de funciones, además de para visualizar gráficos.
¿Qué es R? Primeros usos
¿Cuáles son las ventajas? Primer uso
¿Qué es R? ¿Por qué R?
¿Qué es R? ¿Por qué R?
R es el lenguaje estadístico por excelencia, creado por y para estadísticos/as, con 5 ventajas fundamentales frente a Excel:
Lenguaje de programación: la obviedad → análisis replicables
Gratuito: la filosofía de la comunidad de R es el compartir código bajo copyleft→ uso ético de dinero público
Software libre: no solo es gratis sino que permite acceder libremente a código ajeno, incluso al propio código fuente→ flexibilidad y transparencia
Lenguaje modular: hemos instalado lo mínimo, pero existen códigos de otras personas que podemos reusar (casi 20 000 paquetes) → ahorro de tiempo
Lenguaje de alto nivel: facilita la programación (como Python) → menor curva de aprendizaje
¿Qué es R? ¿Por qué R?
¿Por qué programar?
Automatizar → te permitirá automatizar tareas recurrentes (ejemplo: datos covid) de forma que solo tendrás que programarlo uno vez.
Replicabilidad → podrás replicar tu análisis siempre de la misma manera.
Flexibilidad → podrás adaptar el software a tus necesidades.
Transparencia → ser auditado por la comunidad.
Idea fundamental: paquetes
Una de las ideas claves de R es el uso de paquetes: códigos que otras personas han implementado para resolver un problema
Instalación: descargamos los códigos de la web (necesitamos internet) → comprar un libro, solo una vez (por ordenador)
install.packages("ggplot2")
Carga: con el paquete descargado, indicamos qué paquetes queremos usar cada vez que abramos RStudio → traer el libro de la estantería
library(ggplot2)
Idea fundamental: paquetes
Una vez instalado, hay dos manera de usar un paquete (traerlo de la estantería)
Paquete entero: con library(), usando el nombre del paquete sin comillas, cargamos en la sesión todo el libro
library(ggplot2)
Funciones concretas usando paquete::funcion le índicamos que solo queremos una página concreta de ese libro
ggplot2::geom_point()
Te vas equivocar
Durante tu aprendizaje va a ser muy habitual que las cosas no salgan a la primera → te vas equivocar. No solo será importante asumirlo sino que es importante leer los mensajes de error para aprender de ellos.
Mensajes de error: precedidos de «Error in…» y serán aquellos fallos que impidan la ejecución
"a"+1
Error in "a" + 1: non-numeric argument to binary operator
Mensajes de warning: precedidos de «Warning in…» son los (posibles) fallos más delicados ya que son incoherencias que no impiden la ejecución
# Ejecuta la orden pero el resultado es NaN, **Not A Number**, un valor que no existesqrt(-1)
Warning in sqrt(-1): NaNs produced
[1] NaN
Antes de arrancar: scripts
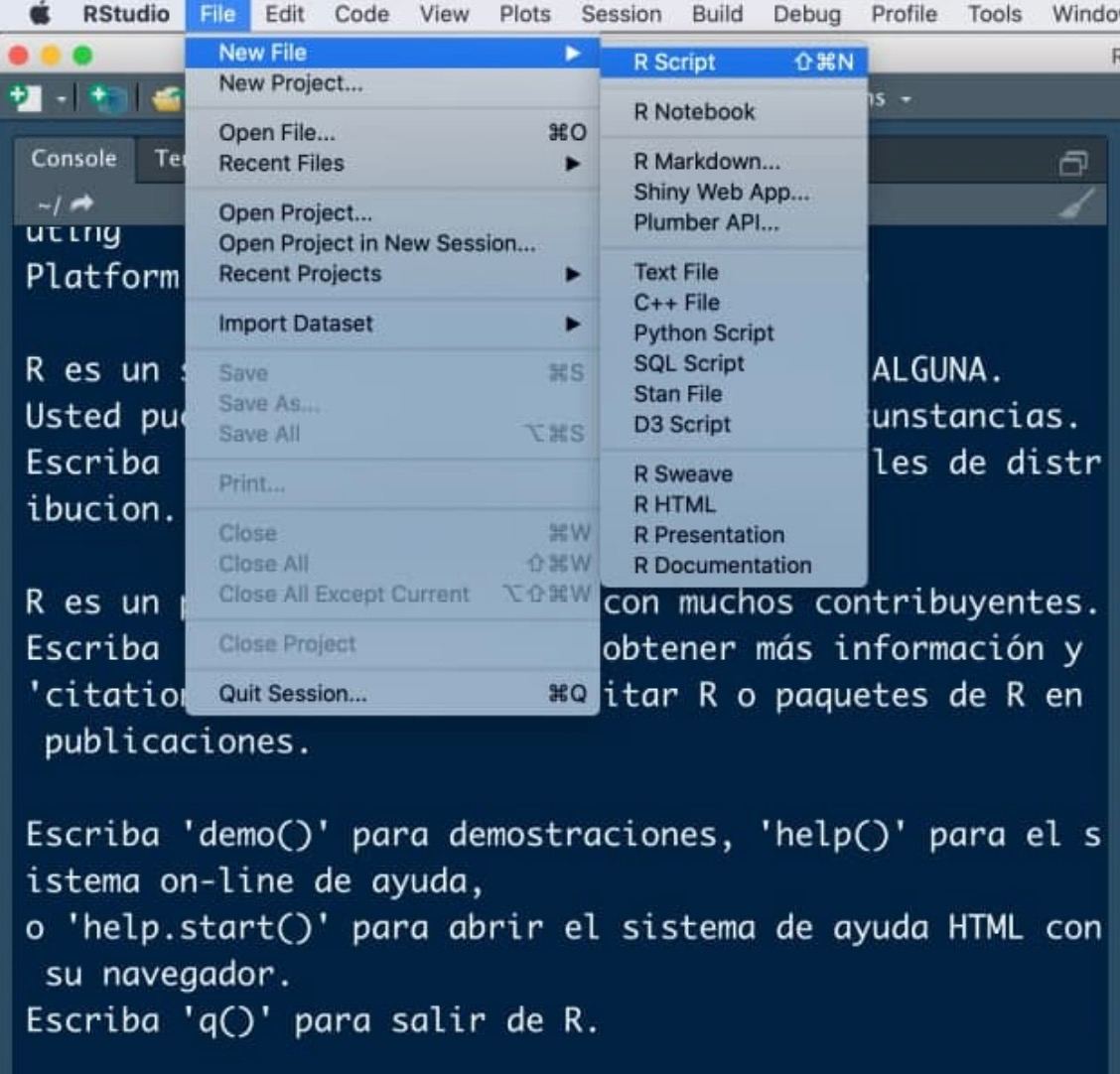
Un script será el documento en el que programamos, nuestro archivo .doc (aquí con extensión .R) donde escribiremos las órdenes. Para abrir nuestro primero script, haz click en el menú en File < New File < R Script.
Cuidado
Es importante no abusar de la consola: todo lo que no escribas en un script, cuando cierres, lo habrás perdido.
Ejecutando el primer script
Ahora tenemos una cuarta ventana: la ventana donde escribiremos nuestros códigos. ¿Cómo ejecutarlo?
Escribimos el código a ejecutar.
Guardamos el archivo .R haciendo click en Save current document.
El código no se ejecuta salvo que se lo indiquemos. Tenemos tres opciones:
Copiar y pegar en consola.
Seleccionar líneas y Ctrl+Enter
Activar Source on save a la derecha de guardar: no solo guarda sino que ejecuta el código completo.
💻 Tu turno
Ejecuta tu primer script: crea un script de cero, programa lo indicado debajo y ejecútalo (de las 3 maneras posibles)
📝 Define una variable de nombre a y cuyo valor sea -1
Código
a <--1
📝 Añade debajo otra línea para definir una variable b con el valor 5. Tras ello múltiplica ambas variables
Código
b <-5a * b # sin guardarmultiplicacion <- a * b # guardado
📝 Modifica el código inferior para definir dos variables c y d, con valores 3 y -1. Tras ello divide las variables.
c <-# deberías asignarle el valor 3d <-# deberías asignarle el valor -1
Código
c <-3d <--1c / d # sin guardardivision <- c / d # guardado
📝 Asigna un valor positivo a x y calcula su raíz cuadrada; asigna otro negativo y y calcula su valor absoluto con la función abs().
Código
x <-5sqrt(x)y <--2abs(y)
📝 Usando la variable x ya definida, completa/modifica el código inferior para guardar en una nueva variable z el resultado guardado en x menos 5.
z <- ? - ? # completa el códigoz
Código
z <- x -5z
Toma nota
Comandos como sqrt(), abs() o max() son lo que llamamos funciones: líneas de código que hemos «encapsulado» bajo un nombre, y dado unos argumentos de entrada, ejecuta las órdenes (una especie de atajo).
Primeros datos: variables
¿Qué tipos de datos existen?
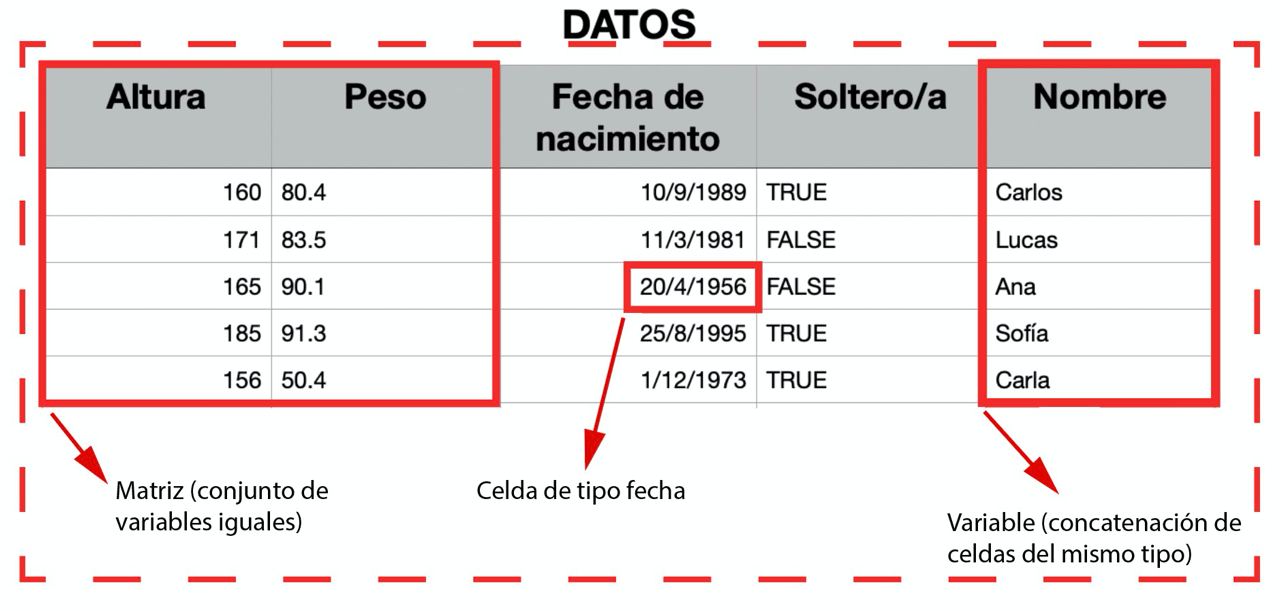
De la CELDA a la TABLA
¿Qué tipo de dato podemos tener en cada celda de una tabla?
Celda: dato individual de un tipo concreto.
Variable: concatenación de valores del mismo tipo (vectores).
Matriz: concatenación de variables del mismo tipo y longitud.
Tabla: concatenación de variables de distinto tipo pero igual longitud
Lista: concatenación de variables de distinto tipo y distinta longitud
Celdas: tipos de datos
¿Existen variables más allá de los números?
Piensa por ejemplo en los datos guardados de una persona:
La edad o el peso será un número.
edad <-33
Su nombre será una cadena de texto (string o char).
nombre <-"javi"
A la pregunta «¿está usted soltero/a?» la respuesta será lo que llamamos una variable lógica (TRUE si está soltero/a o FALSE en otro caso).
soltero <-TRUE
Su fecha de nacimiento será precisamente eso, una fecha.
Variables numéricos
El dato más sencillo (ya lo hemos usado) serán las variables numéricas
a <-5b <-2a + b
Para saber el tipo de una variable tenemos la función class()
class(a)
[1] "numeric"
Con las variables numéricas podemos realizar las operaciones aritméticas de una calculadora: sumar (+), raíz cuadrada (sqrt()), cuadrado (^2), etc.
a^2
[1] 25
Variables de texto
Imagina que además de la edad de una persona queremos guardar su nombre
nombre <-"Javier"class(nombre)
[1] "character"
Las cadenas de texto son un tipo con el que obviamente no podremos hacer operaciones aritméticas (sí otras operaciones como pegar o localizar patrones).
nombre +1# error al sumar número a texto
Error in nombre + 1: non-numeric argument to binary operator
Recuerda que…
Las variables de tipo texto (character o stringr) van siempre entre comillas.
Primera función: paste
Como hemos comentado, una función es un trozo de código encapsulado bajo un nombre que depende de unos argumentos de entrada. Nuestra primera función será paste(): dadas dos cadenas de texto nos permite pegarlas.
paste("Javier", "Álvarez")
[1] "Javier Álvarez"
Fíjate que por defecto nos pega las cadenas con un espacio, pero podemos añadir un argumento opcional para indicarle el separador
paste("Javier", "Álvarez", sep ="*")
[1] "Javier*Álvarez"
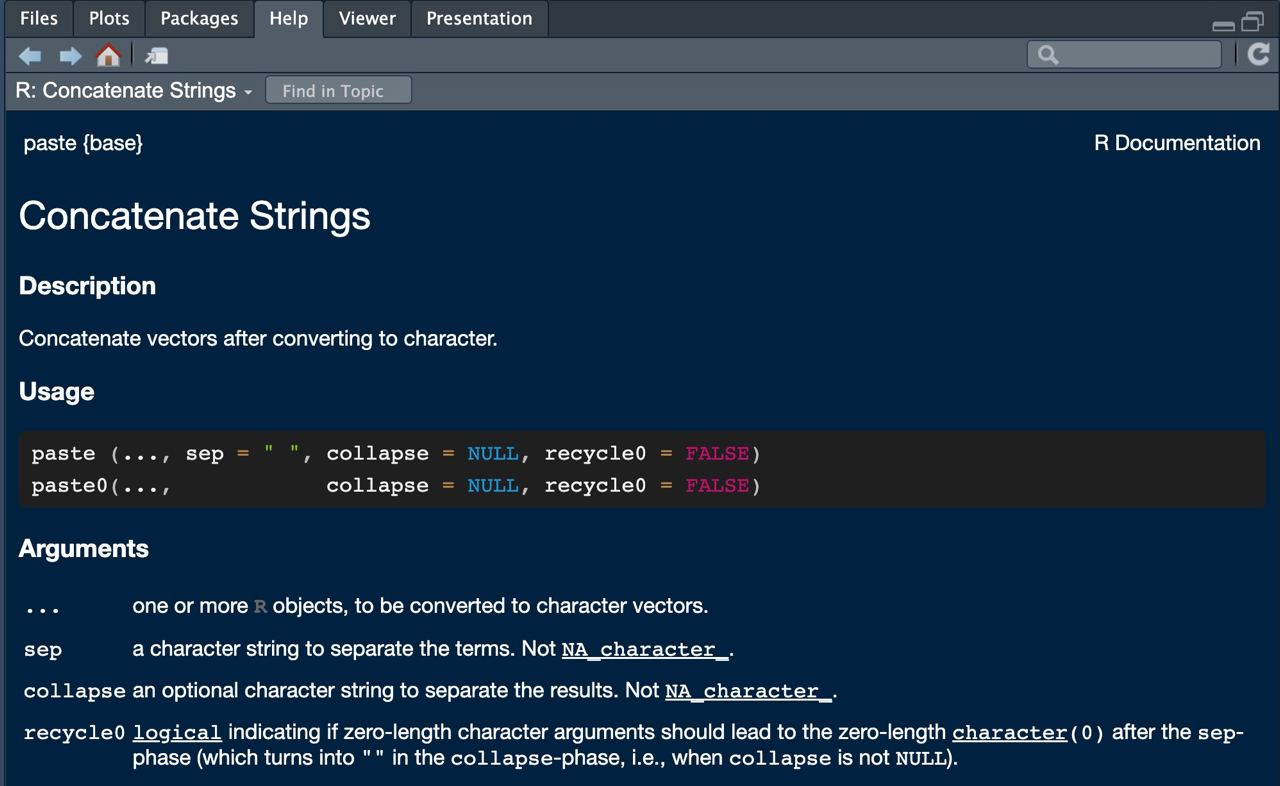
Primera función: paste
¿Cómo saber que argumentos tiene una función? Escribiendo en consola ? paste te aparecerá una ayuda en el panel multiusos.
En dicha ayuda podrás ver en su cabecera que argumentos ya tiene asignados por defecto la función
Existe una función similar llamada paste0() que pega por defecto con sep = "" (sin nada).
paste0("Javier", "Álvarez")
[1] "JavierÁlvarez"
Primer paquete: glue
Una forma más intuitiva de trabajar con textos es usar el paquete {glue}: lo primero que haremos será «comprar el libro» (si nunca lo hemos hecho). Tras ello cargamos el paquete
install.packages("glue") # solo la primra vezlibrary(glue)
Con dicho paquete podemos usar variables dentro de cadenas de texto. Por ejemplo, «la edad es de … años», donde la edad está guardada en una variable.
edad <-33glue("La edad es de {edad} años")
La edad es de 33 años
Dentro de las llaves también podemos ejecutar operaciones
unidades <-"días"glue("La edad es de {edad * 365} {unidades}")
La edad es de 12045 días
Variables lógicas
Una variable lógica o binaria es aquella que toma dos valores:
TRUE: verdadero guardado internamente como un 1.
FALSE: falso guardado internamente como un 0.
NA: dato ausente son las siglas de not available.
soltero <-TRUE# ¿Es soltero? --> SÍclass(soltero)
[1] "logical"
Importante
Las variables lógicas NO son variables de texto: "TRUE" es un texto, TRUE es un valor lógico.
TRUE+1
[1] 2
"TRUE"+1
Error in "TRUE" + 1: non-numeric argument to binary operator
Condiciones lógicas
Los valores lógicos suelen ser resultado de evaluar condiciones lógicas. Por ejemplo, imaginemos que queremos comprobar si una persona se llama Javi.
nombre <-"María"
Con el operador lógico== preguntamos sí a la izquierda es igual a la derecha
nombre =="Javi"
[1] FALSE
Con su opuesto != preguntamos si es distinto.
nombre !="Javi"
[1] TRUE
Fíjate que…
No es lo mismo <- (asignación) que una comparación lógica con == (estamos preguntando).
Condiciones lógicas
Además de las comparaciones «igual a» frente «distinto», también comparaciones de orden como <, <=, > o >=.
¿Tiene la persona menos de 32 años?
edad <-38edad <32# ¿Es la edad menor de 32 años?
[1] FALSE
¿La edad es mayor o igual que 38 años?
edad >=38
[1] TRUE
Variables de fecha
Un tipo de datos muy especial: los datos de tipo fecha.
fecha_char <-"2021-04-21"
Parece una simple cadena de texto pero representa un instante en el tiempo. ¿Qué debería suceder si sumamos un 1 a una fecha?
fecha_char +1
Error in fecha_char + 1: non-numeric argument to binary operator
Las fechas no pueden ser texto: debemos convertir la cadena de texto a fecha con as_date() del paquete {lubridate}
library(lubridate) # instala si no lo has hechofecha <-as_date("2023-03-28")fecha +1
[1] "2023-03-29"
class(fecha)
[1] "Date"
Variables de fecha
En dicho paquete tenemos funciones muy útiles para manejar fechas:
Con today() podemos obtener directamente la fecha actual.
today()
[1] "2023-04-17"
Con now() podemos obtener la fecha y hora actual
now()
[1] "2023-04-17 23:27:45 CEST"
Con year(), month() o day() podemos extraer el año, mes y día
fecha <-today()year(fecha)
[1] 2023
month(fecha)
[1] 4
Resúmenes de paquetes
Amplia contenido
Tienes un resumen en pdf de los paquetes más importantes en la carpeta «fichas paquetes»
💻 Tu turno
Intenta realizar los siguientes ejercicios sin mirar las soluciones
📝 Define otra variable con tus apellidos y junta con glue() las variables nombre y apellidos (una coma entre ellos) en una sola variable nombre_completo.
📝 Calcula los días que han pasado desde la fecha de tu nacimiento, haciendo la resta entre la fecha de hoy y la fecha de nacimiento definida en el ejercicio 2.
Código
today() - fecha_nacimiento
Primeros datos: vectores
¿Cómo concatenamos valores? ¿Cómo creamos una columna?
Vectores: concatenar
Cuando trabajamos con datos normalmente tendremos columnas que representan variables: llamaremos vectores a una concatenación de variables del mismo tipo
La forma más sencilla es con el comando c() (c de concatenar), y basta con introducir sus elementos entre paréntesis y separados por comas
edades <-c(33, 27, 60, 61)edades
[1] 33 27 60 61
Tip
Un número individual x <- 1 es en realidad un vector de longitud uno.
Vectores: concatenar
Como ves ahora en el environment tenemos una colección de elementos guardada
edades
[1] 33 27 60 61
La longitud de un vector se puede calcular con length()
length(edades)
[1] 4
También podemos concatenar vectores
c(edades, edades, 8)
[1] 33 27 60 61 33 27 60 61 8
Secuencias numéricas
En muchas ocasiones querremos crear secuencias numéricas (por ejemplo, los días del mes). El comando seq(inicio, fin) nos permite crear una secuencia desde un elemento inicial hasta uno final, avanzando de uno en uno.
Incluso puede nos interese generar un vector de n elementos repetidos
rep(0, 7) # vector de 7 ceros
[1] 0 0 0 0 0 0 0
Vectores de caracteres
Un vector es una concatenación de elementos del mismo tipo, pero no tienen porque ser necesariamente números. Vamos a crear una frase de ejemplo.
frase <-"Me llamo Javi"frase
[1] "Me llamo Javi"
length(frase)
[1] 1
En el caso anterior no era un vector, era un solo elemento de texto. Para crear un vector debemos usar de nuevo c() y separar elementos entre comas
vector <-c("Me", "llamo", "Javi")vector
[1] "Me" "llamo" "Javi"
length(vector)
[1] 3
Vectores de caracteres
¿Qué sucederá si concatenamos elementos de diferente tipo?
c(1, 2, "javi", "3", TRUE)
[1] "1" "2" "javi" "3" "TRUE"
Fíjate que como todos tienen que ser del mismo tipo, lo que hace R es convertir todo a texto, violando la integridad del dato
c(3, 4, TRUE, FALSE)
[1] 3 4 1 0
Es importante entender que los valores lógicos en realidad están almacenados internamente como 0/1
Operaciones con vectores
Con los vectores numéricos podemos hacer las mismas operaciones aritméticas que con los números → un número es un vector (de longitud uno)
¿Qué sucederá si sumamos o restamos un valor a un vector?
x <-c(1, 3, 5, 7)x +1
[1] 2 4 6 8
x *2
[1] 2 6 10 14
Cuidado
Salvo que indiquemos lo contrario, en R las operaciones con vectores son siempre elemento a elemento
Operaciones con vectores
Los vectores también pueden interactuar entre ellos, así que podemos definir, por ejemplo, sumas de vectores (elemento a elemento)
x <-c(2, 4, 6)y <-c(1, 3, 5)x + y
[1] 3 7 11
Dado que la operación (por ejemplo, una suma) se realiza elemento a elemento, ¿qué sucederá si sumamos dos vectores de distinta longitud?
z <-c(1, 3, 5, 7)x + z
[1] 3 7 11 9
Lo que hace es reciclar elementos: si tiene un vector de 4 elementos y sumamos otro de 3 elementos, lo que hará será reciclar del vector con menor longitud.
Operaciones con vectores
Una operación muy habitual es preguntar a los datos mediante el uso de condiciones lógicas. Por ejemplo, si definimos un vector de temperaturas…
¿Qué días hizo menos de 22 grados?
x <-c(15, 20, 31, 27, 15, 29)
x <22
[1] TRUE TRUE FALSE FALSE TRUE FALSE
Nos devolverá un vector lógico, en función de si cada elemento cumple o no la condición pedida.
Si tuviéramos un dato ausente (por error del aparato ese día), la condición evaluada también sería NA
y <-c(15, 20, NA, 31, 27, 7, 29, 10)y <22
[1] TRUE TRUE NA FALSE FALSE TRUE FALSE TRUE
Operaciones con vectores
Las condiciones lógicas pueden ser combinadas de dos maneras:
Intersección: todas las condiciones concatenadas se deben cumplir (conjunción y con &) para devolver un TRUE
x <30& x >15
[1] FALSE TRUE FALSE TRUE FALSE TRUE
Unión: basta con que al menos una se cumpla (conjunción o con |)
x <30| x >15
[1] TRUE TRUE TRUE TRUE TRUE TRUE
Con any() y all() podemos comprobar que todos los elementos cumplen
any(x <30)
[1] TRUE
all(x <30)
[1] FALSE
Operaciones con vectores
También podemos hacer uso de operaciones estadísticas como por ejemplo sum() que, dado un vector, nos devuelve la suma de todos sus elementos.
x <-c(1, -2, 3, -1)sum(x)
[1] 1
¿Qué sucede cuando falta un dato (ausente)?
x <-c(1, -2, 3, NA, -1)sum(x)
[1] NA
Por defecto, si tenemos un dato ausente, la operación también será ausente. Para poder obviar ese dato, usamos un argumento opcional na.rm = TRUE
sum(x, na.rm =TRUE)
[1] 1
Operaciones con vectores
Como hemos comentado que los valores lógicos son guardados internamente como 0 y 1, podremos usarlos en operaciones aritméticas.
Por ejemplo, si queremos averiguar el número de elementos que cumplen una condición (por ejemplo, menores que 3), los que lo hagan tendrán asignado un 1 (TRUE) y los que no un 0 (FALSE) , por lo que basta con sumar dicho vector lógico para obtener el número de elementos que cumplen
x <-c(2, 4, 6)sum(x <3)
[1] 1
Operaciones con vectores
Otras operaciones habituales son la media, mediana, percentiles, etc.
Media: medida de centralidad que consiste en sumar todos los elementos y dividirlos entre la cantidad de elementos sumados. La más conocida pero la menos robusta: dado un conjunto, si se introducen valores atípicos o outliers (valores muy grandes o muy pequeños), la media se perturba con mucha facilidad.
Otras operaciones habituales son la media, mediana, percentiles, etc.
Mediana: medida de centralidad que consiste en ordenar los elementos y quedarse con el que ocupa la mitad.
x <-c(165, 170, 181, 191, 150, 155, 167, 173, 177)median(x)
[1] 170
Percentiles: medidas de posición (nos dividen en partes iguales los datos).
quantile(x) # por defecto percentiles 0-25-50-75-100
0% 25% 50% 75% 100%
150 165 170 177 191
quantile(x, probs =c(0.1, 0.4, 0.9))
10% 40% 90%
154.0 167.6 183.0
Operaciones con vectores
Otra operación muy habitual es la de acceder a elementos del mismo. La forma más sencilla es usar el operador [i] (acceder al elemento i-ésimo)
edades <-c(20, 30, 33, NA, 61) edades[3] # accedemos a la edad de la tercera persona
[1] 33
Dado que un número no es más que un vector de longitud uno, esta operación también la podemos aplicar usando un vector de índices a seleccionar
y <-c("hola", "qué", "tal", "estás", "?")y[c(1:2, 4)] # primer, segundo y cuarto elemento
[1] "hola" "qué" "estás"
Tip
Para acceder al último, sin preocuparnos de cuál, podemos pasarle como índice la longitud x[length(x)]
Operaciones con vectores
Otras veces no querremos seleccionar sino eliminar algunos elementos. Deberemos repetir la misma operación pero con el signo - delante: el operador [-i] no selecciona el elemento i-ésimo del vector sino que lo «des-selecciona»
y
[1] "hola" "qué" "tal" "estás" "?"
y[-2]
[1] "hola" "tal" "estás" "?"
En muchas ocasiones los queremos seleccionar o eliminar en base a condiciones lógicas, en función de los valores, así que pasaremos como índice la propia condición (recuerda, x < 2 nos devuelve un vector lógico)
edades <-c(15, 21, 30, 17, 45)nombres <-c("javi", "maría", "laura", "carla", "luis")nombres[edades <18] # nombres de los menores de edad
[1] "javi" "carla"
Operaciones con vectores
Por último, una acción habitual es saber ordenar valores:
sort(): devuelve el vector ordenado. Por defecto de menor a mayor pero con decreasing = TRUE podemos cambiarlo
📝 Define el vector x como la concatenación de los 5 primeros números impares, y calcula su suma.
Código
# Dos formasx <-c(1, 3, 5, 7, 9)x <-seq(1, 9, by =2)sum(x)
📝 Obtén los elementos de x mayores que 4. Calcula el número de elementos de x mayores que 4.
Código
x[x >4]sum(x >4)
📝 Calcula el vector 1/x y obtén la versión ordenada (de menor a mayor).
Código
z <-1/xsort(z)z[order(z)]
📝 Encuentra el máximo y el mínimo del vector x
Código
min(x)max(x)
📝 Encuentra del vector x los elementos mayores (estrictos) que 1 y menores (estrictos) que 7. Encuentra una forma de averiguar si todos los elementos son o no positivos.
Código
x[x >1& x <7]all(x >0)
📝 Dado el vector x <- c(1, -5, 8, NA, 10, -3, 9), extrae los elementos que ocupan los lugares 1, 2, 5, 6. Elimina del vector el segundo elemento. Tras eliminarlo determina su suma y su media
¿Cómo construimos una tabla? Matrices, data.frame y tibble
Primer intento: matrices
Cuando analizamos datos solemos tener varias variables de cada individuo: necesitamos una «tabla» que las recopile. La opción más inmediata son las matrices: concatenación de variables del mismo tipo e igual longitud.
Imagina que tenemos estaturas y pesos de 4 personas. ¿Cómo crear un dataset con las dos variables? Con cbind() concatenamos en forma de columnas
edades soltero nombres
[1,] "14" "TRUE" "javi"
[2,] "24" NA "laura"
[3,] NA "FALSE" "lucía"
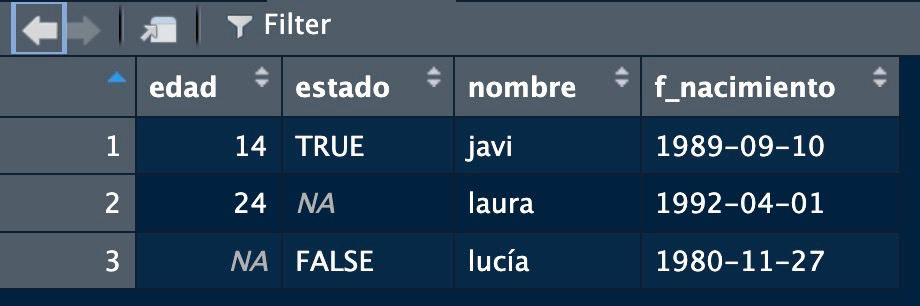
Para poder trabajar con variables de distinto tipo haremos uso de lo que se conoce como data.frame: una variables de igual longitud pero tipo distinto.
tabla <-data.frame(edades, soltero, nombres)tabla
edades soltero nombres
1 14 TRUE javi
2 24 NA laura
3 NA FALSE lucía
Segundo intento: data.frame
tabla
edades soltero nombres
1 14 TRUE javi
2 24 NA laura
3 NA FALSE lucía
class(tabla)
[1] "data.frame"
Dado que un data.frame es ya una «base de datos» las variables no son meros vectores matemáticos: tienen un significado y podemos (debemos) ponerles nombres
edad estado nombre f_nacimiento
1 14 TRUE javi 1989-09-10
2 24 NA laura 1992-04-01
3 NA FALSE lucía 1980-11-27
Segundo intento: data.frame
¡TENEMOS NUESTRO PRIMER CONJUNTO DE DATOS! Puedes visualizarlo escribiendo su nombre en consola o con View(tabla)
Segundo intento: data.frame
Si queremos acceder a sus elementos, el operador será similar al de los vectores: ahora tenemos dos índices (filas y columnas, dejando libre la que no usemos)
tabla[2, ] # segunda fila (todas sus variables)
edad estado nombre f_nacimiento
2 24 NA laura 1992-04-01
tabla[, 3] # tercera columna (de todos los individuos)
[1] "javi" "laura" "lucía"
tabla[2, 1] # primera característica de la segunda persona
[1] 24
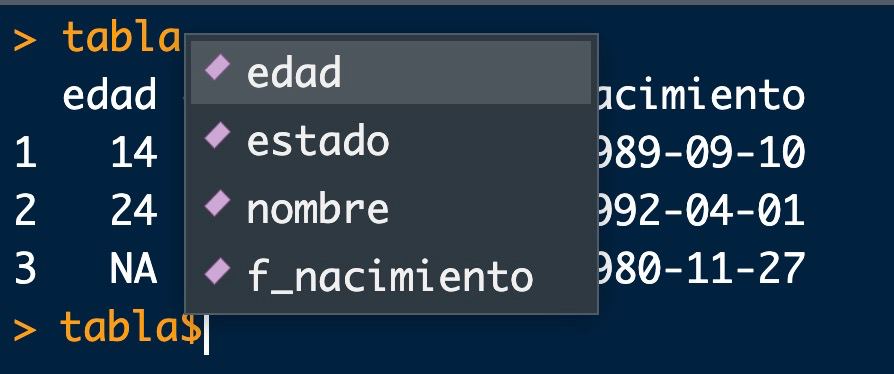
También tiene ventajas de una «base» de datos : podemos aceder a las variables por su nombre (recomendable ya que las variables pueden cambiar de posición), poniendo el nombre de la tabla seguido del símbolo $ (con el tabulador, nos aparecerá un menú de columnas a elegir)
Segundo intento: data.frame
names(): nos muestra los nombres de las variables
names(tabla)
[1] "edad" "estado" "nombre" "f_nacimiento"
dim(): nos muestra las dimensiones (también nrow() y ncol())
dim(tabla)
[1] 3 4
Podemos acceder a las variables por su nombre
tabla[c(1, 3), "nombre"]
[1] "javi" "lucía"
Intento final: tibble
Las tablas en formato data.frame tienen algunas limitaciones
La principal es que no permite la recursividad: imagina que definimos una base de datos con estaturas y pesos, y queremos una tercera variable con el IMC
📝 Carga del paquete {datasets} el conjunto de datos airquality (contiene variables de la calidad del aire de la ciudad de Nueva York desde mayo hasta septiembre de 1973). ¿Es el conjunto de datos airquality de tipo tibble? En caso negativo, conviértelo a tibble (busca en la documentación del paquete en https://tibble.tidyverse.org/index.html).
📝 Una vez convertido a tibble obtén el nombre de las variables y las dimensiones del conjunto de datos. ¿Cuántas variables hay? ¿Cuántos días se han medido?
Si conoces algún otro lenguaje de programación (o tienes gente cercana que programa) te extrañará que aún no hayamos hablado de conceptos habituales como
Bucles for: repetir un código un número fijo de iteraciones.
Bucles while: repetir un código hasta que se cumpla una condición
Estructuras if-else: estructuras de control para decidir por donde camina el código en función del valor de las variables.
Y aunque conocer dichas estructuras puede sernos en algún momento interesante, en la mayoría de ocasiones vamos a poder evitarlas (en especial los bucles) → en lugar de trabajar con lo que se conoce como R Base vamos a vertebrar el curso en torno a Tidyverse
¿Qué es tidyverse?
{tidyverse} es un «universo» de paquetes para garanatizar un flujo de trabajo (de inicio a fin) eficiente, coherente y lexicográficamente sencillo de entender, basado en la idea de que nuestros datos están limpios y ordenados (tidy)
¿Qué es tidyverse?
{tibble}: optimizando data.frame
{tidyr}: limpieza de datos
{readr}: carga datos rectangulares (.csv)
{dplyr}: gramática para depurar
{stringr}: manejo de textos
{ggplot2}: visualización de datos
{tidymodels}: modelización/predicción
También tenemos los paquetes {purrr} para el manejo de listas, {forcast} para cualitativas, {lubridate} para fechas, {readxl} para importar archivos .xls y .xlsx, {rvest} para web scraping y {rmarkdown} para comunicar resultados.
¿Qué es tidyverse?
{tibble}: optimizando data.frame
{tidyr}: limpieza de datos
{readr}: carga datos rectangulares (.csv)
{dplyr}: gramática para depurar
{stringr}: manejo de textos
{ggplot2}: visualización de datos
{tidymodels}: modelización/predicción
También tenemos los paquetes {purrr} para el manejo de listas, {forcast} para cualitativas, {lubridate} para fechas, {readxl} para importar archivos .xls y .xlsx, {rvest} para web scraping y {rmarkdown} para comunicar resultados.
Filosofía base: tidy data
Tidy datasets are all alike, but every messy dataset is messy in its own way (Hadley Wickham, Chief Scientist en RStudio)
TIDYVERSE
El universo de paquetes {tidyverse} se basa en la idea introducido por Hadley Wickham (el Dios al que rezo) de estandarizar el formato los datos para
sistematizar la depuración
hacer más sencillo su manipulación.
código legible
Reglas del tidy data
Lo primero por tanto será entender qué son los conjuntos tidydata ya que todo {tidyverse} se basa en que los datos están estandarizados.
Cada variable en una única columna
Cada individuo en una fila diferente
Cada celda con un único valor
Cada dataset en un tibble
Si queremos cruzar múltiples tablas debemos tener una columna común
Tubería (pipe)
En {tidyverse} será clave el operador pipe (tubería) definido como |> (ctrl+shift+M): será una tubería que recorre los datos y los transforma.
En R base, si queremos aplicar tres funciones first(), second() y third() en orden, sería
third(second(first(datos)))
En {tidyverse} podremos leer de izquierda a derecha y separar los datos de las acciones
datos |>first() |>second() |>third()
Apunte importante
Desde la versión 4.1.0 de R disponemos de |>, un pipe nativo disponible fuera de tidyverse, sustituyendo al antiguo pipe%>% que dependía del paquete {magrittr} (bastante problemático).
Tubería (pipe)
La principal ventaja es que el código sea muy legible (casi literal) pudiendo hacer grandes operaciones con los datos con apenas código.
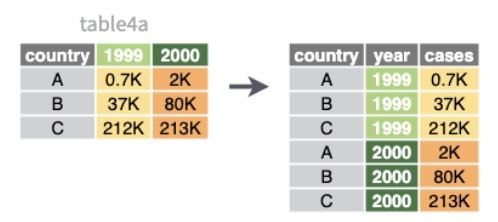
¿Pero qué aspecto tienen los datos no tidy? Vamos a cargar la tabla table4a del paquete {tidyr} (ya lo tenemos cargado del entorno tidyverse).
library(tidyr)table4a
# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 213766
¿Qué puede estar fallando?
Pivotar: pivot_longer()
table4a
# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 213766
❎ Cada fila representa dos observaciones (1999 y 2000) → las columnas 1999 y 2000 en realidad deberían ser en sí valores de una variable y no nombres de columnas.
Incluiremos una nueva columna que nos guarde el año y otra que guarde el valor de la variable de interés en cada uno de esos años. Y lo haremos con la función pivot_longer(): pivotaremos la tabla a formato long:
# A tibble: 6 × 3
country year cases
<chr> <chr> <dbl>
1 Afghanistan 1999 745
2 Afghanistan 2000 2666
3 Brazil 1999 37737
4 Brazil 2000 80488
5 China 1999 212258
6 China 2000 213766
cols: nombre de las variables a pivotar
names_to: nombre de la nueva variable a la quemandamos la cabecera de la tabla (los nombres).
values_to: nombre de la nueva variable a la que vamos a mandar los datos.
Datos SUCIOS: messy data
Veamos otro ejemplo con la tabla table2
table2
# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583
¿Qué puede estar fallando?
Pivotar: pivot_wider()
# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583
❎ Cada observación está dividido en dos filas → los registros con el mismo año deberían ser el mismo
Lo que haremos será lo opuesto: con pivot_wider()ensancharemos la tabla
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583
Datos SUCIOS: messy data
Veamos otro ejemplo con la tabla table3
table3
# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583
¿Qué puede estar fallando?
Separar: separate()
table3
# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583
❎ Cada celda contiene varios valores
Lo que haremos será hacer uso de la función separate() para mandar separar cada valor a una columna diferente.
table3 |>separate(rate, into =c("cases", "pop"))
# A tibble: 6 × 4
country year cases pop
<chr> <dbl> <chr> <chr>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583
Separar: separate()
table3 |>separate(rate, into =c("cases", "pop"))
# A tibble: 6 × 4
country year cases pop
<chr> <dbl> <chr> <chr>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583
Fíjate que los datos, aunque los ha separado, los ha mantenido como texto cuando en realidad deberían ser variables numéricas. Para ello podemos añadir el argumento opcional convert = TRUE
table3 |>separate(rate, into =c("cases", "pop"), convert =TRUE)
# A tibble: 6 × 4
country year cases pop
<chr> <dbl> <int> <int>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583
Datos SUCIOS: messy data
Veamos el último ejemplo con la tabla table5
table5
# A tibble: 6 × 4
country century year rate
<chr> <chr> <chr> <chr>
1 Afghanistan 19 99 745/19987071
2 Afghanistan 20 00 2666/20595360
3 Brazil 19 99 37737/172006362
4 Brazil 20 00 80488/174504898
5 China 19 99 212258/1272915272
6 China 20 00 213766/1280428583
¿Qué puede estar fallando?
Unir unite()
table5
# A tibble: 6 × 4
country century year rate
<chr> <chr> <chr> <chr>
1 Afghanistan 19 99 745/19987071
2 Afghanistan 20 00 2666/20595360
3 Brazil 19 99 37737/172006362
4 Brazil 20 00 80488/174504898
5 China 19 99 212258/1272915272
6 China 20 00 213766/1280428583
❎ Tenemos mismos valores divididos en dos columnas
Usaremos unite() para unir los valores de siglo y año en una misma columna
table5 |>unite(col = year_completo, century, year, sep ="")
# A tibble: 6 × 3
country year_completo rate
<chr> <chr> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583
💻 Tu turno
Intenta realizar los siguientes ejercicios sin mirar las soluciones
📝 Echa un vistazo a la tabla table4b del paquete {tidyr}. ¿Es tidydata? En caso negativo, ¿qué falla? ¿Cómo convertirla a tidy data en caso de que no lo sea ya?
📝 Echa un vistazo a la tabla relig_income del paquete {tidyr}. ¿Es tidydata? En caso negativo, ¿qué falla? ¿Cómo convertirla a tidy data en caso de que no lo sea ya?
📝 Echa un vistazo a la tabla billboard del paquete {tidyr}. ¿Es tidydata? En caso negativo, ¿qué falla? ¿Cómo convertirla a tidy data en caso de que no lo sea ya?
Código
billboard |>pivot_longer(cols ="wk1":"wk76",names_to ="week",names_prefix ="wk",values_to ="position",values_drop_na =TRUE)
Introducción a Tidyverse
Con los datos limpicos, vamos a trabajarlos
Preprocesamiento: dplyr
Dentro de {tidyverse} usaremos el paquete {dplyr} para el preprocesamiento y depuración de datos de datos.
Una de las operaciones más comunes es filtrar registros en base a alguna condición lógica: con filter() se seleccionarán solo individuos que cumplan ciertas condiciones.
==, !=: igual o distinto que
>, <: mayor o menor que
>=, <=: mayor o igual o menor o igual que
%in%: valores pertenencen a un listado de opciones
between(variable, val1, val2): si los valores (normalmente continuos) caen dentro de un rango de valores
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías… filtrar los personajes de ojos marrones?
starwars |>filter(eye_color =="brown")
# A tibble: 21 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Leia Or… 150 49 brown light brown 19 fema… femin…
2 Biggs D… 183 84 black light brown 24 male mascu…
3 Han Solo 180 80 brown fair brown 29 male mascu…
4 Yoda 66 17 white green brown 896 male mascu…
5 Boba Fe… 183 78.2 black fair brown 31.5 male mascu…
6 Lando C… 177 79 black dark brown 31 male mascu…
7 Arvel C… NA NA brown fair brown NA male mascu…
8 Wicket … 88 20 brown brown brown 8 male mascu…
9 Quarsh … 183 NA black dark brown 62 <NA> <NA>
10 Shmi Sk… 163 NA black fair brown 72 fema… femin…
# ℹ 11 more rows
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías… filtrar los personajes que no tienen ojos marrones?
starwars |>filter(eye_color !="brown")
# A tibble: 66 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Luke Sk… 172 77 blond fair blue 19 male mascu…
2 C-3PO 167 75 <NA> gold yellow 112 none mascu…
3 R2-D2 96 32 <NA> white, bl… red 33 none mascu…
4 Darth V… 202 136 none white yellow 41.9 male mascu…
5 Owen La… 178 120 brown, gr… light blue 52 male mascu…
6 Beru Wh… 165 75 brown light blue 47 fema… femin…
7 R5-D4 97 32 <NA> white, red red NA none mascu…
8 Obi-Wan… 182 77 auburn, w… fair blue-gray 57 male mascu…
9 Anakin … 188 84 blond fair blue 41.9 male mascu…
10 Wilhuff… 180 NA auburn, g… fair blue 64 male mascu…
# ℹ 56 more rows
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías… filtrar los personajes que tengan los ojos marrones o azules?
# A tibble: 40 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Luke Sk… 172 77 blond fair blue 19 male mascu…
2 Leia Or… 150 49 brown light brown 19 fema… femin…
3 Owen La… 178 120 brown, gr… light blue 52 male mascu…
4 Beru Wh… 165 75 brown light blue 47 fema… femin…
5 Biggs D… 183 84 black light brown 24 male mascu…
6 Anakin … 188 84 blond fair blue 41.9 male mascu…
7 Wilhuff… 180 NA auburn, g… fair blue 64 male mascu…
8 Chewbac… 228 112 brown unknown blue 200 male mascu…
9 Han Solo 180 80 brown fair brown 29 male mascu…
10 Jek Ton… 180 110 brown fair blue NA male mascu…
# ℹ 30 more rows
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías… filtrar los personajes que midan entre 120 y 160 cm?
starwars |>filter(between(height, 120, 160))
# A tibble: 6 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Leia Org… 150 49 brown light brown 19 fema… femin…
2 Mon Moth… 150 NA auburn fair blue 48 fema… femin…
3 Nien Nunb 160 68 none grey black NA male mascu…
4 Watto 137 NA black blue, grey yellow NA male mascu…
5 Gasgano 122 NA none white, bl… black NA male mascu…
6 Cordé 157 NA brown light brown NA fema… femin…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Importante
Recuerda que dentro de filter() debe ir siempre algo que devuelva un vector de valores lógicos.
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías… filtrar los personajes que tengan ojos y no sean humanos?
starwars |>filter(eye_color =="brown"& species !="Human")
# A tibble: 3 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Yoda 66 17 white green brown 896 male mascu…
2 Wicket S… 88 20 brown brown brown 8 male mascu…
3 Eeth Koth 171 NA black brown brown NA male mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías… filtrar los personajes que tengan ojos y no sean humanos, o que tengan más de 60 años?
starwars |>filter((eye_color =="brown"& species !="Human") | birth_year >60)
# A tibble: 18 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 C-3PO 167 75 <NA> gold yellow 112 none mascu…
2 Wilhuff… 180 NA auburn, g… fair blue 64 male mascu…
3 Chewbac… 228 112 brown unknown blue 200 male mascu…
4 Jabba D… 175 1358 <NA> green-tan… orange 600 herm… mascu…
5 Yoda 66 17 white green brown 896 male mascu…
6 Palpati… 170 75 grey pale yellow 82 male mascu…
7 Wicket … 88 20 brown brown brown 8 male mascu…
8 Qui-Gon… 193 89 brown fair blue 92 male mascu…
9 Finis V… 170 NA blond fair blue 91 male mascu…
10 Quarsh … 183 NA black dark brown 62 <NA> <NA>
11 Shmi Sk… 163 NA black fair brown 72 fema… femin…
12 Mace Wi… 188 84 none dark brown 72 male mascu…
13 Ki-Adi-… 198 82 white pale yellow 92 male mascu…
14 Eeth Ko… 171 NA black brown brown NA male mascu…
15 Cliegg … 183 NA brown fair blue 82 male mascu…
16 Dooku 193 80 white fair brown 102 male mascu…
17 Bail Pr… 191 NA black tan brown 67 male mascu…
18 Jango F… 183 79 black tan brown 66 male mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Eliminar ausentes: drop_na()
datos |>retirar_ausentes(var1, var2, ...)
starwars |>drop_na(var1, var2, ...)
Hay un filtro especial que es el de retirar los ausentes, para lo cual podemos usar filter(is.na(variable)) o directamente drop_na(): si no indicamos variable, elimina registros con ausente en cualquiera de las variables.
starwars |>drop_na(mass, height)
# A tibble: 7 × 4
name mass height hair_color
<chr> <dbl> <int> <chr>
1 Luke Skywalker 77 172 blond
2 C-3PO 75 167 <NA>
3 R2-D2 32 96 <NA>
4 Darth Vader 136 202 none
5 Leia Organa 49 150 brown
6 Owen Lars 120 178 brown, grey
7 Beru Whitesun lars 75 165 brown
starwars |>drop_na()
# A tibble: 7 × 4
name mass height hair_color
<chr> <dbl> <int> <chr>
1 Luke Skywalker 77 172 blond
2 Darth Vader 136 202 none
3 Leia Organa 49 150 brown
4 Owen Lars 120 178 brown, grey
5 Beru Whitesun lars 75 165 brown
6 Biggs Darklighter 84 183 black
7 Obi-Wan Kenobi 77 182 auburn, white
💻 Tu turno
Intenta realizar los siguientes ejercicios sin mirar las soluciones
📝 Selecciona del conjunto original de starwars los personajes no humanos, male en el sexo y que midan entre 120 y 170 cm, o los personajes con ojos marrones o rojos.
📝 Busca información en la ayuda de la función str_detect() del paquete {stringr} (cargado en {tidyverse}). Consejo: prueba antes las funciones que vayas a usar con algún vector de prueba para poder comprobar su funcionamiento. Tras saber lo que hace, filtra solo aquellos personajes con apellido Skywalker
Código
starwars |>filter(str_detect(name, "Skywalker"))
Rebanadas de datos: slice()
datos |>rebanadas(posiciones)
starwars |>slice(posiciones)
Normalmente filtraremos condición pero a veces nos puede interesar filtrar por posición: con slice(posiciones) podremos seleccionar filas concreetas pasando como argumento un vector de índices
starwars |>slice(1)
# A tibble: 1 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Luke Skywalker 172 77 blond
starwars |>slice(7:9)
# A tibble: 3 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Beru Whitesun lars 165 75 brown
2 R5-D4 97 32 <NA>
3 Biggs Darklighter 183 84 black
starwars |>slice(c(2, 7, 10, 31))
# A tibble: 4 × 8
name height mass hair_color skin_color eye_color birth_year sex
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 C-3PO 167 75 <NA> gold yellow 112 none
2 Beru Whitesun l… 165 75 brown light blue 47 fema…
3 Obi-Wan Kenobi 182 77 auburn, w… fair blue-gray 57 male
4 Qui-Gon Jinn 193 89 brown fair blue 92 male
Rebanadas de datos: slice()
datos |>rebanadas(posiciones)
starwars |>slice(posiciones)
Disponemos de opciones por defecto: con slice_head(n = ...) y slice_tail(n = ...) podemos obtener la cabecera y cola de la tabla
starwars |>slice_head(n =2)
# A tibble: 2 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Luke Skywalker 172 77 blond
2 C-3PO 167 75 <NA>
starwars |>slice_tail(n =2)
# A tibble: 2 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Captain Phasma NA NA unknown
2 Padmé Amidala 165 45 brown
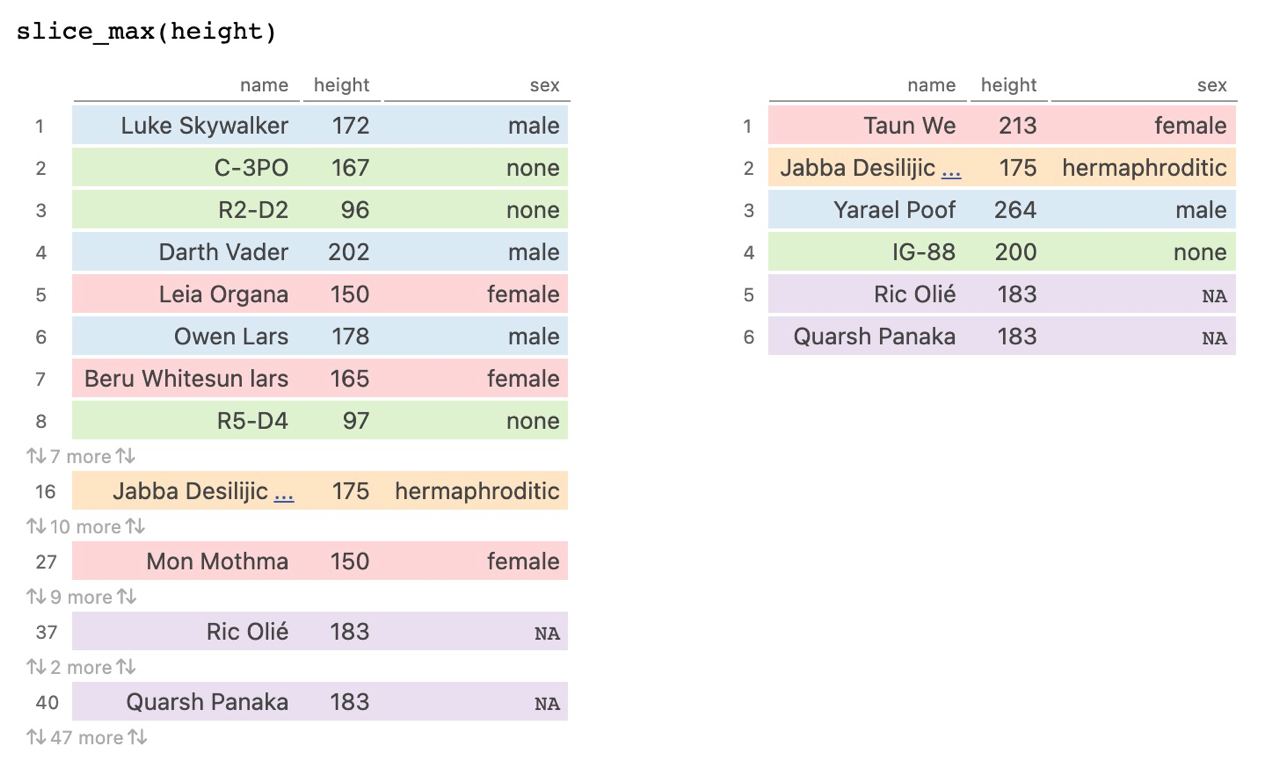
Con slice_max() y slice_min() obtenemos la filas con menor/mayor valor de una variable (si empate, todas salvo que with_ties = FALSE).
starwars |>slice_min(mass, n =2)
# A tibble: 2 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Ratts Tyerell 79 15 none
2 Yoda 66 17 white
starwars |>slice_max(height, n =2)
# A tibble: 2 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Yarael Poof 264 NA none
2 Tarfful 234 136 brown
Reordenar filas: arrange()
datos |>ordenar(var1, var2, ...)
starwars |>arrange(var1, var2, ...)
También podemos ordenar filas en función de alguna variable con arrange()
starwars |>arrange(mass)
# A tibble: 5 × 6
name height mass hair_color skin_color eye_color
<chr> <int> <dbl> <chr> <chr> <chr>
1 Ratts Tyerell 79 15 none grey, blue unknown
2 Yoda 66 17 white green brown
3 Wicket Systri Warrick 88 20 brown brown brown
4 R2-D2 96 32 <NA> white, blue red
5 R5-D4 97 32 <NA> white, red red
Por defecto de menor a mayor pero podemos invertir el orden con desc()
starwars |>arrange(desc(height))
# A tibble: 5 × 3
name height mass
<chr> <int> <dbl>
1 Yarael Poof 264 NA
2 Tarfful 234 136
3 Lama Su 229 88
4 Chewbacca 228 112
5 Roos Tarpals 224 82
📝 Para saber que valores únicos hay en el color de pelo, elimina duplicados de la variable hair_color, eliminando antes los ausentes de dicha variable.
📝 De los personajes que son humanos y miden más de 160 cm, elimina duplicados en color de ojos, elimina ausentes en peso, selecciona los 3 más altos, y orden de mayor a menor peso. Devuelve la tabla.
La opción más sencilla para seleccionar variables por nombre es select(), dando como argumentos los nombres de columnas sin comillas.
starwars %>%select(name, hair_color)
# A tibble: 87 × 2
name hair_color
<chr> <chr>
1 Luke Skywalker blond
2 C-3PO <NA>
3 R2-D2 <NA>
4 Darth Vader none
5 Leia Organa brown
6 Owen Lars brown, grey
7 Beru Whitesun lars brown
8 R5-D4 <NA>
9 Biggs Darklighter black
10 Obi-Wan Kenobi auburn, white
# ℹ 77 more rows
Selección columnas: select()
datos |>selecciono(var1, var2, ...)
starwars |>select(var1, var2, ...)
La función select() nos permite seleccionar varias variables a la vez concatenando sus nombres como si fuesen índices
starwars |>select(name:eye_color)
# A tibble: 4 × 6
name height mass hair_color skin_color eye_color
<chr> <int> <dbl> <chr> <chr> <chr>
1 Luke Skywalker 172 77 blond fair blue
2 C-3PO 167 75 <NA> gold yellow
3 R2-D2 96 32 <NA> white, blue red
4 Darth Vader 202 136 none white yellow
Y podemos deseleccionar columnas con -
starwars |>select(-mass, -(eye_color:starships))
# A tibble: 4 × 4
name height hair_color skin_color
<chr> <int> <chr> <chr>
1 Luke Skywalker 172 blond fair
2 C-3PO 167 <NA> gold
3 R2-D2 96 <NA> white, blue
4 Darth Vader 202 none white
Selección columnas: select()
datos |>selecciono(var1, var2, ...)
starwars |>select(var1, var2, ...)
Tenemos además palabras reservadas: everything()todas las variables…
starwars |>select(mass, homeworld, everything())
# A tibble: 4 × 14
mass homeworld name height hair_color skin_color eye_color birth_year sex
<dbl> <chr> <chr> <int> <chr> <chr> <chr> <dbl> <chr>
1 77 Tatooine Luke … 172 blond fair blue 19 male
2 75 Tatooine C-3PO 167 <NA> gold yellow 112 none
3 32 Naboo R2-D2 96 <NA> white, bl… red 33 none
4 136 Tatooine Darth… 202 none white yellow 41.9 male
# ℹ 5 more variables: gender <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
…y last_col() para referirnos a la última columna.
# A tibble: 4 × 5
name height mass homeworld starships
<chr> <int> <dbl> <chr> <list>
1 Luke Skywalker 172 77 Tatooine <chr [2]>
2 C-3PO 167 75 Tatooine <chr [0]>
3 R2-D2 96 32 Naboo <chr [0]>
4 Darth Vader 202 136 Tatooine <chr [1]>
Selección columnas: select()
datos |>selecciono(var1, var2, ...)
starwars |>select(var1, var2, ...)
Podemos jugar con patrones en el nombre, aquellas que comiencen por un prefijo (starts_with()), terminen con un sufijo (ends_with()), contengan un texto (contains()) o cumplan una expresión regular (matches()).
# variables cuyo nombre acaba en "color" y contengan sexo o génerostarwars |>select(ends_with("color"), matches("sex|gender"))
# A tibble: 87 × 5
hair_color skin_color eye_color sex gender
<chr> <chr> <chr> <chr> <chr>
1 blond fair blue male masculine
2 <NA> gold yellow none masculine
3 <NA> white, blue red none masculine
4 none white yellow male masculine
5 brown light brown female feminine
6 brown, grey light blue male masculine
7 brown light blue female feminine
8 <NA> white, red red none masculine
9 black light brown male masculine
10 auburn, white fair blue-gray male masculine
# ℹ 77 more rows
Selección columnas: select()
datos |>selecciono(var1, var2, ...)
starwars |>select(var1, var2, ...)
Incluso podemos seleccionar por rango numérico si tenemos variables con un prefijo y números.
Con num_range() podemos seleccionar con un prefijo y una secuencia numérica.
datos |>select(num_range("semana", 1:4))
# A tibble: 3 × 4
semana1 semana2 semana3 semana4
<dbl> <dbl> <dbl> <dbl>
1 115 7 95 11
2 141 NA 162 19
3 232 17 NA 15
Selección columnas: select()
datos |>selecciono(var1, var2, ...)
starwars |>select(var1, var2, ...)
Por último, podemos seleccionar columnas por tipo de dato haciendo uso de where() y dentro una función que devuelva un valor lógico de tipo de dato.
# Solo columnas numéricas o de textostarwars |>select(where(is.numeric) |where(is.character))
# A tibble: 87 × 11
height mass birth_year name hair_color skin_color eye_color sex gender
<int> <dbl> <dbl> <chr> <chr> <chr> <chr> <chr> <chr>
1 172 77 19 Luke Sk… blond fair blue male mascu…
2 167 75 112 C-3PO <NA> gold yellow none mascu…
3 96 32 33 R2-D2 <NA> white, bl… red none mascu…
4 202 136 41.9 Darth V… none white yellow male mascu…
5 150 49 19 Leia Or… brown light brown fema… femin…
6 178 120 52 Owen La… brown, gr… light blue male mascu…
7 165 75 47 Beru Wh… brown light blue fema… femin…
8 97 32 NA R5-D4 <NA> white, red red none mascu…
9 183 84 24 Biggs D… black light brown male mascu…
10 182 77 57 Obi-Wan… auburn, w… fair blue-gray male mascu…
# ℹ 77 more rows
# ℹ 2 more variables: homeworld <chr>, species <chr>
Mover columnas: relocate()
datos |>recolocar(var1, despues_de = var2)
starwars |>relocate(var1, .after = var2)
Para facilitar la recolocación de variables tenemos una función para ello, relocate(), indicándole en .after o .beforedetrás o delante de qué columnas queremos moverlas.
starwars |>relocate(species, .before = name)
# A tibble: 87 × 14
species name height mass hair_color skin_color eye_color birth_year sex
<chr> <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 Human Luke S… 172 77 blond fair blue 19 male
2 Droid C-3PO 167 75 <NA> gold yellow 112 none
3 Droid R2-D2 96 32 <NA> white, bl… red 33 none
4 Human Darth … 202 136 none white yellow 41.9 male
5 Human Leia O… 150 49 brown light brown 19 fema…
6 Human Owen L… 178 120 brown, gr… light blue 52 male
7 Human Beru W… 165 75 brown light blue 47 fema…
8 Droid R5-D4 97 32 <NA> white, red red NA none
9 Human Biggs … 183 84 black light brown 24 male
10 Human Obi-Wa… 182 77 auburn, w… fair blue-gray 57 male
# ℹ 77 more rows
# ℹ 5 more variables: gender <chr>, homeworld <chr>, films <list>,
# vehicles <list>, starships <list>
Renombrar: rename()
datos |>renombrar(nuevo = antiguo)
starwars |>rename(nuevo = antiguo)
A veces también podemos querer modificar la «metainformación» de los datos, renombrando columnas. Para ello usaremos de rename() poniendo primero el nombre nuevo y luego el antiguo.
# A tibble: 87 × 16
height_m IMC name height mass hair_color skin_color eye_color birth_year
<dbl> <dbl> <chr> <int> <dbl> <chr> <chr> <chr> <dbl>
1 1.72 26.0 Luke … 172 77 blond fair blue 19
2 1.67 26.9 C-3PO 167 75 <NA> gold yellow 112
3 0.96 34.7 R2-D2 96 32 <NA> white, bl… red 33
4 2.02 33.3 Darth… 202 136 none white yellow 41.9
5 1.5 21.8 Leia … 150 49 brown light brown 19
6 1.78 37.9 Owen … 178 120 brown, gr… light blue 52
7 1.65 27.5 Beru … 165 75 brown light blue 47
8 0.97 34.0 R5-D4 97 32 <NA> white, red red NA
9 1.83 25.1 Biggs… 183 84 black light brown 24
10 1.82 23.2 Obi-W… 182 77 auburn, w… fair blue-gray 57
# ℹ 77 more rows
# ℹ 7 more variables: sex <chr>, gender <chr>, homeworld <chr>, species <chr>,
# films <list>, vehicles <list>, starships <list>
Modificar columnas: mutate()
datos |>modificar(nueva =funcion())
starwars |>mutate(nueva =funcion())
Importante…
Cuando aplicamos mutate(), debemos de acordarnos que las operaciones se realizan de manera vectorial, elemento a elemento, por lo que la función que usemos dentro debe devolver un vector de igual longitud. En caso contrario, devolverá una constante
# A tibble: 87 × 15
constante name height mass hair_color skin_color eye_color birth_year sex
<dbl> <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 97.3 Luke… 172 77 blond fair blue 19 male
2 97.3 C-3PO 167 75 <NA> gold yellow 112 none
3 97.3 R2-D2 96 32 <NA> white, bl… red 33 none
4 97.3 Dart… 202 136 none white yellow 41.9 male
5 97.3 Leia… 150 49 brown light brown 19 fema…
6 97.3 Owen… 178 120 brown, gr… light blue 52 male
7 97.3 Beru… 165 75 brown light blue 47 fema…
8 97.3 R5-D4 97 32 <NA> white, red red NA none
9 97.3 Bigg… 183 84 black light brown 24 male
10 97.3 Obi-… 182 77 auburn, w… fair blue-gray 57 male
# ℹ 77 more rows
# ℹ 6 more variables: gender <chr>, homeworld <chr>, species <chr>,
# films <list>, vehicles <list>, starships <list>
Recategorizar: if_else()
También podemos combinar mutate() con la expresión de control if_else() para recategorizar la variable: si se cumple una condición, hace una cosa, en caso contrario otra.
# A tibble: 87 × 4
name human height mass
<chr> <chr> <int> <dbl>
1 Luke Skywalker Human 172 77
2 C-3PO Not Human 167 75
3 R2-D2 Not Human 96 32
4 Darth Vader Human 202 136
5 Leia Organa Human 150 49
6 Owen Lars Human 178 120
7 Beru Whitesun lars Human 165 75
8 R5-D4 Not Human 97 32
9 Biggs Darklighter Human 183 84
10 Obi-Wan Kenobi Human 182 77
# ℹ 77 more rows
Recategorizar: case_when()
Para recategorizaciones más complejas tenemos case_when(), por ejemplo, para crear una categoría de los personajes en función de su altura.
📝 Selecciona solo las variables nombre, altura y así como todas aquellas variables relacionadas con el color, a la vez que te quedas solo con aquellos que no tengan ausente en la altura.
📝 Con los datos originales, comprueba cuántas modalidades únicas hay en la variable de color de pelo.
Código
starwars |>distinct(hair_color) |>nrow()
📝 Del dataset original, selecciona solo las variables numéricas y de tipo texto. Tras ello define una nueva variable llamada under_18 que nos recategorice la variable de edad: TRUE si es menor de edad y FALSE en caso contrario
📝 Del dataset original, crea una nueva columna llamada auburn (cobrizo/caoba) que nos diga TRUE si el color de pelo contiene dicha palabra y FALSE en caso contrario (reminder str_detect()).
📝 Del dataset original, incluye una columna que calcule el IMC. Tras ello, crea una nueva variable que valga NA si no es humano, delgadez por debajo de 18, normal entre 18 y 30, sobrepeso por encima de 30.
Hasta ahora solo hemos transformado o consultado los datos pero no hemos generado estadísticas. Empecemos por lo sencillo: ¿cómo contar (frecuencias)?
Cuando lo usamos en solitario count() nos devolverá simplemente el número de registros , pero cuando lo usamos con variables count() calcula lo que se conoce como frecuencias: número de elementos de cada modalidad.
starwars |>count(sex)
# A tibble: 5 × 2
sex n
<chr> <int>
1 female 16
2 hermaphroditic 1
3 male 60
4 none 6
5 <NA> 4
Contar: count()
datos |>contar(var1, var2)
starwars |>count(var1, var2)
Además si pasamos varias variables nos calcula lo que se conoce como una tabla de contigencia. Con sort = TRUE nos devolverá el conteo ordenado (más frecuentes primero).
starwars |>count(sex, gender, sort =TRUE)
# A tibble: 6 × 3
sex gender n
<chr> <chr> <int>
1 male masculine 60
2 female feminine 16
3 none masculine 5
4 <NA> <NA> 4
5 hermaphroditic masculine 1
6 none feminine 1
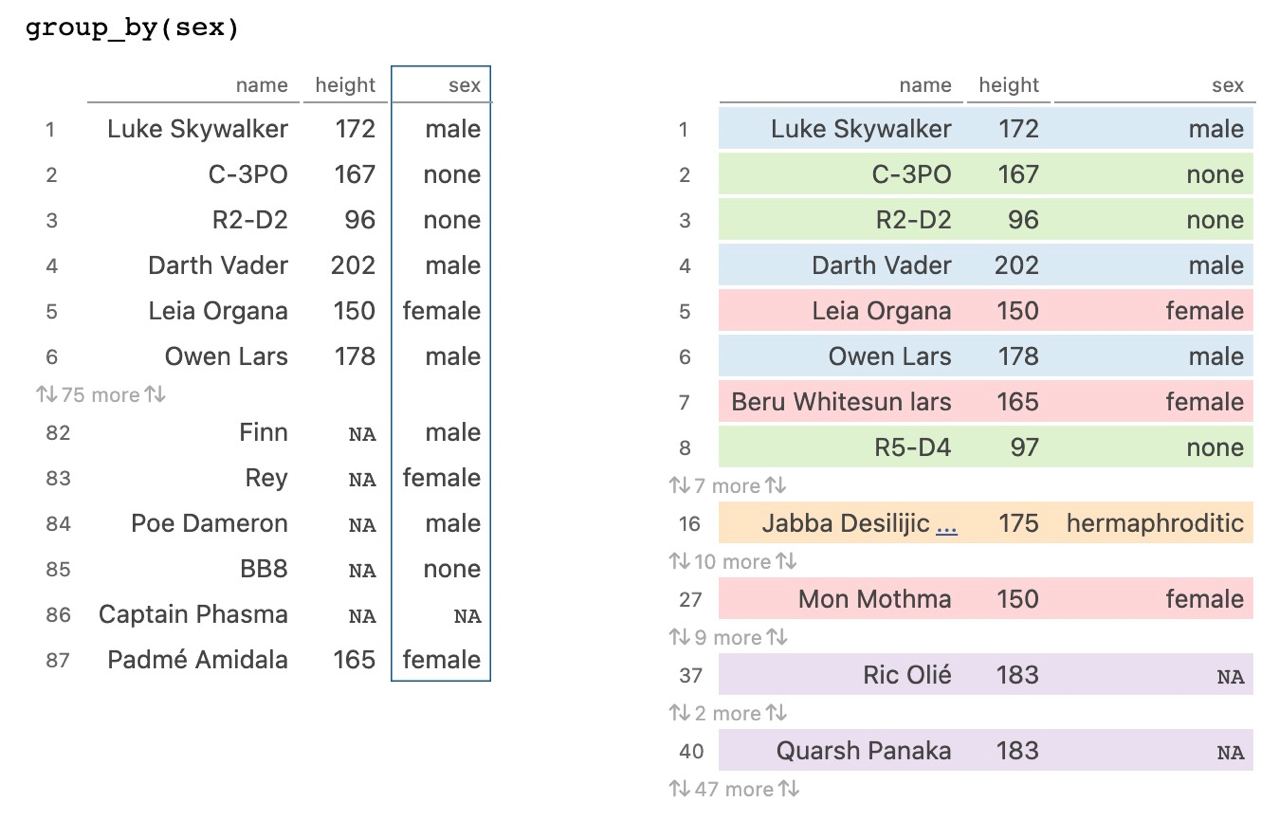
Agrupar: group_by()
datos |>agrupar(var1, var2) |>accion() |>desagrupar()
Cuando apliquemos group_by() es importante entender que NO MODIFICA los datos, sino que nos crea una variable de grupo (subtablas por cada grupo) que modificará las acciones futuras: las operaciones se aplicarán a cada subtabla por separado
Por ejemplo, imaginemos que queremos extraer el personaje más alto con slice_max().
starwars |>slice_max(height)
# A tibble: 1 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Yarael P… 264 NA none white yellow NA male mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Agrupar: group_by()
datos |>agrupar(var1, var2) |>accion() |>desagrupar()
# A tibble: 6 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Taun We 213 NA none grey black NA fema… femin…
2 Jabba De… 175 1358 <NA> green-tan… orange 600 herm… mascu…
3 Yarael P… 264 NA none white yellow NA male mascu…
4 IG-88 200 140 none metal red 15 none mascu…
5 Ric Olié 183 NA brown fair blue NA <NA> <NA>
6 Quarsh P… 183 NA black dark brown 62 <NA> <NA>
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Agrupar: group_by()
datos |>agrupar(var1, var2) |>accion() |>desagrupar()
Recuerda siempre hacer ungroup para eliminar la variable de grupo creada
En la nueva versión de {dplyr} ahora se permite incluir la variable de grupo en la llamada a muchas funciones con el argumento by = ... o .by = ...
starwars |>slice_max(height, by = sex)
# A tibble: 6 × 6
name height mass hair_color skin_color eye_color
<chr> <int> <dbl> <chr> <chr> <chr>
1 Yarael Poof 264 NA none white yellow
2 IG-88 200 140 none metal red
3 Taun We 213 NA none grey black
4 Jabba Desilijic Tiure 175 1358 <NA> green-tan, brown orange
5 Ric Olié 183 NA brown fair blue
6 Quarsh Panaka 183 NA black dark brown
Fila-a-fila: rowwise()
Una opción muy útil usada antes de una operación también es rowwise(): toda operación que venga después se aplicará en cada fila por separado. Por ejemplo, vamos a definir un conjunto dummy de notas.
Si aplicamos la media directamente el valor será idéntico ya que nos ha hecho la media global, pero nos gustaría sacar una media por registro. Para eso usaremos rowwise()
Fíjate que mutate() devuelve tantas filas como registros originales, mientras que con summarise() calcula un nuevo dataset de resumen, solo incluyendo aquello que esté indicado.
Resumir: summarise()
datos |>resumir()
starwars |>summarise()
Si además esto lo combinamos con la agrupación de group_by() o .by = ..., en pocas líneas de código puedes obtener estadísticas desagreagadas
Warning: Returning more (or less) than 1 row per `summarise()` group was deprecated in
dplyr 1.1.0.
ℹ Please use `reframe()` instead.
ℹ When switching from `summarise()` to `reframe()`, remember that `reframe()`
always returns an ungrouped data frame and adjust accordingly.
📝 Calcula cuántos personajes hay de cada especie, ordenados de más a menor frecuencia.
Código
starwars |>count(species, sort =TRUE)
📝 Tras eliminar ausentes en las variables de peso y estatura, añade una nueva variable que nos calcule el IMC de cada personaje, y determina el IMC medio de nuestros personajes desagregada por sexo
El paquete {readr} (ya en {tidyverse}) nos permite realizar una carga más ágil y más inteligente que el read.csv() de base (lo importa a un tibble e interpreta bien el tipo de cada variable, incluso fechas)
# A tibble: 3,753 × 59
type_survey date_elec id_pollster pollster media field_date_from
<chr> <date> <chr> <chr> <chr> <date>
1 national 1982-10-28 pollster-1 PSOE <NA> 1982-10-28
2 national 1982-10-28 pollster-2 IDEAL <NA> 1982-10-28
3 national 1982-10-28 pollster-3 SOFEMASA EL PAÍS 1982-10-16
4 national 1982-10-28 pollster-4 GRUPO 16 GRUPO 16 1982-10-09
5 national 1982-10-28 pollster-3 SOFEMASA EL PAÍS 1982-10-01
6 national 1982-10-28 pollster-4 GRUPO 16 GRUPO 16 1982-09-25
7 national 1982-10-28 pollster-3 SOFEMASA EL PAÍS 1982-09-24
8 national 1982-10-28 pollster-5 AP <NA> 1982-09-27
9 national 1982-10-28 pollster-6 GALLUP <NA> 1982-09-06
10 national 1982-10-28 pollster-4 GRUPO 16 GRUPO 16 1982-09-05
# ℹ 3,743 more rows
# ℹ 53 more variables: field_date_to <date>, exit_poll <lgl>, size <dbl>,
# turnout <dbl>, UCD <dbl>, PSOE <dbl>, PCE <dbl>, AP <dbl>, CIU <dbl>,
# PA <dbl>, `EAJ-PNV` <dbl>, HB <dbl>, ERC <dbl>, EE <dbl>, CDS <dbl>,
# FN <dbl>, PAD <dbl>, PRD <dbl>, MUC <dbl>, IU <dbl>, CG <dbl>, PAR <dbl>,
# AIC <dbl>, UV <dbl>, EA <dbl>, PP <dbl>, LV <dbl>, ARM <dbl>, PDP <dbl>,
# CC <dbl>, PAP <dbl>, BNG <dbl>, ICV <dbl>, EH <dbl>, UPYD <dbl>, …
Caso real: datos de encuestas
Lo primero que debes hacer es visualizar con View() la tabla para entenderla
Primera tarea: crea una variable llamada id_survey que nos permita identificar a cada encuesta. ¿Qué podríamos concatenar?
Código
encuestas <- encuestas |># Creamos un id con type_survey-date_elec-id_pollster# con .before la ponemos delante de everything(), de todo (1ª col)mutate(id_survey =glue("{type_survey}-{date_elec}-{id_pollster}"),.before =everything())
Caso real: datos de encuestas
Segunda tarea: usando la variable id_survey creada elimina duplicados.
Código
encuestas <- encuestas |># Eliminamos duplicados por id_survey, pero mantenemos todas las# columnas con .keep_all = TRUEdistinct(id_survey, .keep_all =TRUE)
Caso real: datos de encuestas
Tercera tarea: tenemos una variable media que representa el medio en el que se publicó o encargo la encuesta. Elimina dicha variable, así como el tipo de encuesta y el id de la encuestadora
Código
encuestas <- encuestas |># Eliminamos las columnas pedidas con un -# las concateno para usar solo un - para todasselect(-c(type_survey, id_pollster, media))
Caso real: datos de encuestas
Cuarta tarea: quédate solo con las encuestas cuyo tamaño muestral conozcamos y que no sean encuestas a pie de urna. Elimina esta última variable.
Código
encuestas <- encuestas |># eliminar ausentesdrop_na(size) |># Filtramos encuestas (registros) a pie de urna (aquellas que exit_poll == FALSE)filter(!exit_poll) |># Quitamos la variable pie de urnaselect(-exit_poll)
Caso real: datos de encuestas
Quinta tarea: convierte el dataset en tidydata. ¿Qué falla? ¿Cómo arreglarlo? Reminder: no quremos ausentes.
Sexta tarea: calcula el número de días que la encuesta ha hecho trabajo de campo, y coloca dicha columna tras el nombre de la encuestadora. Tras ello elimina aquellas encuestas que tengan 0 días de trabajo de campo.
Código
encuestas <- encuestas |># Calculamos los días de campo como la diferencia de fechas # con as.numeric() convertimos la dif. de fechas a un númeromutate(n_dias_campo =as.numeric(field_date_to - field_date_from),.after = pollster) |># Solo aquellas cuyo trabajo de campo haya durado 1 día o másfilter(n_dias_campo >0)
Caso real: datos de encuestas
Séptima tarea: calcula el número de días que faltan hasta las elecciones desde que la encuesta cerro el trabajo de campo y coloca dicha variable tras n_dias_campo. Tras ello elimina las fechas de inicio y fin de trabajo de campo de la manera más eficiente posible
Código
encuestas <- encuestas |># Calculamos los días que faltan a las elecciones# con as.numeric() convertimos la dif. de fechas a un númeromutate(n_dias_elec =as.numeric(date_elec - field_date_to),.after = n_dias_campo) |># Eliminamos ya las fechas de campo que no necesitamosselect(-contains("field"))
Caso real: datos de encuestas
Octava tarea: elimina encuestas que se hayan cerrado dentro de la ventana temporal en la que está prohibido la publicación de encuestas (no se deberían usar para predecir ya que «no se conocen»)
Código
encuestas <- encuestas |># Solo con encuestas antes del baneo electoralfilter(n_dias_elec >15)
Caso real: datos de encuestas
Novena tarea: obtén, por cada elección, la media de las encuestas de cada partido
Código
encuestas |># Resumen: media de voto por fecha y partidosummarise(media_voto =mean(est_voto),.by =c("date_elec", "partido"))
# A tibble: 137 × 3
date_elec partido media_voto
<date> <chr> <dbl>
1 1986-06-22 PSOE 45.7
2 1986-06-22 AP 22.8
3 1986-06-22 CIU 3.9
4 1986-06-22 EAJ-PNV 1.82
5 1986-06-22 HB 1.27
6 1986-06-22 EE 0.5
7 1986-06-22 CDS 4.33
8 1986-06-22 PRD 4
9 1986-06-22 MUC 2.8
10 1986-06-22 IU 5.5
# ℹ 127 more rows
Caso real: datos de encuestas
Décima tarea: realiza lo mismo que la tarea anterior pero solo para las encuestas de los 60 días previos a las elecciones. Ordena la salida de reciente a antiguo
Código
encuestas |># Filtramos ventana de 60 díasfilter(n_dias_elec <=60) |># Media de est_voto por fecha y partidosummarise(media_voto =mean(est_voto),.by =c("date_elec", "partido")) |># Ordenar de mayor a menorarrange(desc(date_elec))
Undécima tarea: del dataset generado en el anterior ejercicio, obtén el primer y el segundo con mayor estimación de voto (en promedio)
Código
encuestas |># Filtramos ventana de 60 díasfilter(n_dias_elec <=60) |># Media de est_voto por fecha y partidosummarise(media_voto =mean(est_voto),.by =c("date_elec", "partido")) |># Ordenar de mayor a menor por fechaarrange(desc(date_elec)) |># extraemos los dos con más est de voto (por cada fecha)slice_max(media_voto, n =2, by = date_elec)
Trabajar ordenados, publicar resultados, replicabilidad de lo realizado
¿Qué es Github?
GitHub es la plataforma colaborativa más conocida basada en el sistema de control de versiones Git
¿Qué es Git? Git es un sistema de control de versiones: una especie de Dropbox para facilitar la programación colaborativa entre un grupo de personas, permitiendo llevar la trazabilidad de los cambios realizados.
¿Qué es Github? Nuestra plataforma/interfaz para ejecutar el control de versiones: nos servirá no solo para trabajar colaborativamente sino para hacer transparente el proceso de construcción de nuestros proyectos de código.
Importante
Desde el 4 de junio de 2018 Github es de Microsoft (ergo el código que subas también)
Visión general
Tras hacernos una cuenta en Github, arriba a la derecha tendremos un círculo, y haciendo click en Your Profile, veremos algo similar a esto
Edit profile: nos permite añadir una descripción y foto de perfil.
Overview: en ese panel de cuadrados se visualizará nuestra actividad a lo largo del tiempo.
Repositories: el códugo será subido a repositorios, el equivalente a nuestras carpetas compartidas en Dropbox.
Primer uso: consumidor
Antes de aprender como crear repositorios, Github también nos servirá para
Acceder a código ajeno
Proponer mejoras a otros usuarios, e incluso proponer correcciones de error que detectemos de software que usemos
Instalar paquetes de R. En muchas ocasiones los desarrolladores de paquetes suben las actualizaciones a CRAN cada cierto tiempo, y en otras el software no es suficientemente «amplio» para poder ser subido como paquete.
El código de paquetes que no tengamos subido en CRAN podremos instalarlo como código desde Github
Instalar desde Github
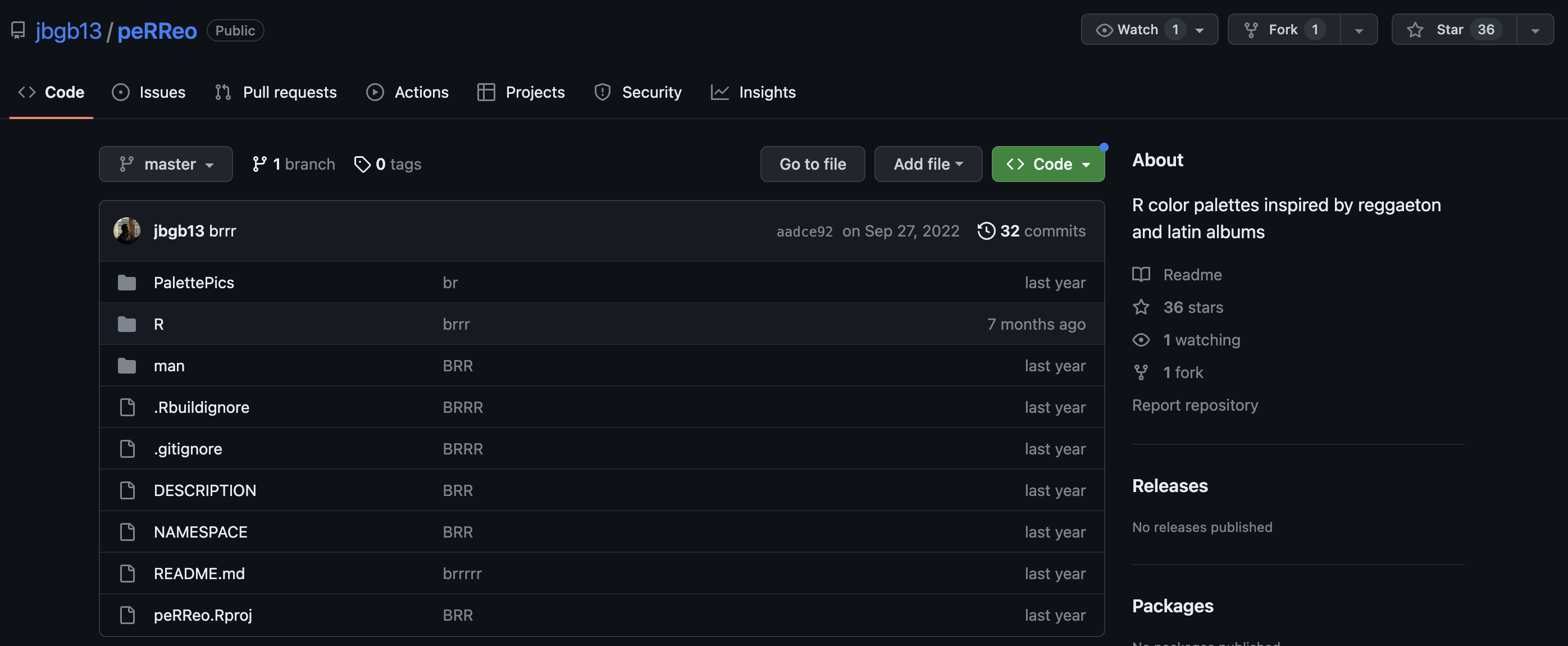
Por ejemplo, vamos a instalar un paquete llamado {peRReo}, cuya única función es darnos paletas de colores basadas en portadas de álbumes de música urbana
Para ello antes tendremos que instalar un conjunto de paquetes para desarrolladores llamado {devtools}, que nos permitirá la instalación desde Github
install.packages("devtools")
Instalar desde Github
Las instrucciones de instalación suelen venir detalladas en la portada del repositorio
En la mayoría de casos bastará con la función install_github() (del paquete que acabamos de instalar), pasándole como argumento la ruta del repositorio (sin “github.com/”).
devtools::install_github("jbgb13/peRReo")
Ya puedes perrear con ggplot ;)
Descargar desde Github
La mayoría de veces lo que subamos no será un paquete de R como tal sino que subiremos un código más o menos organizado y comentado. En ese caso podremos descargar el repo entero haciendo click Code y luego Download ZIP.
Por ejemplo, vamos a descargarnos los scripts de dataviz que han subido desde el Centre d’Estudis d’Opinió
Ideal
¿Lo ideal en caso de RTVE? Tener dos tipos de repositorios
Una colección de repositorios públicos (producción) donde hacer transparente el código y los datos (ya validados), coordinado por un nº reducido de personas.
Una colección de repositorios privados (desarrollo) donde esté todo el equipo colaborando y donde se haga el trabajo del día, con trazabilidad interna.
Nuestro primer repositorio
Vamos a crear nuestro primero repositorio que servirá además como carta de presentación de nuestro perfil en Github.
Repositories: hacemos click en las pestaña de Repositories.
New: hacemos click en el botón verde New para crear un nuevo repositorio
Nuestro primer repositorio
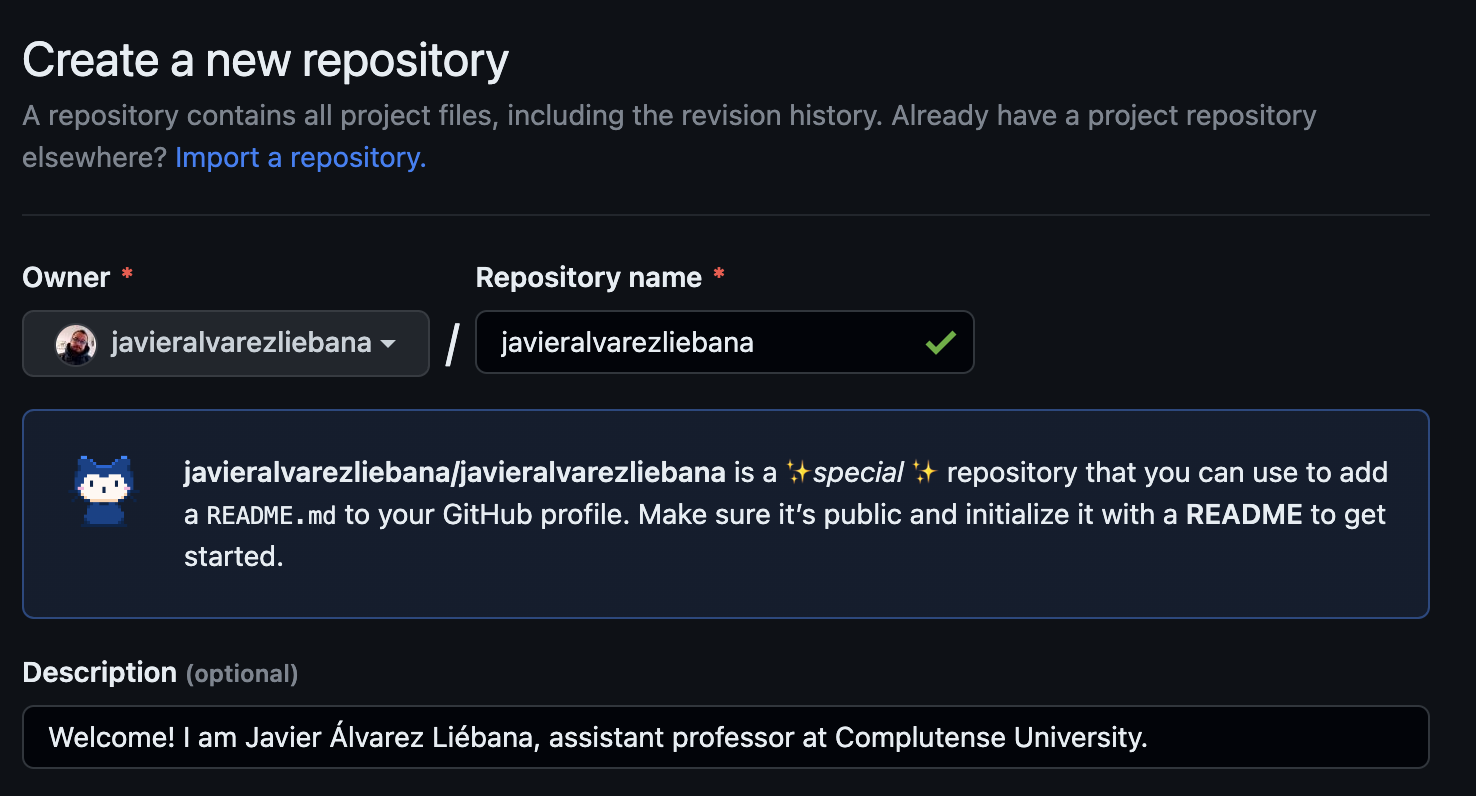
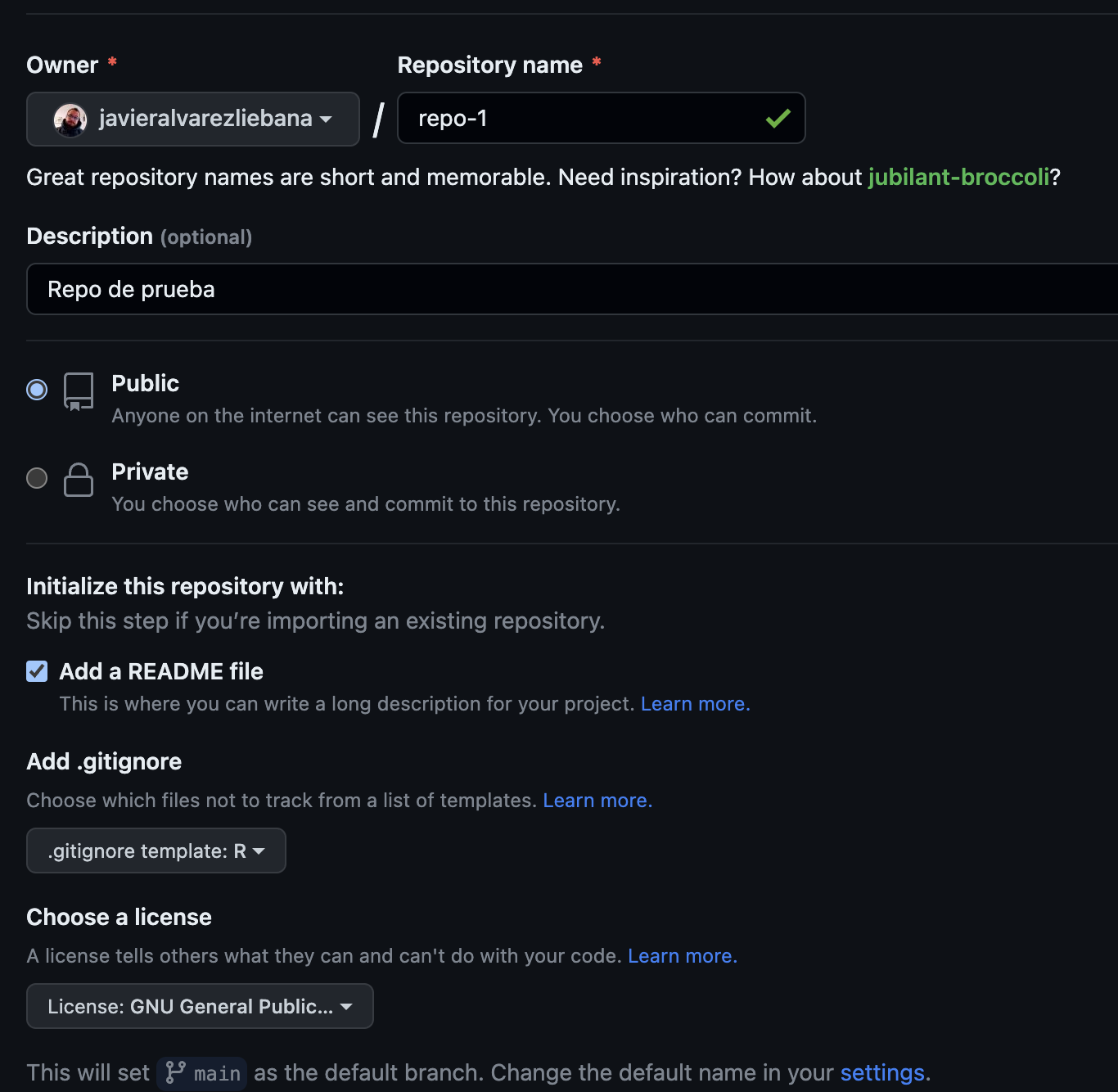
Repository name: el nombre del repositorio. En este caso vamos a crear un repositorio muy concreto: el nombre debe coincidir exactamente con tu nombre de usuario
Description: descripción de tu repositorio. En este caso será un repo de presentación.
Nuestro primer repositorio
Public vs private: con cada repositorio tendremos la opción de hacer el repositorio
público: todos los usuarios podrán ver el código así cómo la trazabilidad de su desarrollo (qué se añade y cuándo). Es para mí la opción más recomendable cuando quieres darle visibilidad y transparencia a tu trabajo
privado: solo tendrán acceso al repositorio aquellos usuarios a los que se lo permitas. No se podrá visualizar ni instalar nada de él fuera de Github.
En este caso concreto, dado que será un repositorio de presentación, lo haremos público.
Nuestro primer repositorio
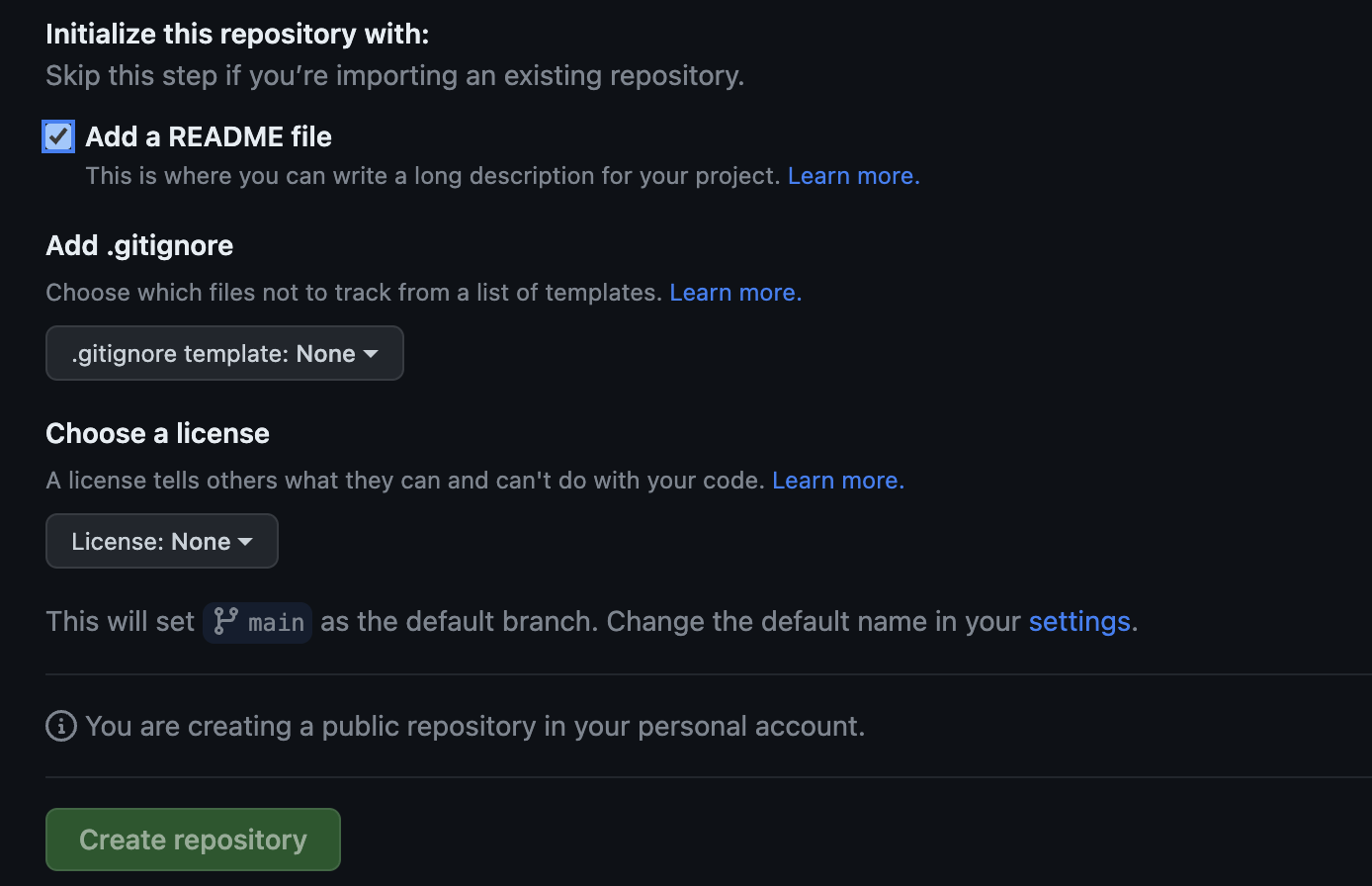
Add a README file: un README file será el archivo donde incluiremos las instrucciones y detalles de uso a los demás (en el caso de {peRReo} era el archivo que contenía los detalles de instalación)
De momento ignoraremos los demás campos para este primer repositorio.
Nuestro primer repositorio
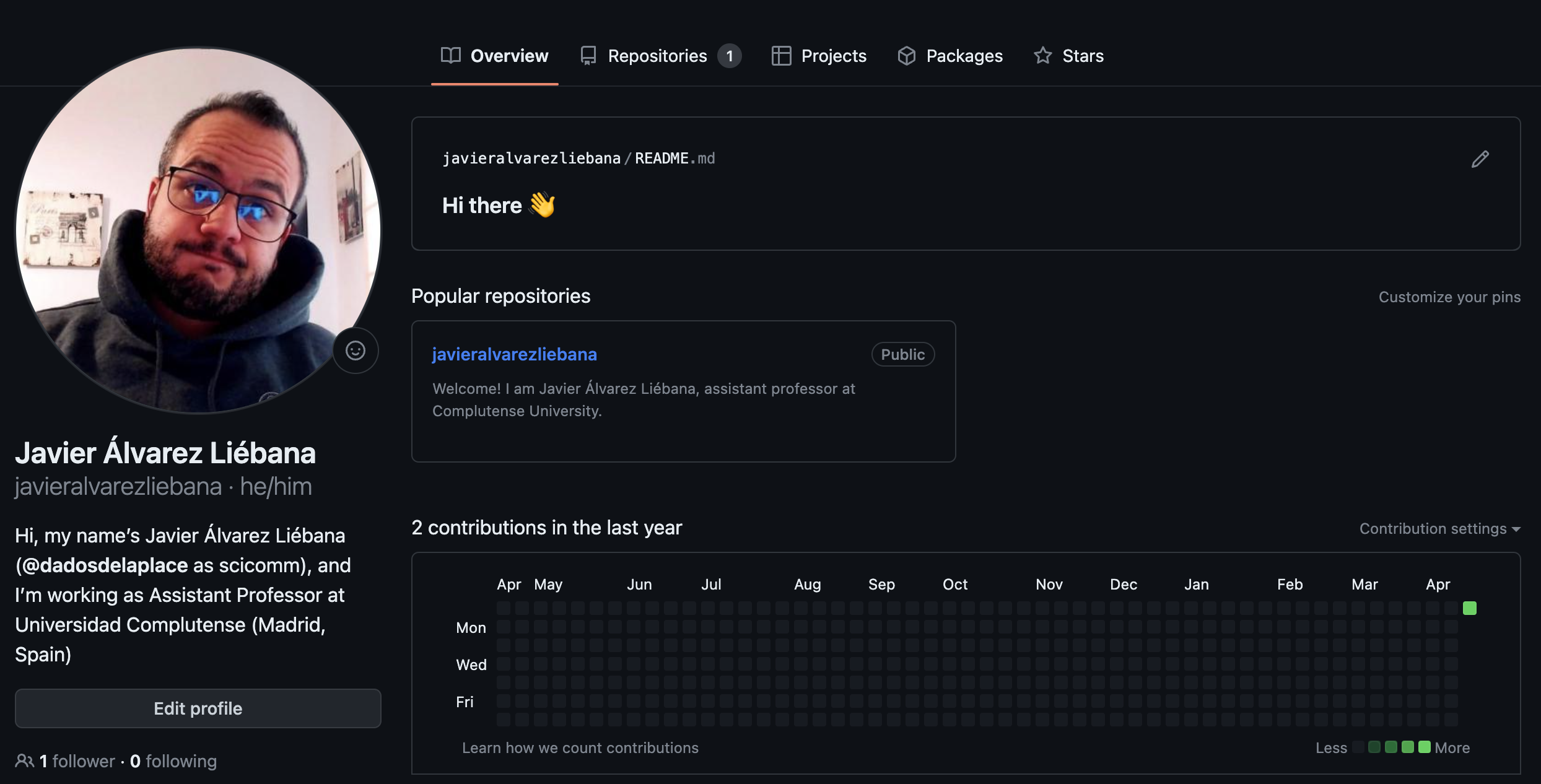
Por defecto Github asume que este repositorio, con el mismo nombre que nuestro usuario será el repositorio que querremos que se presente de inicio cuando alguien entra en nuestro perfil, y será el repositorio donde [incluir en el README.md] una presentación de nosotros y un índice de tu trabajo (si quieres).
Nuestro primer repositorio
Fíjate que ahora en nuestra portada tenemos dicho README.md que podemos personalizar a nuestro gusto haciendo uso de html y markdown.
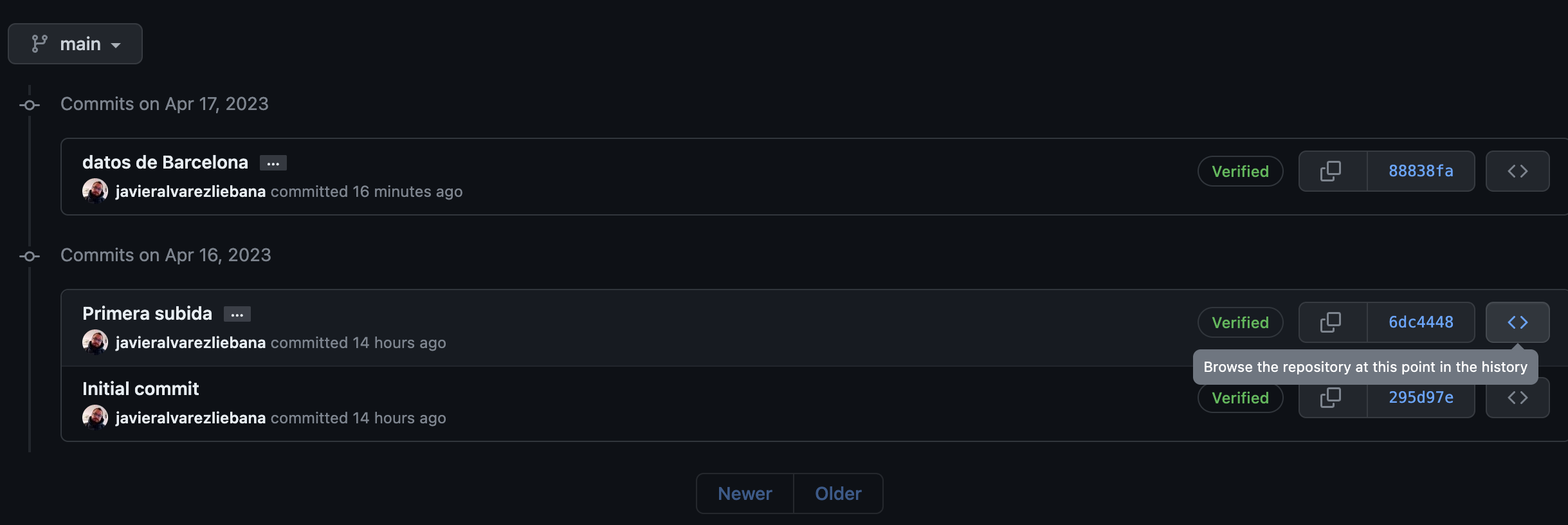
Una vez que tenemos nuestro README de presentación (recuerda que puedes personalizar a tu gusto con html y markdown) vamos a crear un repositorio de código.
Si ya era importante trabajar con proyectos en RStudio, cuando lo combinamos con Github es aún más crucial que creemos un proyecto antes de subir el código, así que vamos a crear uno de prueba que se llame repo-github-1.
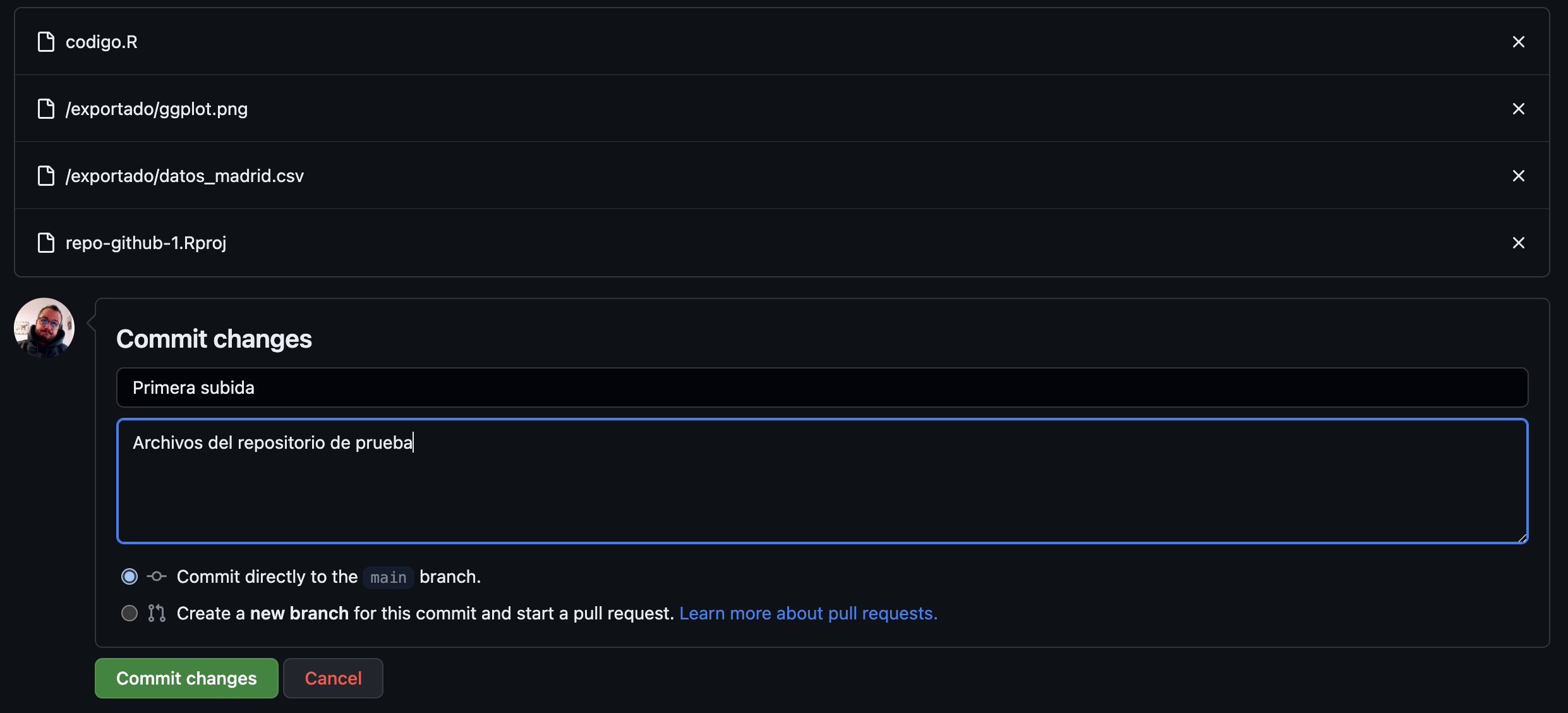
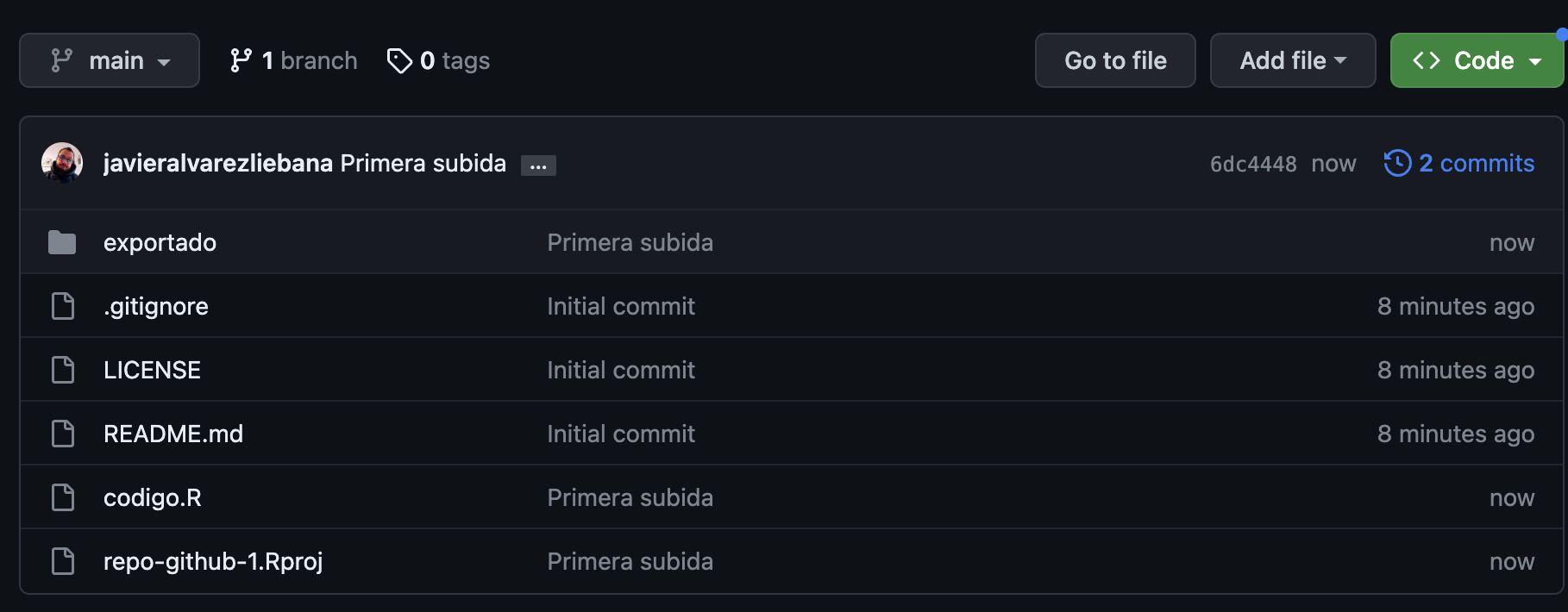
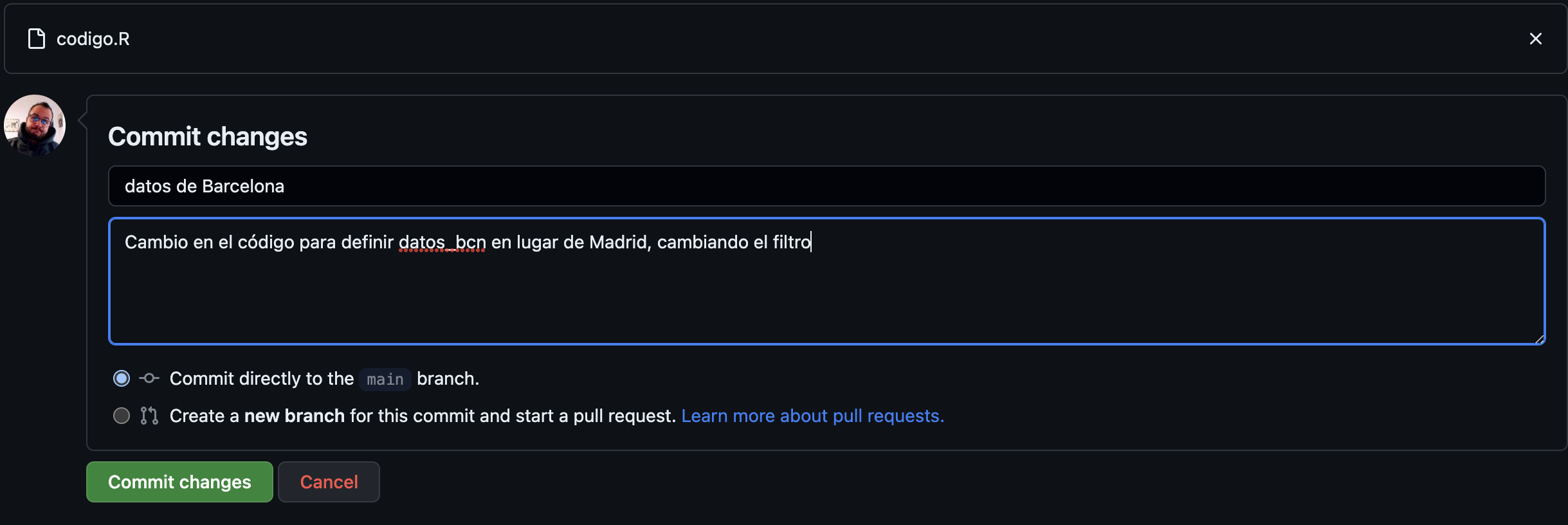
En dicho proyecto vamos a crear un script (en mi caso llamado codigo.R) en el que deberás hacer los siguientes pasos:
Repo de código
Carga directamente desde la página del ISCIII el archivo llamado casos_hosp_uci_def_sexo_edad_provres.csv
Código
# Carga de datos desde ISCIIIdatos_covid <-read_csv(file ="https://cnecovid.isciii.es/covid19/resources/casos_hosp_uci_def_sexo_edad_provres.csv")
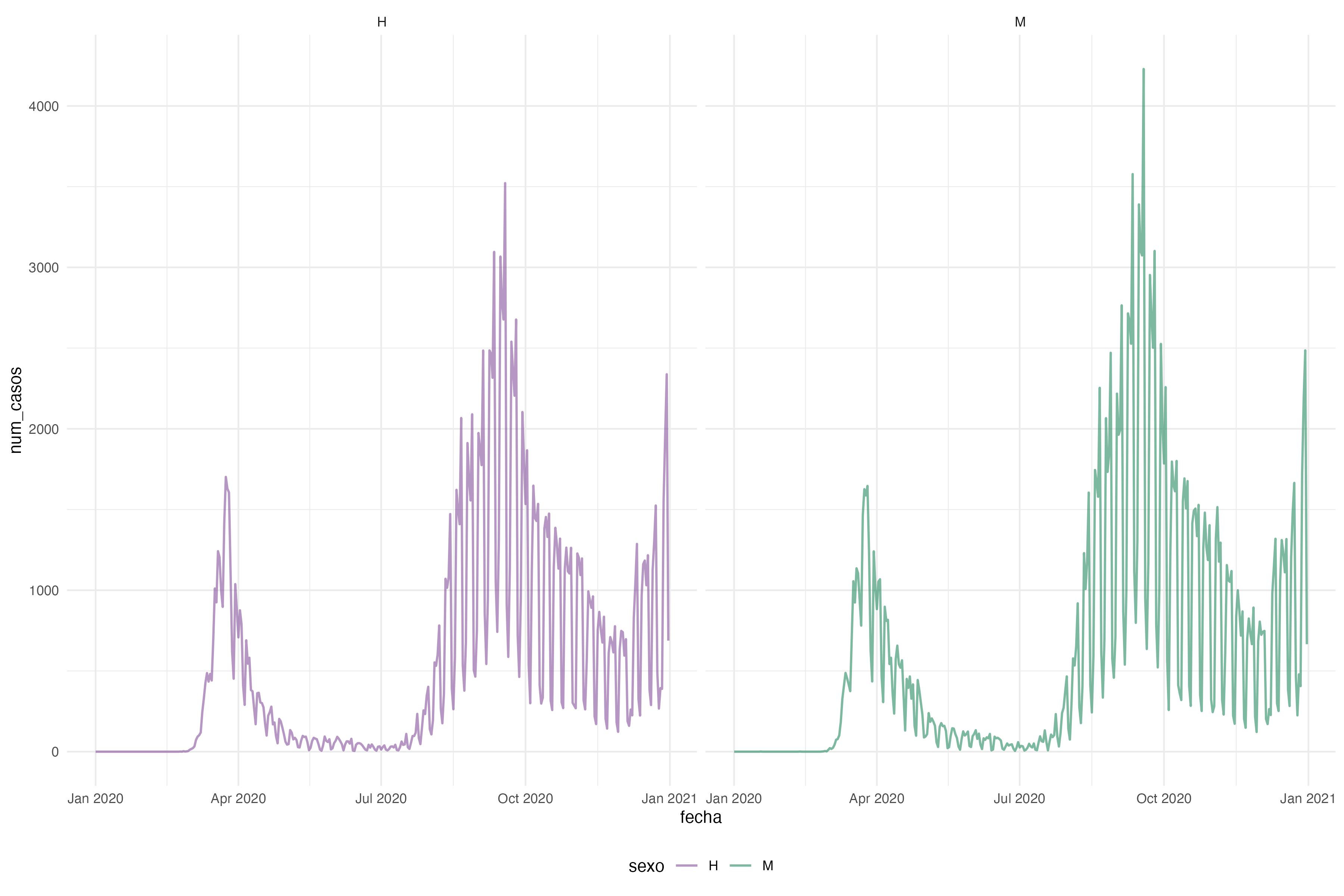
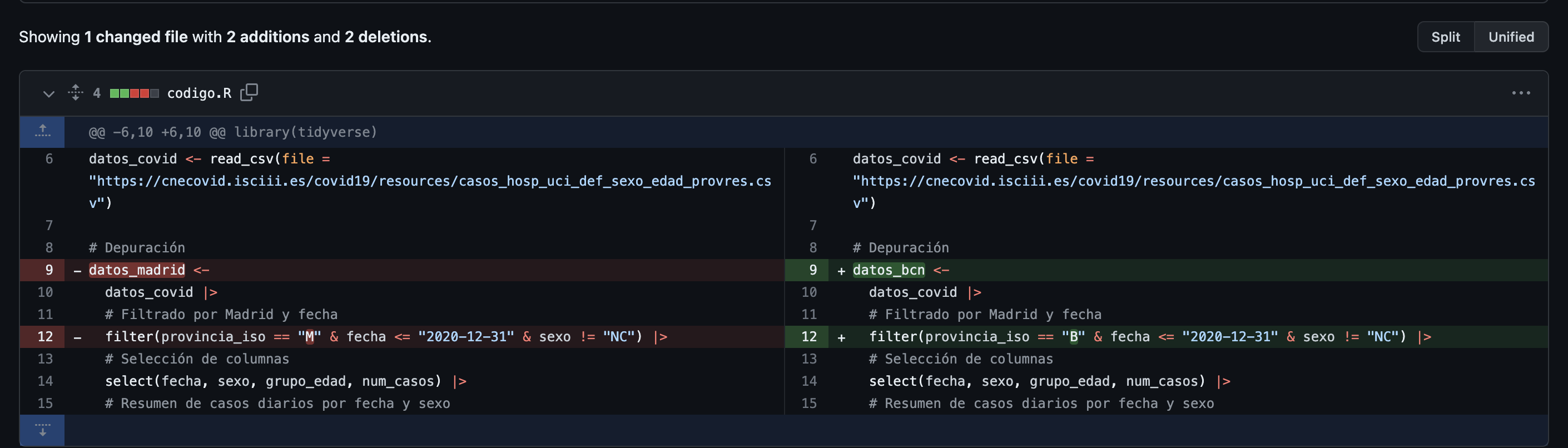
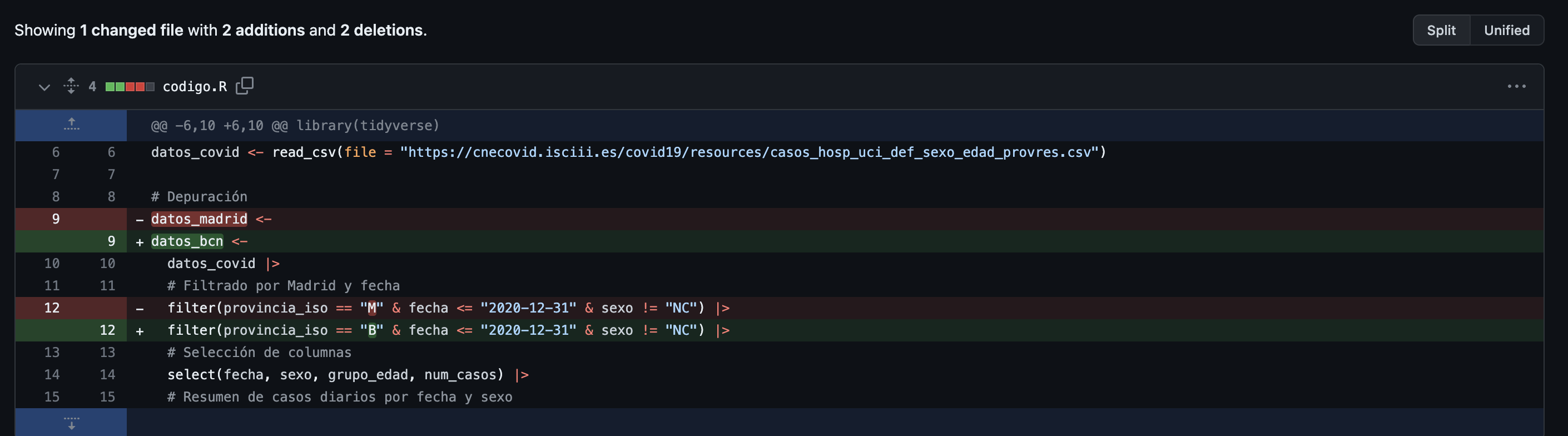
Filtra datos de Madrid ("M"), de 2020 y con sexo conocido (hombre/mujer). Tras ello quédate con las columnas fecha, sexo, grupo_edad, num_casos (ese orden). Por último obtén la suma de casos diarios por fecha y sexo.
Código
# Depuracióndatos_madrid <- datos_covid |># Filtrado por Madrid y fechafilter(provincia_iso =="M"& fecha <="2020-12-31"& sexo !="NC") |># Selección de columnasselect(provincia_iso:fecha, num_casos) |># Resumen de casos diarios por fecha y sexosummarise(num_casos =sum(num_casos), .by =c(fecha, sexo))
Repo de código
Exporta el dataset a un csv en una carpeta que se llame exportado
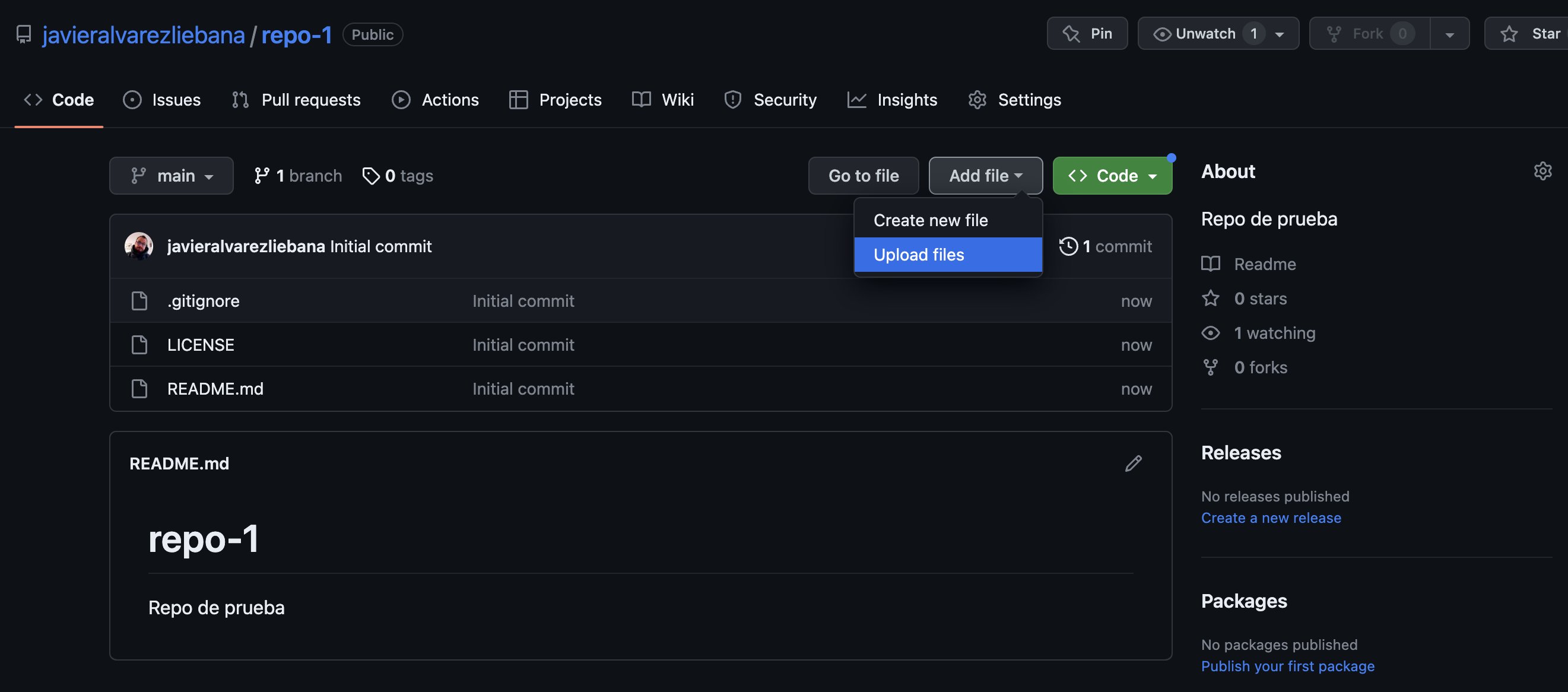
¿Cómo subimos el proyecto? Vamos de nuevo a crear un proyecto de cero. Antes no hemos hablado de dos campos importantes:
Add .gitignore nos permitirá seleccionar el lenguaje en el que estará nuestro proyecto para que Github lo entienda al sincronizar (y no actualice cosas que no deba).
Choose a license nos permitirá seleccionar la licencia que determinará las condiciones en las que otros podrán reusar tu código.
Repo de código
Si te fijas traer crearlo tenemos solo 3 archivos: el de licencia, el .gitignore y el readme.md (donde deberíamos escribir una guía de uso de lo que hayamos subido)
Para subir los archivos vamos a clickar en Add file < Upload File y arrastraremos TODOS los archivos de la carpeta de nuestro proyecto.
Repo de código
Tras la subida de archivos tendremos un cuadro llamado Commit changes
Un commit es una modificación del repositorio con algo que se añade/elimine/modifique, y dicho cuadro es recomendable usarlo para resumir en qué consiste la modificación, de manera que quede trazado el cambio.
Repo de código
Haciendo click en el reloj donde indica el número de commits accedemos al histórico de commits (cambios) con hora, día, autor, comentarios, etc.
Repo de código
Vamos a realizar un cambio en nuestro código: en tu código local (local –> tu ordenador), en lugar de filtrar por Madrid haz el filtro por Barcelona, guarda el código y sube en el repositorio el nuevo archivo (con el mismo nombre, Github hará la sobrescritura)
datos_bcn <- datos_covid |>filter(provincia_iso =="B"& fecha <="2020-12-31"& sexo !="NC") |>select(fecha, sexo, grupo_edad, num_casos) |>summarise(num_casos =sum(num_casos), .by =c(fecha, sexo))
Consulta de commits
Si ahora consultamos el commit, al lado hay un número que lo identifica, y clickando en él nos resume los cambios: no solo almacena todas las versiones pasadas sino que además nos muestra las diferencias entre los archivos cambiados
Trazabilidad de cambios
Tenemos dos modos de visualización de los cambios: el modo split nos muestra el antiguo y el nuevo, con las inclusiones en verde y lo que ya no está en rojo; y el modo unified nos muestra todo en un mismo documento.
Recuperación de commits
Github nos permite incluso recuperar una versión del pasado de nuestro repositorio, haciendo click en el tercer icono del commit.
Recuperación de commits
Si te fijas ahora al lado de 1 branch tenemos un menú desplegable en el que antes ponía main y ahora un número identificador del commit. Ya hablaremos de la idea de rama (branch)
Repo con rmd/qmd
Vamos a poner en práctica lo aprendido:
Crea un nuevo repositorio en Github (llamado repo-github-2) donde habrá alojado con proyecto de R.
Crea un proyecto en RStudio que se llame (por ejemplo) proyecto-qmd
Una vez dentro del proyecto en RStudio haz click en File < New File < Quarto Document
Deberás tener un documento similar a este: un quarto markdown (.qmd), un documento que nos permitirá incluir markdown + código (puede ser R o puede ser Observable, D3, etc).
Repo con rmd/qmd
Este formato es ideal para:
Trabajar en equipo construyendo el borrador de una pieza.
Tomar apuntes o informes para uno mismo.
Presentar tu trabajo a tus compañeros.
Si te fijas ahora nuestro repositorio tiene un archivo con formato .html…es decir…
¡Es una web!
Github pages
¿Cómo convertir nuestro repositorio en una web?
Haz click en Settings
Ve al apartado Pages
En el subapartado branch selecciona la única rama que tenemos ahora (main)
Selecciona la carpeta donde tengas el .html (en web complejas estará como en cualquier web en docs, en algo simple estará en la ruta raiz del repositorio)
Haz click en Save
Github pages
Si te fijas en la parte superior del repositorio ahora tenemos un icono naranja, que nos indica que la web está en proceso de ser desplegada (deploy)
Github pages
Pasados unos segundos (dependiendo del tamaño de la web y tu conexión a internet) ese icono pasará a ser un check verde: habemus web
El link de la web por defecto será {nombre_usuario}.github.io/{nombre_repo}
Github pages
¡Un momento! Ahora mismo nuestra web no nos está mostrando nuestro .qmd, sino por defecto el README.md.
Para que Github entienda que queremos visualizar ese .html que hemos generado a partir del .qmd vamos en nuestro proyecto local a borrar todo lo que no sea nuestro archivo .Rproj y nuestro archivo .qmd, y vamos a cambiar el nombre a este último llamándolo index.qmd, y volvemos a compilarlo para generar un index.html
Github pages
Vamos a subir a Github ese nuevo proyecto con el cambio de nombre (llamado repo-github-3) para ver luego las diferencias entre uno y otro
Github pages
Si repetimos el proceso para hacer una Page y esperamos al tick verde…
Si a tu .qmd ya le llamas de inicio index.qmd, automáticamente, al detectar Github un index.html, interpreta que ese archivo index.html es el que define la web (y puedes personalizar añadiendo un archivo css de estilos)
Habemus web simplemente clickando en Pages :)
Repo con diapositivas
Vamos a crear el último repositorio que se llamará repo-diapos, y crear un proyecto en RStudio del mismo nombre (por ejemplo). Una vez creado le daremos a File < New File < Quarto Presentation.
La forma de escribir será igual que un .qmd normal solo que ahora cada diapositiva la separaremos con un --- (usando archivos de estilos podemos personalizar lo que queramos)
Llama al archivo directamente index.qmd, súbelo a Github y con un click en Pages tienes una web con tus diapositivas
Uso de Gitkraken
La forma más sencilla para trabajar de manera colaborativa en Github, y tenerlo sincronizado con nuestro local, es hacer uso de Gitkraken
Una vez dentro clickamos en el icono de la carpeta (Repo Management) y si ya tenemos el repositorio en Github seleccionamos Clone, indicando donde queremos clonar (en nuestro local) y que repositorio de Github queremos clonar.
Uso de Gitkraken
Una vez clonado, la idea es que cada cambio que hagamos en local nos aparecerá en Gitkraken como View changes.
Uso de Gitkraken
Cuando tengas suficientes cambios como para actualizar el repositorio (tampoco tiene sentido actualizar con cada edición), verás algo similar a esto con todos los commits realizados
Podrás decidir cuáles de los commits locales quieres incluir en remoto, bien uno a uno o en Stage all changes (para todos)
Uso de Gitkraken
Tras incluir los commits deberás incluir un título y descripción del commit
Uso de Gitkraken
Tras hacerlo verás que ahora tenemos dos iconos separados en una especie de árbol (¿te acuerdas de la branch o rama?):
Ordenador: la versión del repositorio que tienes en tu ordenador.
Logo: la versión del repositorio que tienes subida en remoto
Uso de Gitkraken
Mientras eso suceda solo tendrás sincronizado tu ordenador con Gitkraken, pero no con Github. Para ello haremos click en Push (con Pull podrás forzar a tener en local lo mismo que en remoto).
Branchs
Como hemos mencionado ya en varias ocasiones, hay un elefante en la habitación que aún no hemos mentado: las ramas o branchs de un repositorio.
Imagina que estáis trabajando varios en un proyecto y teneís una versión que funciona pero que queréis modificar en paralelo a partir del estado actual del repositorio.
Las ramas nos permiten partir de una versión común del repositorio y hacer cambios que no afecten a los demás
Branchs
Para crear una rama a partir del estado actual de repositorio haremos click en Branch y le pondremos un nombre
Una vez creada verás dos iconos y un menú desplegable con las distintas ramas en las que quieres hacer el commit. Imagina que realizas un cambio pero no quieres añadirlo a la rama principal: puedes hacer el commit en tu rama propia en LOCAL (lo harás en la rama activa de tu menú de branchs).
Branchs
La primera vez te pedirá que escribas la rama en REMOTO con la quieres sincronizar tu rama en local. Consejo: ponle el mismo nombre en remoto que en local.
Branchs
Fíjate que ahora tenemos el ordenador y el logo en el mismo sitio. Esto no significa que tengas ambas ramas en tu local, solo que Gitkraken tiene ambas sincronizadas: clickando en cualquiera de ellas, tus archivos en tu ordenador cambiarán.
Pull request
Lo más recomendable es que solo se incorpore de una rama secundaria a la rama principal aquello que está validado por un/a coordinador/a del repositorio, asegurándose que todo funciona correctamente.
Cuando queramos incluirlo haremos click con botón derecho en el icono de la rama secundaria y seleccionamos Start a pull request to origin from...
Una pull request será una petición al responsable de la rama principal para incluir los cambios
Pull request
En el cuadro que no se abre deberemos escribir:
La rama a la que hacer el merge (normalmente la main)
Título y resumen de los cambios
Puedes incluso asignar un revisor entre los colaboradores del repo.
Puedes asignar etiquetas
Pull request
Mientras no se acepte aparecerá un icono de rama y un +1 en Pull Requests
Si somos al mantenedor del repositorio, haciendo click en el menú nos saldrán las ramas que nos quieren hacer hacer merge
Pull request
Al hacer click se abrirá un cuadro de Pull Request para decidir si
Revisar los cambios
Aprobar el merge
Añadir comentarios al que ha solicitado el merge por si queremos solicitar algún cambio antes de ser aprobado
Pull request
Tras revisar todo y aprobarlo clickaremos en Confirm merge, y tras ello podremos decidir si esa rama que era paralela a la principal la queremos eliminar o dejar visible a todos (consejo: dejar visible para tene trazabilidad del proyecto)
Manual de Quarto: el nuevo rmarkdown, más completo y sencillo para elaborar manuales, diapositivas, informes e incluso webs https://quarto.org/docs/guide/

.png)