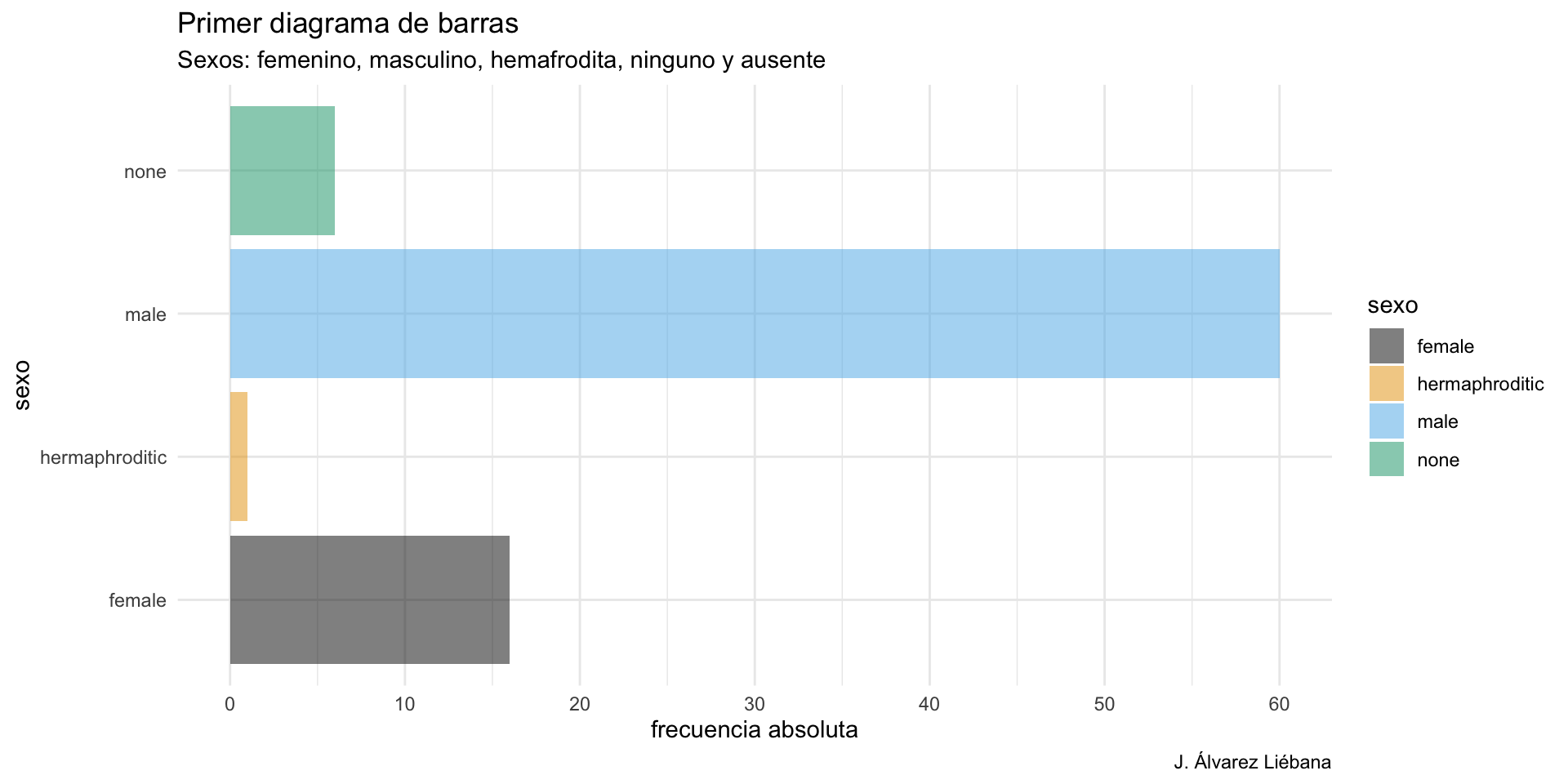
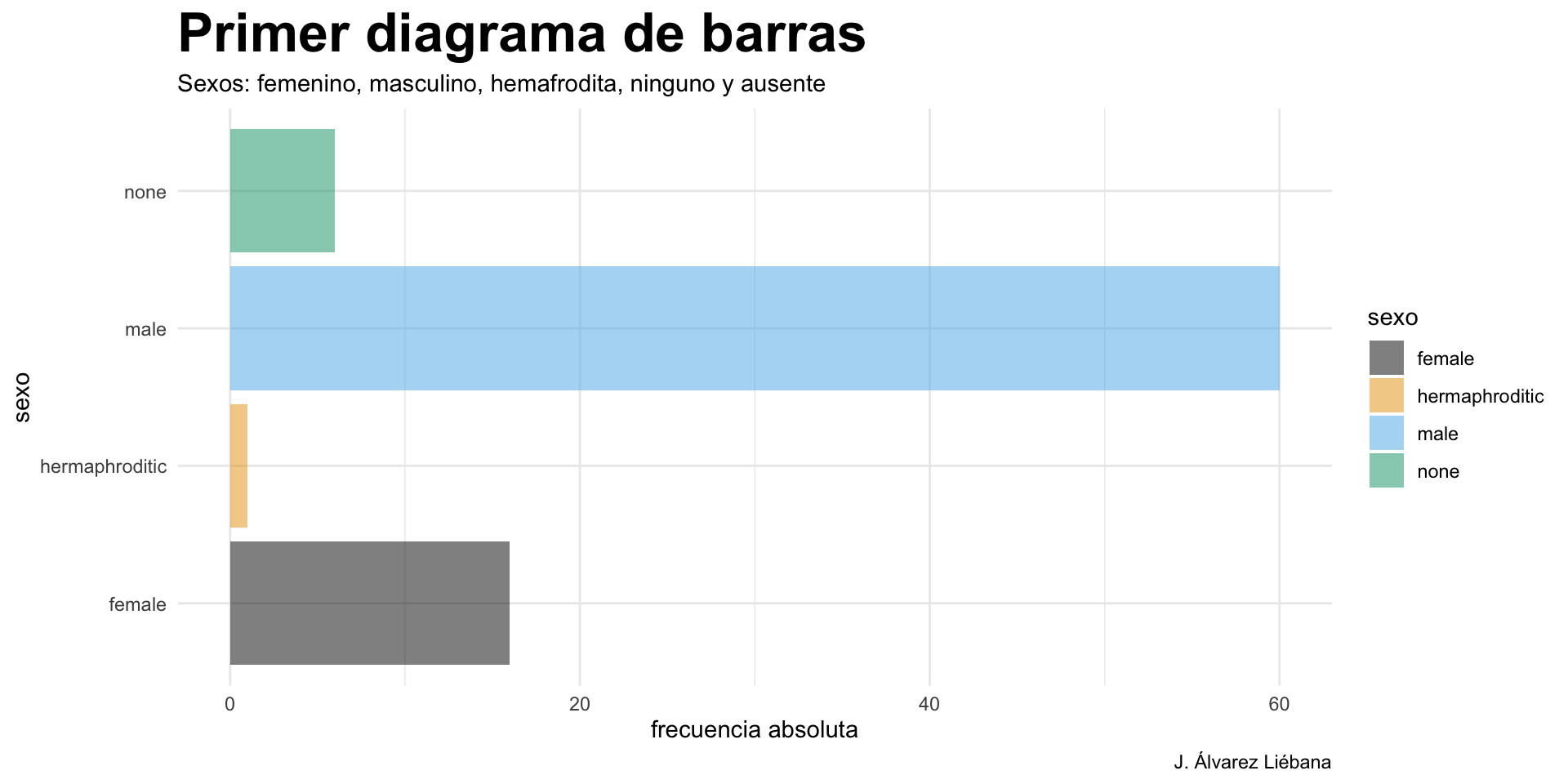
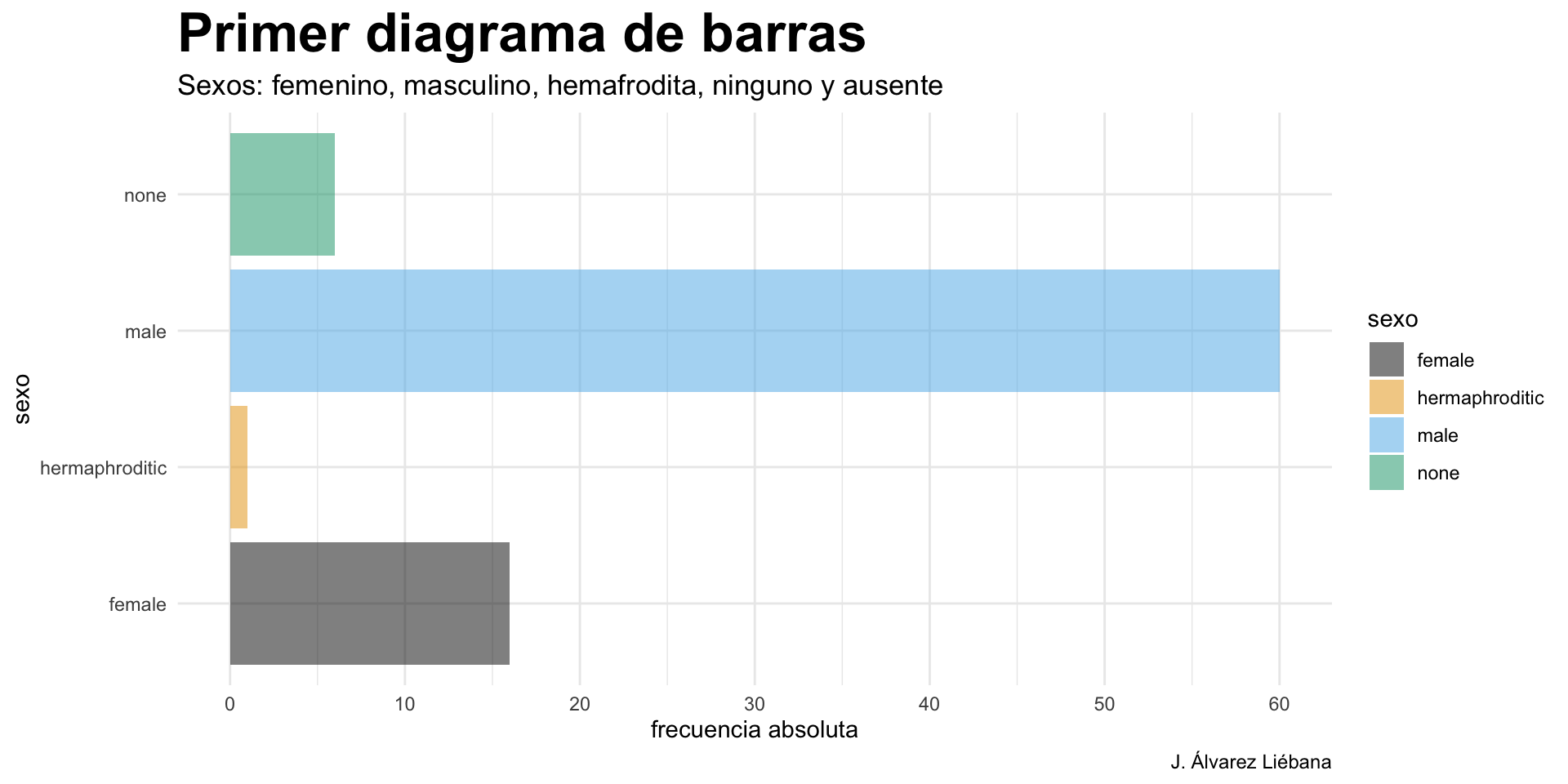
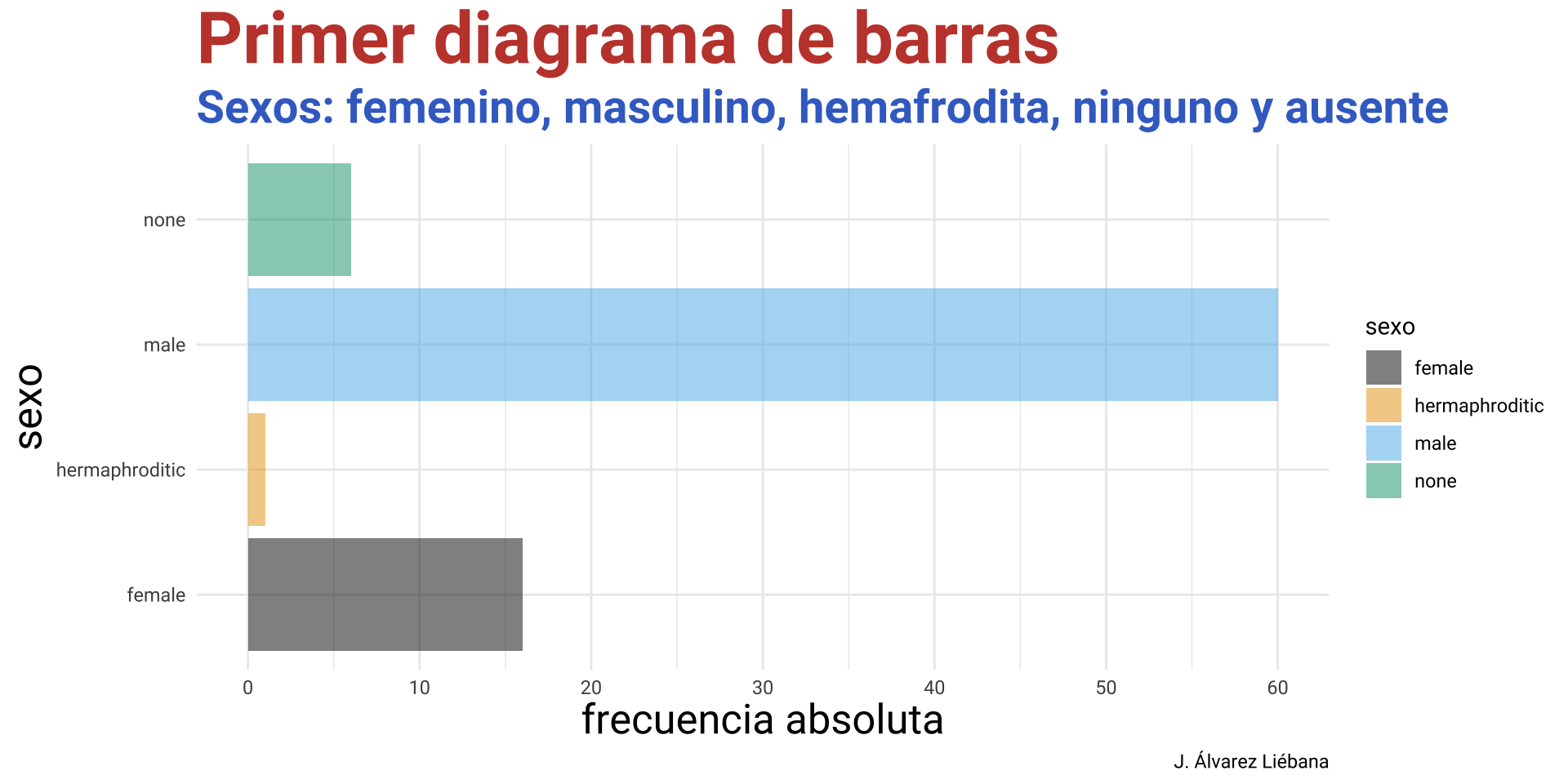
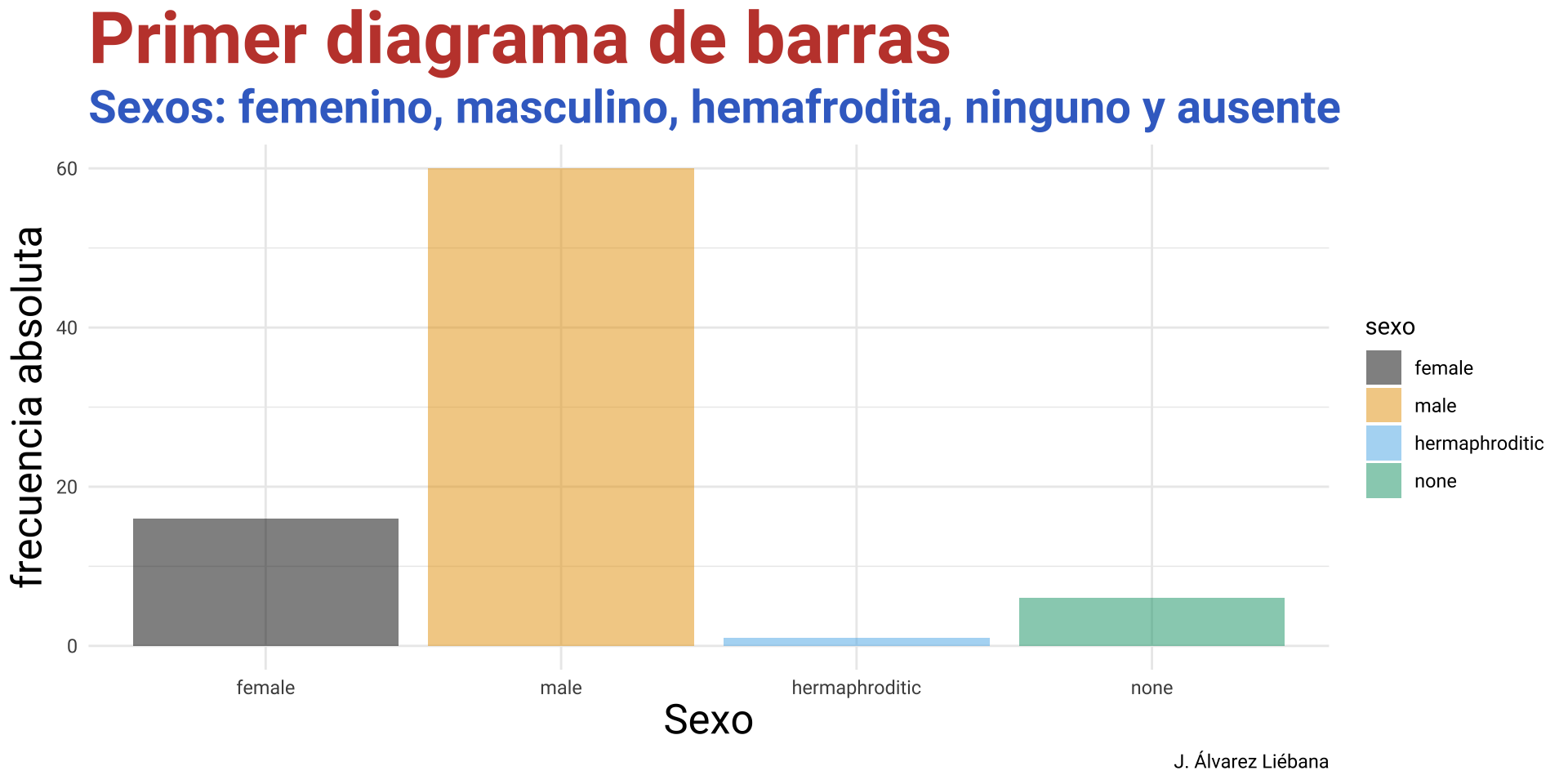
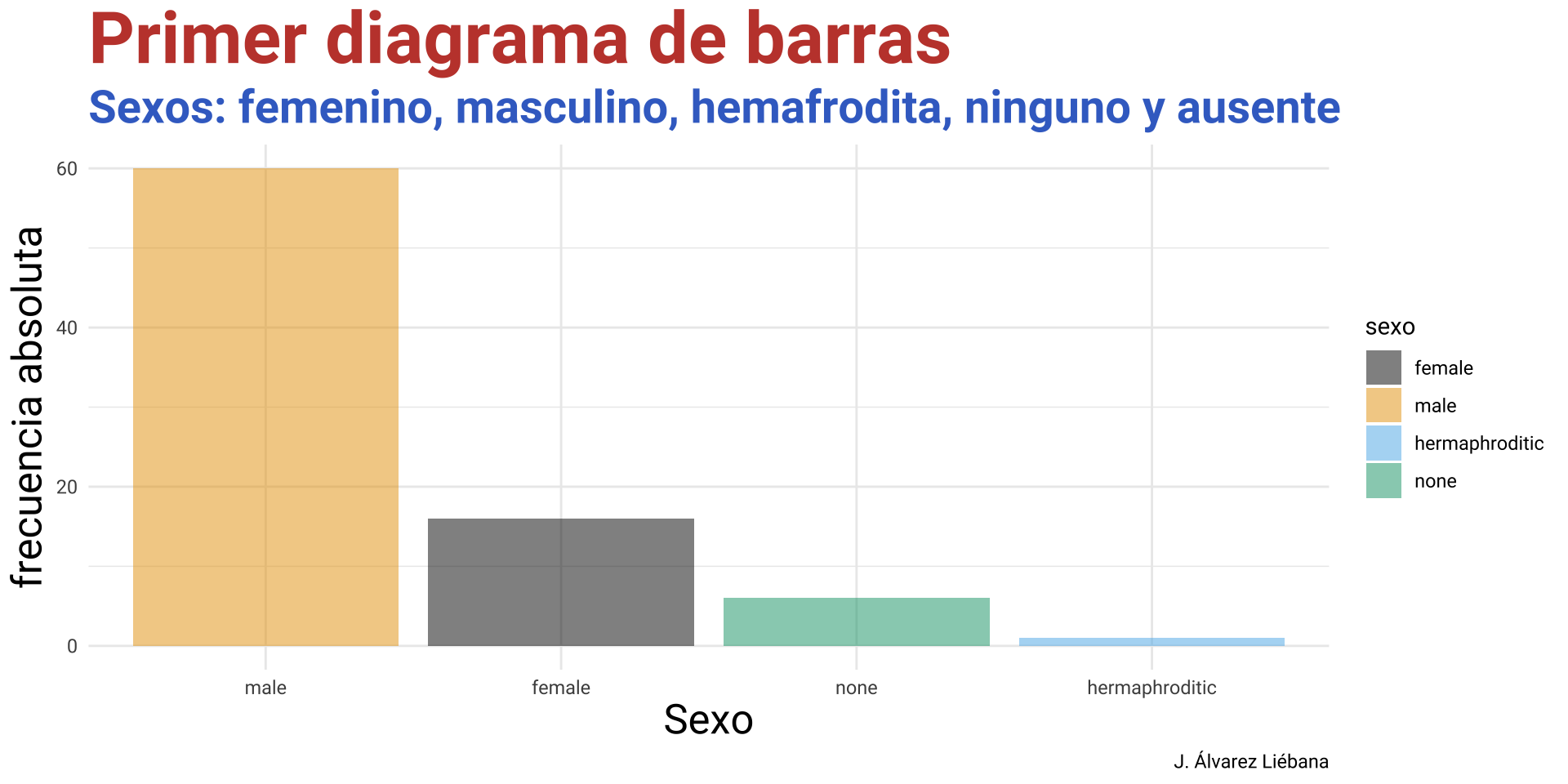
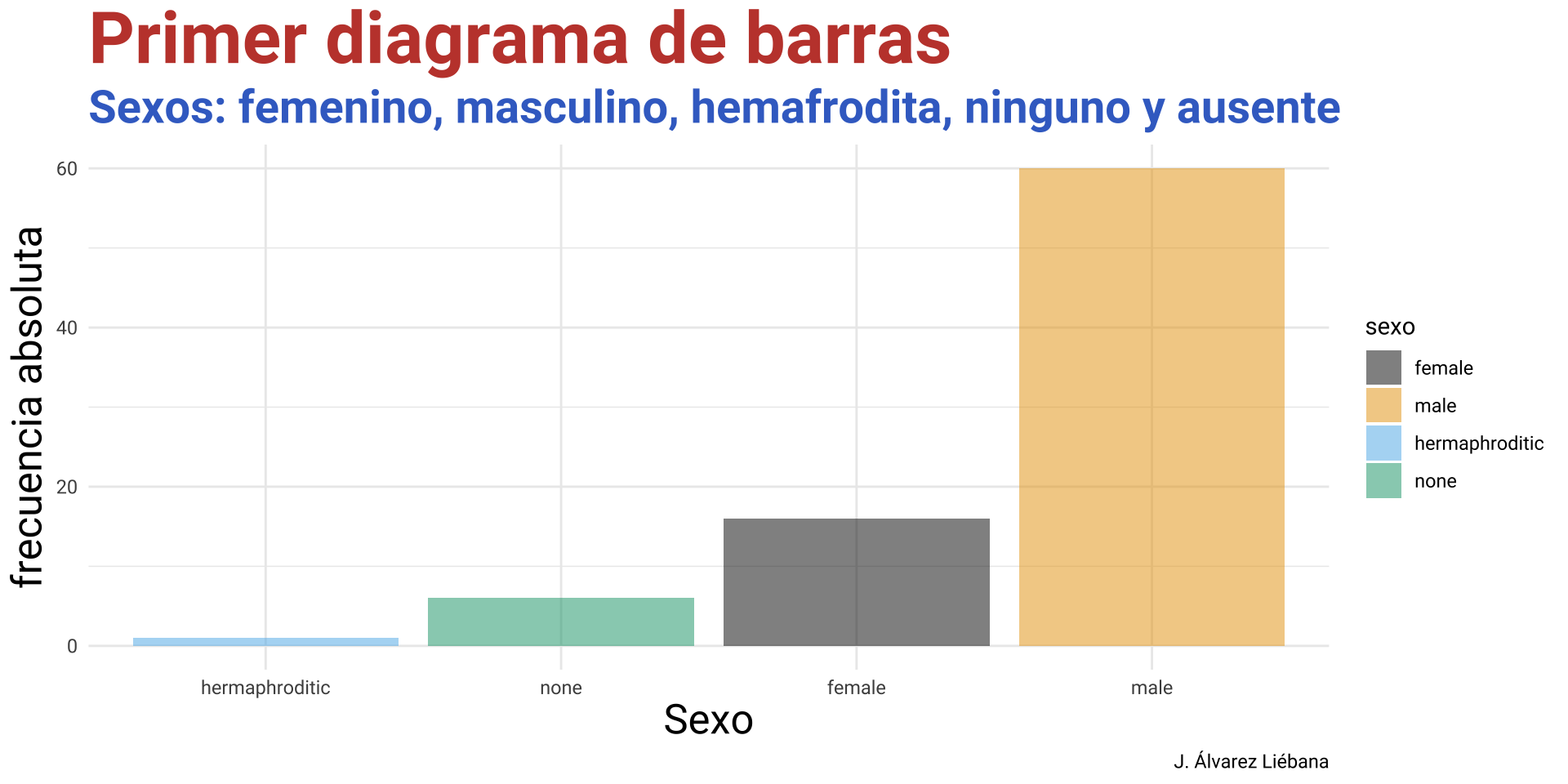
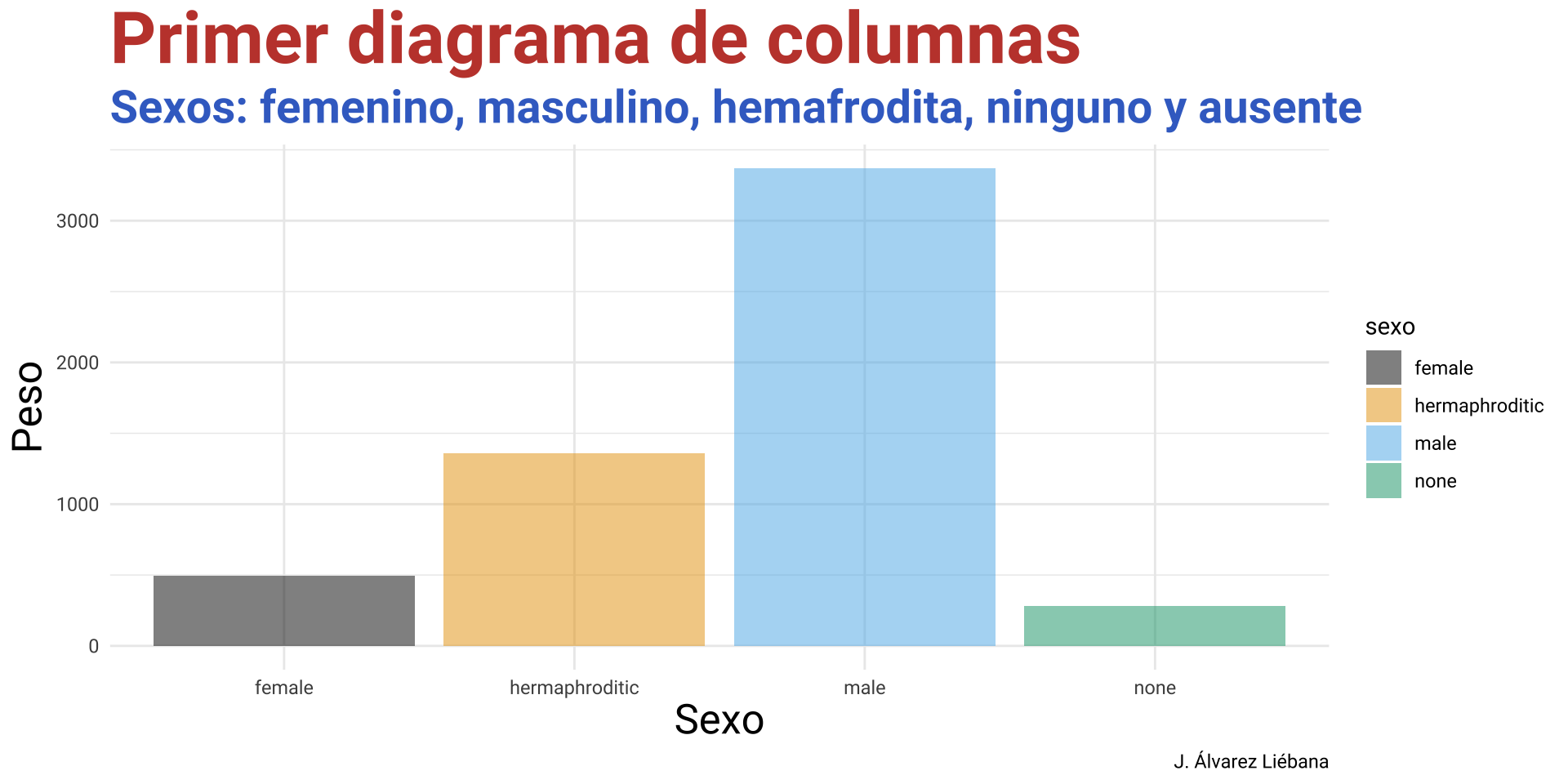
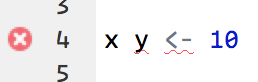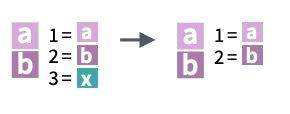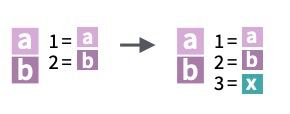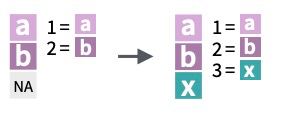Licenciado en Matemáticas (UCM). Doctorado en estadística (UGR).
Encargado de la visualización y análisis de datos covid del Principado de Asturias (2021-2022).
Miembro de la Sociedad Española de Estadística e IO y la Real Sociedad Matemática Española.
Actualmente, investigador y docente en la Facultad de Estadística de la UCM. Divulgando por Twitter e Instagram
Objetivos
Quitarnos el miedo a los errores en programación → a programar se aprende programando
Entender los conceptos básicos de R desde cero → aprender a abstraer ideas y algoritmos
Utilidad de programar → flujos de trabajo reproducibles, transparentes y mantenibles
Introducción al análisis y preprocesamiento de datos → {tidyverse}
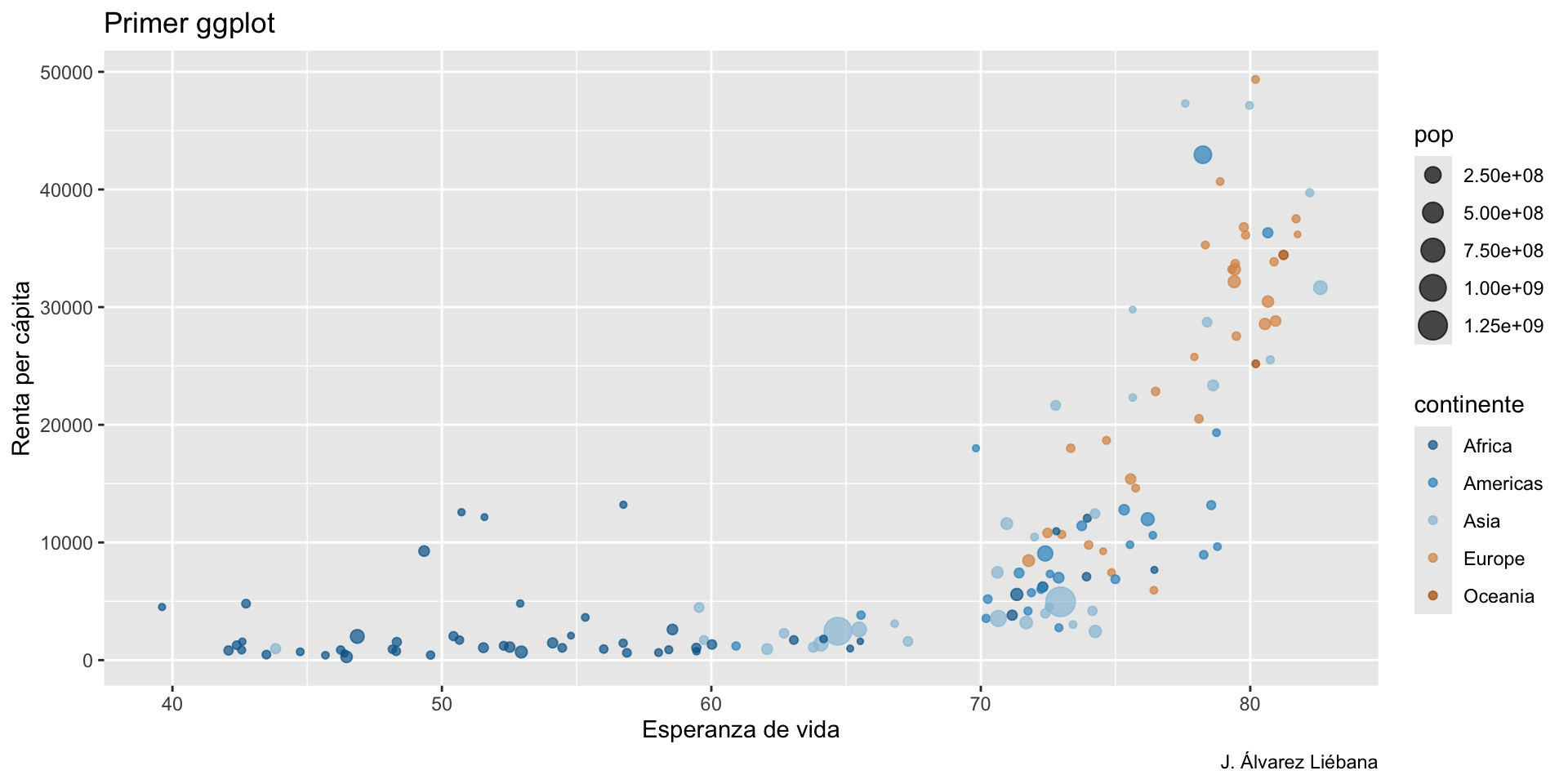
Adquirir habilidades en la visualización de datos → {ggplot2}
Evaluación
Asistencia. No será obligatoria pero se valorará positivamente la participación.
Evaluación continua: se han planteado 4 entregas individuales (5%-15%-25%-30%), así como una entrega final grupal (25%) (entre 4 y 7 personas).
Examen final: solo obligatorio en caso de que en la continua individual (sin contar la grupal) no superes el 3.5 sobre 10 de nota media. En caso contrario el día de la entrega final grupal (día del examen oficial de enero) deberás realizar un examen final en lugar de la grupal.
Nota máxima: para tener una nota final superior al 9 deberás tener al menos un 8.5 de nota media en la evaluación continua individual (sin contar la grupal).
Planificación entregas
Entrega I (5%): 25 de septiembre (60 minutos).
Entrega II (15%): 9 de octubre (120 minutos).
Entrega III (25%): 30 de octubre (120 minutos).
Entrega IV (30%): 16 de diciembre (120 minutos).
Entrega grupal (25%) o examen final: … enero (10:00-13:30)
Se podrán modificar las fechas por saturación con otras asignaturas siempre y cuando el/la delegado/a lo solicite con más de 7 días de antelación.
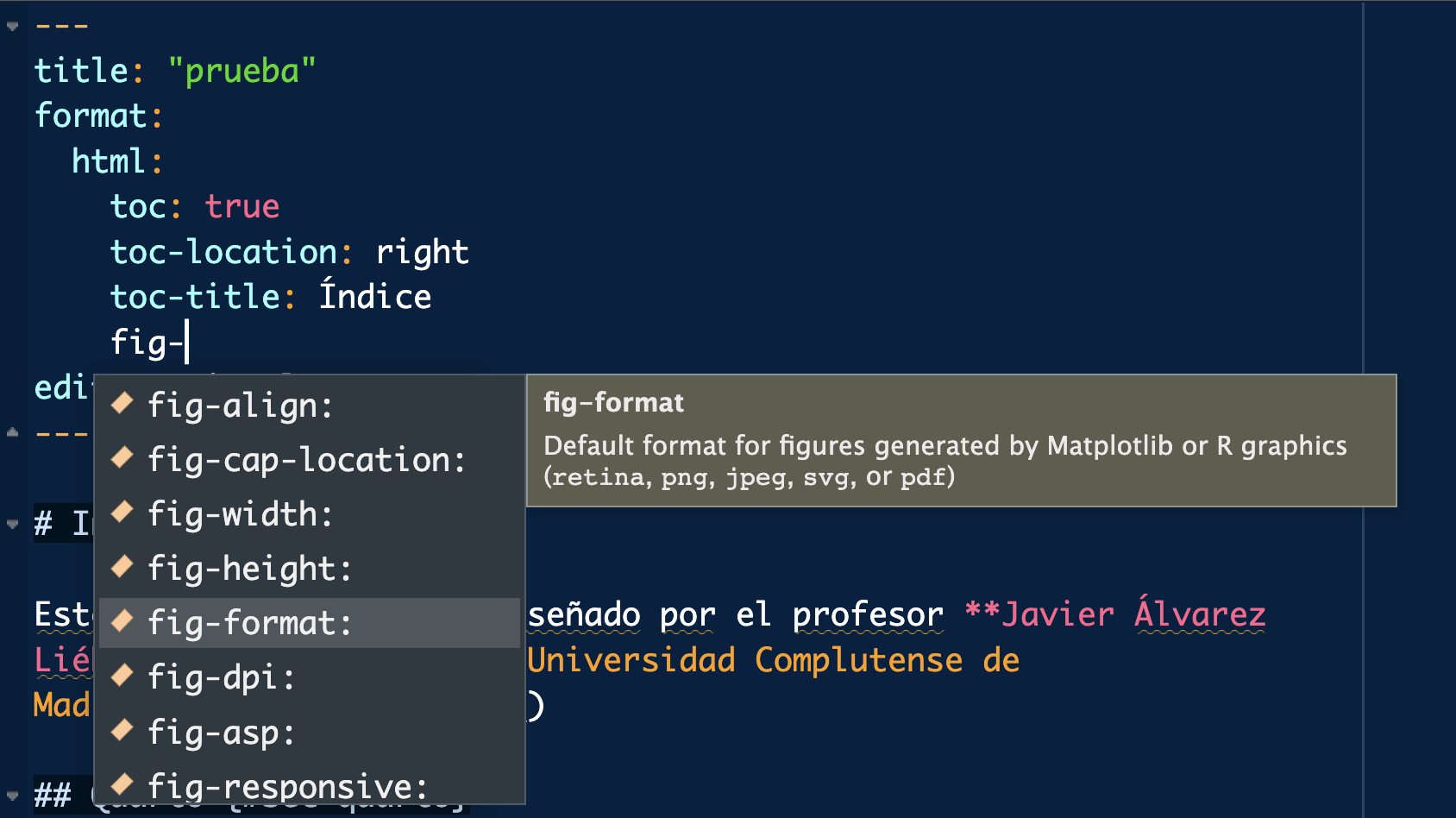
Diapositivas: diapositivas en Quarto disponibles y actualizadas en https://javieralvarezliebana.es/docencia/R-biostats. En el menú de las diapositivas (abajo a la izquierda) tienes una opción para descargarlas en pdf en Tools
Paso 2: para Mac basta con que hacer click en el archivo .pkg, y abrirlo una vez descargado. Para sistemas Windows, debemos clickar en install R for the first time y después en Download R for Windows. Una vez descargado, abrirlo como cualquier archivo de instalación.
Paso 3: abrir el ejecutable de instalación.
Warning
Siempre que tengas que descargar algo de CRAN (ya sea el propio R o un paquete), asegúrate de tener conexión a internet.
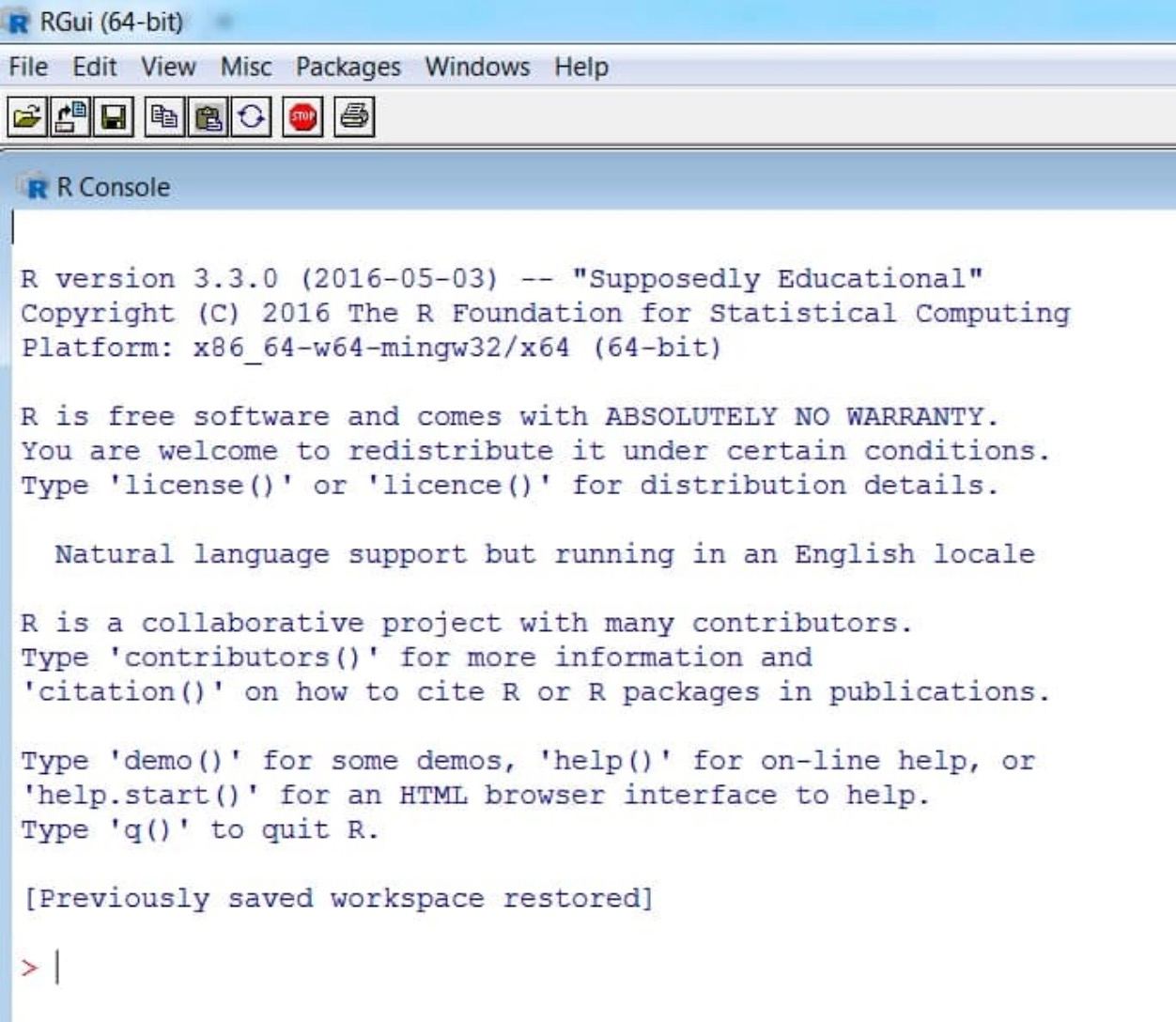
Primera operación
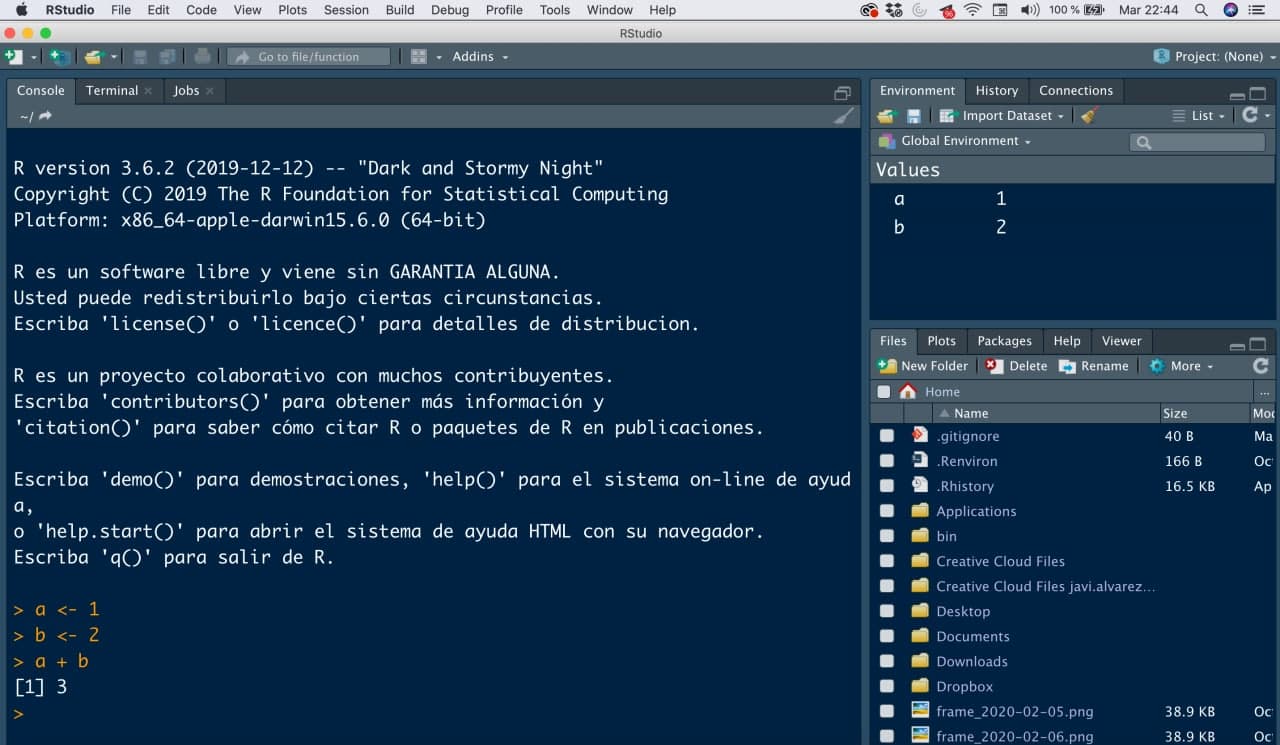
Para comprobar la instalación, tras abrir R, deberías ver el R GUI (Graphical User Interface) con una pantalla blanca similar a esta (consola).
Primer código: a una variable llamada a le asignaremos el valor 1 (escribiremos el código en la consola y daremos «enter»). Tras ello haremos la suma a + b.
a <-1
Primera operación
Para comprobar la instalación, tras abrir R, deberías ver el R GUI (Graphical User Interface) con una pantalla blanca similar a esta (consola).
Primer código: a una variable llamada a le asignaremos el valor 1 (escribiremos el código en la consola y daremos «enter»). Tras ello haremos la suma a + b.
a <-1b <-2
Primera operación
Para comprobar la instalación, tras abrir R, deberías ver el R GUI (Graphical User Interface) con una pantalla blanca similar a esta (consola).
Primer código: a una variable llamada a le asignaremos el valor 1 (escribiremos el código en la consola y daremos «enter»). Tras ello haremos la suma a + b.
a <-1b <-2a + b
[1] 3
Fíjate que…
En la consola aparece un número [1]: simplemente es un contador de elementos (como contar filas en un Word)
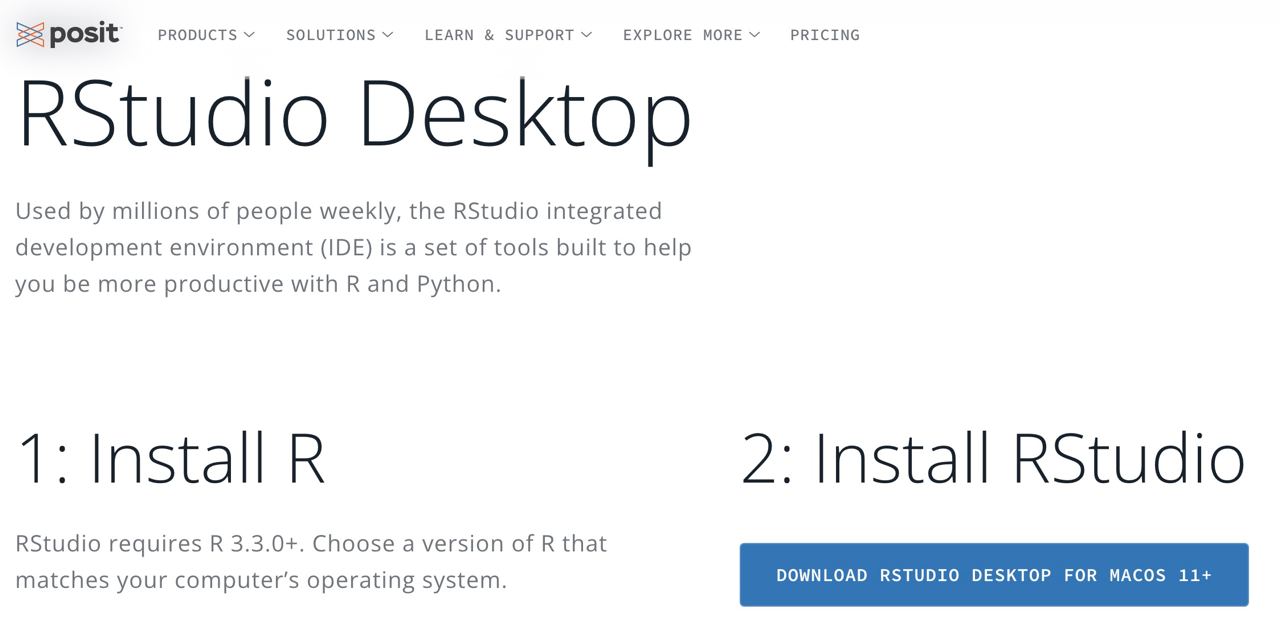
Instalación de R Studio
RStudio será el Word que usaremos para escribir (lo que se conoce como un IDE: entorno integrado de desarrollo).
Paso 1: entra la web oficial de RStudio (ahora llamado Posit) y selecciona la descarga gratuita.
Paso 2: selecciona el ejecutable que te aparezca acorde a tu sistema operativo.
Paso 3: tras descargar el ejecutable, hay que abrirlo como otro cualquier otro y dejar que termine la instalación.
Organización de RStudio
Al abrir RStudio seguramente tengas tres ventanas:
Consola: es el nombre para llamar a la ventana grande que te ocupa buena parte de tu pantalla. Prueba a escribir el mismo código que antes (la suma de las variables) en ella. La consola será donde ejecutaremos órdenes y mostraremos resultados.
Organización de RStudio
Al abrir RStudio seguramente tengas tres ventanas:
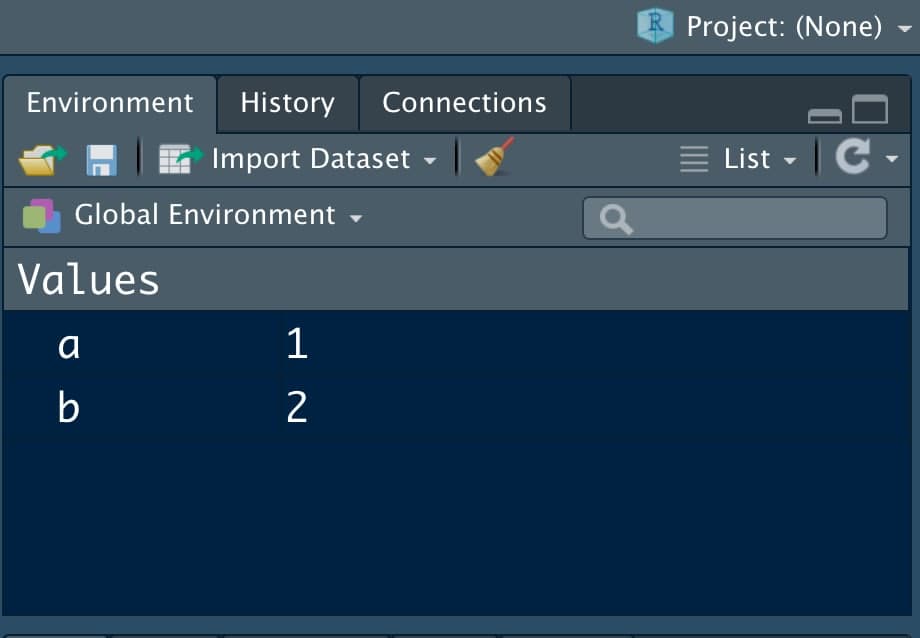
Environment: la pantalla pequeña (puedes ajustar los márgenes con el ratón a tu gusto) que tenemos en la parte superior derecha. Nos mostrará las variables que tenemos definidas.
Organización de RStudio
Al abrir RStudio seguramente tengas tres ventanas:
Panel multiusos: la ventana que tenemos en la parte inferior derecha no servirá para buscar ayuda de funciones, además de para visualizar gráficos.
¿Qué es R? ¿Por qué R?
¿Qué es R? ¿Por qué R?
R es la evolución del trabajo de los laboratorios Bell con el lenguaje S, que fue llevado al mundo del software libre por Ross Ihaka y Robert Gentleman en los años 90. La version R 1.0.0 se publicó el 29 de febrero de 2000.
¿Qué es R? ¿Por qué R?
R es el lenguaje estadístico por excelencia, creado por y para estadísticos/as, con 6 ventajas fundamentales frente a Excel, SAS, Stata o SPSS:
Lenguaje de programación: la obviedad → análisis replicables
Gratuito: la filosofía de la comunidad de R es el compartir código bajo copyleft → uso ético de dinero y algoritmos
Software libre: no solo es gratis sino que permite acceder libremente a código ajeno, incluso al propio código fuente → flexibilidad y transparencia (Free and Open Source Software FOSS)
¿Qué es R? ¿Por qué R?
R es el lenguaje estadístico por excelencia, creado por y para estadísticos/as, con 6 ventajas fundamentales frente a Excel, SAS, Stata o SPSS:
Lenguaje modular: hemos instalado lo mínimo, pero existen códigos de otras personas que podemos reusar (casi 20 000 paquetes) → ahorro de tiempo e innovación inmediata
Lenguaje de alto nivel: facilita la programación (como Python) → menor curva de aprendizaje
Comunidad y empleabilidad: junto con Python es el lenguaje más utilizado en el campo de la estadística y la ciencia de datos en investigación, docencia, empresas (Línea Directa, Mapfre, Telefónica, Orange, Apple, Spotify, Netflix, El País, Civio, HP, etc) y organismos públicos (ISCIII, CNIC, CNIO, INE, IGN, CIS, CEO, DGT, AEMET, RTVE, etc)
¿Por qué programar?
Automatizar → te permitirá automatizar tareas recurrentes.
Replicabilidad → podrás replicar tu análisis siempre de la misma manera.
Flexibilidad → podrás adaptar el software a tus necesidades.
Transparencia → ser auditado por la comunidad.
Idea fundamental: paquetes
Una de las ideas claves de R es el uso de paquetes: códigos que otras personas han implementado para resolver un problema
Instalación: descargamos los códigos de la web (necesitamos internet) → comprar un libro, solo una vez (por ordenador)
install.packages("ggplot2")
Carga: con el paquete descargado, indicamos qué paquetes queremos usar cada vez que abramos RStudio → traer el libro de la estantería
library(ggplot2)
Idea fundamental: paquetes
Una vez instalado, hay dos manera de usar un paquete (traerlo de la estantería)
Paquete entero: con library(), usando el nombre del paquete sin comillas, cargamos en la sesión todo el libro
library(ggplot2)
Funciones concretas usando paquete::funcion le índicamos que solo queremos una página concreta de ese libro
ggplot2::geom_point()
Te vas equivocar
Durante tu aprendizaje va a ser muy habitual que las cosas no salgan a la primera → te vas equivocar. No solo será importante asumirlo sino que es importante leer los mensajes de error para aprender de ellos.
Mensajes de error: precedidos de «Error in…» y serán aquellos fallos que impidan la ejecución
"a"+1
Error in "a" + 1: non-numeric argument to binary operator
Mensajes de warning: precedidos de «Warning in…» son los (posibles) fallos más delicados ya que son incoherencias que no impiden la ejecución
# Ejecuta la orden pero el resultado es NaN, **Not A Number**, un valor que no existesqrt(-1)
Warning in sqrt(-1): NaNs produced
[1] NaN
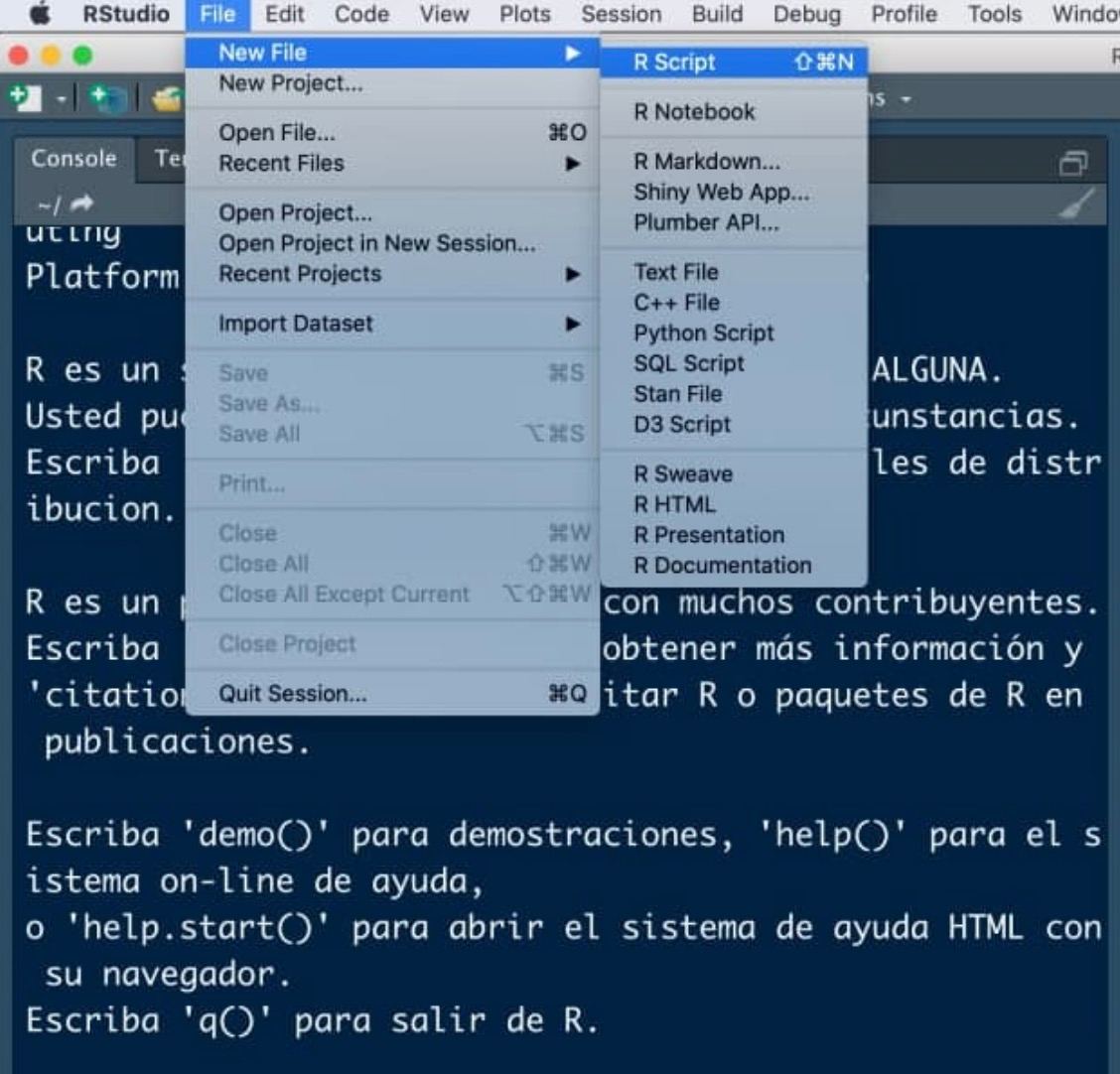
Scripts (documentos .R)
Un script será el documento en el que programamos, nuestro archivo .doc (aquí con extensión .R) donde escribiremos las órdenes. Para abrir nuestro primero script, haz click en el menú en File < New File < R Script.
Cuidado
Es importante no abusar de la consola: todo lo que no escribas en un script, cuando cierres, lo habrás perdido.
Cuidado
R es case-sensitive: es sensible a mayúsculas y minúsculas por lo que x y X representa variables distintas.
Ejecutando el primer script
Ahora tenemos una cuarta ventana: la ventana donde escribiremos nuestros códigos. ¿Cómo ejecutarlo?
Escribimos el código a ejecutar.
Guardamos el archivo .R haciendo click en Save current document.
El código no se ejecuta salvo que se lo indiquemos. Tenemos tres opciones de ejecutar un script:
Copiar y pegar en consola.
Seleccionar líneas y Ctrl+Enter
Activar Source on save a la derecha de guardar: no solo guarda sino que ejecuta el código completo.
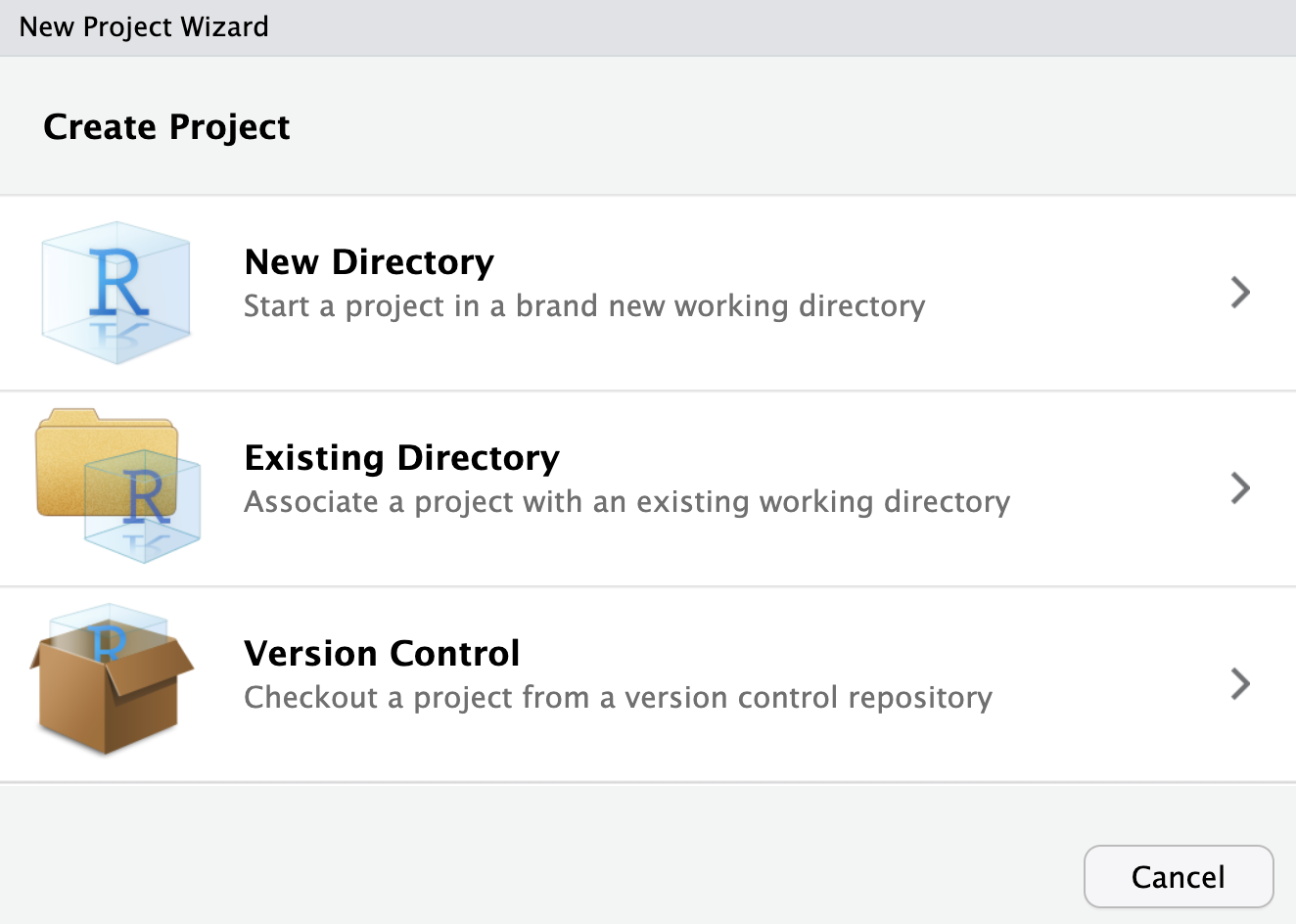
Sé organizado: proyectos
De la misma manera que en el ordenador solemos trabajar de manera ordenada por carpetas, en RStudio podemos hacer lo mismo para trabajar de manera eficaz creando proyectos.
Un proyecto será una «carpeta» dentro de RStudio, de manera que nuestro directorio raíz automáticamente será la propia carpeta de proyecto (pudiendo pasar de un proyecto a otro con el menu superior derecho).
Podemos crear uno en una carpeta nueva o en una carpeta ya existente.
📝 Crea en tu ordenador una carpeta de la asignatura y crea dentro de ella el proyecto de RStudio: es ahí donde vas a guardar todo lo que hagamos a lo largo de este curso.Tras crear el proyecto tendrás un archivo R Project. A continuación crea en dicha carpeta dos subcarpetas: datos (es ahí donde irás guardando los distintos datasets que usaremos) y scripts (es ahí donde irás guardando los archivos .R de cada clase)
📝 Dentro del proyecto crea un script ejercicios-clase1.R (dentro de la carpeta scripts). Una vez creado define en él una variable de nombre a y cuyo valor sea -1. Ejecuta el código de las 3 maneras explicadas.
Code
a <--1
📝 Añade debajo otra línea para definir una variable b con el valor 5. Tras ello guarda la multiplicación de ambas variables. Ejecuta el código como consideres.
Code
b <-5a * b # sin guardarmultiplicacion <- a * b # guardado
📝 Modifica el código inferior para definir dos variables c y d, con valores 3 y -1. Tras ello divide las variables y guarda el resultado.
c <-# deberías asignarle el valor 3d <-# deberías asignarle el valor -1
Code
c <-3d <--1c / d # sin guardardivision <- c / d # guardado
📝 Asigna un valor positivo a x y calcula su raíz cuadrada; asigna otro negativo y y calcula su valor absoluto con la función abs().
Code
x <-5sqrt(x)y <--2abs(y)
Toma nota
Comandos como sqrt(), abs() o max() son lo que llamamos funciones: líneas de código que hemos «encapsulado» bajo un nombre, y dado unos argumentos de entrada, ejecuta las órdenes (una especie de atajo). En las funciones los argumentos irán SIEMPRE entre paréntesis
📝 Usando la variable x ya definida, completa/modifica el código inferior para guardar en una nueva variable z el resultado guardado en x menos 5.
z <- ? - ? # completa el códigoz
Code
z <- x -5z
📝 Define una variable x y asígnale el valor -1. Define otra y y asígnale el valor 0. Tras ello realiza las operaciones a) x entre y; b) raíz cuadrada de x. ¿Qué obtienes?
Code
x <--1y <-0x / ysqrt(x)
📝 Escribe el código inferior en tu script. ¿Por qué crees que no funciona?
x <--1y <-0X + y
Error: object 'X' not found
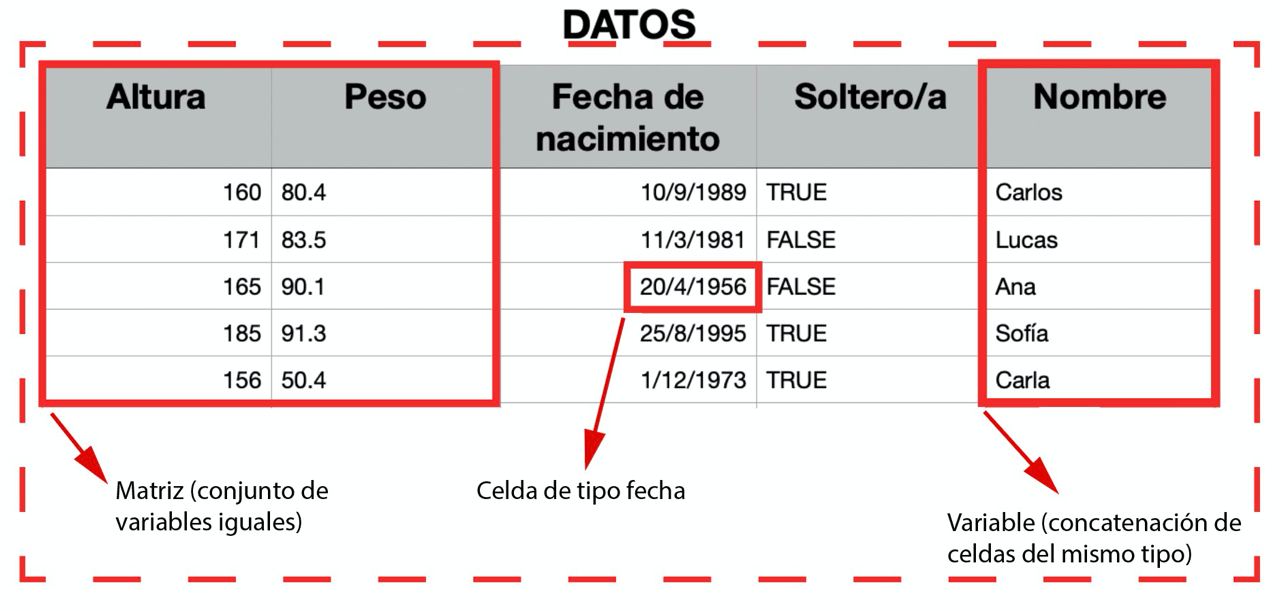
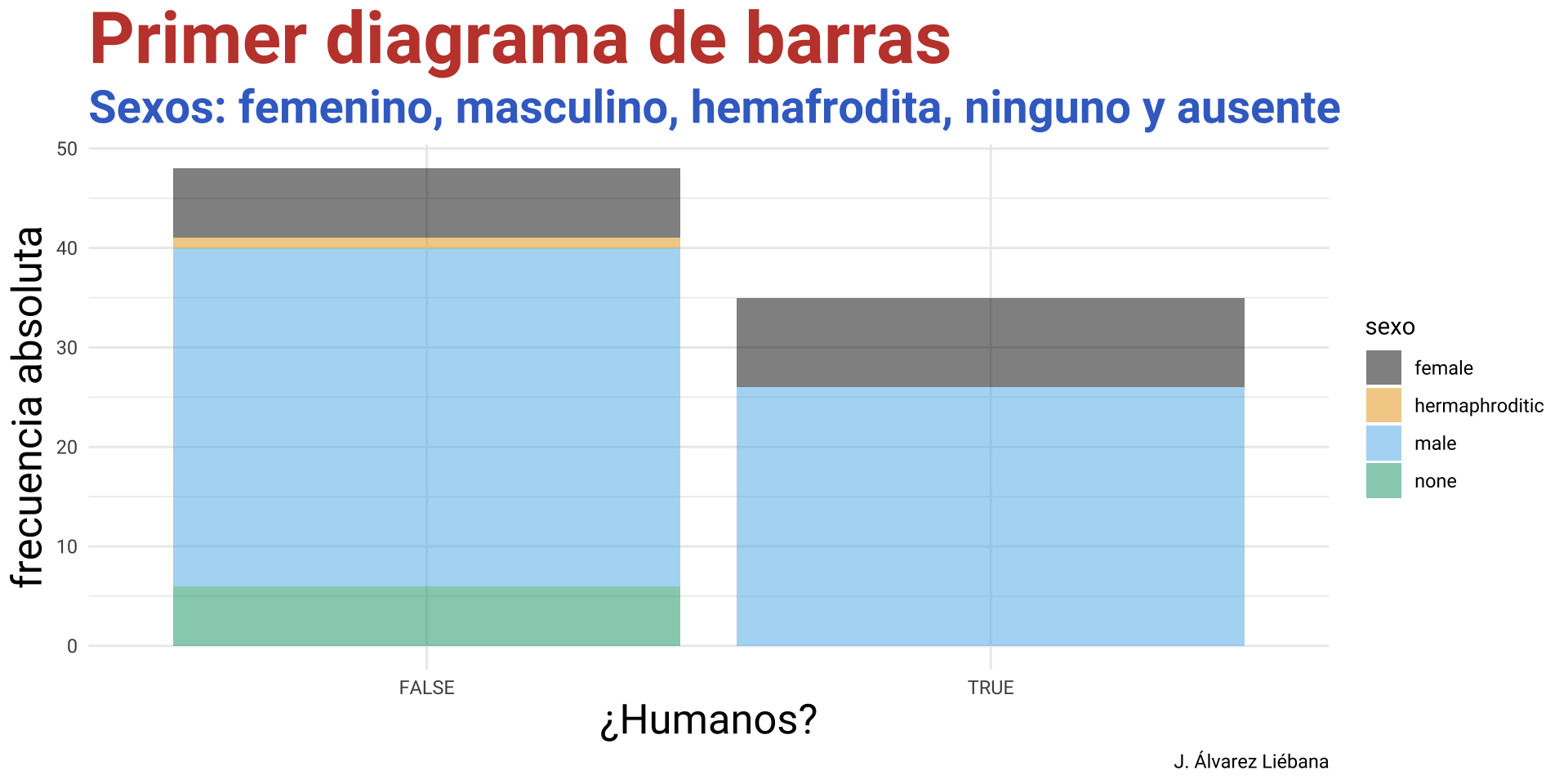
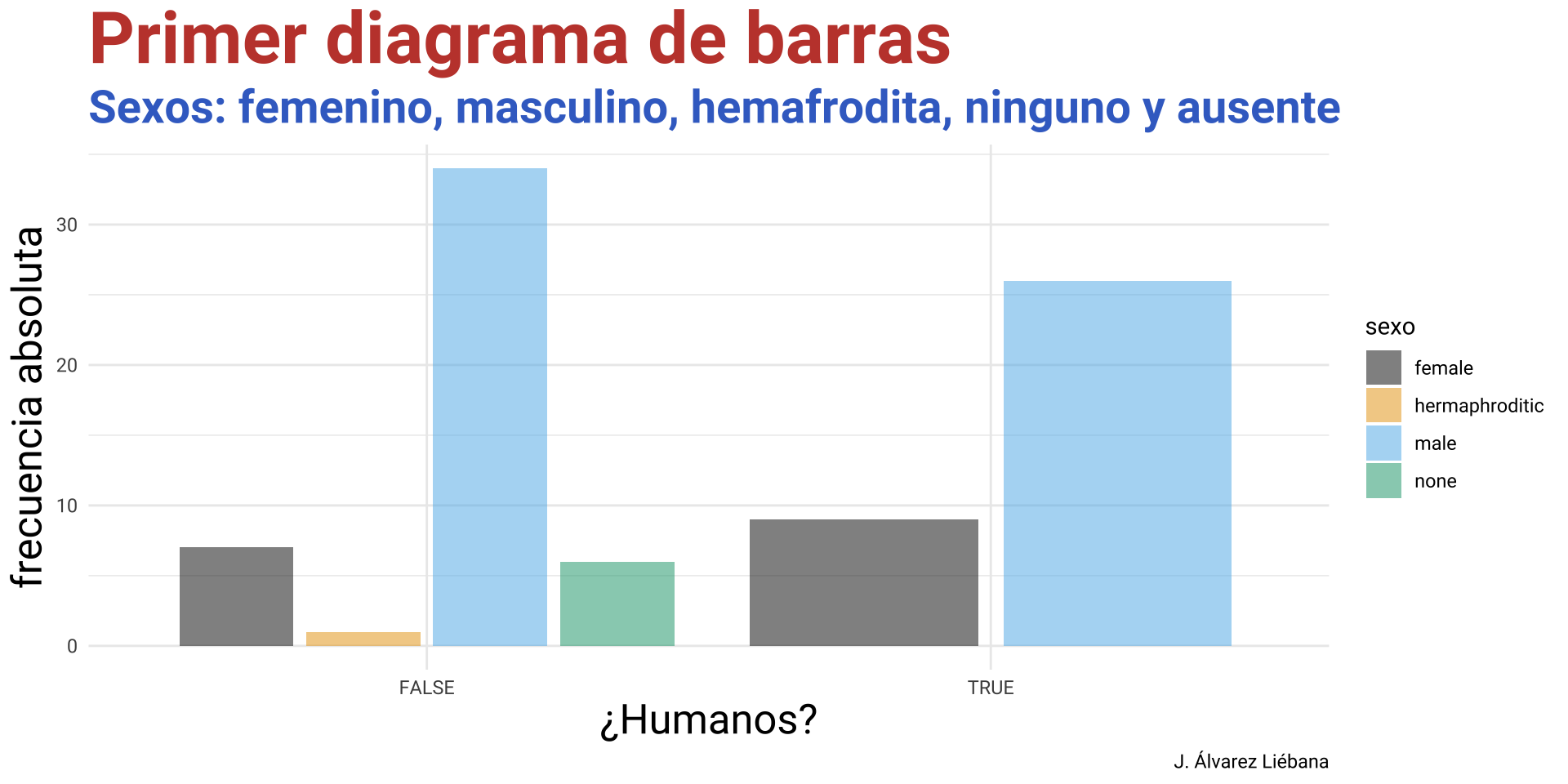
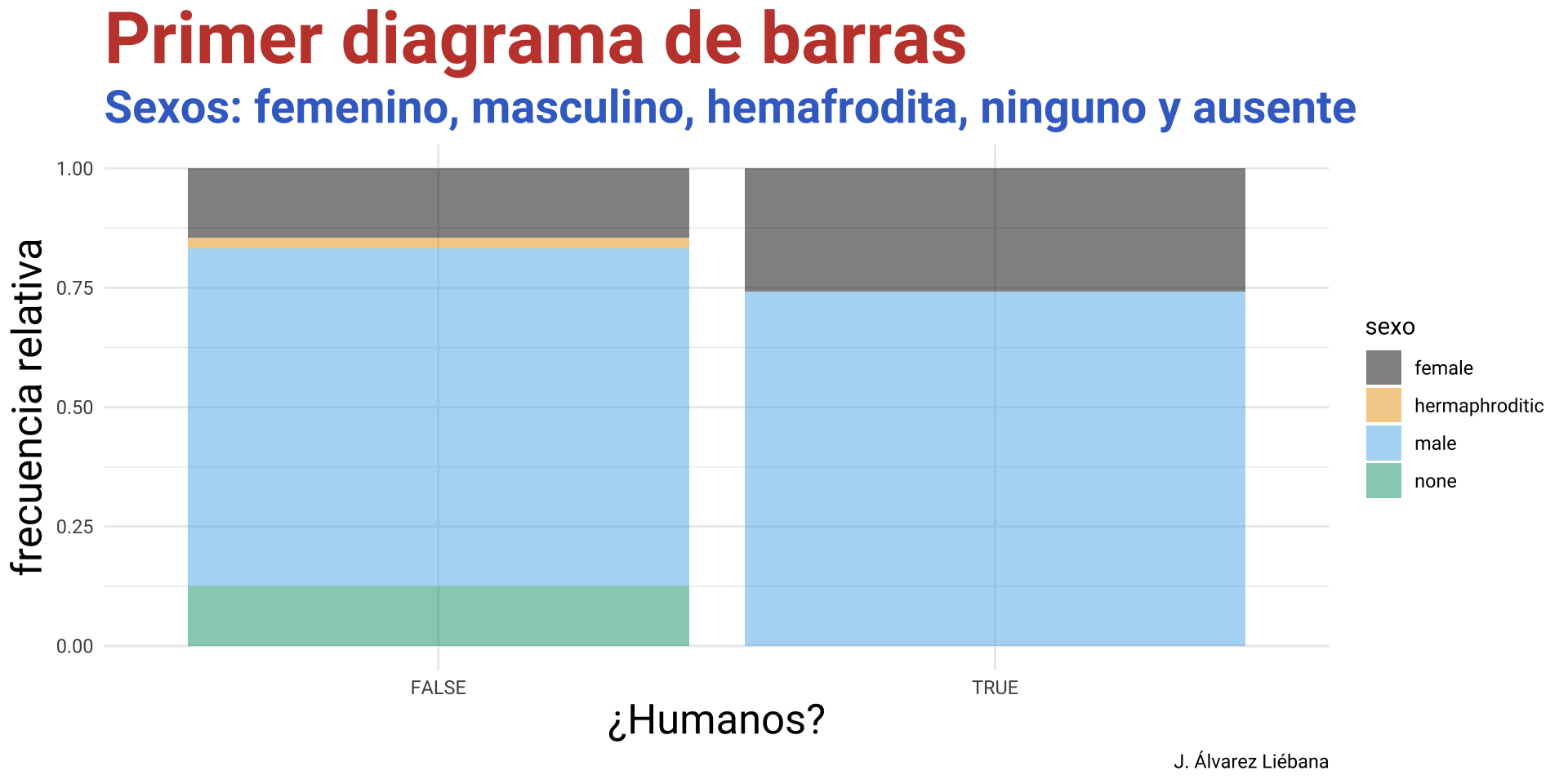
De la CELDA a la TABLA
¿Qué tipo de dato podemos tener en cada celda de una tabla?
Celda: dato individual de un tipo concreto.
Variable: concatenación de valores del mismo tipo (vectores en R).
Matriz: concatenación de variables del mismo tipo y longitud.
Tabla: concatenación de variables de distinto tipo pero igual longitud
Lista: concatenación de variables de distinto tipo y distinta longitud
Pero antes…buenas prácticas
Antes de seguir, es importante que sepas algo cuánto antes: empezar en la programación puede ser frustrante
Al igual que cuando aprendes un idioma nuevo, el primer obstáculo a solventar no es tanto qué decir sino cómo decirlo de manera correcta. Y en R pasa lo mismo, así que vamos a normalizar nuestra forma de programar lo máximo posible para evitar errores futuros.
Tip 1: asignar, evaluar y comparar no es lo mismo. Si te has fijado en R estamos usando <- para asignar valores a variables. Usaremos = para evaluar argumentos en funciones y == para saber si dos elementos son iguales.
x <-1# asignarx =1# evaluarx ==1# comparar
Pero antes…buenas prácticas
Tip 2: programa como escribes. Al igual que cuando redactas en castellano, acostúmbrate a incorporar espacios y saltos de línea paranoquedarteciego (es una buena práctica y no un requisito porque R no procesa los espacios)
x <-1# óptimox<-1# regux<-1# peor (decídete)
Tip 3: no seas caótico/a, estandariza nombres. Acostúmbrate siempre a nombrar las variables de la misma manera. El único requisito es que debe empezar siempre por una letra (y sin tildes). La forma más recomendable es la conocida como snake_case
Tip 4: facilita la lectura y escritura, pon límites. En Tools < Global Options puedes personalizar algunas opciones de RStudio. En Code < Display podemos indicarle en Show margin que los scripts nos muestren un margen “imaginario” (no interacciona con el código) para “forzarnos” a realizar un salto de línea.
Pero antes…buenas prácticas
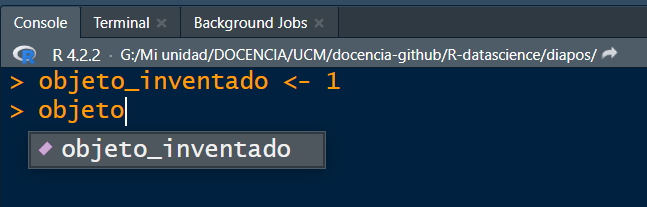
Tip 5: el tabulador es tu mejor amigo. En RStudio tenemos una herramienta maravillosa: si escribes parte del nombre de una variable o función y tabulas, RStudio te autocompleta
Pero antes…buenas prácticas
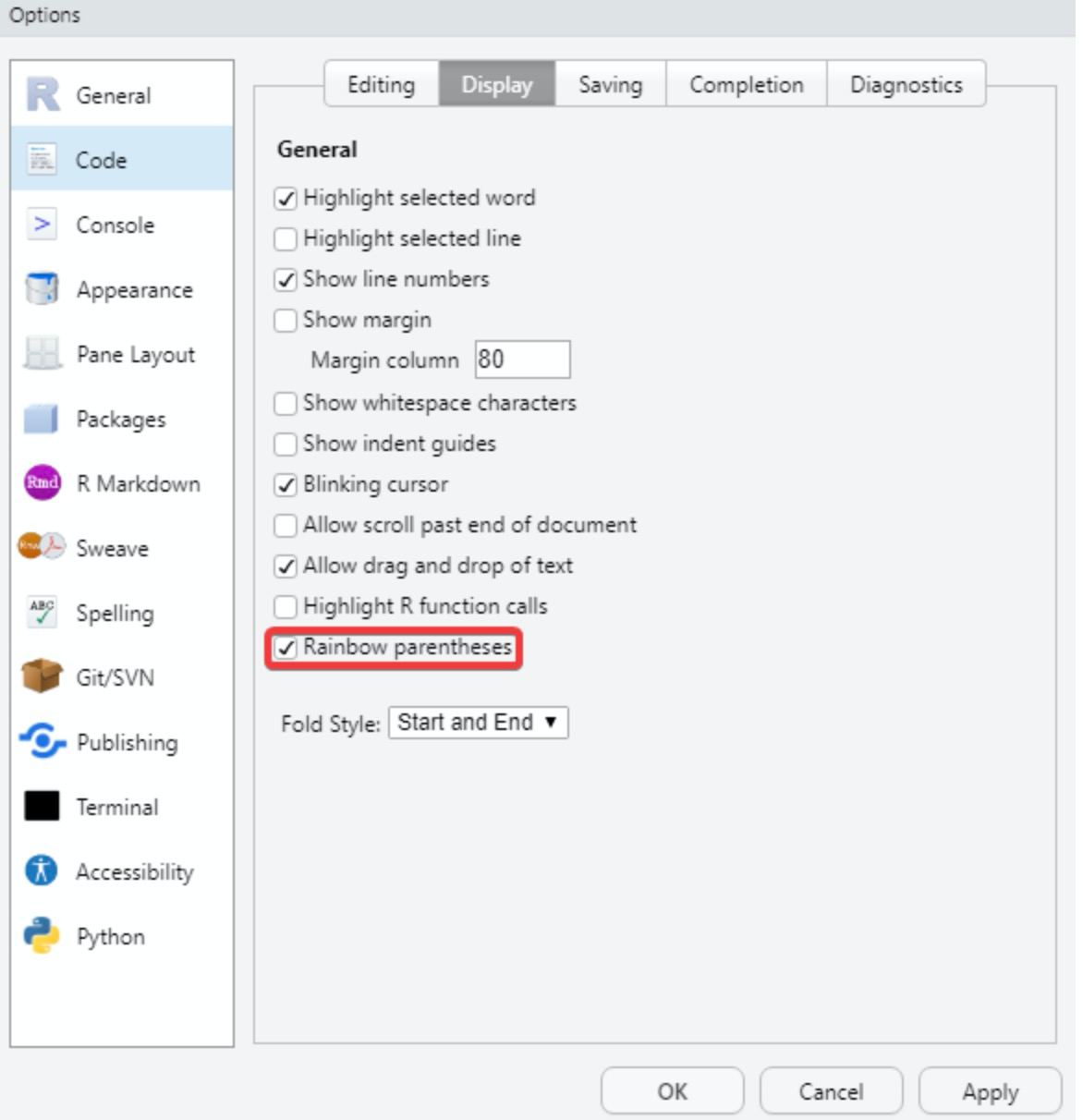
Tip 6: ni un paréntesis soltero. Siempre que abras un paréntesis deberás cerrarlo. Para facilitar esta tarea entra en Tools < Global Options < Code < Display y activa la opción Rainbow parentheses
Pero antes…buenas prácticas
Tip 7: fíjate en el lateral izquierdo. No solo podrás ver la línea de código por la que vas sino que, en caso de estar cometiendo un error de sintaxis, el propio RStudio te avisará.
Tip 8: intenta trabajar siempre por proyectos (para esta clase, crea un script clase2.R en el proyecto que creamos en la anterior clase)
¿Existen variables más allá de los números en la ciencia de datos? Piensa por ejemplo en los datos que podrías guardar de una persona:
La edad o el peso será un número.
edad <-33
Su nombre será una cadena de texto (conocida como string o char).
nombre <-"javi"
A la pregunta «¿estás matriculado en la Facultad?» la respuesta será lo que llamamos una variable lógica (TRUE si está matriculado o FALSE en otro caso).
matriculado <-TRUE
Su fecha de nacimiento será precisamente eso, una fecha.
Variables numéricas
El dato más sencillo (ya lo hemos usado) serán las variables numéricas. Para saber la clase de dato en R de una variable tenemos la función class()
a <-5
Variables numéricas
El dato más sencillo (ya lo hemos usado) serán las variables numéricas. Para saber la clase de dato en R de una variable tenemos la función class()
a <-5class(a)
Para saber su tipología (naturaleza o formato) variable tenemos typeof()
typeof(1) # 1 pero almacenado como un valor real (double, con decimales)
[1] "double"
typeof(as.integer(1)) # 1 pero almacenado como un entero.
[1] "integer"
Fíjate que…
En R tenemos una colección de funciones que empiezan por as.x() y que sirven como funciones de conversión: un dato que era de un tipo, lo convertimos a tipo x.
Variables numéricas
Además de los números «normales» tendremos el valor más/menos infinito codificado como Inf o -Inf
1/0
[1] Inf
-1/0
[1] -Inf
Y valores que no son números realesnot a number (indeterminaciones, complejos, etc) codificado como NaN
0/0
[1] NaN
sqrt(-2)
[1] NaN
Variables numéricas
Con las variables numéricas podemos realizar las operaciones aritméticas de una calculadora: sumar (+)…
a + b
[1] 7
…raíz cuadrada (sqrt())…
sqrt(a)
[1] 2.236068
… potencias (^2, ^3)…
a^2
[1] 25
…valor absoluto (abs()), etc.
abs(a)
[1] 5
Variables de texto
Imagina que además de la edad de una persona queremos guardar su nombre: ahora la variable será de tipo character
nombre <-"Javier"class(nombre)
[1] "character"
Las cadenas de texto son un tipo con el que obviamente no podremos hacer operaciones aritméticas (sí otras operaciones como pegar o localizar patrones).
nombre +1# error al sumar número a texto
Error in nombre + 1: non-numeric argument to binary operator
Recuerda que…
Las variables de tipo texto (character o string) van SIEMPRE entre comillas: no es lo mismo TRUE (valor lógico, binario) que "TRUE" (texto).
Primera función: paste
Como hemos comentado R llamaremos función a un trozo de código encapsulado bajo un nombre, y que depende de unos argumentos de entrada. Nuestra primera función será paste(): dadas dos cadenas de texto nos permite pegarlas.
paste("Javier", "Álvarez")
[1] "Javier Álvarez"
Fíjate que por defecto nos pega las cadenas con un espacio, pero podemos añadir un argumento opcional para indicarle el separador (en sep = ...).
paste("Javier", "Álvarez", sep ="*")
[1] "Javier*Álvarez"
Primera función: paste
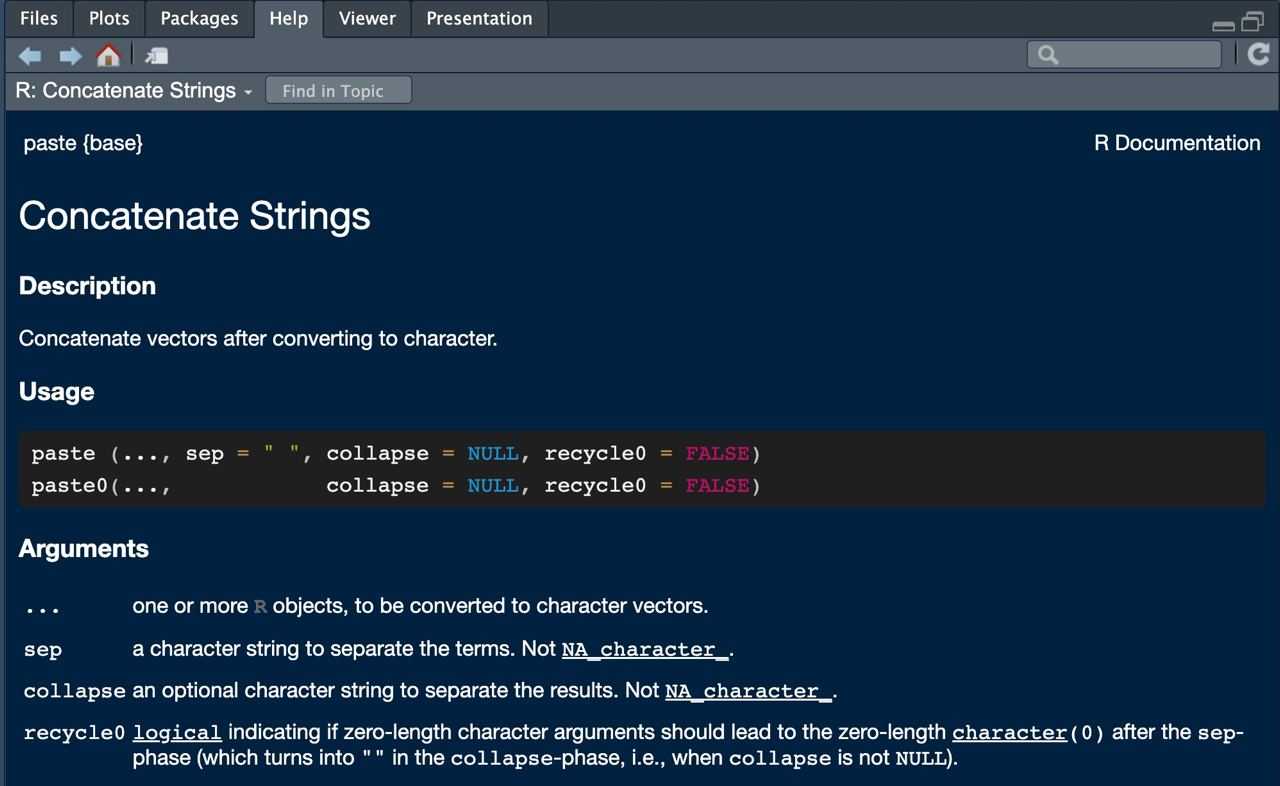
¿Cómo saber qué argumentos necesita una función? Escribiendo en consola ? paste te aparecerá una ayuda en el panel multiusos.
En dicha ayuda podrás ver en su cabecera que argumentos ya tiene asignados por defecto la función
Existe una función similar llamada paste0() que pega por defecto con sep = "" (sin nada).
paste0("Javier", "Álvarez")
[1] "JavierÁlvarez"
Primera función: paste
Los argumentos (y su detalle) también pueden ser consultado tabulando (detras una coma).
Funciones: argumentos por defecto
Es muy importante entender el concepto de argumento por defecto de una función en R: es un valor que la función usa pero a veces podemos no ver porque ya tiene un valor asignado.
# Hacen lo mismopaste("Javier", "Álvarez")
[1] "Javier Álvarez"
paste("Javier", "Álvarez", sep =" ")
[1] "Javier Álvarez"
Toma nota
El operador = lo reservaremos para asignar argumentos dentro de funciones. Para todas las demás asignaciones usaremos <-
Primer paquete: glue
Una forma más intuitiva de trabajar con textos es usar el paquete {glue}: lo primero que haremos será «comprar el libro» (si nunca lo hemos hecho). Tras ello cargamos el paquete
install.packages("glue") # solo la primra vezlibrary(glue)
Con la función glue() de dicho paquete podemos usar variables dentro de cadenas de texto. Por ejemplo, «la edad es de … años», donde la edad está guardada en una variable.
edad <-33glue("La edad es de {edad} años")
La edad es de 33 años
Dentro de las llaves también podemos ejecutar operaciones
unidades <-"días"glue("La edad es de {edad * 365} {unidades}")
La edad es de 12045 días
Variables lógicas
Otro tipo fundamental serán las variables lógicas o binarias (dos valores):
TRUE: verdadero guardado internamente como un 1.
FALSE: falso guardado internamente como un 0.
soltero <-TRUE# ¿Es soltero? --> SÍclass(soltero)
[1] "logical"
Dado que internamente están guardados como variables binarias, podemos realizar operaciones aritméticas con ellas
2*TRUE
[1] 2
FALSE-1
[1] -1
Variables lógicas
Como veremos en breve, las variables lógicas en realidad puede tomar un tercer valor: NA o dato ausente, representando las siglas de not available, y será muy habitual encontrarlo dentro de una base de datos.
ausente <-NAausente +1
[1] NA
Importante
Las variables lógicas NO son variables de texto: "TRUE" es un texto, TRUE es un valor lógico.
TRUE+1
[1] 2
"TRUE"+1
Error in "TRUE" + 1: non-numeric argument to binary operator
Condiciones lógicas
Los valores lógicos suelen ser resultado de evaluar condiciones lógicas. Por ejemplo, imaginemos que queremos comprobar si una persona se llama Javi.
nombre <-"María"
Con el operador lógico== preguntamos sí lo que tenemos guardado a la izquierda es igual que lo que tenemos a la derecha: es una pregunta
nombre =="Javi"
[1] FALSE
Con su opuesto != preguntamos si es distinto.
nombre !="Javi"
[1] TRUE
Fíjate que…
No es lo mismo <- (asignación) que == (estamos preguntando, es una comparación lógica).
Condiciones lógicas
Además de las comparaciones «igual a» frente «distinto», también comparaciones de orden como menor que<, mayor que>, <= o >=.
¿Tiene la persona menos de 32 años?
edad <-34edad <32# ¿Es la edad menor de 32 años?
[1] FALSE
¿La edad es mayor o igual que 38 años?
edad >=38
[1] FALSE
¿El nombre guardado es Javi?
nombre <-"Javi"nombre =="Javi"
[1] TRUE
Variables de fecha
Un tipo de datos muy especial: los datos de tipo fecha.
fecha_char <-"2021-04-21"
Parece una simple cadena de texto pero debería representar un instante en el tiempo. ¿Qué debería suceder si sumamos un 1 a una fecha?
fecha_char +1
Error in fecha_char + 1: non-numeric argument to binary operator
Las fechas NO pueden ser texto: debemos convertir la cadena de texto a fecha.
Para trabajar con fechas usaremos el paquete {lubridate}, que deberemos instalar antes de poder usarlo.
install.packages("lubridate")
Variables de fecha
Una vez instalado, de todos los paquetes (libros) que tenemos, le indicaremos que nos cargue ese concretamente.
library(lubridate) # instala si no lo has hecho
Para convertir a tipo fecha usaremos la función as_date() del paquete {lubridate} (por defecto en formato yyyy-mm-dd)
# ¡no es una fecha, es un texto!fecha_char +1
Error in fecha_char + 1: non-numeric argument to binary operator
class(fecha_char)
[1] "character"
fecha <-as_date("2023-03-28")fecha +1
[1] "2023-03-29"
class(fecha)
[1] "Date"
Variables de fecha
En as_date() el formato de fecha por defecto es yyyy-mm-dd así si la cadena de texto no se introduce de manera adecuada…
as_date("28-03-2023")
[1] NA
Para cualquier otro formato debemos especificarlo en el argumento opcional format = ... tal que %d representa días, %m meses, %Y en formato de 4 años y %y en formato de 2 años.
as_date("28-03-2023", format ="%d-%m-%Y")
[1] "2023-03-28"
as_date("28-03-23", format ="%d-%m-%y")
[1] "2023-03-28"
as_date("03-28-2023", format ="%m-%d-%Y")
[1] "2023-03-28"
as_date("28/03/2023", format ="%d/%m/%Y")
[1] "2023-03-28"
Variables de fecha
En dicho paquete tenemos funciones muy útiles para manejar fechas:
Con today() podemos obtener directamente la fecha actual.
today()
[1] "2024-11-17"
Con now() podemos obtener la fecha y hora actual
now()
[1] "2024-11-17 22:05:23 CET"
Con year(), month() o day() podemos extraer el año, mes y día
fecha <-today()year(fecha)
[1] 2024
month(fecha)
[1] 11
Resúmenes de paquetes
Amplia contenido
Tienes un resumen en pdf de los paquetes más importantes en la carpeta correspondiente en el campus
💻 Tu turno
Intenta realizar los siguientes ejercicios sin mirar las soluciones
📝 Define una variable que guarde tu edad (llamada edad) y otra con tu nombre (llamada nombre)
Code
edad <-33nombre <-"Javi"
📝 Comprueba con dicha variable edad si NO tiene 60 años o si se llama "Ornitorrinco" (debes obtener variables lógicas como resultado)
Code
edad !=60# distinto denombre =="Ornitorrinco"# igual a
📝 ¿Por qué el código inferior da error?
edad + nombre
Error in edad + nombre: non-numeric argument to binary operator
📝 Define otra variable llamada hermanos que responda la pregunta «¿tienes hermanos?» y otra variable que almacene tu fecha de nacimiento (llamada fecha_nacimiento).
Code
hermanos <-TRUElibrary(lubridate) # sino lo tenías ya cargadofecha_nacimiento <-as_date("1989-09-10")
📝 Define otra variable con tus apellidos (llamada apellidos) y usa glue() para tener, en una sola variable llamada nombre_completo, tu nombre y apellidos separando nombre y apellido por una coma
Cuando trabajamos con datos normalmente tendremos columnas que representan variables: llamaremos vectores a una concatenación de celdas (valores) del mismo tipo (lo que sería una columna de una tabla).
La forma más sencilla es con el comando c() (c de concatenar), y basta con introducir sus elementos entre paréntesis y separados por comas
edades <-c(32, 27, 60, 61)edades
[1] 32 27 60 61
Tip
Un número individual x <- 1 (o bien x <- c(1)) es en realidad un vector de longitud uno –> todo lo que sepamos hacer con un número podemos hacerlo con un vector de ellos.
Vectores: concatenar
Como ves ahora en el environment tenemos una colección de elementos guardada
edades
[1] 32 27 60 61
La longitud de un vector se puede calcular con length()
length(edades)
[1] 4
También podemos concatenar vectores entre sí (los repite uno tras otro)
c(edades, edades, 8)
[1] 32 27 60 61 32 27 60 61 8
Secuencias numéricas
El vector más famoso será el de tipo numérico, y en concreto, las conocidas como secuencias numéricas (por ejemplo, los días del mes), usadas para, entre otras cosas, indexar bucles.
El comando seq(inicio, fin) nos permite crear una secuencia numérica desde un elemento inicial hasta uno final, avanzando de uno en uno.
Un vector es una concatenación de elementos del mismo tipo, pero no tienen porque ser necesariamente números. Vamos a crear una frase de ejemplo.
frase <-"Me llamo Javi"frase
[1] "Me llamo Javi"
length(frase)
[1] 1
En el caso anterior no era un vector, era un solo elemento de texto. Para crear un vector debemos usar de nuevo c() y separar elementos entre comas
vector <-c("Me", "llamo", "Javi")vector
[1] "Me" "llamo" "Javi"
length(vector)
[1] 3
Vectores de caracteres
¿Qué sucederá si concatenamos elementos de diferente tipo?
c(1, 2, "javi", "3", TRUE)
[1] "1" "2" "javi" "3" "TRUE"
Fíjate que como todos tienen que ser del mismo tipo, lo que hace R es convertir todo a texto, violando la integridad del dato
c(3, 4, TRUE, FALSE)
[1] 3 4 1 0
Es importante entender que los valores lógicos en realidad están almacenados internamente como 0/1
Operaciones con vectores
Con los vectores numéricos podemos hacer las mismas operaciones aritméticas que con los números → un número es un vector (de longitud uno)
¿Qué sucederá si sumamos o restamos un valor a un vector?
x <-c(1, 3, 5, 7)x +1
[1] 2 4 6 8
x *2
[1] 2 6 10 14
Cuidado
Salvo que indiquemos lo contrario, en R las operaciones con vectores son siempre elemento a elemento
Suma de vectores
Los vectores también pueden interactuar entre ellos, así que podemos definir, por ejemplo, sumas de vectores (elemento a elemento)
x <-c(2, 4, 6)y <-c(1, 3, 5)x + y
[1] 3 7 11
Dado que la operación (por ejemplo, una suma) se realiza elemento a elemento, ¿qué sucederá si sumamos dos vectores de distinta longitud?
z <-c(1, 3, 5, 7)x + z
[1] 3 7 11 9
Lo que hace es reciclar elementos: si tiene un vector de 4 elementos y sumamos otro de 3 elementos, lo que hará será reciclar del vector con menor longitud.
Comparar vectores
Una operación muy habitual es preguntar a los datos mediante el uso de condiciones lógicas. Por ejemplo, si definimos un vector de temperaturas…
¿Qué días hizo menos de 22 grados?
x <-c(15, 20, 31, 27, 15, 29)
x <22
[1] TRUE TRUE FALSE FALSE TRUE FALSE
Nos devolverá un vector lógico, en función de si cada elemento cumple o no la condición pedida (de igual longitud que el vector preguntado)
Si tuviéramos un dato ausente (por error del aparato ese día), la condición evaluada también sería NA
y <-c(15, 20, NA, 31, 27, 7, 29, 10)y <22
[1] TRUE TRUE NA FALSE FALSE TRUE FALSE TRUE
Comparar vectores
Las condiciones lógicas pueden ser combinadas de dos maneras:
Intersección: todas las condiciones concatenadas se deben cumplir (conjunción y con &) para devolver un TRUE
x <30& x >15
[1] FALSE TRUE FALSE TRUE FALSE TRUE
Unión: basta con que al menos una se cumpla (conjunción o con |)
x <30| x >15
[1] TRUE TRUE TRUE TRUE TRUE TRUE
Con any() y all() podemos comprobar que todos los elementos cumplen
any(x <30)
[1] TRUE
all(x <30)
[1] FALSE
Acceder a elementos
Otra operación muy habitual es la de acceder a elementos. La forma más sencilla es usar el operador [i] (acceder al elemento i-ésimo)
edades <-c(20, 30, 33, NA, 61) edades[3] # accedemos a la edad de la tercera persona
[1] 33
Dado que un número no es más que un vector de longitud uno, esta operación también la podemos aplicar usando un vector de índices a seleccionar
y <-c("hola", "qué", "tal", "estás", "?")y[c(1:2, 4)] # primer, segundo y cuarto elemento
[1] "hola" "qué" "estás"
Tip
Para acceder al último, sin preocuparnos de cuál es, podemos pasarle como índice la propia longitud x[length(x)]
Eliminar elementos
Otras veces no querremos seleccionar sino eliminar algunos elementos. Deberemos repetir la misma operación pero con el signo - delante: el operador [-i] no selecciona el elemento i-ésimo del vector sino que lo «des-selecciona»
y
[1] "hola" "qué" "tal" "estás" "?"
y[-2]
[1] "hola" "tal" "estás" "?"
En muchas ocasiones los queremos seleccionar o eliminar en base a condiciones lógicas, en función de los valores, así que pasaremos como índice la propia condición (recuerda, x < 2 nos devuelve un vector lógico)
edades <-c(15, 21, 30, 17, 45)nombres <-c("javi", "maría", "laura", "carla", "luis")nombres[edades <18] # nombres de los menores de edad
[1] "javi" "carla"
Sumar vectores
También podemos hacer uso de operaciones estadísticas como por ejemplo sum() que, dado un vector, nos devuelve la suma de todos sus elementos.
x <-c(1, -2, 3, -1)sum(x)
[1] 1
¿Qué sucede cuando falta un dato (ausente)?
x <-c(1, -2, 3, NA, -1)sum(x)
[1] NA
Por defecto, si tenemos un dato ausente, la operación también será ausente. Para poder obviar ese dato, usamos un argumento opcional na.rm = TRUE
sum(x, na.rm =TRUE)
[1] 1
Sumar vectores
Como hemos comentado que los valores lógicos son guardados internamente como 0 y 1, podremos usarlos en operaciones aritméticas.
Por ejemplo, si queremos averiguar el número de elementos que cumplen una condición (por ejemplo, menores que 3), los que lo hagan tendrán asignado un 1 (TRUE) y los que no un 0 (FALSE) , por lo que basta con sumar dicho vector lógico para obtener el número de elementos que cumplen
x <-c(2, 4, 6)sum(x <3)
[1] 1
Suma acumulada
Otra operación habitual que puede sernos útil es la suma acumulada con cumsum() que, dado un vector, nos devuelve un vector a su vez con el primero, el primero más el segundo, el primero más el segundo más el tercero…y así sucesivamente.
x <-c(1, 5, 2, -1, 8)cumsum(x)
[1] 1 6 8 7 15
¿Qué sucede cuando falta un dato (ausente)?
x <-c(1, -2, 3, NA, -1)cumsum(x)
[1] 1 -1 2 NA NA
En el caso de la suma acumulada lo que sucede es que a partir de ese valor, todo lo acumulado posterior será ausente.
Diferencia
Otra operación habitual que puede sernos útil es la diferencia (con retardo) con diff() que, dado un vector, nos devuelve un vector con el segundo menos el primero, el tercero menos el segundo, el cuarto menos el tercero…y así sucesivamente.
x <-c(1, 8, 5, 3, 9, 0, -1, 5)diff(x)
[1] 7 -3 -2 6 -9 -1 6
Con el argumento lag = podemos indicar el retardo de dicha diferencia (por ejemplo, lag = 3 implica que se resta el cuarto menos el primero, el quinto menos el segundo, etc)
x <-c(1, 8, 5, 3, 9, 0, -1, 5)diff(x, lag =3)
[1] 2 1 -5 -4 -4
Media
Otras operaciones habituales son la media, mediana, percentiles, etc.
Media: medida de centralidad que consiste en sumar todos los elementos y dividirlos entre la cantidad de elementos sumados. La más conocida pero la menos robusta: dado un conjunto, si se introducen valores atípicos o outliers (valores muy grandes o muy pequeños), la media se perturba con mucha facilidad.
📝 Define el vector x como la concatenación de los 5 primeros números impares. Calcula la longitud del vector
Code
# Dos formasx <-c(1, 3, 5, 7, 9)x <-seq(1, 9, by =2)length(x)
📝 Accede al tercer elemento de x. Accede al último elemento (sin importar la longitud, un código que pueda ejecutarse siempre). Elimina el primer elemento.
Code
x[3]x[length(x)]x[-1]
📝 Obtén los elementos de x mayores que 4. Calcula el vector 1/x y guárdalo en una variable.
Code
x[x >4]z <-1/xz
📝 Crea un vector que represente los nombres de 5 personas, de los cuales uno es desconocido.
📝 Encuentra del vector x de ejercicios anteriores los elementos mayores (estrictos) que 1 Y ADEMÁS menores (estrictos) que 7. Encuentra una forma de averiguar si todos los elementos son o no positivos.
Code
x[x >1& x <7]all(x >0)
📝 Dado el vector x <- c(1, -5, 8, NA, 10, -3, 9), ¿por qué su media no devuelve un número sino lo que se muestra en el código inferior?
x <-c(1, -5, 8, NA, 10, -3, 9)mean(x)
[1] NA
📝 Dado el vector x <- c(1, -5, 8, NA, 10, -3, 9), extrae los elementos que ocupan los lugares 1, 2, 5, 6.
📝 Dado el vector x del ejercicio anterior, ¿cuales tienen un dato ausente? Pista: las funciones is.algo() comprueban si el elemento es tipo algo (tabula)
Code
is.na(x)
📝 Define el vector x como la concatenación de los 4 primeros números pares. Calcula el número de elementos de x menores estrictamente que 5.
Code
x[x <5] sum(x <5)
📝 Calcula el vector 1/x y obtén la versión ordenada (de menor a mayor) de las dos formas posibles
Code
z <-1/xsort(z)z[order(z)]
Code
min(x)max(x)
📝 Encuentra del vector x los elementos mayores (estrictos) que 1 y menores (estrictos) que 6. Encuentra una forma de averiguar si todos los elementos son o no negativos.
Code
x[x >1& x <7]all(x >0)
🐣 Caso práctico I: vectores
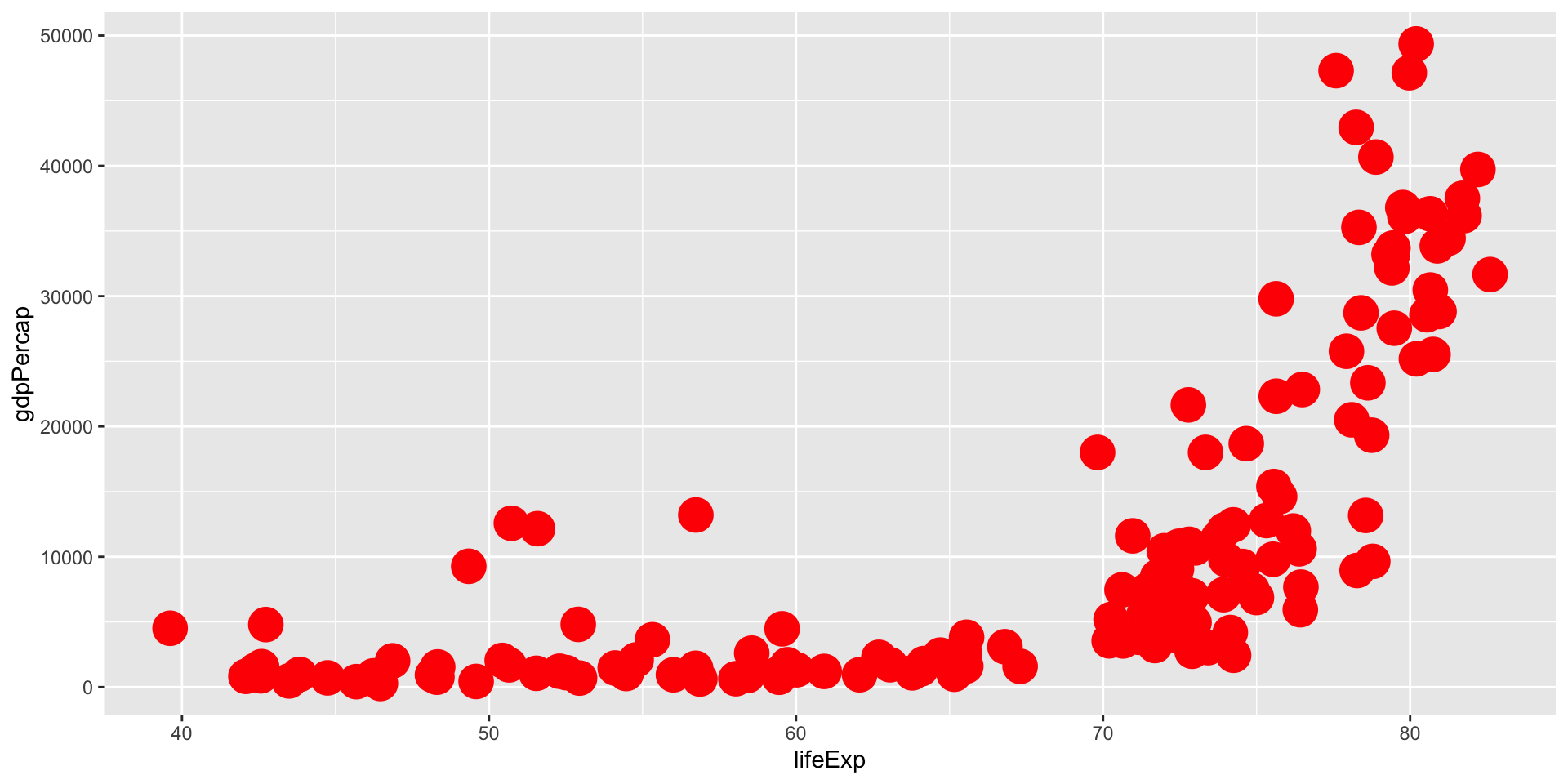
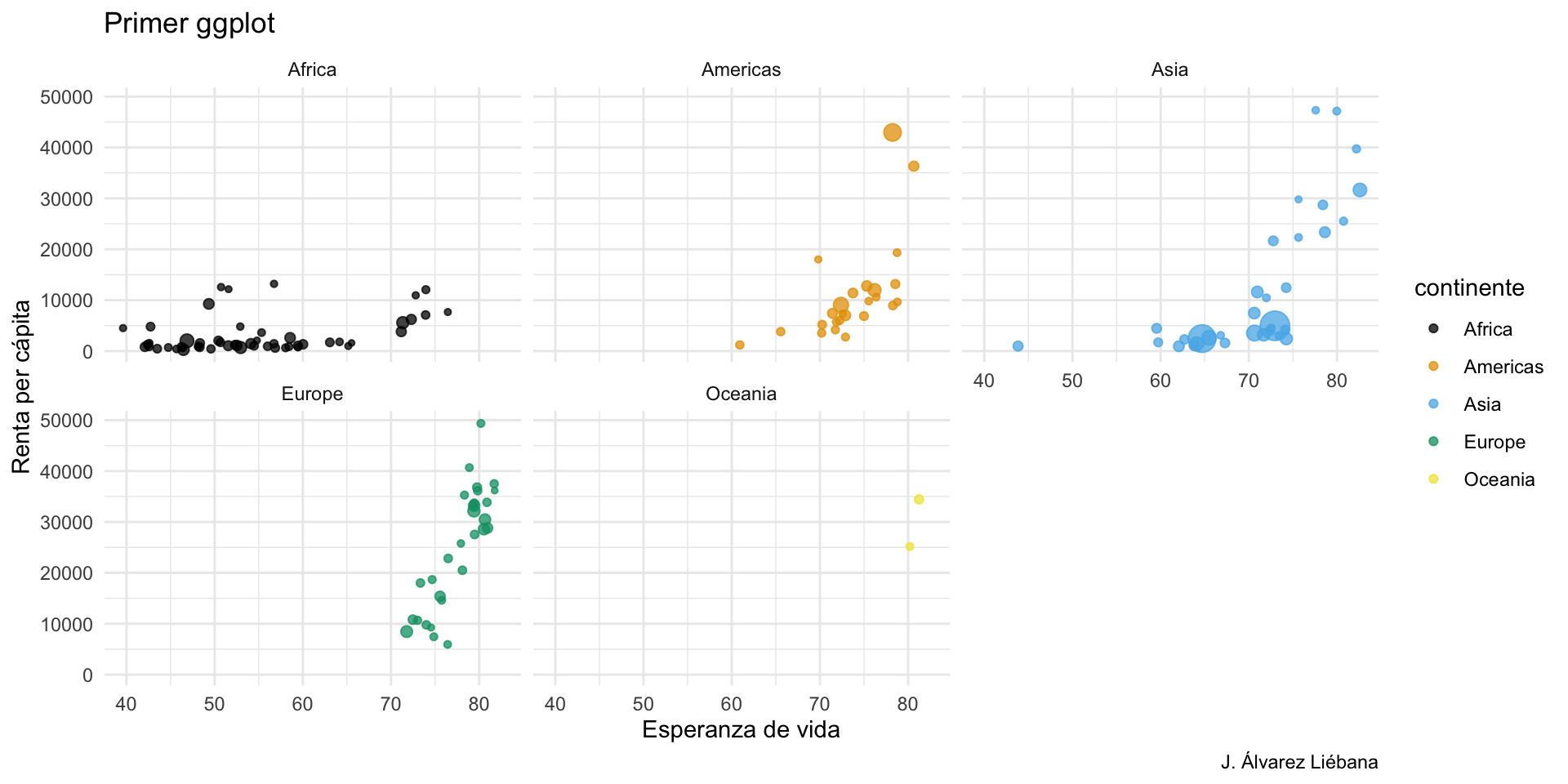
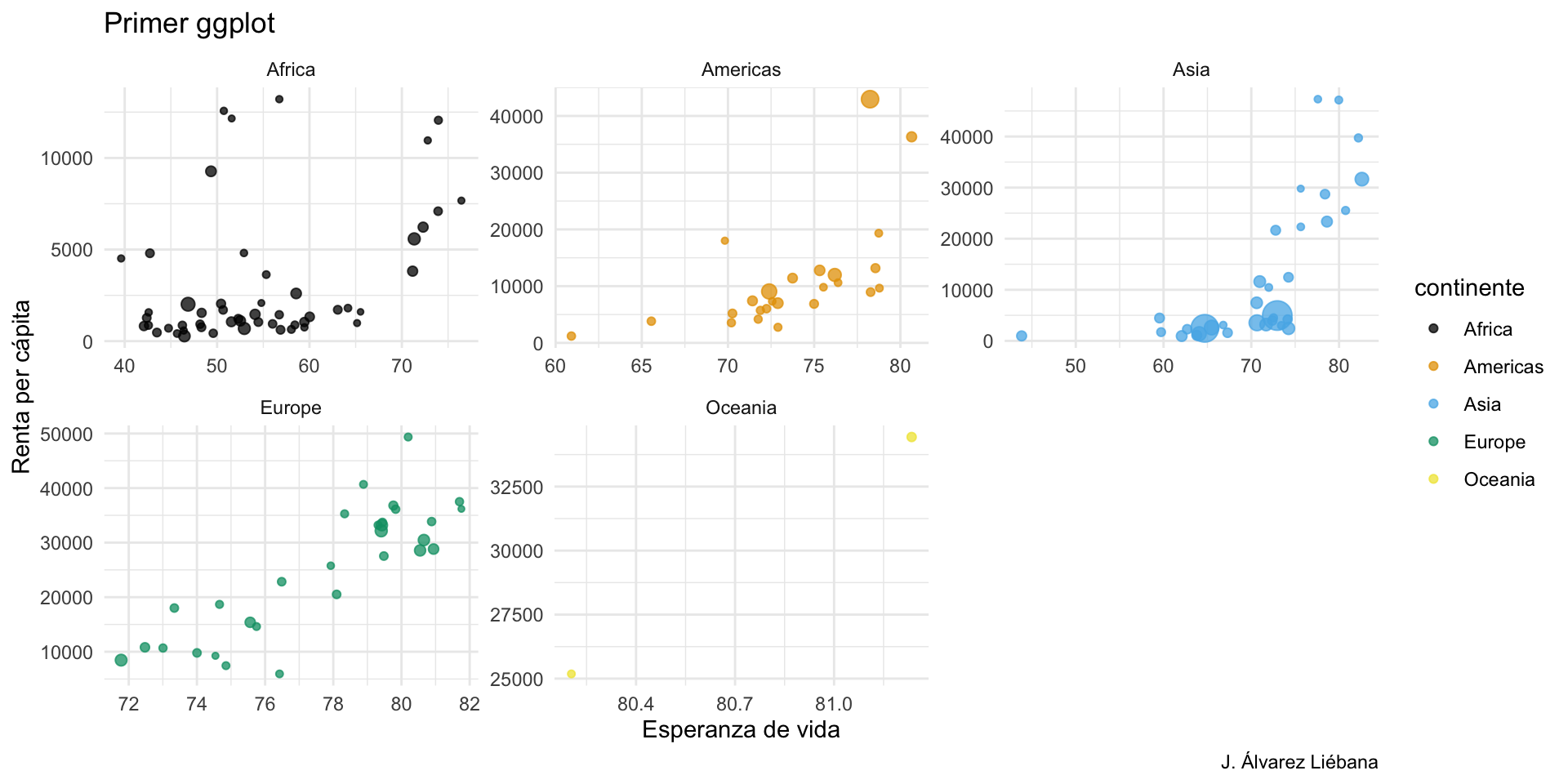
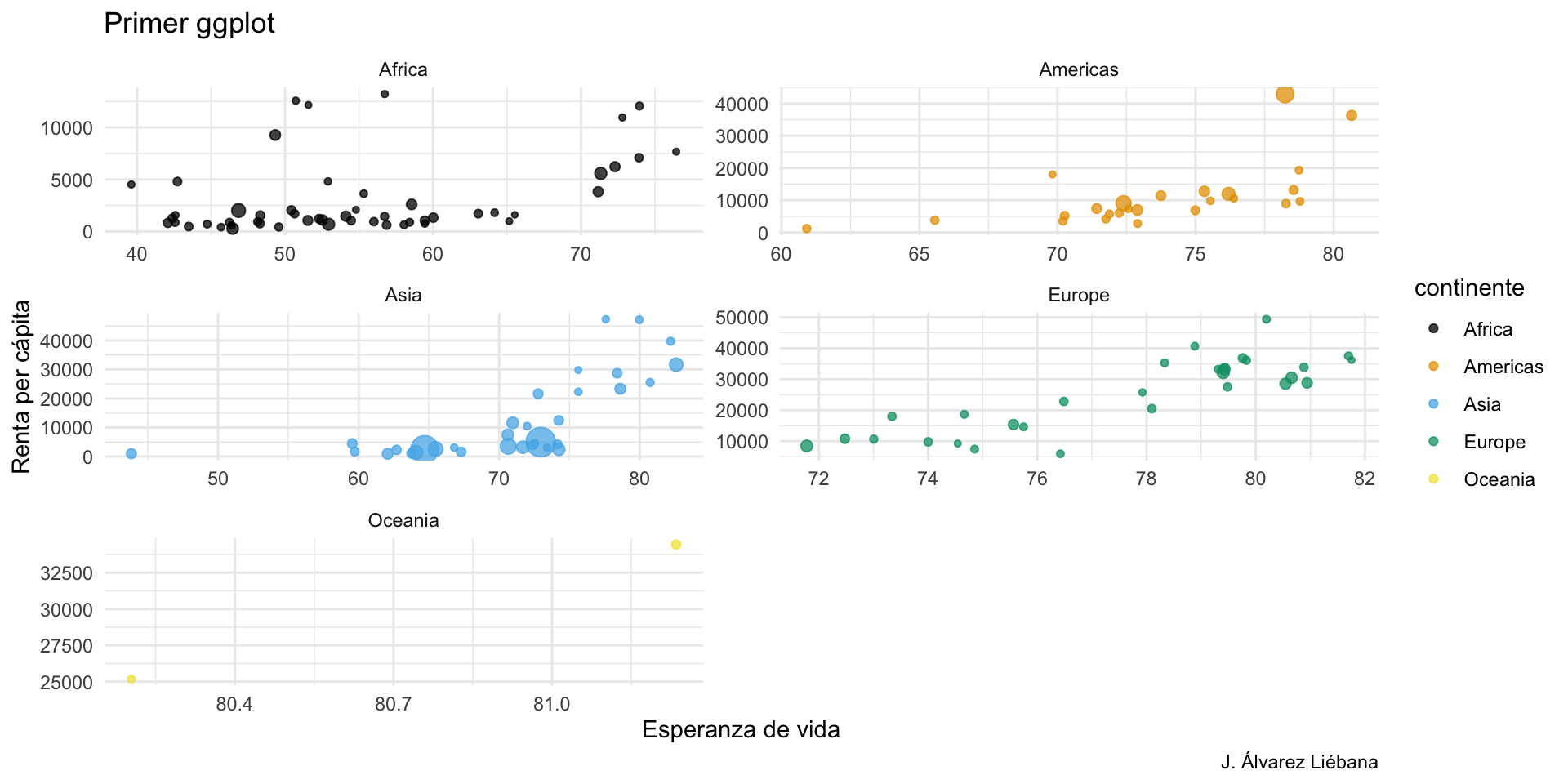
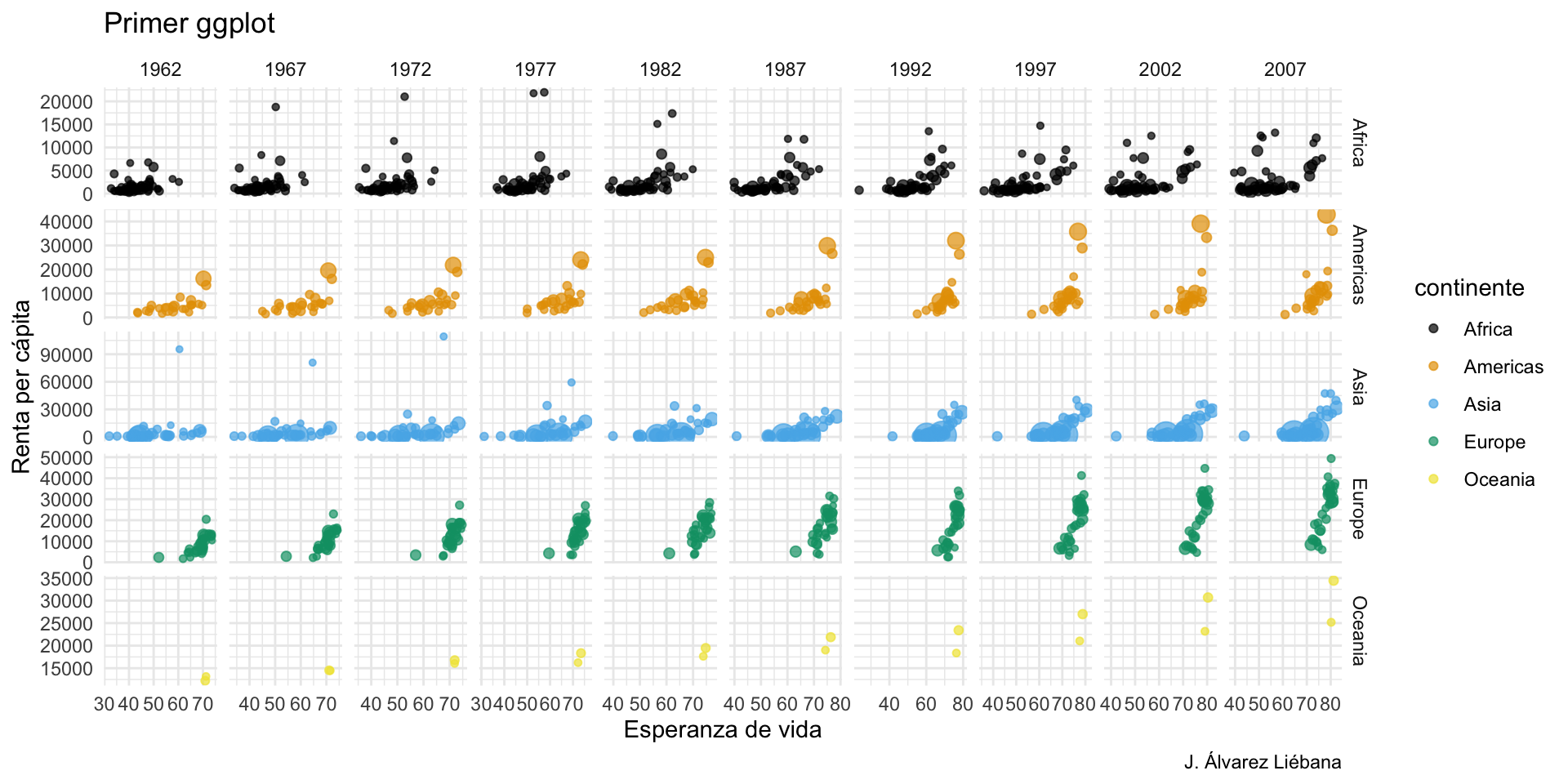
En el paquete {datasets} (ya instalado por defecto) tenemos diversos conjuntos de datos y uno de ellos es airquality. Debajo te he extraído 3 variables de dicho dataset (fíjate que se hace con datos$variable, ese dolar será importante en el futuro).
Los datos capturan medidas diarias (n = 153 observaciones) de la calidad del aire en Nueva York, de mayo a septiembre de 1973. Se midieron 6 variables: niveles de ozono, radiación solar, viento, temperatura, mes y día.
Intenta responder a las preguntas planteadas en el workbook
Primera base de datos
Cuando analizamos datos solemos tener varias variables de cada individuo: necesitamos una «tabla» que las recopile. La opción más inmediata son las matrices: concatenación de variables del mismo tipo e igual longitud.
Imagina que tenemos estaturas y pesos de 4 personas. ¿Cómo crear un dataset con las dos variables?
La opción más habitual es usando cbind(): concatenamos (bind) vectores en forma de columnas (c)
También podemos construir la matriz por filas con la función rbind() (concatenar - bind - por filas - rows), aunque lo recomendable es tener cada variable en columna e individuo en fila como luego veremos.
rbind(estaturas, pesos) # Construimos la matriz por filas
Dado que ahora tenemos dos dimensiones en nuestros datos, para acceder a elementos con [] deberemos proporcionar dos índices separados por comas: índice de la fila y de la columna
datos_matriz[2, 1] # segunda fila, primera columna
estaturas
160
datos_matriz[1, 2] # primera fila, segunda columna
pesos
63
Primer intento: matrices
En algunas casos querremos obtener los datos totales de un individuo (una fila concreta pero todas las columnas) o los valores de toda una variable para todos los individuos (una columna concreta pero todas las filas). Para ello dejaremos sin rellenar uno de los índices
datos_matriz[2, ] # segundo individuo
estaturas pesos
160 70
datos_matriz[, 1] # primera variable
[1] 150 160 170 180
Mucho de lo aprendido con vectores podemos hacerlo con matrices, así podemos por ejemplo acceder a varias filas y/o columnas haciendo uso de las secuencias de enteros 1:n
datos_matriz[c(1, 3), 1] # primera variable para el primer y tercer individuo
[1] 150 170
Primer intento: matrices
También podemos definir una matriz a partir de un vector numérico, reorganizando los valores en forma de matriz (sabiendo que los elementos se van colocando por columnas).
z <-matrix(1:9, ncol =3) z
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
Incluso podemos definir una matriz de valores constantes, por ejemplo de ceros (para luego rellenar)
matrix(0, nrow =2, ncol =3)
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 0 0
Operaciones con matrices
Con las matrices sucede como con los vectores: cuando aplicamos una operación aritmética lo hacemos elemento a elemento
📝 Define la matriz x <- matrix(1:12, nrow = 4). Tras ello obtén los datos del primer individuo, los datos de la tercera variable, y el elemento (4, 1).
Code
x <-matrix(1:12, nrow =4)x[1, ] # primera filax[, 3] # tercera columnax[4, 1] # elemento (4, 1)
📝 Define una matriz de 2 variables y 3 individuos tal que cada variable capture la estatura y la edad 3 personas, de manera que la edad de la segunda persona sea desconocida (ausente). Tras ello calcula la media de cada variable (¡nos debe de volver un número!)
Code
datos <-cbind("edad"=c(20, NA, 25), "estatura"=c(160, 165, 170))apply(datos, MARGIN =2, FUN ="mean", na.rm =TRUE) # media por columnas
📝 ¿Por qué devuelve error el código inferior? ¿Qué está mal?
Las matrices tienen el mismo problema que los vectores: si juntamos datos de distinto tipo, se perturba la integridad del dato ya que los convierte (fíjate en el código inferior: las edades y los TRUE/FALSE los ha convertido a texto)
edades soltero nombres
[1,] "14" "TRUE" "javi"
[2,] "24" NA "laura"
[3,] NA "FALSE" "lucía"
De hecho al no ser números ya no podemos realizar operaciones aritméticas
matriz +1
Error in matriz + 1: non-numeric argument to binary operator
Segundo intento: data.frame
Para poder trabajar con variables de distinto tipo tenemos en R lo que se conoce como data.frame: concatenación de variables de igual longitud pero que pueden ser de tipo distinto.
tabla <-data.frame(edades, soltero, nombres)class(tabla)
[1] "data.frame"
tabla
edades soltero nombres
1 14 TRUE javi
2 24 NA laura
3 NA FALSE lucía
Segundo intento: data.frame
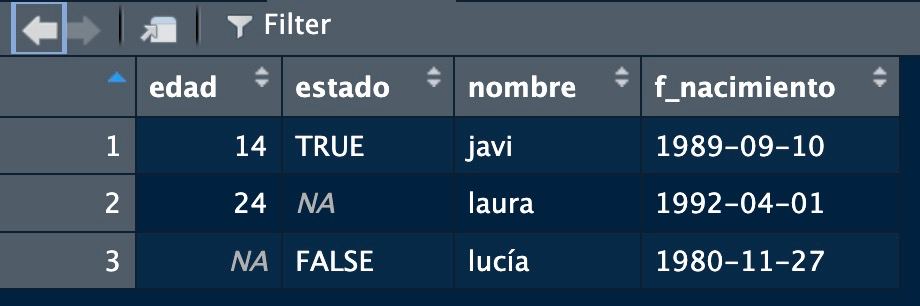
Dado que un data.frame es ya un intento de «base de datos» las variables no son meros vectores matemáticos: tienen un significado y podemos (debemos) ponerles nombres que describan su significado
edad estado nombre f_nacimiento
1 14 TRUE javi 1989-09-10
2 24 NA laura 1992-04-01
3 NA FALSE lucía 1980-11-27
Segundo intento: data.frame
¡TENEMOS NUESTRO PRIMER CONJUNTO DE DATOS! (estrictamente no podemos hablar de base de datos pero de momento como lo si fuesen). Puedes visualizarlo escribiendo su nombre en consola o con View(tabla)
Acceso a variables
Si queremos acceder a sus elementos, al ser de nuevo datos tabulados, podemos acceder como en las matrices (no recomendable): de nuevo tenemos dos índices (filas y columnas, dejando libre la que no usemos)
tabla[2, ] # segunda fila (todas sus variables)
edad estado nombre f_nacimiento
2 24 NA laura 1992-04-01
tabla[, 3] # tercera columna (de todos los individuos)
[1] "javi" "laura" "lucía"
tabla[2, 1] # primera característica de la segunda persona
[1] 24
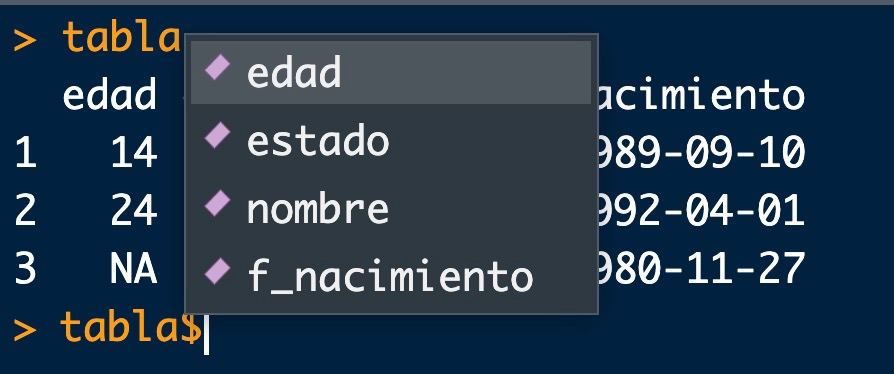
Pero también tiene las ventajas de una «base» de datos : podemos aceder a las variables por su nombre (lo recomendable ya que las variables pueden cambiar de posición y ahora sí tienen un significado), poniendo el nombre de la tabla seguido del símbolo $ (con el tabulador, nos aparecerá un menú de columnas a elegir)
Funciones de consulta
names(): nos muestra los nombres de las variables
names(tabla)
[1] "edad" "estado" "nombre" "f_nacimiento"
dim(): nos muestra las dimensiones (también nrow() y ncol())
dim(tabla)
[1] 3 4
Podemos acceder a las variables por su nombre
tabla[c(1, 3), "nombre"]
[1] "javi" "lucía"
tabla$nombre[c(1, 3)]
[1] "javi" "lucía"
Añadir variable
Si tenemos uno ya creado y queremos añadir una columna es tan simple como usar la función data.frame() que ya hemos visto para concatenar la columna. Vamos añadir por ejemplo una nueva variable, el número de hermanos de cada individuo.
# Añadimos una nueva columna con nº de hermanos/ashermanos <-c(0, 2, 3)tabla <-data.frame(tabla, "n_hermanos"= hermanos)tabla
edad estado nombre f_nacimiento n_hermanos
1 14 TRUE javi 1989-09-10 0
2 24 NA laura 1992-04-01 2
3 NA FALSE lucía 1980-11-27 3
Intento final: tibble
Las tablas en formato data.frame tienen algunas limitaciones. La principal es que no permite la recursividad: imagina que definimos una base de datos con estaturas y pesos, y queremos una tercera variable con el IMC
📝 Carga del paquete {datasets} el conjunto de datos airquality (variables de la calidad del aire de Nueva York desde mayo hasta septiembre de 1973). ¿Es el conjunto de datos airquality de tipo tibble? En caso negativo, conviértelo a tibble (busca en la documentación del paquete en https://tibble.tidyverse.org/index.html).
📝 Una vez convertido a tibble obtén el nombre de las variables y las dimensiones del conjunto de datos. ¿Cuántas variables hay? ¿Cuántos días se han medido?
📝 Modifica el código inferior para filtrar solo los datos del mes de agosto. ¿Cómo indicarle que queremos solo las filas que cumplan una condición concreta? (pista: en realidad todo son vectores “formateados”)
airquality_tb[Month ==8, ]
Code
airquality_tb[airquality_tb$Month ==8, ]
📝 Selecciona aquellos datos que no sean ni de julio ni de agosto.
Code
airquality_tb[airquality_tb$Month !=7& airquality_tb$Month !=8, ]# otra formaairquality_tb[!(airquality_tb$Month %in%c(7, 8)), ]
📝 Modifica el siguiente código para quedarte solo con las variable de ozono y temperatura (sin importar qué posición ocupen)
airquality_tb[, 3]
📝 Selecciona los datos de temperatura y viento de agosto.
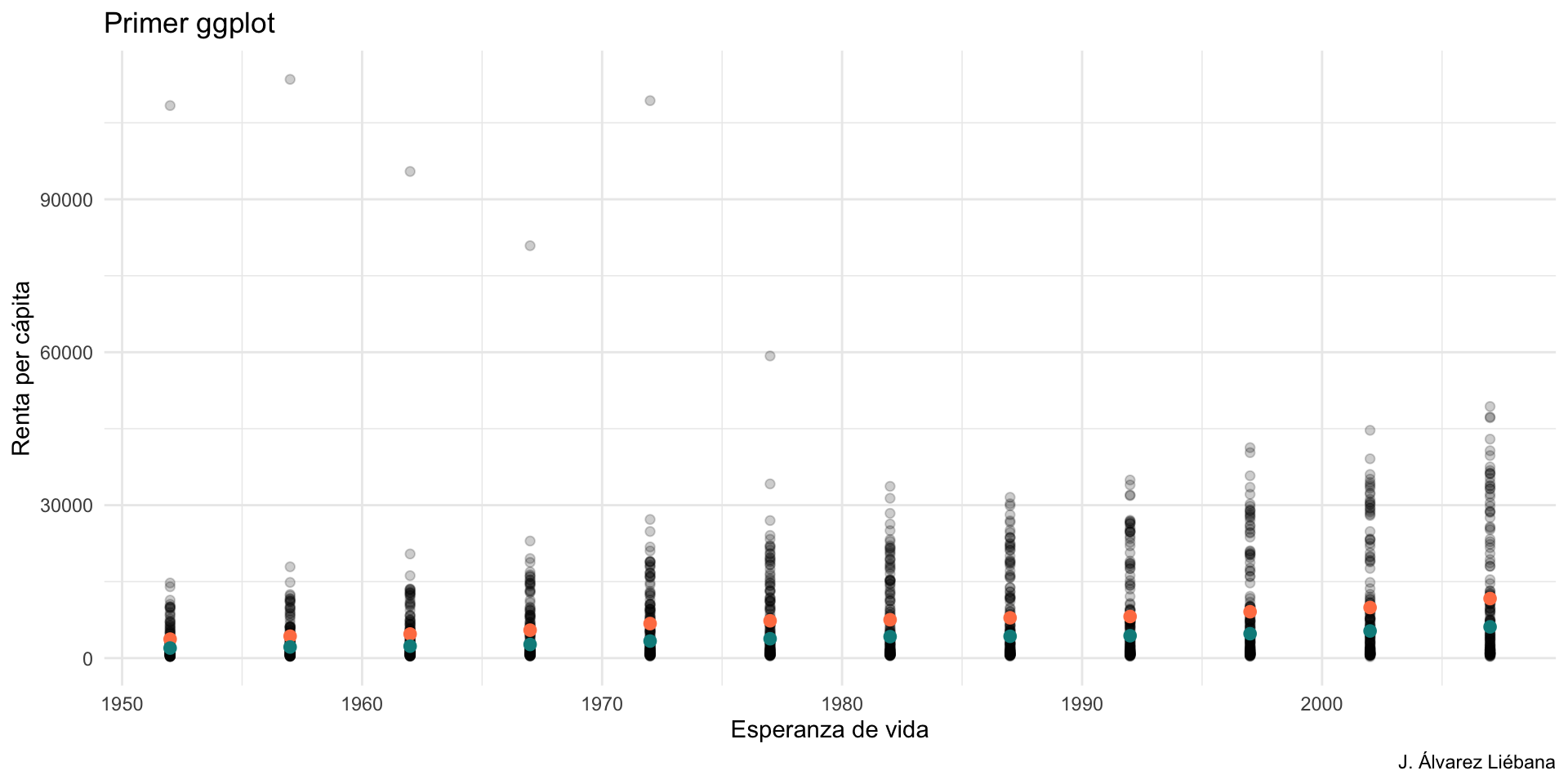
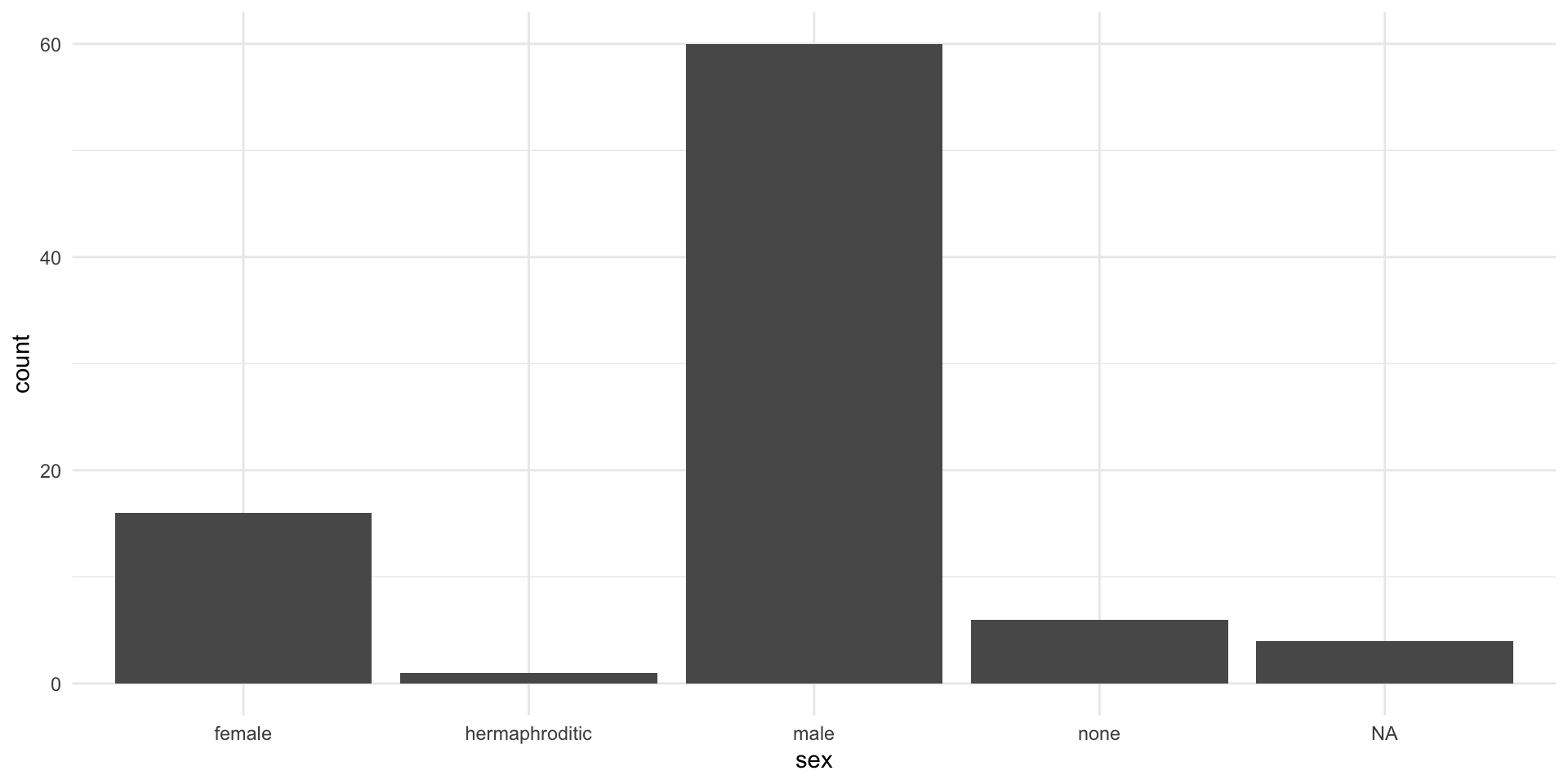
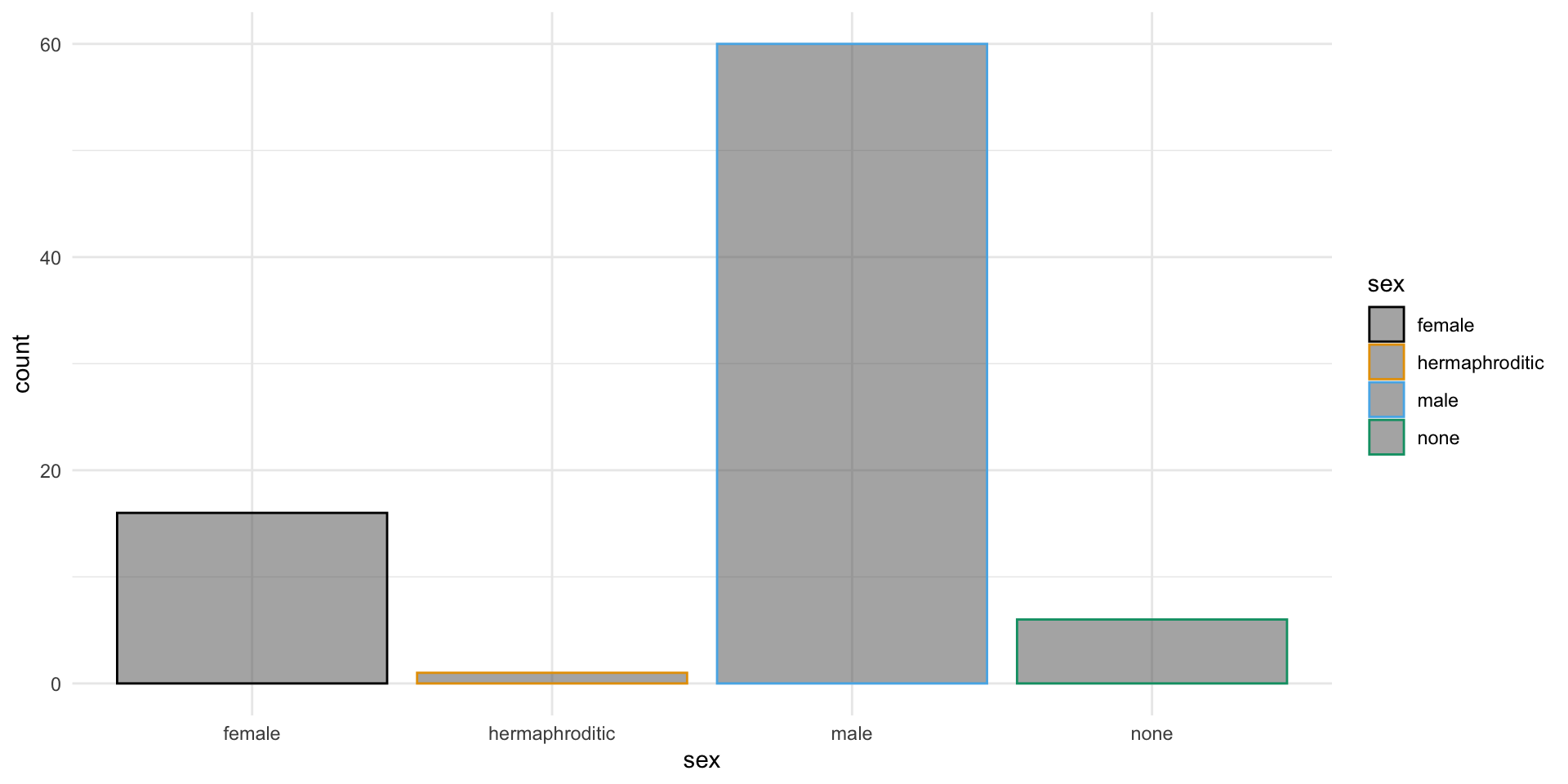
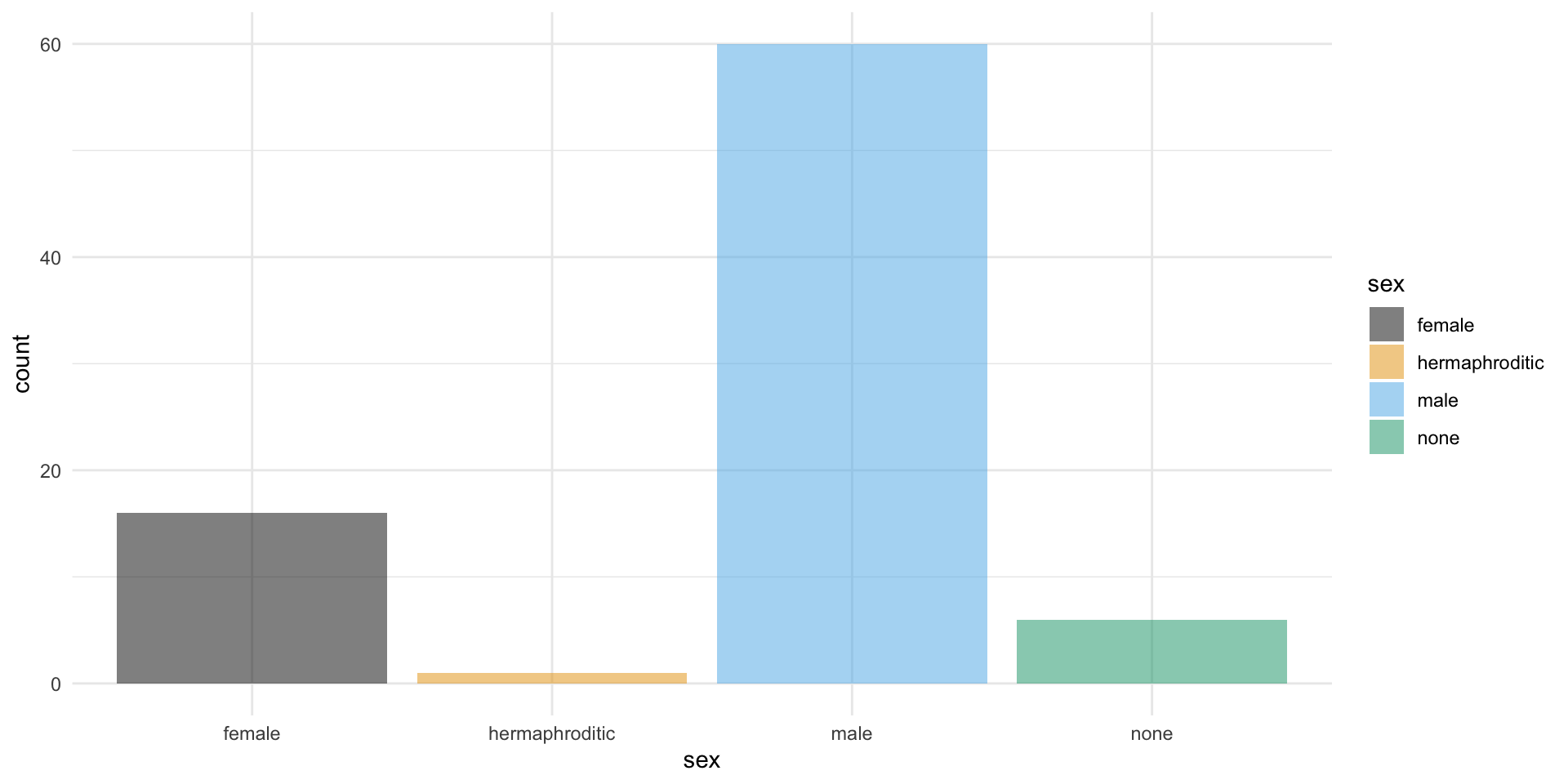
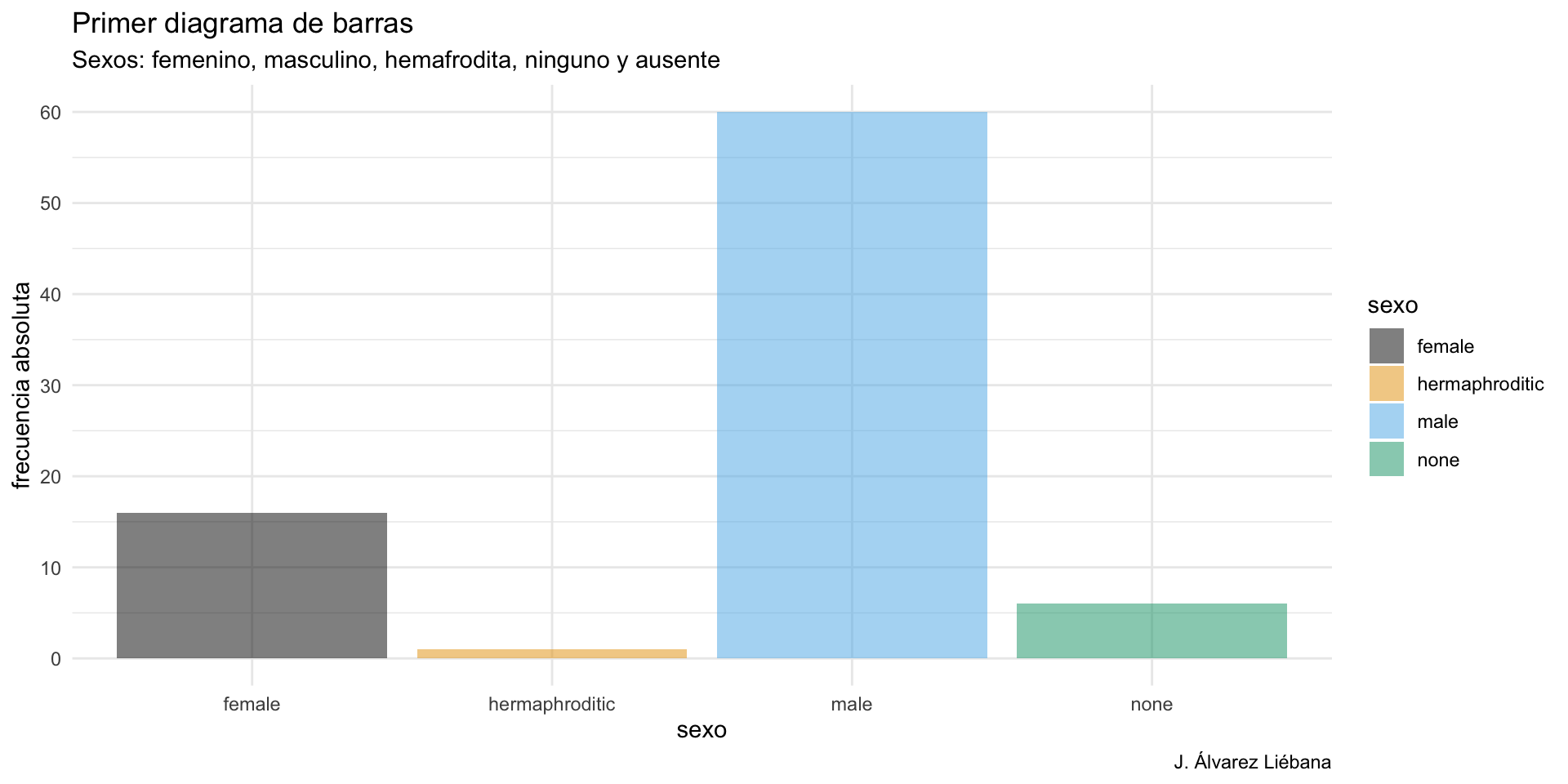
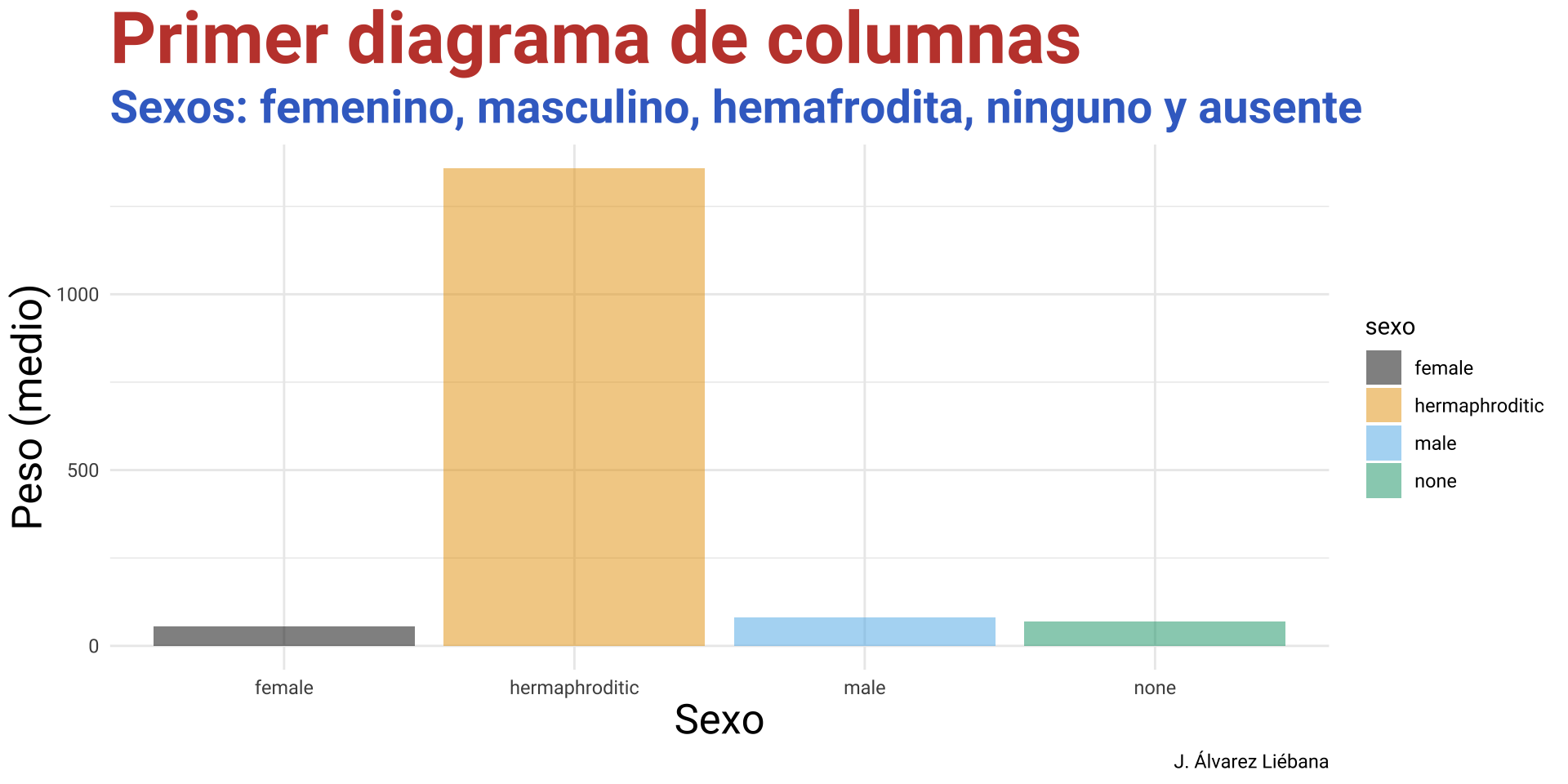
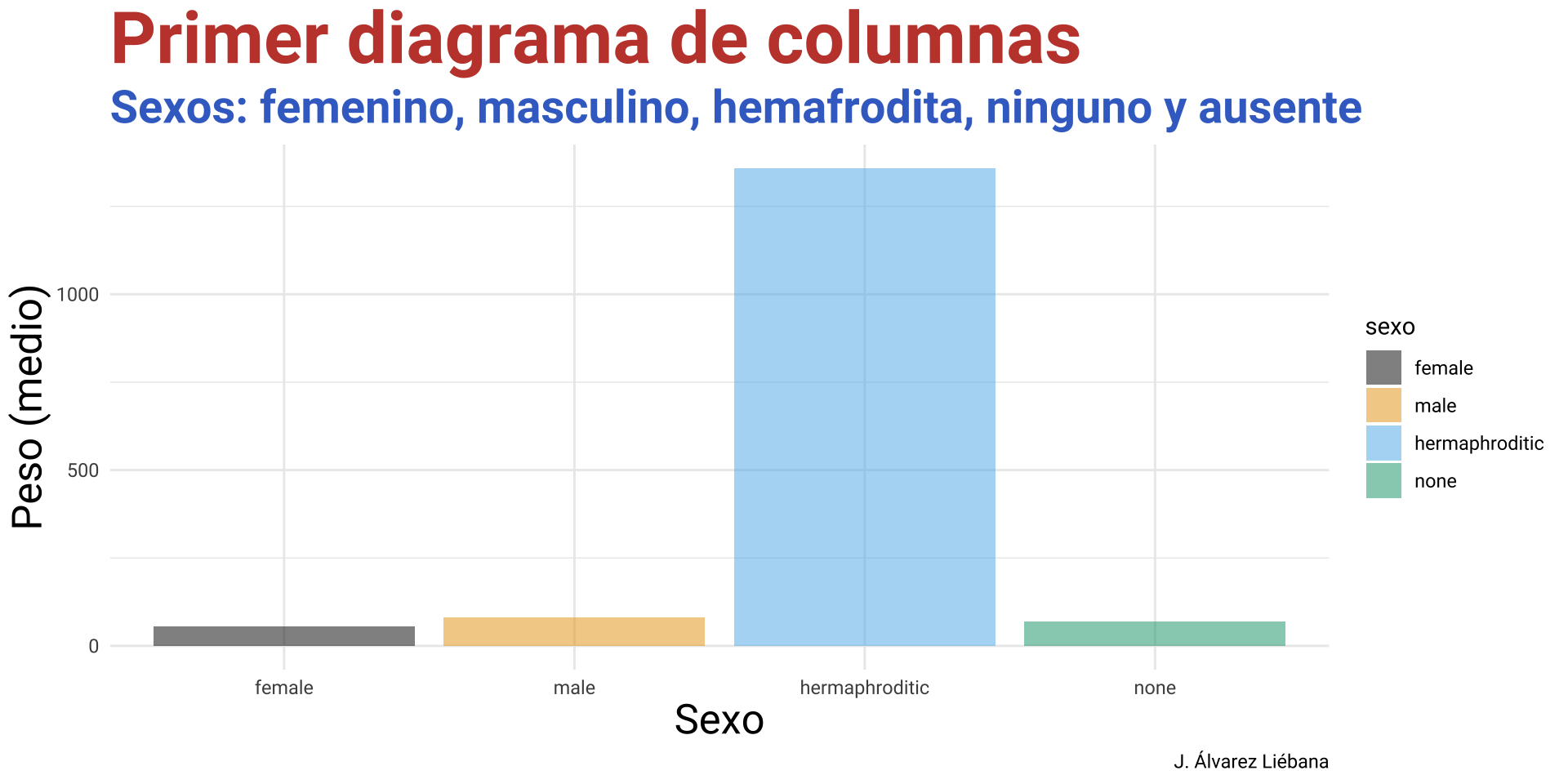
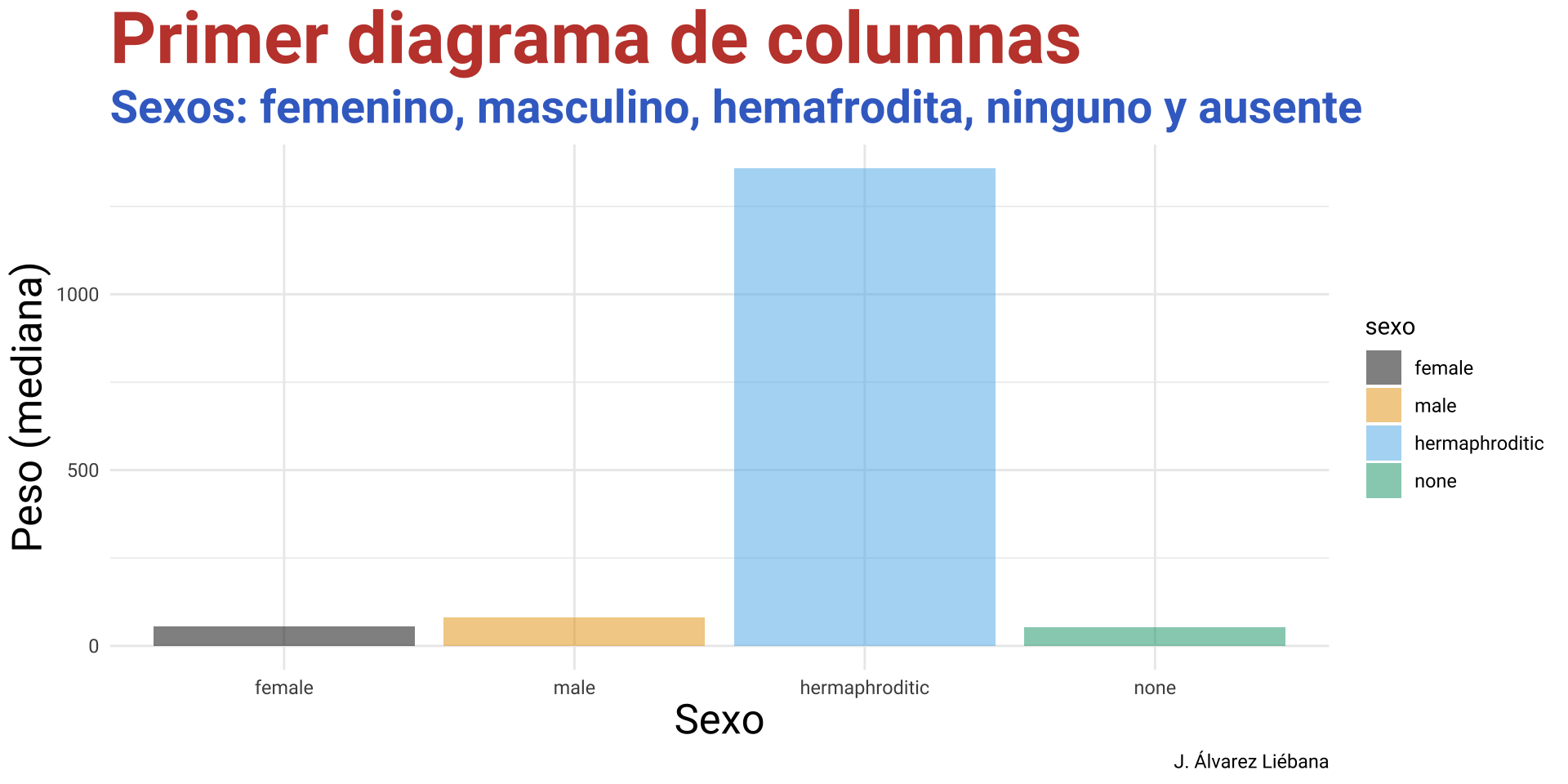
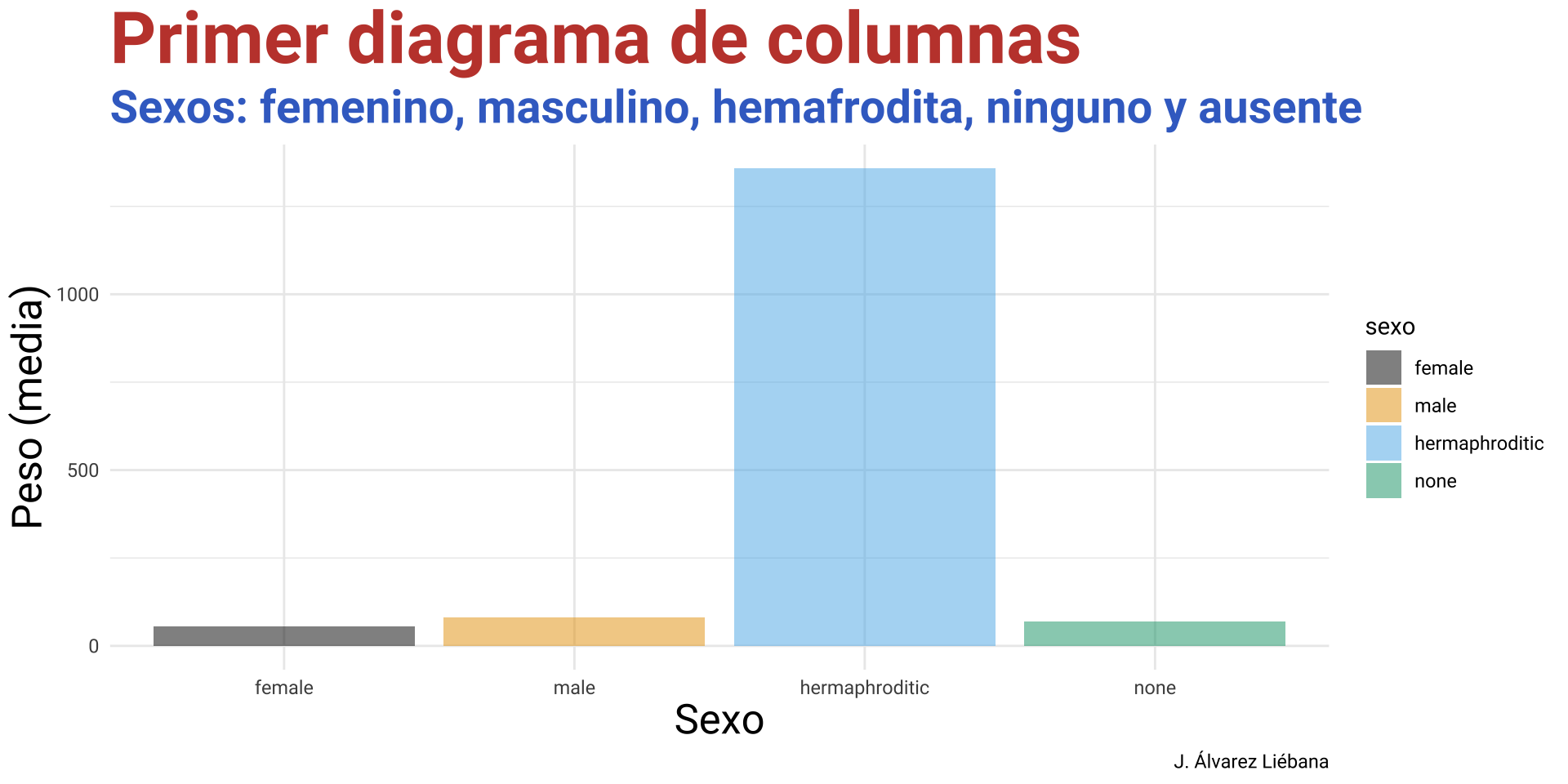
Del paquete {Biostatistics} usaremos el conunto de datos pinniped, que guarda los datos de peso de cuerpo y cerebro (desagregado por sexo y mono/poligamia) de 33 especies de mamíferos marinos.
Una de las principales fortalezas de R es la facilidad para generar informes, libros, webs, apuntes y hasta diapositivas (este mismo material por ejemplo). Para ello instalaremos antes
el paquete {rmarkdown} (para generar archivos .rmd)
install.packages("rmarkdown")
instalar Quarto (si ya conocías R, el «nuevo» .rmd ahora como .qmd)
Comunicar: rmd y Quarto
Hasta ahora solo hemos programado en scripts (archivos .R) dentro de proyectos, pero en muchas ocasiones no trabajaremos solos y necesitaremos comunicar los resultados en diferentes formatos:
Los archivos de extensión .qmd (o .rmd antes) nos permitirán fácilmente combinar:
Markdown: lenguaje tipado que nos permite crear contenido simple (tipo wordpress, con texto, negritas, cursivas, etc) con un diseño legible.
Matemáticas (latex): lenguaje para escribir notación matemática como \(x^2\) o \(\sqrt{y}\) o \(\int_{a}^{b} f(x) dx\)
Código y salidas: podremos no solo mostrar el paso final sino el código que has ido realizando (en R, Python, C++, Julia, …), con cajitas de código llamadas CHUNKS.
Imágenes, gráficas, tablas, estilos (css, js), etc.
Comunicar: rmd y Quarto
La principal ventaja de realizar este tipo de material en Quarto/Rmarkdown es que, al hacerlo desde RStudio, puedes generar un informe o una presentación sin salirte del entorno de programación en el que estás trabajando
De esta forma podrás analizar los datos, resumirlos y a la vez comunicarlos con la misma herramienta.
Recientemente el equipo de RStudio desarrolló Quarto, una versión mejorada de Rmarkdown (archivos .qmd), con un formato un poco más estético y simple. Tienes toda la documentación y ejemplos en https://quarto.org/
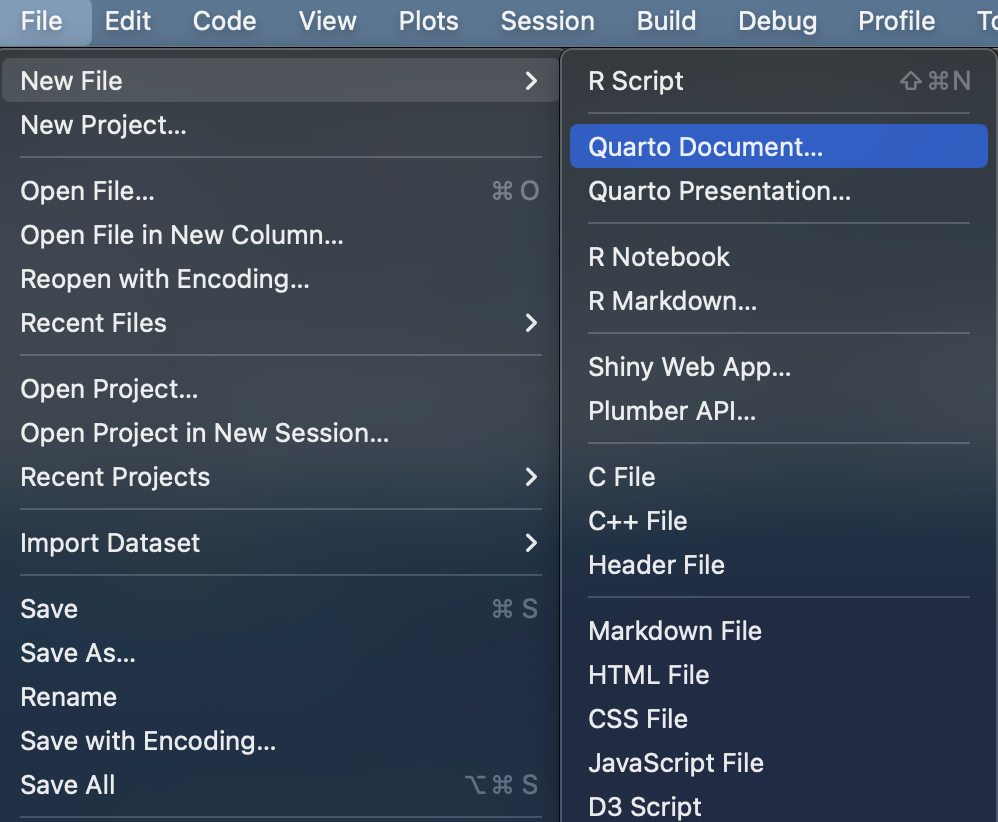
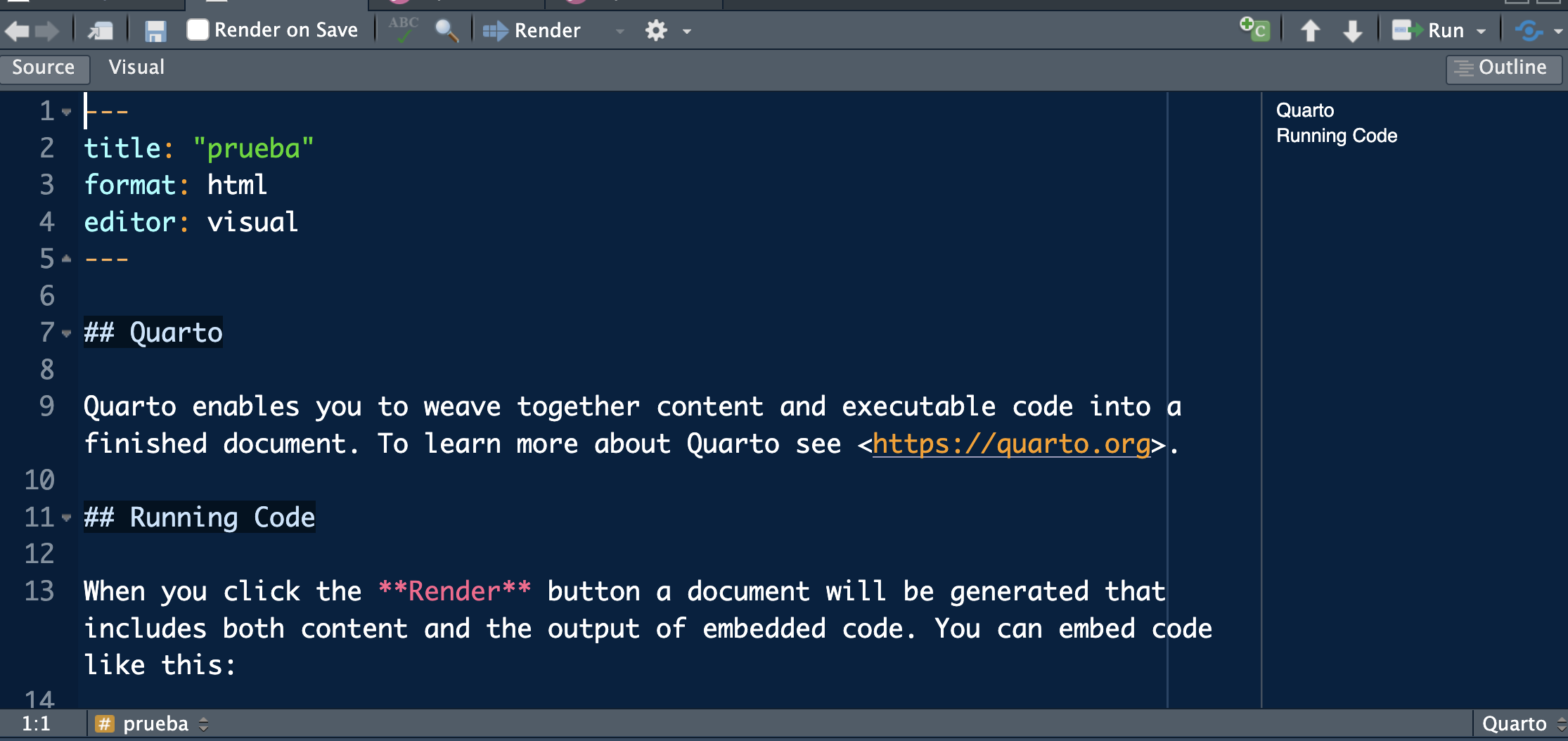
Vamos a crear el primer fichero rmarkdown con Quarto con extensión .qmd. Para ello solo necesitaremos hacer click en
File << New File << Quarto Document
Nuestro primer informe
Tras hacerlo nos aparecerán varias opciones de formatos de salida:
archivo .pdf
archivo .html (recomendable): documento dinámico, permite la interacción con el usuario, como una «página web».
archivo .doc (nada recomendable)
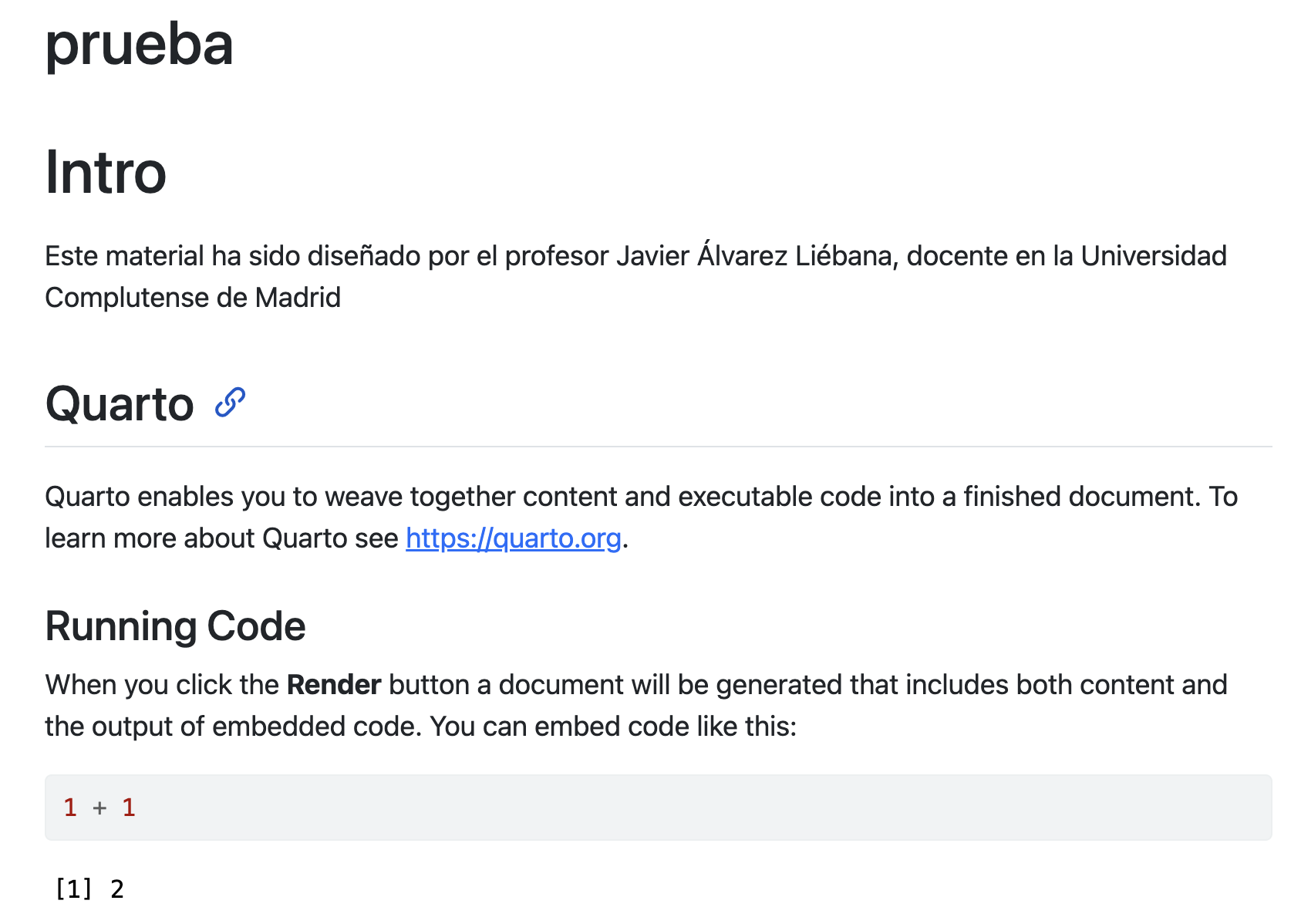
De momento dejaremos marcado el formato HTML que viene por defecto, y escribiremos el título de nuestro documento. Tras ello tendremos nuestro archivo .qmd (ya no es un script .R como los que hemos abierto hasta ahora).
Nuestro primer informe
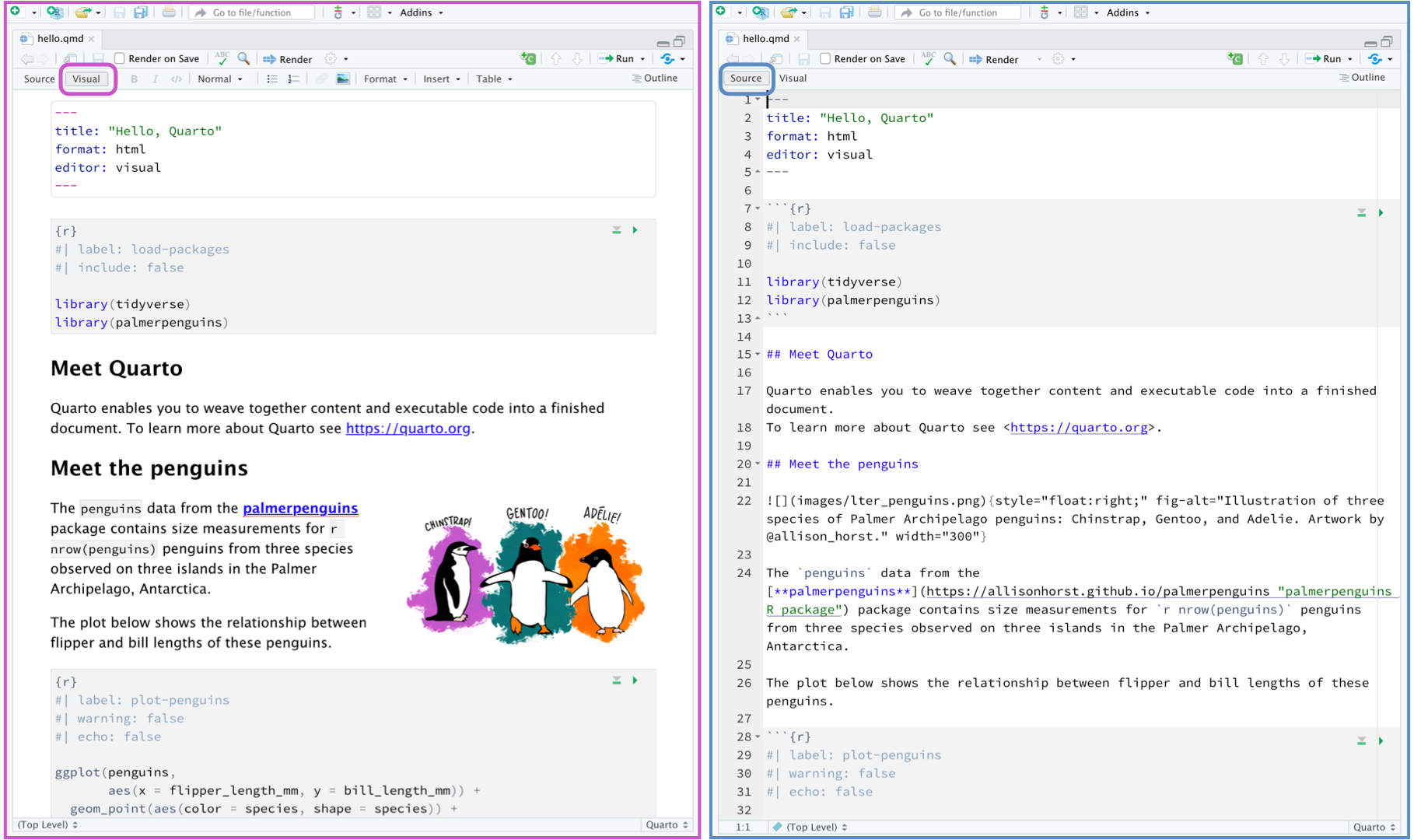
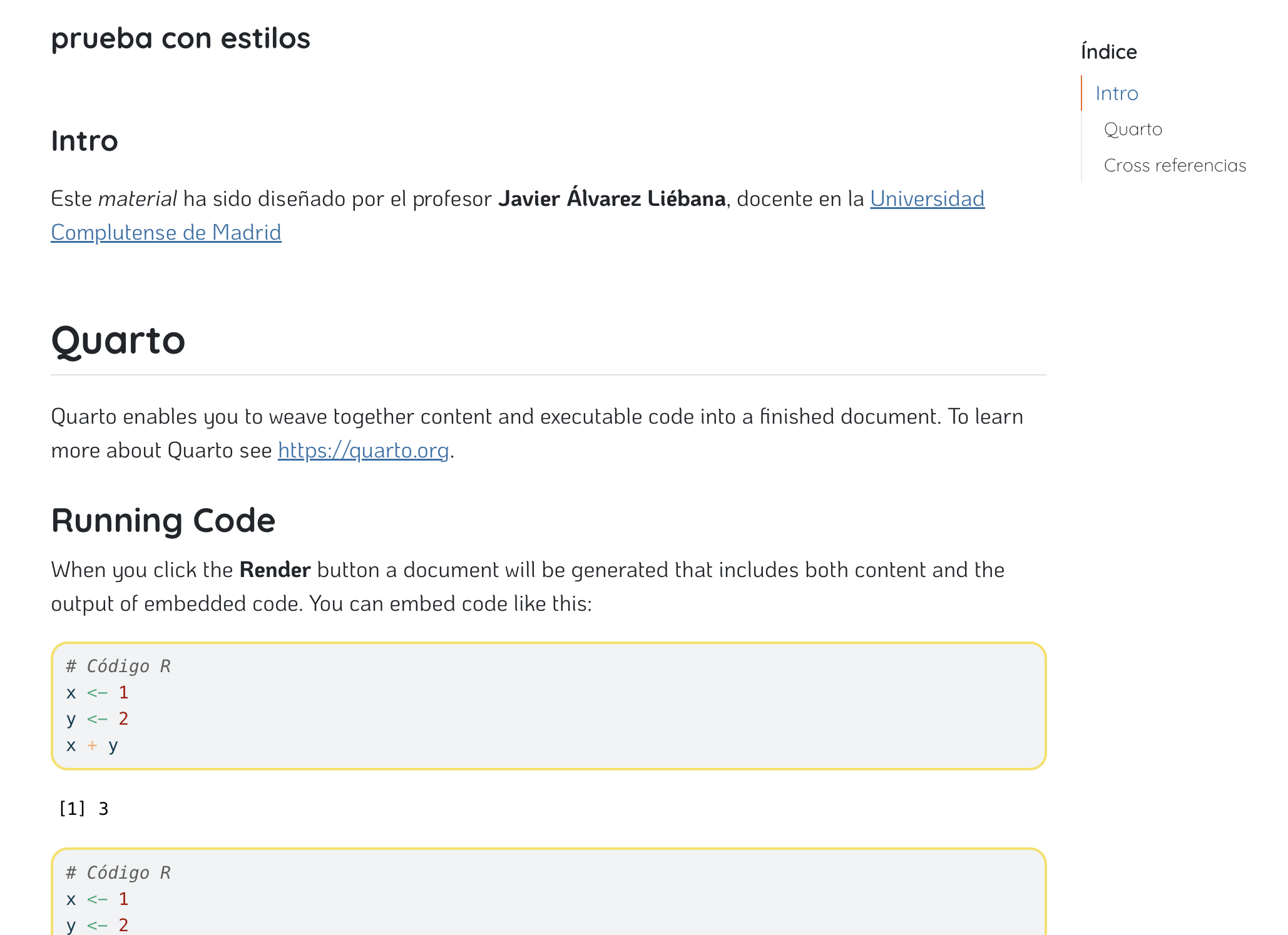
Deberías tener algo similar a la captura de la imagen con dos modos de edición: Source (con código, la opción recomendada hasta que lo domines) y Visual (más parecido a un blog)
Para ejecutar TODO el documento debes clickar Render on Save y darle a guardar.
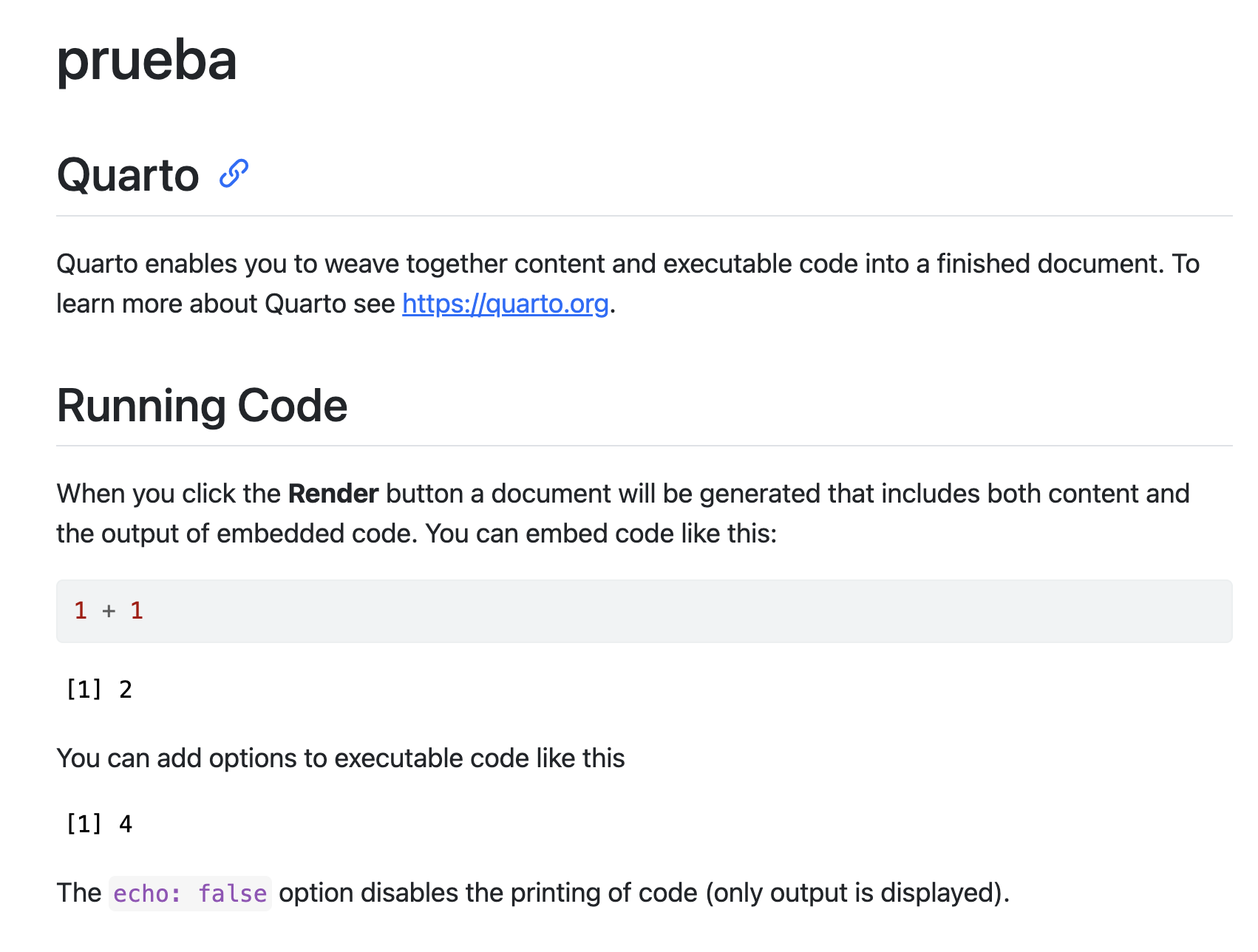
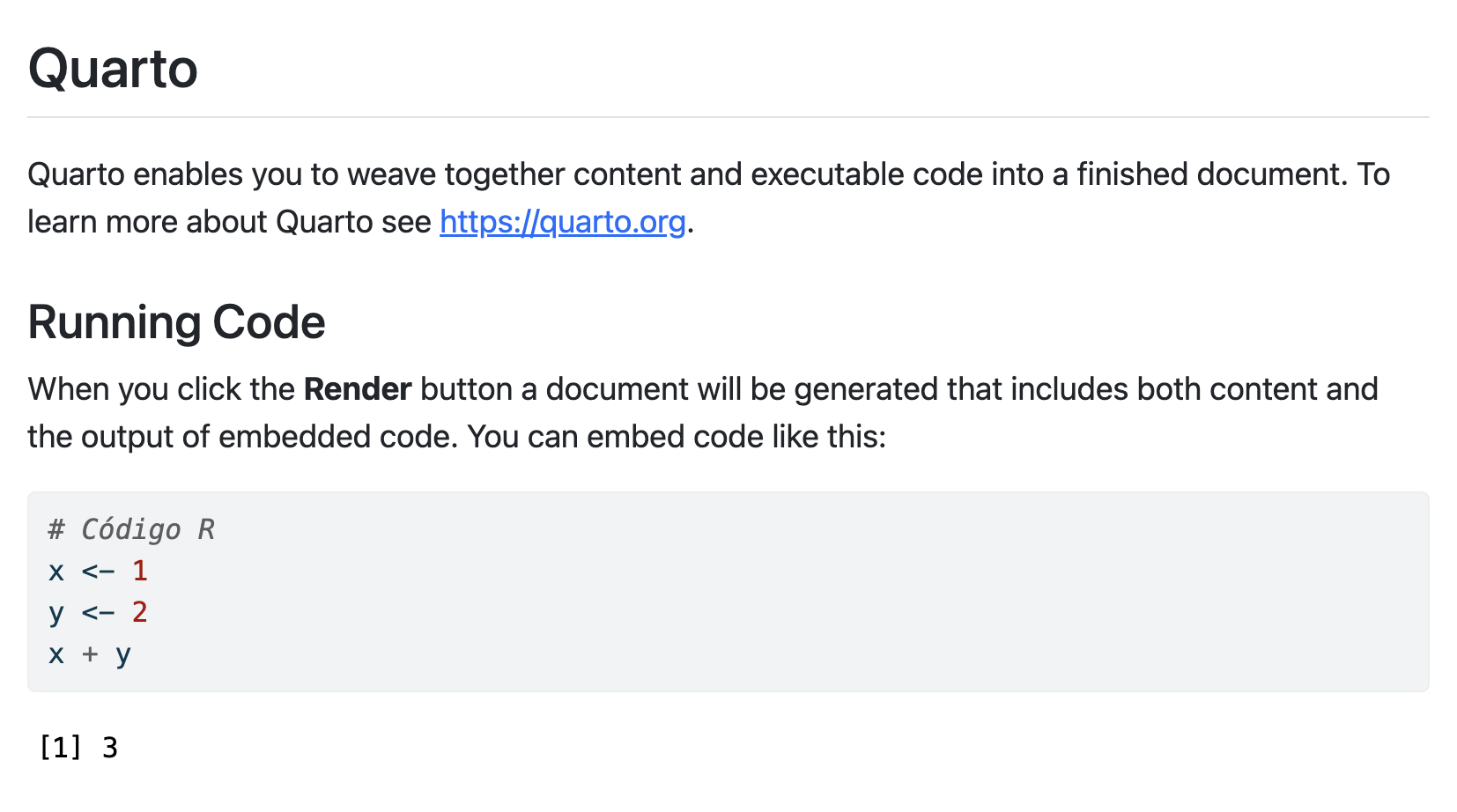
Salida de Quarto
Deberías haber obtenido una salida en html similar a esta (y se te ha generado en tu ordenador un archivo html)
Editor: source vs visual
Como se indicaba, tienes dos formas de trabajar: con código puro y algo parecido a un Notion (blog)
Un fichero .qmd se divide básicamente en tres partes:
Cabecera: la parte que tienes al inicio entre ---.
Texto: que podremos formatear y mejorar con negritas (escrito como negritas, con doble astérisco al inicio y final), cursivas (cursivas, con barra baja al inicio y final) o destacar nombres de funciones o variables de R. Puedes añadir ecuaciones como \(x^2\) (he escrito $x^2$, entre dólares).
Código R
Cabecera de un qmd
La cabecera están en formato YAML y contiene los metadatos del documento
title y subtitle: el título/subtítulo del documento
author: autor del mismo
format: formato de salida (podremos personalizar)
theme: si tienes algún archivo de estilos
toc: si quieres índice o no
toc-location: posición del índice
toc-title: título del índice
editor: si estás en modo visual o source.
---title:"prueba"format:html:editor: visual---
Cabecera de un qmd
La cabecera están en formato YAML y contiene los metadatos del documento
title y subtitle: el título/subtítulo del documento
Respecto a la escritura solo hay una cosa importante: salvo que indiquemos lo contrario, TODO lo que vamos a escribir es texto (normal). No código R.
Vamos a empezar escribiendo una sección al inicio (# Intro y detrás por ej. la frase
Este material ha sido diseñado por el profesor Javier Álvarez Liébana, docente en la Universidad Complutense de Madrid
Además al Running Code le añadiremos una almohadilla #: las almohadillas FUERA DE CHUNKS nos servirán para crear epígrafes (secciones) en el documento
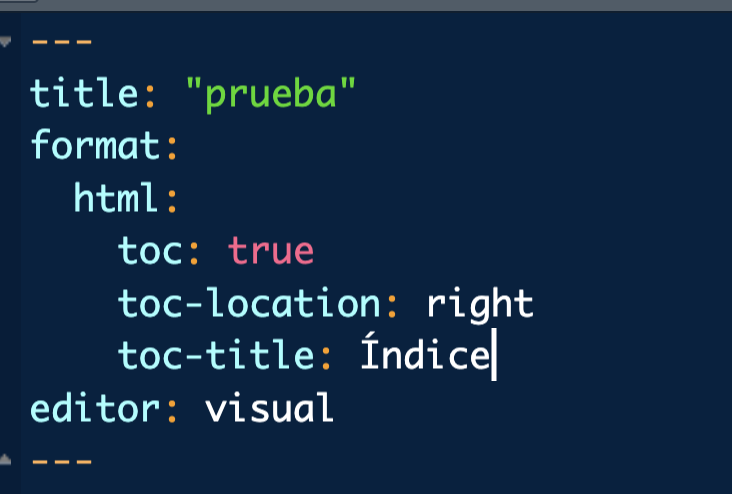
Índice de un qmd
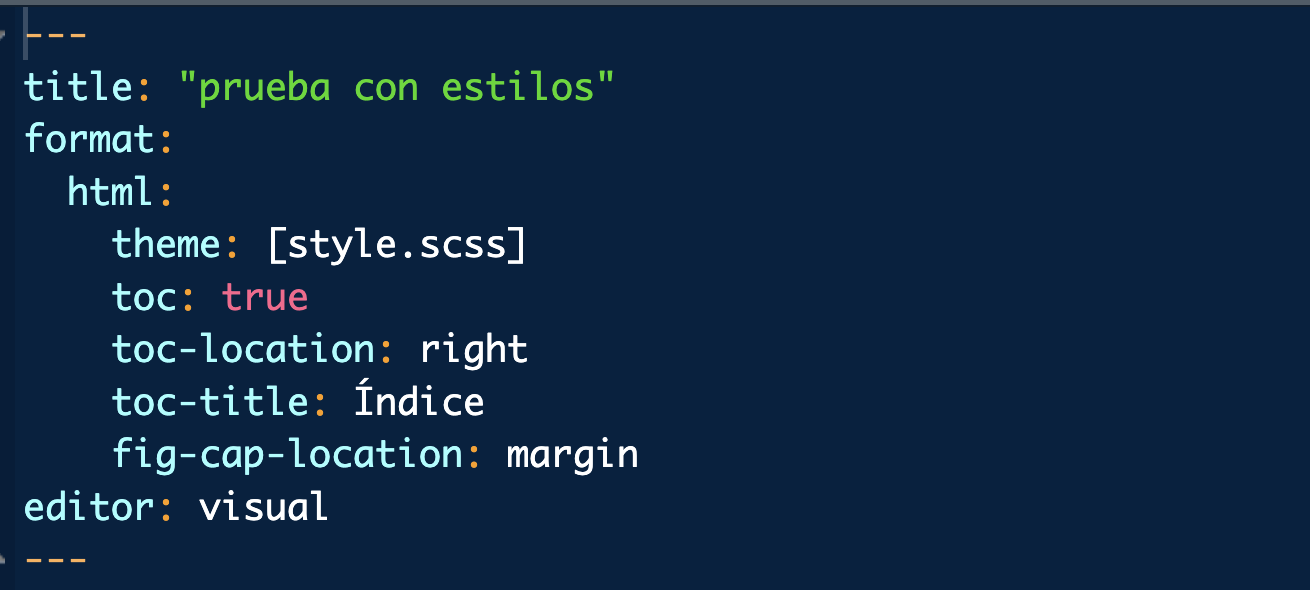
Para que el índice capture dichas secciones modificaremos la cabecera del archivo como se observa en la imagen (puedes cambiar la localización del índice y el título si quieres para probar).
Texto en un qmd
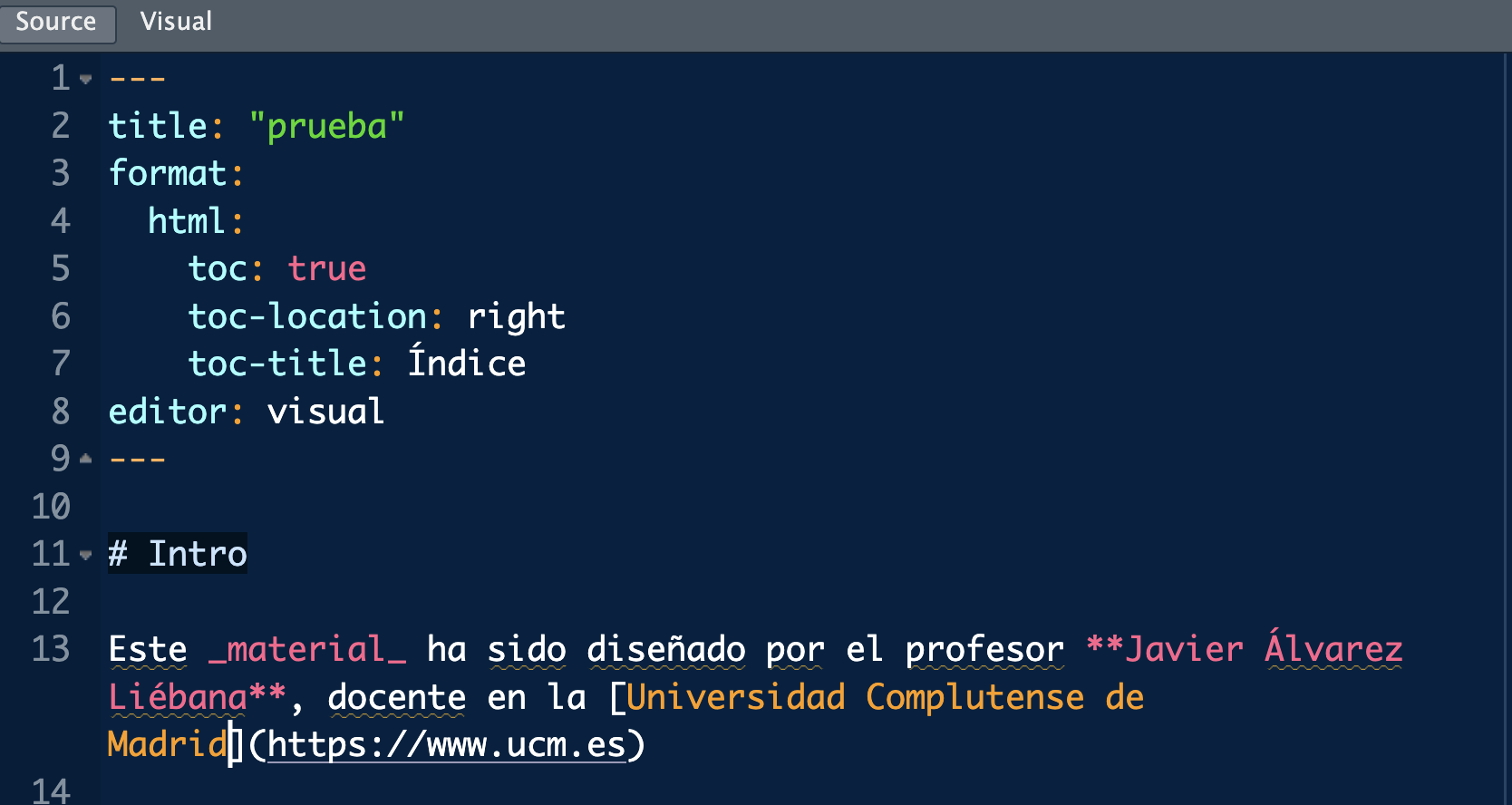
Vamos a personalizar un poco el texto haciendo lo siguiente:
Vamos a añadir negrita al nombre (poniendo ** al inicio y al final).
Vamos añadir cursiva a la palabra material (poniendo _ al inicio y al final).
Vamos añadir un enlacehttps://www.ucm.es, asociándolo al nombre de la Universidad. Para ello el título lo ponemos entre corchetes y justo detrás el enlace entre paréntesis [«Universidad Complutense de Madrid»](https://www.ucm.es)
Código en un qmd
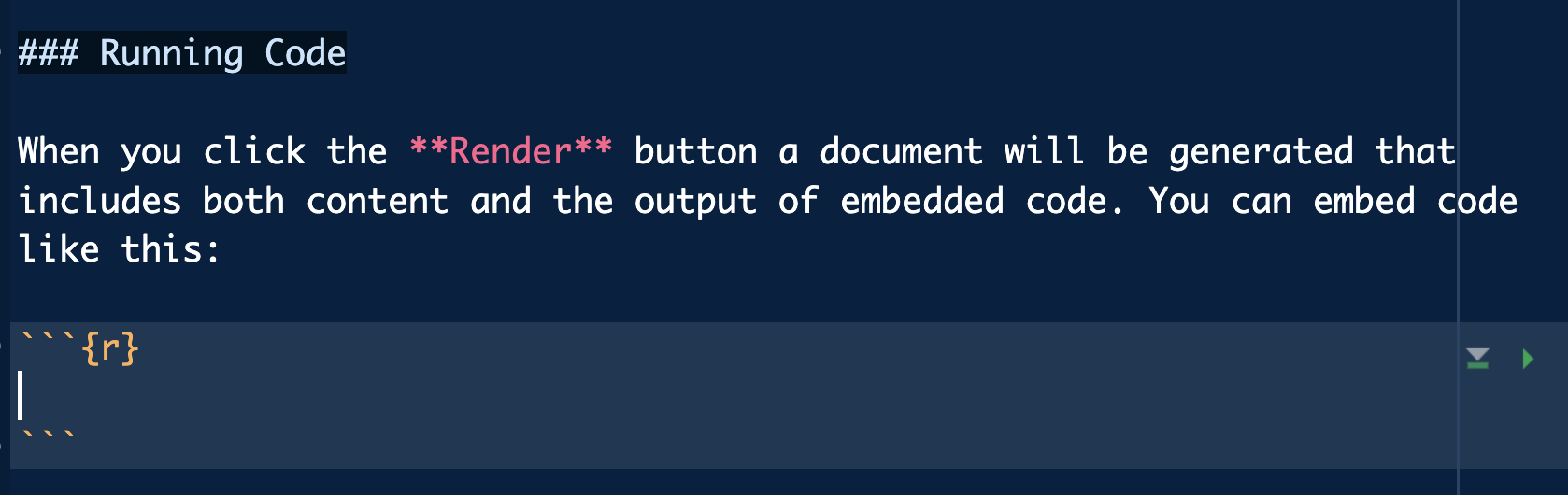
Para añadir código R debemos crear nuestras cajas de código llamadas chunks: altos en el camino en nuestro texto markdown donde podremos incluir código de casi cualquier lenguaje (y sus salidas).
Para incluir uno deberá de ir encabezado de la siguiente forma tienes un atajo Command + Option + I (Mac) o Ctrl + Shift + I (Windows)
Código en un qmd
Dentro de dicha cajita (que tiene ahora otro color en el documento) escribiremos código R como lo veníamos haciendo hasta ahora en los scripts.
Vamos por ejemplo a definir dos variables y su suma de la siguiente manera, escribiendo dicho código en nuestro .qmd (dentro de ese chunk)
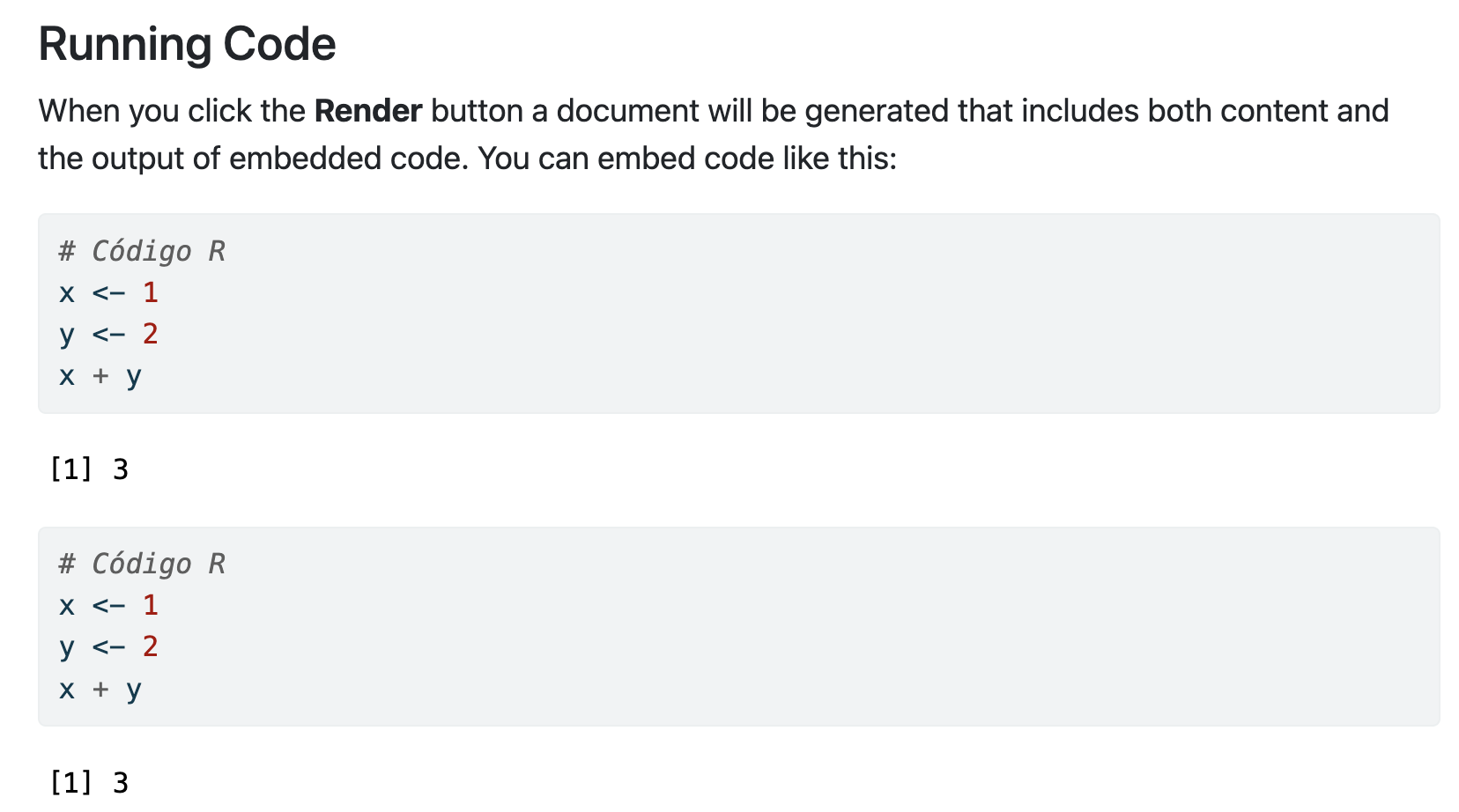
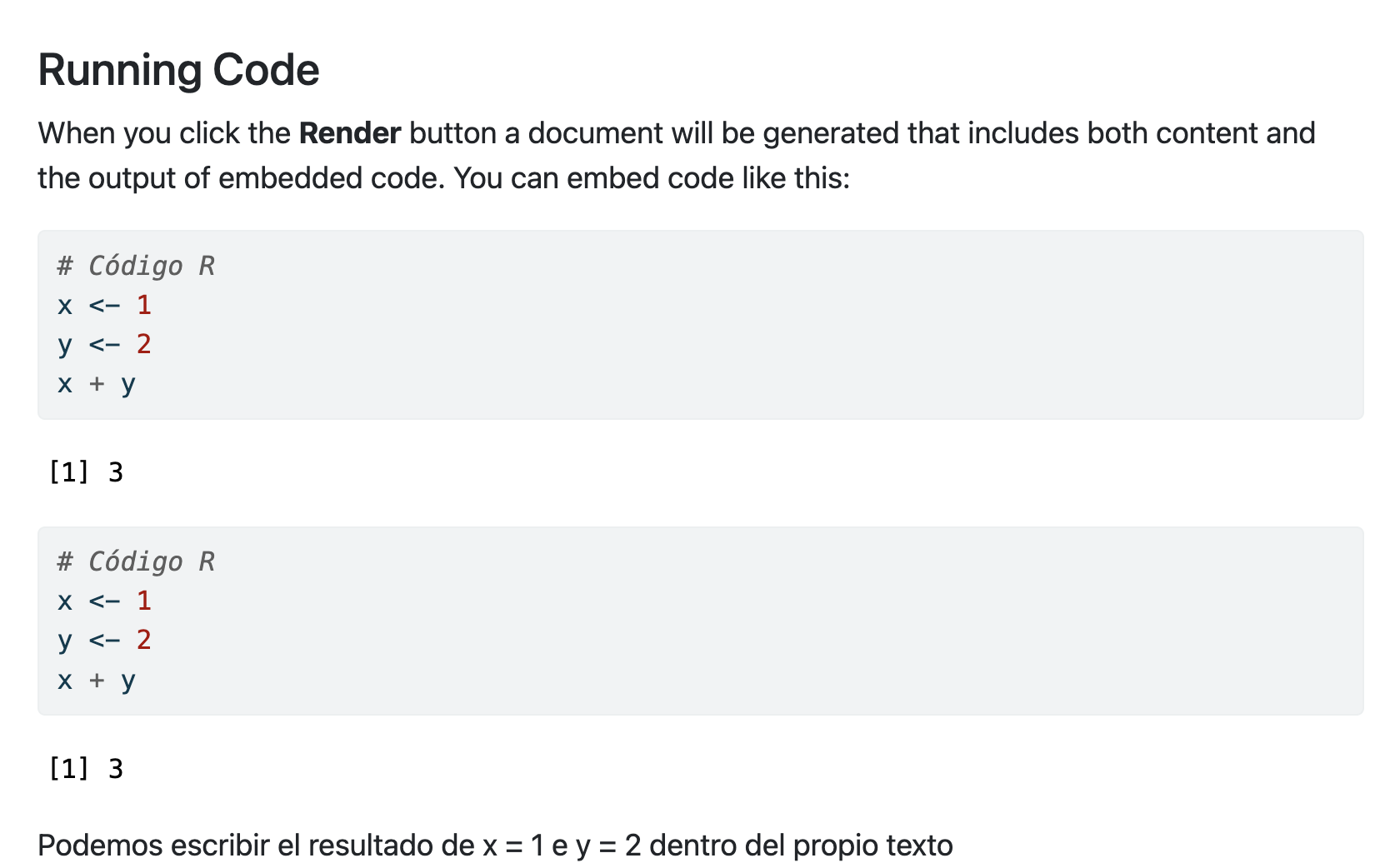
# Código Rx <-1y <-2x + y
[1] 3
Etiquetando chunks
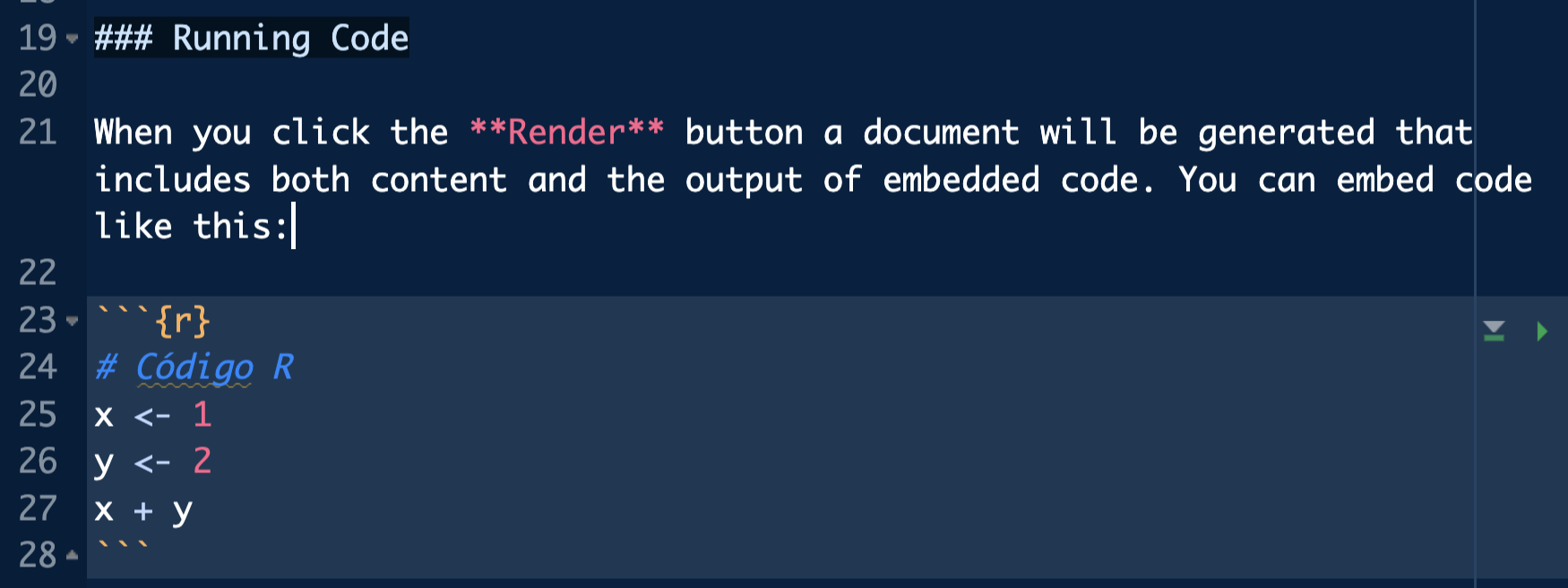
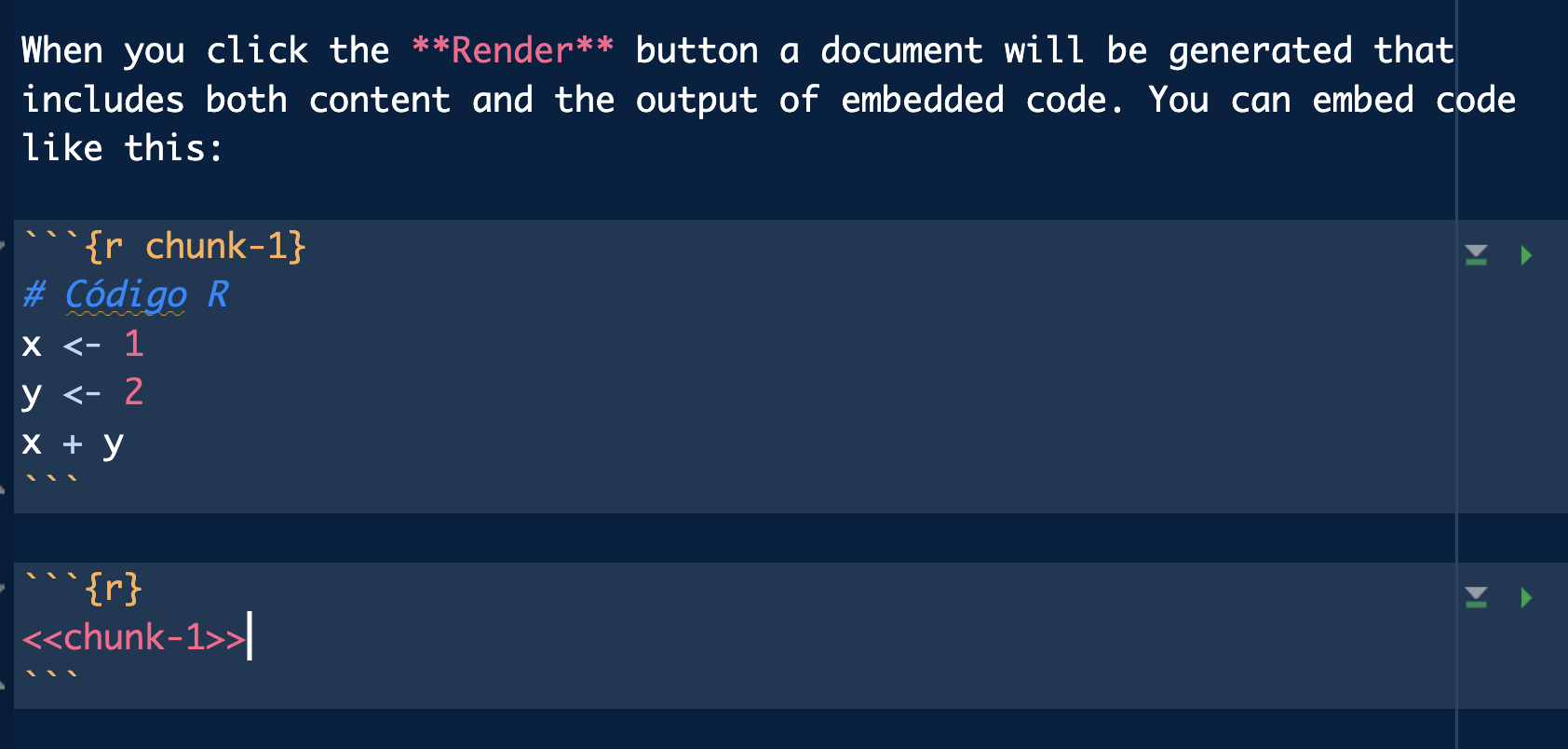
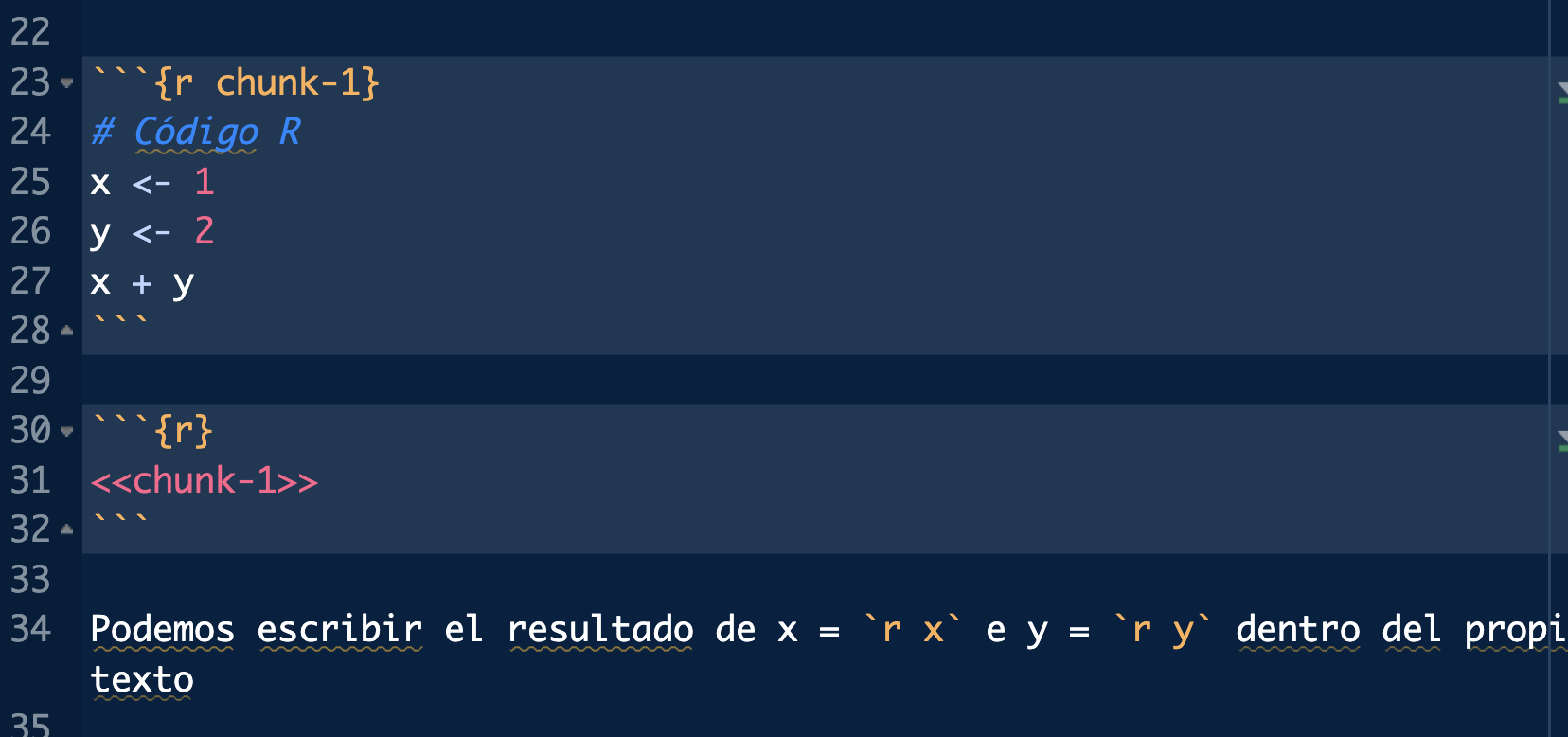
Los chunks pueden tener un nombre o etiqueta, de forma que podamos referenciarlos de nuevo para no repetir código.
Ejecutando chunks
En cada chunk aparecen dos botones:
botón de play: activa la ejecución y salida de ese chunk particular (lo puedes visualizar dentro de tu propio RStudio)
botón de rebobinar: activa la ejecución y salida de todos los chunk hasta ese (sin llegar a él)
Además podemos incluir código R dentro de la línea de texto (en lugar de mostrar el texto x ejecuta el código R mostrando la variable).
Personalización de chunks
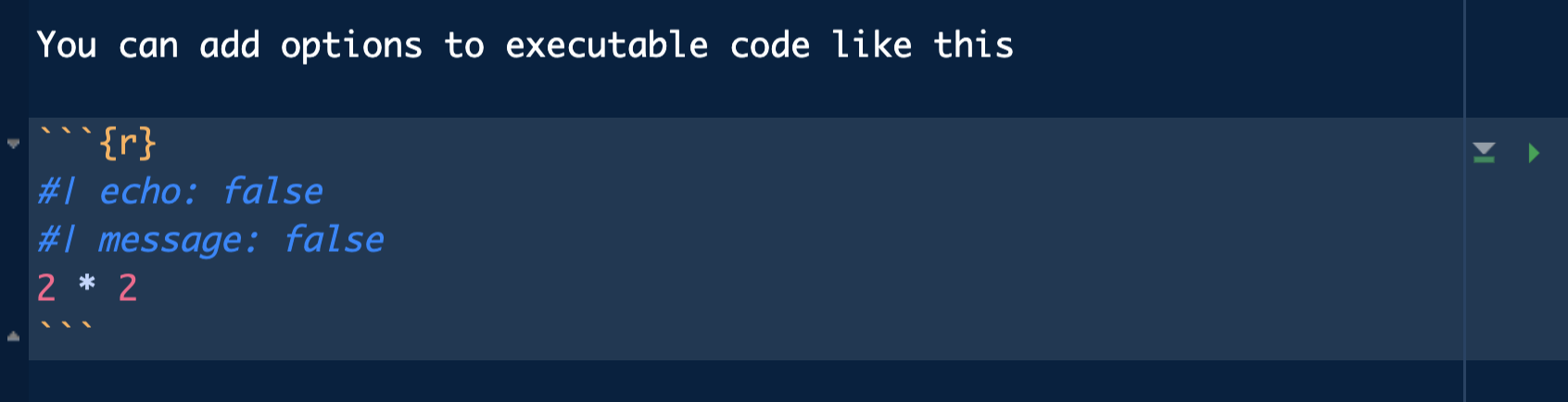
Los chunks podemos personalizarlos con opciones al inicio del chunk precedido de #|:
#| echo: false: ejecuta código y se muestra resultado pero no visualiza código en la salida.
#| include: false: ejecuta código pero no muestra resultado y no visualiza código en la salida.
#| eval: false: no ejecuta código, no muestra resultado pero sí visualiza código en la salida.
#| message: false: ejecuta código pero no muestra mensajes de salida.
#| warning: false: ejecuta código pero no muestra mensajes de warning.
#| error: true: ejecuta código y permite que haya errores mostrando el mensaje de error en la salida.
Estas opciones podemos aplicarlas chunk a chunk o fijar los parámetros de forma global con knitr::opts_chunk$set() al inicio del documento (dentro de un chunk).
Personalizando chunks
Si queremos que aplique la opción a todos los chunks por defecto debemos incluirlo al final de la cabecera, como opciones de ejecución
Además de texto y código podemos introducir lo siguiente:
Ecuaciones: puedes añadir además ecuaciones como \(x^2\) (he escrito $x^2$, la ecuación entre dólares).
Listas: puedes itemizar elementos poniendo *
* Paso 1: ...
* Paso 2: ...
Cross-references: puedes etiquetar partes del documento (la etiqueta se construye con {#nombre-seccion}) y llamarlas luego con [Sección](@nombre-seccion)
Gráficas/imágenes en qmd
Por último, también podemos añadir pies de gráficas o imágenes añadiendo #| fig-cap: "..."
Fíjate que el caption está en el margen (por ejemplo). Puedes cambiarlo introduciendo ajustes en la cabecera (todo lo relativo a figuras empieza por fig-, y puedes ver las opciones tabulando). Tienes más información en https://quarto.org/
El archivo de estilos debe estar en la misma carpeta que el archivo .qmd
Añadir estilos
También puedes hacerlo de manera sencilla añadiendo a los textos un poco de HTML. Por ejemplo, para personalizar el color de un texto va entre corchetes y justo tras el texto, entre llaves, las opciones de estilo
Esta palabra es [roja]{style="color:red;"} ...
... y esta [verde y en negrita]{style="color:green; font-weight: bold;"}
Esta palabra es roja …
… y esta verde y en negrita
Revealjs
Puedes añadir algunas «animaciones» usando lo que se conoce como Revealjs (javascript), especifcándolo en la cabecera y usando bloques de dicho lenguaje delimitados por ::: al inicio y final, y la palabra de la «herramienta» a usar. Por ejemplo {.incremental} hace una transición de los elementos.
format: revealjs
::: {.incremental}- Me- llamo- Javi:::
Me
llamo
Javi
Bloques de llamada
También puedes usar los bloques de llamada que por defecto son note, tip, warning, caution e important (aunque los puedes crear y personalizar). Para ello basta con usar :::{.callout-tipo} y el tipo que quieras
:::{.callout-tip}Note that there are five types of callouts, including: `note`, `tip`, `warning`, `caution`, and `important`.:::
Tip
Recuerda que los 5 tipos son note, tip, warning, caution e important.
Caution
Úsalos con cabeza, a veces mucho recursos estético puede marear.
Múltiples columnas
Con :::: columns podemos definir una disposición de múltiples columnas donde cada una viene definida por ::: {.column width="65%"} cosa :::, indicando al lado del porcentaje cuanto quieres que ocupe cada columna (¡cuidado, no dejar espacios!)
:::: columns::: {.column width="65%"}Así se define un vector:::::: {.column width="35%"}x <- c(1, 2, 3)x:::::::
Así se define un vector
x <-c(1, 2, 3)x
[1] 1 2 3
Pestañas
Con ::: panel-tabset ::: podemos también definir un panel de pestañas
### EjerciciosResuelve los siguientes ejercicios::: panel-tabset#### Ejercicio 1Define un vector x con los primeros 3 números naturales#### Ejercicio 2Haz la suma del vector anterior:::
# install.packages("reticulate")library(reticulate)install_python("3.9.12") # Instalar python en PC sino lo tienes# Instalar paquetes de Pythonreticulate::py_install("numpy")reticulate::py_install("matplotlib")
Vamos a realizar un pequeño simulacro antes de la entrega usando el dataset starwars del paquete {dplyr}
Ejemplo de entrega
library(dplyr)starwars
# A tibble: 87 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Luke Sk… 172 77 blond fair blue 19 male mascu…
2 C-3PO 167 75 <NA> gold yellow 112 none mascu…
3 R2-D2 96 32 <NA> white, bl… red 33 none mascu…
4 Darth V… 202 136 none white yellow 41.9 male mascu…
5 Leia Or… 150 49 brown light brown 19 fema… femin…
6 Owen La… 178 120 brown, gr… light blue 52 male mascu…
7 Beru Wh… 165 75 brown light blue 47 fema… femin…
8 R5-D4 97 32 <NA> white, red red NA none mascu…
9 Biggs D… 183 84 black light brown 24 male mascu…
10 Obi-Wan… 182 77 auburn, w… fair blue-gray 57 male mascu…
# ℹ 77 more rows
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
En él tenemos diferentes variables de los personajes de Star Wars, con características de su pelo, piel, altura, nombre, etc.
Ejemplo de entrega
Crea un documento .qmd con nombre, título, formato e índice. Cada ejercicio posterior será una subsección del documento. Ejecuta los chunks que consideres y comenta las salidas para responder a cada pregunta
Ejercicio 1. ¿Cuántos personajes hay guardados en la base de datos? ¿Cuántas características se han medido de cada uno?
Ejercicio 2. Extrae en dos variables distintas nombres y edades las variables correspondientes de la tabla. ¿De qué tipo es la variable nombre? ¿Y la variable birth_year?
Ejercicio 3. Obtén el vector de nombres de los personajes ordenados de mayores a jóvenes.
Ejemplo de entrega
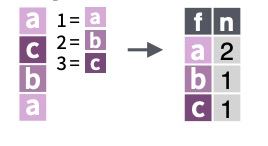
Ejercicio 4. Busca ayuda de la función unique(). Úsala para saber que modalidades tiene la variable cualitativa correspondiente al color de ojos. ¿Cuántos distintos hay?
Ejercicio 5. ¿Existe ALGÚN valor ausente en la variable de color ojos?
Ejercicio 6. Calcula la media y desviación típica de las variables de estatura y peso (cuidado con los ausentes). Define un nuevo tibble con esas dos variables e incorpora una tercera variable que se llame “IMC” que calcule el índice de masa corporal. Incorpora con $ $ la fórmula usada para el IMC.
🐣 Caso práctico: simulacro
Crea un documento .qmd en el que al menos la cabecera contenga
Título, autor y formato (html)
Índice con título y situado a la derecha
Tras ello vuelve a ejercicios del tema 2 y estructura un documento donde cada ejercicio sea una subsección. En cada subsección pon el enunciado.
Debajo de cada enunciado pon el chunk con el código correspondiente, así como comentarios de texto de la salida (con negritas y cursivas)
Añade un último chunk en el que, dado un vector x <- 1:5, calcules su media, e incluye con $ $ la fórmula de la media aritmética e incrusta además una foto de la fórmula que encuentres por google.
Renderiza el documento para obtener el html
Entrega I
El día de la entrega tendrás subido una plantilla de entrega en formato .qmd en el campus.
Descomprime la carpeta (¡importante! si no descomprimes, aunque puedas editar el .qmd, no podrás generar el .html)
Edita la cabecera con tu nombre y DNI
Deberás rellenar cada chunk con el código que consideres (en algunos te he dejado pistas) y cambiar de #| eval: false a #| eval: true (si los quitas directamente, por defecto ya es true)
Deberás de comentar con texto normal lo que consideres para responder a las preguntas.
Será OBLIGATORIO subir el archivo .html generado (solo se corregirá dicho archivo) así que ve renderizando según rellenas el documento, no lo dejes para el final.
Una estructura de control se compone de una serie de comandos orientados a decidir el camino que tu código debe recorrer
Si se cumple la condición A, ¿qué sucede?
¿Y si sucede B?
¿Cómo puedo repetir una misma expresión (dependiendo de una variable)?
Si has programado antes, quizás te sea familiar las conocidas como estructuras condicionales tales como if (blabla) {...} else {...} o buclesfor/while (a evitar siempre que podamos).
Estructura If
Una de las estructuras de control más famosas son las conocidas como estructuras condicionalesif.
SI (IF) un conjunto de condiciones se cumple (TRUE), entonces ejecuta lo que haya dentro de las llaves
Por ejemplo, la estructura if (x == 1) { código A } lo que hará será ejecutar el código A entre llaves pero SOLO SI la condición entre paréntesis es cierta (solo si x es 1). En cualquier otro caso, no hará nada.
Por ejemplo, definamos un vector de edades de 8 personas
edad <-c(14, 17, 24, 56, 31, 20, 87, 73)edad <18
[1] TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
Estructura If
Nuestra estructura condicional hará lo siguiente: si existe algún menor de edad, imprimirá por pantalla un mensaje.
if (any(edad <18)) { print("Existe alguna persona menor de edad")}
[1] "Existe alguna persona menor de edad"
Estructura If
if (any(edad <18)) { print("Existe alguna persona menor de edad")}
En caso de que las condiciones no sean ciertas dentro de if() (FALSE), no sucede nada
if (all(edad >=18)) { print("Todos son mayores de edad")}
No obtenemos ningún mensaje porque la condición all(edad >= 18) no es TRUE, así que no ejecuta nada.
Estructura If-else
La estructura if (condicion) { código A } puede combinarse con un else { código B }: cuando la condición no está verificada, se ejecutará el código alternativo B dentro de else { }, permitiéndonos decidir que sucede cuando se cumple y cuando no.
Por ejemplo, if (x == 1) { código A } else { código B } ejecutará A si x es igual a 1 y B en cualquier otro caso.
if (all(edad >=18)) { print("Todos son mayores de edad")} else {print("Existe alguna persona menor de edad")}
[1] "Existe alguna persona menor de edad"
Estructura If-else
Esta estructura if - else puede ser anidada: imagina que queremos ejecutar un código si todos son menores; si no sucede, pero todos son mayores de 16, hacer otra cosa; en cualquier otra cosa, otra acción.
if (all(edad >=18)) { print("Todos son mayores de edad")} elseif (all(edad >=16)) {print("Hay algún menor de edad pero todos con 16 años o más")} else { print("Hay alguna persona con menos de 16 años") }
[1] "Hay alguna persona con menos de 16 años"
Truco
Puedes colapsar las estructuras haciendo click en la flecha a la izquierda que aparece en tu script.
If-else vectorizado
Esta estructura condicional se puede vectorizar (en una sola línea) con if_else() (del paquete {dplyr}), cuyos argumentos son
la condición a evaluar
lo que sucede cuando se cumple y cuando no
un argumento opcional para cuando la condición a evaluar es NA
Vamos a etiquetar sin son mayores/menores y un “desconocido” cuando no conocemos
La salida es 0 ya que sqrt(9) es igual 3, y dado que no es menor que 2, devuelve el segundo argumento que es 0
📝 ¿Cuál es la salida del siguiente código?
x <-c(1, NA, -1, 9)if_else(sqrt(x) <2, 0, 1)
Code
La salida es el vector c(0, NA, NA, 1) ya que sqrt(1) sí es menor que 2, sqrt(9) no lo es, y tanto en el caso de sqrt(NA) (raíz de ausente) como sqrt(-1) (devuelve NaN, not a number), su raíz cuadrada no puede verificarse si es menor que 2 o no, así que la salida es NA.
📝 Modifica el código inferior para que, cuando no se pueda verificar si la raíz cuadrada de un número es menor que 2, devuelva -1
x <-c(1, NA, -1, 9)if_else(sqrt(x) <2, 0, 1)
Code
x <-c(1, NA, -1, 9)if_else(sqrt(x) <2, 0, 1, missing =-1)
📝 ¿Cuál es son los valores de x e y del código inferior para z <- 1, z <- -1 y z <- -5?
z <--1if (z >0) { x <- z^3 y <--sqrt(z)} elseif (abs(z) <2) { x <- z^4 y <-sqrt(-z)} else { x <- z/2 y <-abs(z)}
Code
En primero caso x =1 e y =-1. En el segundo caso x =1 e y =1. En el tercer caso -2.5 y 5
📝 ¿Qué pasaría si ejecutamos el siguiente código? Spoiler: da error. ¿Por qué? ¿Cómo solucionarlo?
z <-c(-1, 1, 5)if (z >0) { x <- z^3 y <--sqrt(z)} elseif (abs(z) <2) { x <- z^4 y <-sqrt(-z)} else { x <- z/2 y <-abs(z)}
Code
Da error ya que en los `if (condición) { } else { }`"clásicos" necesitamos quela condición tenga longitud uno (un solo valor TRU/FALSE)
Code
# para arreglarlo podemos hacer un if_else vectorialz <-c(-1, 1, -5)library(dplyr)x <-if_else(z >0, z^3, if_else(abs(z) <2, z^4, z/2))y <-if_else(z >0, -sqrt(z), if_else(abs(z) <2, sqrt(-z), abs(z)))
📝 ¿Qué sucederá si ejecutamos el código inferior?
z <-"a"if (z >0) { x <- z^3 y <--sqrt(z)} elseif (abs(z) <2) { x <- z^4 y <-sqrt(-z)} else { x <- z/2 y <-abs(z)}
Code
# dará error ya que no es un argumento numéricoError in z^3: non-numeric argument to binary operator
📝 Del paquete {lubridate}, la función hour() nos devuelve la hora de una fecha dada, y la función now() nos devuelve fecha y hora del momento actual. Con ambas funciones haz que se imprima por pantalla (cat()) “buenas noches” solo a partir de las 21 horas.
Code
# Cargamos libreríalibrary(lubridate)# Fecha-hora actualfecha_actual <-now()# Estructura ifif (hour(fecha_actual) >21) {cat("Buenas noches") # print/cat dos formas de imprimir por pantalla}
Bucles
Aunque en la mayoría de ocasiones se pueden reemplazar por otras estructuras más eficientes y legibles, es importante conocer una de las expresiones de control más famosas: los bucles.
for { }: permite repetir el mismo código en un número prefijado y conocido de veces.
while { }: permite repetir el mismo código pero en un número indeterminado de veces (hasta que una condición deje de cumplirse).
Bucles for
Un bucle for es una estructura que permite repetir un conjunto de órdenes un número finito, prefijado y conocido de veces dado un conjunto de índices.
Vamos a definir un vector x <- c(0, -7, 1, 4) y otra variable vacía y. Tras ello definiremos un bucle for con for () { }: dentro de los paréntesis indicaremos un índice y unos valores a recorrer, dentro de las llaves el código a ejecutar en cada iteración (en este caso, rellenar y como x + 1)
x <-c(0, -7, 1, 4)y <-c()
Bucles for
Un bucle for es una estructura que permite repetir un conjunto de órdenes un número finito, prefijado y conocido de veces dado un conjunto de índices.
Vamos a definir un vector x <- c(0, -7, 1, 4) y otra variable vacía y. Tras ello definiremos un bucle for con for () { }: dentro de los paréntesis indicaremos un índice y unos valores a recorrer, dentro de las llaves el código a ejecutar en cada iteración (en este caso, rellenar y como x + 1)
x <-c(0, -7, 1, 4)y <-c()for (i in1:4) {}
Bucles for
Un bucle for es una estructura que permite repetir un conjunto de órdenes un número finito, prefijado y conocido de veces dado un conjunto de índices.
Vamos a definir un vector x <- c(0, -7, 1, 4) y otra variable vacía y. Tras ello definiremos un bucle for con for () { }: dentro de los paréntesis indicaremos un índice y unos valores a recorrer, dentro de las llaves el código a ejecutar en cada iteración (en este caso, rellenar y como x + 1)
x <-c(0, -7, 1, 4)y <-c()for (i in1:4) { y[i] <- x[i] +1}
Bucles for
Fíjate que debido a que R funciona de manera vectorial por defecto, el bucle es lo mismo que hacer x + 1 directamente.
x <-c(0, -7, 1, 4)y <-c()for (i in1:4) { y[i] <- x[i] +1}y
[1] 1 -6 2 5
y2 <- x +1y2
[1] 1 -6 2 5
Bucles for
Otra opción habitual es indicar los índices de manera «automática»: desde el primero 1 hasta el último (que corresponde con la longitud de x length(x))
x <-c(0, -7, 1, 4)y <-c()for (i in1:length(x)) { y[i] <- x[i] +1}y
[1] 1 -6 2 5
Bucles for
Así la estructura general de un bucle for será siempre la siguiente
for (índice in conjunto) { código (dependiente de i)}
SIEMPRE sabemos cuántas iteraciones tenemos (tantas como elementos haya en el conjunto a indexar)
Evitando bucles
Como ya hemos aprendido con el paquete{microbenchmark} podemos chequear como los bucles suelen ser muy ineficientes (de ahí que debamos evitarlos en la mayoría de ocasiones
library(microbenchmark)x <-1:1000microbenchmark(y <- x^2, for (i in1:100) { y[i] <- x[i]^2 },times =500)
Unit: microseconds
expr min lq mean median
y <- x^2 1.722 1.968 2.699194 2.132
for (i in 1:100) { y[i] <- x[i]^2 } 1263.251 1287.092 1374.566164 1301.688
uq max neval
3.116 59.327 500
1370.938 4121.894 500
Bucles for
Podemos ver otro ejemplo de bucle combinando números y textos: definimos un vector de edades y de nombres, e imprimimos el nombre y edad i-ésima.
nombres <-c("Javi", "Sandra", "Carlos", "Marcos", "Marta")edades <-c(33, 27, 18, 43, 29)for (i in1:5) { print(glue("{nombres[i]} tiene {edades[i]} años")) }
Javi tiene 33 años
Sandra tiene 27 años
Carlos tiene 18 años
Marcos tiene 43 años
Marta tiene 29 años
Bucles for
Aunque normalmente se suelen indexar con vectors numéricos, los bucles pueden ser indexados sobre cualquier estructura vectorial, da igual de que tipo sea el conjunto
Vamos a combinar las estructuras condicionales y los bucles: usando el conjunto swiss del paquete {datasets}, vamos a asignar NA si los valores de fertilidad son mayores de 80.
for (i in1:nrow(swiss)) {if (swiss$Fertility[i] >80) { swiss$Fertility[i] <-NA }}
Esto es exactamente igual a un if_else() vectorizado
Otra forma de crear un bucle es con la estructura while { }, que nos ejecutará un bucle un número desconocido de veces, hasta que una condición deje de cumplirse (de hecho puede que nunca termine). Por ejemplo, vamos a inializar una variable ciclos <- 1, que incrementaremos en cada paso, y no saldremos del bucle hasta que ciclos > 4.
ciclos <-1while(ciclos <=4) {print(glue("No todavía, vamos por el ciclo {ciclos}")) ciclos <- ciclos +1}
No todavía, vamos por el ciclo 1
No todavía, vamos por el ciclo 2
No todavía, vamos por el ciclo 3
No todavía, vamos por el ciclo 4
Bucles while
Un bucle while será siempre como sigue
while(condición) { código a hacer mientras la condición sea TRUE# normalmente aquí se actualiza alguna variable}
Bucles while
¿Qué sucede cuando la condición nunca es FALSE? Pruébalo tu mismo
while (1>0) {print("Presiona ESC para salir del bucle")}
Cuidado
Un bucle while { } puede ser bastante «peligroso» sino controlamos bien cómo pararlo.
Bucles while
Contamos con dos palabras reservadas para abortar un bucle o forzar su avance:
break: permite abortar un bucle incluso si no se ha llegado a su final
for(i in1:10) {if (i ==3) {break# si i = 3, abortamos bucle }print(i)}
[1] 1
[1] 2
Bucles while
Contamos con dos palabras reservadas para abortar un bucle o forzar su avance:
next: fuerza un bucle a avanzar a la siguiente iteración
for(i in1:5) {if (i ==3) {next# si i = 3, la obvia y continua al siguiente }print(i)}
[1] 1
[1] 2
[1] 4
[1] 5
Bucles repeat
Aunque no es tan usado como las opciones anteriores, también contamos con repeat { } que ejecuta un bucle de manera infinita hasta que se indique abortar con un break
Aunque no es formalmente un bucle, otra forma de repetir código un número de veces es hacer uso de replicate(): simplemente permite repetir lo mismo n veces
x <-1:3replicate(n =3, x^2)
[,1] [,2] [,3]
[1,] 1 1 1
[2,] 4 4 4
[3,] 9 9 9
Replicate
La función replicate() se suele usar para generar distintas repeticiones de elementos aleatorios. Por ejemplo, imaginemos que queremos generar 3 muestras de distribuciones normales, en la que cada muestra tendrá 7 elementos. Para generar una se usa rnorm(n = 7) (r de resample, norm de normal, y si no se dice nada es media 0 y desv 1).
📝 Modifica el código inferior para que se imprima un mensaje por pantalla si y solo si todos los datos de airquality son con mes distinto a enero
library(datasets)months <- airquality$Monthif (months ==2) {print("No hay datos de enero")}
Code
library(datasets)months <- airquality$Monthif (all(months !=1)) {print("No hay datos de enero")}
📝 Modifica el código inferior para guardar en una variable llamada temp_alta un TRUE si alguno de los registros tiene una temperatura superior a 90 grados Farenheit y FALSE en cualquier otro caso
temp <- airquality$Tempif (temp ==100) {print("Algunos de los registros tienen temperaturas superiores a 90 grados Farenheit")}
📝 Modifica el código inferior para diseñar un bucle for de 5 iteraciones que solo recorra los primeros 5 impares (y en cada paso del bucle los imprima)
for (i in1:5) {print(i)}
Code
for (i inc(1, 3, 5, 7, 9)) {print(i)}
📝 Modifica el código inferior para diseñar un bucle while que empiece con un contador count <- 1 y pare cuando llegue a 6
Intenta responder a las preguntas planteadas en el workbook donde tendrás que diseñar algunos estudios de simulación haciendo uso de bucles y estructuras condicionales
Clase 6: funciones
¿Qué es una función? ¿Cómo se definen? Variables locales vs globales
No solo podemos usar funciones predeterminadas que vienen ya cargadas en paquetes, además podemos crear nuestras propias funciones para automatizar tareas. ¿Cómo crear nuestra propia función? Veamos su esquema básico:
Nombre: por ejemplo name_fun (sin espacios ni caracteres extraños). Al nombre le asignamos la palabra reservadafunction().
Definir argumentos de entrada (dentro de function()).
Cuerpo de la función dentro de { }.
Finalizamos la función con los argumentos de salida con return().
name_fun <-function() {}
Creando funciones
No solo podemos usar funciones predeterminadas que vienen ya cargadas en paquetes, además podemos crear nuestras propias funciones para automatizar tareas. ¿Cómo crear nuestra propia función? Veamos su esquema básico:
Nombre: por ejemplo name_fun (sin espacios ni caracteres extraños). Al nombre le asignamos la palabra reservadafunction().
Definir argumentos de entrada (dentro de function()).
Cuerpo de la función dentro de { }.
Finalizamos la función con los argumentos de salida con return().
name_fun <-function(arg1, arg2, ...) {}
Creando funciones
No solo podemos usar funciones predeterminadas que vienen ya cargadas en paquetes, además podemos crear nuestras propias funciones para automatizar tareas. ¿Cómo crear nuestra propia función? Veamos su esquema básico:
Nombre: por ejemplo name_fun (sin espacios ni caracteres extraños). Al nombre le asignamos la palabra reservadafunction().
Definir argumentos de entrada (dentro de function()).
Cuerpo de la función dentro de { }.
Finalizamos la función con los argumentos de salida con return().
name_fun <-function(arg1, arg2, ...) { código a ejecutar}
Creando funciones
No solo podemos usar funciones predeterminadas que vienen ya cargadas en paquetes, además podemos crear nuestras propias funciones para automatizar tareas. ¿Cómo crear nuestra propia función? Veamos su esquema básico:
Nombre: por ejemplo name_fun (sin espacios ni caracteres extraños). Al nombre le asignamos la palabra reservadafunction().
Definir argumentos de entrada (dentro de function()).
Cuerpo de la función dentro de { }.
Finalizamos la función con los argumentos de salida con return().
name_fun <-function(arg1, arg2, ...) { código a ejecutarreturn(var_salida)}
Creando funciones
arg1, arg2, ...: serán los argumentos de entrada, los argumentos que toma la función para ejecutar el código que tiene dentro
código: líneas de código que queramos que ejecute la función.
return(var_salida): se introducirán los argumentos de salida.
Todas las variables que definamos dentro de la función son variables LOCALES: solo existirán dentro de la función salvo que especifiquemos lo contrario.
Creando funciones
Veamos un ejemplo muy simple de función para calcular el área de un rectángulo.
Dado que el área de un rectángulo se calcula como el producto de sus lados, necesitaremos precisamente eso, sus lados: esos serán los argumentos de entrada y el valor a devolver será justo su área (\(lado_1 * lado_2\)).
# Definición del nombre de función y argumentos de entradacalcular_area <-function(lado_1, lado_2) {}
Creando funciones
Veamos un ejemplo muy simple de función para calcular el área de un rectángulo.
Dado que el área de un rectángulo se calcula como el producto de sus lados, necesitaremos precisamente eso, sus lados: esos serán los argumentos de entrada y el valor a devolver será justo su área (\(lado_1 * lado_2\)).
# Definición del nombre de función y argumentos de entradacalcular_area <-function(lado_1, lado_2) { area <- lado_1 * lado_2}
Creando funciones
Veamos un ejemplo muy simple de función para calcular el área de un rectángulo.
Dado que el área de un rectángulo se calcula como el producto de sus lados, necesitaremos precisamente eso, sus lados: esos serán los argumentos de entrada y el valor a devolver será justo su área (\(lado_1 * lado_2\)).
# Definición del nombre de función y argumentos de entradacalcular_area <-function(lado_1, lado_2) { area <- lado_1 * lado_2return(area)}
Uso de funciones
También podemos hacer una definición directa de las variables sin almacenar por el camino.
# Definición del nombre de función y argumentos de entradacalcular_area <-function(lado_1, lado_2) {return(lado_1 * lado_2)}
¿Cómo aplicar la función?
calcular_area(5, 3) # área de un rectángulo 5 x 3
[1] 15
calcular_area(1, 5) # área de un rectángulo 1 x 5
[1] 5
Uso de funciones
Tip
Aunque no sea necesario, es recomendable hacer explícita la llamada de los argumentos, especificando en el código qué valor es para cada argumento para que no dependa de su orden, haciendo el código más legible
calcular_area(lado_1 =5, lado_2 =3) # área de un rectángulo 5 x 3
[1] 15
calcular_area(lado_2 =3, lado_1 =5) # área de un rectángulo 5 x 3
[1] 15
Argumentos por defecto
Imagina ahora que nos damos cuenta que el 90% de las veces usamos dicha función para calcular por defecto el área de un cuadrado (es decir, solo necesitamos un lado). Para ello, podemos definir argumentos por defecto en la función: tomarán dicho valor salvo que le asignemos otro.
¿Por qué no asignar lado_2 = lado_1por defecto, para ahorrar líneas de código y tiempo?
calcular_area <-function(lado_1, lado_2 = lado_1) {# Cuerpo de la función area <- lado_1 * lado_2# Resultado que devolvemosreturn(area)}
Argumentos por defecto
calcular_area <-function(lado_1, lado_2 = lado_1) {# Cuerpo de la función area <- lado_1 * lado_2# Resultado que devolvemosreturn(area)}
Ahora por defecto el segundo lado será igual al primero (si se lo añadimos usará ambos).
calcular_area(lado_1 =5) # cuadrado
[1] 25
calcular_area(lado_1 =5, lado_2 =7) # rectángulo
[1] 35
Salida múltiple
Compliquemos un poco la función y añadamos en la salida los valores de cada lado, etiquetados como lado_1 y lado_2, empaquetando la salida en una vector.
# Definición del nombre de función y argumentos de entradacalcular_area <-function(lado_1, lado_2 = lado_1) {# Cuerpo de la función area <- lado_1 * lado_2# Resultadoreturn(c("area"= area, "lado_1"= lado_1, "lado_2"= lado_2))}
Salida múltiple
Podemos complicar un poco más la salida añadiendo una cuarta variable que nos diga, en función de los argumentos, si rectángulo o cuadrado, teniendo que añadir en la salida una variable que de tipo caracter (o lógica).
# Definición del nombre de función y argumentos de entradacalcular_area <-function(lado_1, lado_2 = lado_1) {# Cuerpo de la función area <- lado_1 * lado_2# Resultadoreturn(c("area"= area, "lado_1"= lado_1, "lado_2"= lado_2,"tipo"=if_else(lado_1 == lado_2, "cuadrado", "rectángulo")))}calcular_area(5, 3)
area lado_1 lado_2 tipo
"15" "5" "3" "rectángulo"
Problema: al intentar juntar números y texto, lo convierte todo a números. Podríamos guardarlo todo en un tibble() como hemos aprendido o en un objeto conocido en R como listas
Introducción a listas
Veamos un pequeño resumen de los datos que ya conocemos:
vectores: colección de elementos de igual tipo. Pueden ser números, caracteres o valores lógicos, entre otros.
matrices: colección BIDIMENSIONAL de elementos de igual tipo e igual longitud.
data.frame / tibble: colección BIDIMENSIONAL de elementos de igual longitud pero de cualquier tipo.
Las listas serán colecciones de variables de diferente tipo y diferente longitud, con estructuras totalmente heterógeneas (incluso una lista puede tener dentro a su vez otra lista).
Introducción a listas
Vamos a crear nuestra primera lista con list() con tres elementos: el nombre de nuestros padres/madres, nuestro lugar de nacimiento y edades de nuestros hermanos.
Si observas el objeto que hemos definido como lista, su longitud del es de 3 ya que tenemos guardados tres elementos: un vector de caracteres (de longitud 2), un caracter (vector de longitud 1), y un vector de números (de longitud 3)
Tenemos guardados elementos de distinto tipo (algo que ya podíamos hacer) pero, además, de longitudes dispares.
dim(lista) # devolverá NULL al no tener dos dimensiones
NULL
class(lista) # de tipo lista
[1] "list"
Introducción a listas
Si los juntásemos con un tibble(), al tener distinta longitud, obtendríamos un error.
# Definición del nombre de función y argumentos de entradacalcular_area <-function(lado_1, lado_2 = lado_1) {# Cuerpo de la función area <- lado_1 * lado_2# Resultadoreturn(list("area"= area, "lado_1"= lado_1, "lado_2"= lado_2,"tipo"=if_else(lado_1 == lado_2, "cuadrado", "rectángulo")))}calcular_area(5, 3)
Antes nos daba igual el orden de los argumentos pero ahora el orden de los argumentos de entrada importa, ya que en la salida incluimos lado_1 y lado_2.
Recomendación
Como se comentaba, altamente recomendable hacer la llamada a la función indicando explícitamente los argumentos para mejorar legibilidad e interpretabilidad.
# Equivalente a calcular_area(5, 3)calcular_area(lado_1 =5, lado_2 =3)
Parece una tontería lo que hemos hecho pero hemos cruzado una frontera importante: hemos pasado de consumir conocimiento (código de otros paquetes, elaborado por otros/as), a generar conocimiento, creando nuestras propias funciones.
Las funciones van a ser claves en tu día a día ya que te permitirá automatizar código que vas a repetir una y otra vez: empaquetando ese código bajo un alias (nombre de la función) vas a poder usarlo una y otra vez sin necesidad de programarlo (por lo que hacer el doble de trabajo no implicará trabajar el doble)
Variables locales vs globales
Un aspecto importante sobre el que reflexionar con las funciones: ¿qué sucede si nombramos a una variable dentro de una función a la que se nos ha olvidado asignar un valor dentro de la misma?
Debemos ser cautos al usar funciones en R, ya que debido a la «regla lexicográfica», si una variable no se define dentro de la función, Rbuscará dicha variable en el entorno de variables.
x <-1funcion_ejemplo <-function() {print(x) # No devuelve nada, solo realiza la acción }funcion_ejemplo()
[1] 1
Variables locales vs globales
Si una variable ya está definida fuera de la función (entorno global), y además es usada dentro de cambiando su valor, el valor solo cambia dentro pero no en el entorno global.
x <-1funcion_ejemplo <-function() { x <-2print(x) # lo que vale dentro}
# lo que vale dentrofuncion_ejemplo() #<<
[1] 2
# lo que vale fueraprint(x) #<<
[1] 1
Variables locales vs globales
Si queremos que además de cambiar localmente lo haga globalmente deberemos usar la doble asignación (<<-).
x <-1y <-2funcion_ejemplo <-function() {# no cambia globalmente, solo localmente x <-3# cambia globalmente y <<-0#<<print(x)print(y)}funcion_ejemplo() # lo que vale dentro
[1] 3
[1] 0
x # lo que vale fuera
[1] 1
y # lo que vale fuera
[1] 0
💻 Tu turno
Intenta realizar los siguientes ejercicios sin mirar las soluciones
📝 Modifica el código inferior para definir una función llamada funcion_suma, de forma que dados dos elementos, devuelve su suma.
nombre <-function(x, y) { suma <-# código a ejecutarreturn()}# Aplicamos la funciónsuma(3, 7)
Code
funcion_suma <-function(x, y) { suma <- x + yreturn(suma)}funcion_suma(3, 7)
📝 Modifica el código inferior para definir una función llamada funcion_producto, de forma que dados dos elementos, devuelve su producto, pero que por defecto calcule el cuadrado
nombre <-function(x, y) { producto <-# código de la multiplicaciónreturn()}producto(3)producto(3, -7)
Code
funcion_producto <-function(x, y = x) { producto <- x * yreturn(producto)}funcion_producto(3)funcion_producto(3, -7)
📝 Define una función llamada igualdad_nombres que, dados dos nombres, nos diga si son iguales o no. Hazlo considerando importantes las mayúsculas, y sin que importen las mayúsculas. Usa el paquete {stringr}.
📝 Crea una función llamada calculo_IMC que, dados dos argumentos (peso y estatura en metros) y un nombre, devuelva una lista con el IMC (\(peso/(estatura_m^2)\)) y el nombre.
📝 Repite el ejercicio anterior pero con otro argumento opcional que se llame unidades (por defecto, unidades = "metros"). Desarrolla la función de forma que haga lo correcto si unidades = "metros" y si unidades = "centímetros".
📝 Crea un tibble ficticio de 7 personas, con tres variables (inventa nombre, y simula peso, estatura en centímetros), y adapta la función calculo_IMC() de forma que obtengamos una cuarta columna con su IMC.
Code
datos <-tibble("nombres"=c("javi", "sandra", "eva", "ana", "carlos", "leo", NA),"peso"=rnorm(n =7, mean =70, sd =1),"estatura"=rnorm(n =7, mean =168, sd =5))# IMPORTANTE. if_else trabaja de manera vectorial, elemento a elemento: la longitud de la# condición (unidades == "metros" es un vector lógico de longitud uno) debe ser igual que# lo que le decimos que haga cuando es TRUE y FALSE (en este caso, condicion tiene longitud 1# pero al aplicarla lo que devuelve es vector de tamaño 7, por eso hay que usar ifelse (sin _))calculo_IMC <-function(nombre, peso, estatura, unidades ="metros") {return(list("nombre"= nombre,"IMC"= peso/(ifelse(unidades =="metros", estatura, estatura/100)^2)))}datos |>mutate(IMC =calculo_IMC(nombres, peso, estatura, unidades ="centímetros")$IMC)
📝 Crea una función llamada atajo que tenga dos argumentos numéricos x e y. Si ambos son iguales, debes devolver "iguales" y hacer que la función acaba automáticamente (piensa cuándo una función sale). OJO: x e y podrían ser vectores. Si son distintos (de igual de longitud) calcula la proporción de elementos diferentes. Si son distintos (por ser distinta longitud), devuelve los elementos que no sean comunes.
Para practicar con funciones vamos a crear un completo conversor de temperaturas que, dada una temperatura en Fahrenheit, Celsius o Kelvin, la convierta a cualquiera de las otras
Intenta responder a las preguntas planteadas en el workbook hasta construirlo.
Clase 7: tidydata
Nuestra base de datos: tibble. Tidydata: un multiverso de datos limpios
Hasta ahora todo lo que hemos hecho en R lo hemos realizado en el paradigma de programación conocido como R base. Y es que cuando R nació como lenguaje, muchos de los que programaban en él imitaron formas y metodologías heredadas de otros lenguajes, basado en el uso de
Bucles for
Bucles while
Estructuras if-else
Y aunque conocer dichas estructuras puede sernos en algunos casos interesantes, en la mayoría de ocasiones han quedado caducas y vamos a poder evitarlas (en especial los bucles) ya que R está especialmente diseñado para trabajar de manera funcional (en lugar de elemento a elemento).
¿Qué es tidyverse?
En ese contexto de programación funcional, hace una década nacía {tidyverse}, un «universo» de paquetes para garantizar un flujo de trabajo eficiente, coherente y lexicográficamente sencillo de entender, basado en la idea de que nuestros datos están limpios y ordenados (tidy)
¿Qué es tidyverse?
{lubridate} manejo de fechas
{rvest}: web scraping
{tidymodels}: modelización/predicción
{tibble}: optimizando data.frame
{tidyr}: limpieza de datos
{readr}: carga datos rectangulares (.csv), {readxl} para importar archivos .xls y .xlsx
{dplyr}: gramática para depurar
{stringr}: manejo de textos
{purrr}: manejo de listas
{forcats}: manejo de cualitativas
{ggplot2}: visualización de datos
¿Qué es tidyverse?
{lubridate} manejo de fechas
{rvest}: web scraping
{tidymodels}: modelización/predicción
{tibble}: optimizando data.frame
{tidyr}: limpieza de datos
{readr}: carga datos rectangulares (.csv), {readxl} para importar archivos .xls y .xlsx
{dplyr}: gramática para depurar
{stringr}: manejo de textos
{purrr}: manejo de listas
{forcats}: manejo de cualitativas
{ggplot2}: visualización de datos
Filosofía base: tidy data
Tidy datasets are all alike, but every messy dataset is messy in its own way (Hadley Wickham, Chief Scientist en RStudio)
TIDYVERSE
El universo de paquetes {tidyverse} se basa en la idea introducida por Hadley Wickham (el Dios al que rezamos) de estandarizar el formato de los datos para
sistematizar la depuración
hacer más sencillo su manipulación.
código legible
Reglas del tidy data
Lo primero por tanto será entender qué son los conjuntos tidydata ya que todo {tidyverse} se basa en que los datos están estandarizados.
Cada variable en una única columna
Cada individuo en una fila diferente
Cada celda con un único valor
Cada dataset en un tibble
Si queremos cruzar múltiples tablas debemos tener una columna común
Tubería (pipe)
En {tidyverse} será clave el operador pipe (tubería) definido como |> (ctrl+shift+M): será una tubería que recorre los datos y los transforma.
En R base, si queremos aplicar tres funciones first(), second() y third() en orden, sería
third(second(first(datos)))
En {tidyverse} podremos leer de izquierda a derecha y separar los datos de las acciones
datos |>first() |>second() |>third()
Apunte importante
Desde la versión 4.1.0 de R disponemos de |>, un pipe nativo disponible fuera de tidyverse, sustituyendo al antiguo pipe%>% que dependía del paquete {magrittr} (bastante problemático).
Tubería (pipe)
La principal ventaja es que el código sea muy legible (casi literal) pudiendo hacer grandes operaciones con los datos con apenas código.
¿Pero qué aspecto tienen los datos no tidy? Vamos a cargar la tabla table4a del paquete {tidyr} (ya lo tenemos cargado del entorno tidyverse).
library(tidyr)table4a
# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 213766
¿Qué puede estar fallando?
Pivotar: pivot_longer()
table4a
# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 213766
❎ Cada fila representa dos observaciones (1999 y 2000) → las columnas 1999 y 2000 en realidad deberían ser en sí valores de una variable y no nombres de columnas.
Incluiremos una nueva columna que nos guarde el año y otra que guarde el valor de la variable de interés en cada uno de esos años. Y lo haremos con la función pivot_longer(): pivotaremos la tabla a formato long:
# A tibble: 6 × 3
country year cases
<chr> <chr> <dbl>
1 Afghanistan 1999 745
2 Afghanistan 2000 2666
3 Brazil 1999 37737
4 Brazil 2000 80488
5 China 1999 212258
6 China 2000 213766
cols: nombre de las variables a pivotar
names_to: nombre de la nueva variable a la quemandamos la cabecera de la tabla (los nombres).
values_to: nombre de la nueva variable a la que vamos a mandar los datos.
Datos SUCIOS: messy data
Veamos otro ejemplo con la tabla table2
table2
# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583
¿Qué puede estar fallando?
Pivotar: pivot_wider()
# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583
❎ Cada observación está dividido en dos filas → los registros con el mismo año deberían ser el mismo
Lo que haremos será lo opuesto: con pivot_wider()ensancharemos la tabla
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583
Datos SUCIOS: messy data
Veamos otro ejemplo con la tabla table3
table3
# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583
¿Qué puede estar fallando?
Separar: separate()
table3
# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583
❎ Cada celda contiene varios valores
Lo que haremos será hacer uso de la función separate() para mandar separar cada valor a una columna diferente.
table3 |>separate(rate, into =c("cases", "pop"))
# A tibble: 6 × 4
country year cases pop
<chr> <dbl> <chr> <chr>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583
Separar: separate()
table3 |>separate(rate, into =c("cases", "pop"))
# A tibble: 6 × 4
country year cases pop
<chr> <dbl> <chr> <chr>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583
Fíjate que los datos, aunque los ha separado, los ha mantenido como texto cuando en realidad deberían ser variables numéricas. Para ello podemos añadir el argumento opcional convert = TRUE
table3 |>separate(rate, into =c("cases", "pop"), convert =TRUE)
# A tibble: 6 × 4
country year cases pop
<chr> <dbl> <int> <int>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583
Datos SUCIOS: messy data
Veamos el último ejemplo con la tabla table5
table5
# A tibble: 6 × 4
country century year rate
<chr> <chr> <chr> <chr>
1 Afghanistan 19 99 745/19987071
2 Afghanistan 20 00 2666/20595360
3 Brazil 19 99 37737/172006362
4 Brazil 20 00 80488/174504898
5 China 19 99 212258/1272915272
6 China 20 00 213766/1280428583
¿Qué puede estar fallando?
Unir unite()
table5
# A tibble: 6 × 4
country century year rate
<chr> <chr> <chr> <chr>
1 Afghanistan 19 99 745/19987071
2 Afghanistan 20 00 2666/20595360
3 Brazil 19 99 37737/172006362
4 Brazil 20 00 80488/174504898
5 China 19 99 212258/1272915272
6 China 20 00 213766/1280428583
❎ Tenemos mismos valores divididos en dos columnas
Usaremos unite() para unir los valores de siglo y año en una misma columna
table5 |>unite(col = year_completo, century, year, sep ="")
# A tibble: 6 × 3
country year_completo rate
<chr> <chr> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583
Ejemplo: relig_income
Vamos a realizar un ejemplo juntos con la tabla relig_income del paquete {tidyr}. Como se indica en la ayuda ? relig_income, la tabla representa la cantidad de personas que hay en cada tramo de ingresos anuales (20k = 20 000$) y en cada religión.
No lo es ya que en realidad solo deberíamos tener una variable de ingresos y la tenemos dividida en 11: todas ellas es la misma variable solo que adopta un valor diferente. ¿Cómo convertirla a tidy data?
Ejemplo: relig_income
La idea es pivotar todas las columnas de ingresos para que acaben en una sola columna llamada income, y los valores (el número de personas) en otra llamada people (por ejemplo). La tabla la haremos más larga y menos ancha así que…
Vamos a hilar más fino: ahora mismo en la variable income en realidad tenemos dos valores, el límite inferior y el superior de la renta. Vamos a separar dicha variable e ingresos en dos, llamadas income_inf y income_sup
Vamos a hilar más fino: ahora mismo en la variable income en realidad tenemos dos valores, el límite inferior y el superior de la renta. Vamos a separar dicha variable e ingresos en dos, llamadas income_inf y income_sup
relig_tidy |># Separamos por -separate(income, into =c("income_inf", "income_sup"), sep ="-")
Piensa ahora como podemos convertir los límites de ingresos a numéricas (eliminando símbolos, letras, etc)
Ejemplo: relig_income
Para ello usaremos el paquete {stringr} que hemos visto antes, en concreto la función str_remove_all() a la que le podemos pasar los caracteres que queremos eliminar (fíjate que $ al ser un caracter reservado en R hay que indicárselo con \\$)
Fíjate que tenemos "Don't now/refused". ¿Qué deberíamos tener?
Debería ser un dato ausente así que usaremos if_else(): si contiene dicha frase, NA, en caso contrario su valor (consejo: str_detect() para detectar patrones en textos, y evitar tener que escribir toda la palabra sin errores)
¿Se te ocurre alguna forma de «cuantificar numéricamente» los valores ausentes que tenemos en este caso?
Si te fijas en realidad cuando hay ausente en el límite inferior en realidad podríamos poner un 0 (nadie puede ganar menos de eso) y cuando lo tenemos en el límite superior sería Inf
¿Por qué era importante tenerlo en tidydata? Lo veremos más adelante al visualizar los datos pero esto ya nos permite realizar filtros muy rápidos con muy poco código.
Por ejemplo: ¿cuántas personas agnósticas con ingresos superiores (o iguales) a 30 tenemos?
# una línea de códigosum(relig_tidy$people[relig_tidy$religion =="Agnostic"& relig_tidy$income_inf >=30])
[1] 609
💻 Tu turno
Intenta realizar los siguientes ejercicios sin mirar las soluciones
📝 Usa el dataset original relig_income y trata de responder a la última pregunta: ¿cuántas personas agnósticas con ingresos superiores (o iguales) a 30 tenemos? Compara el código a realizar cuando tenemos tidydata a cuando no. ¿Cuál es más legible si no supieses R? ¿Cuál tiene mayor probabilidad de error?
📝 Usando relig_tidy determina quién tiene más ingresos medios, ¿católicos (Catholic) o agnósticos (Agnostic)? Crea antes una variable avg_income (ingresos medios por intervalo): si hay 5 personas entre 20 y 30, y 3 personas entre 30 y 50, la media sería \((25*5 + 40*3)/8\) (si es Inf por arriba, NA)
📝 Echa un vistazo a la tabla table4b del paquete {tidyr}. ¿Es tidydata? En caso negativo, ¿qué falla? ¿Cómo convertirla a tidy data en caso de que no lo sea ya?
📝 Echa un vistazo a la tabla billboard del paquete {tidyr}. ¿Es tidydata? En caso negativo, ¿qué falla? ¿Cómo convertirla a tidy data en caso de que no lo sea ya?
Code
billboard |>pivot_longer(cols ="wk1":"wk76",names_to ="week",names_prefix ="wk",values_to ="position",values_drop_na =TRUE)
🐣 Caso práctico
En el paquete {tidyr} contamos con el dataset who2 (dataset de la Organización Mundial de la Salud). Intenta responder a las preguntas planteadas en el workbook.
who2
# A tibble: 7,240 × 58
country year sp_m_014 sp_m_1524 sp_m_2534 sp_m_3544 sp_m_4554 sp_m_5564
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 1980 NA NA NA NA NA NA
2 Afghanistan 1981 NA NA NA NA NA NA
3 Afghanistan 1982 NA NA NA NA NA NA
4 Afghanistan 1983 NA NA NA NA NA NA
5 Afghanistan 1984 NA NA NA NA NA NA
6 Afghanistan 1985 NA NA NA NA NA NA
7 Afghanistan 1986 NA NA NA NA NA NA
8 Afghanistan 1987 NA NA NA NA NA NA
9 Afghanistan 1988 NA NA NA NA NA NA
10 Afghanistan 1989 NA NA NA NA NA NA
# ℹ 7,230 more rows
# ℹ 50 more variables: sp_m_65 <dbl>, sp_f_014 <dbl>, sp_f_1524 <dbl>,
# sp_f_2534 <dbl>, sp_f_3544 <dbl>, sp_f_4554 <dbl>, sp_f_5564 <dbl>,
# sp_f_65 <dbl>, sn_m_014 <dbl>, sn_m_1524 <dbl>, sn_m_2534 <dbl>,
# sn_m_3544 <dbl>, sn_m_4554 <dbl>, sn_m_5564 <dbl>, sn_m_65 <dbl>,
# sn_f_014 <dbl>, sn_f_1524 <dbl>, sn_f_2534 <dbl>, sn_f_3544 <dbl>,
# sn_f_4554 <dbl>, sn_f_5564 <dbl>, sn_f_65 <dbl>, ep_m_014 <dbl>, …
El nombre de las columnas codifica el sexo (H hombre, M mujer, NC no consta) y el grupo etario (0-9, 10-19, 20-29, 30-39, 40-49, 50-59, 60-69, 70-79, ≥80 años y NC no consta).
Diseña un bucle que recorra todas las filas y, salvo en las dos primeras columnas, convierta cada 0 casos que encuentre en la fila por un NA
Necesitamos 2 bucles: uno que recorra filas (desde la primera hasta la última) y otro que recorra columnas (desde la tercera hasta la última), y dentro del bucle: si el elemento (i, j) es 0 (o ausente), lo pasamos a ausente; en caso contrario, lo que había guardado.
Razona por qué no es tidydata y conviérte a tidy data. Si te fijas hay muchísimas filas que nos sobran (ausentes) así que haz que al pivotar las elimine.
Es un pivot_longer() sin más: le indicamos que columnas no queremos pivotar, la variable a donde irán los nombres y cómo se llamará la variable de casos; le incluimos values_drop_na = TRUE para que elimine los ausentes (de ahí que hayamos convertido los 0 para hacerlo más sencillo aquí)
Una de las columnas la tenemos codificada a veces como cosa-cosa_cosa, otras como 80-Inf_cosa, otras como NC-NC_cosa. Intenta separar dicha columna para generar tres columnas nuevas edad_inf, edad_sup y sexo de manera adecuada. Recuerda que NC es un ausente.
Si lo intentamos hacer sin procesar nada antes, vemos que los Inf y los NC figuran como tal, como cadena texto, lo que nos impide convertir a numérica el resto de la columna.
Incorpora una nueva variable a la tabla que codifice el mes y el año (por ejemplo, cualquier día de enero de 2020 será algo similar a “1-2020” y cualquier día de febrero del 2021 será “2-2021”).
Haciendo uso de esa variable de grupo mes_year y del vector de provincias permitidas que aparece debajo (busca en https://es.wikipedia.org/wiki/ISO_3166-2:ES#Provincias) obtén un resumen que nos devuelva en un tibble, por cada provincia permitida y cada mes-año, la media de casos (sin importar edad ni sexo)
Solo necesitamos recorrer cada provincia permitida y cada valor mes_year distinto, así que creamos ambos vectores. También creamos un dataset vacío resumen_mes_provincia donde, en cada iteración, pegaremos una fila con su resumen.
Una vez creados esos objetos, el bucle simplemente deberá recorrer cada valor de provincia y de mes-año: para el mes-año i y la provincia j, filtramos solo los casos para esos valores concretos (de todo el vector de casos nos quedamos con aquellos que cumplan dicha condición, eliminando también provincias ausentes). Tras filtrar guardamos la media ese filtro de casos
Diseña una función resumen_por_fecha_provincia() que dada un vector de códigos ISO de provincias permitidas, y un tabla, nos devuelva la media de casos diarios que hubo cada mes-año (sin importar sexo ni edad) en las provincias permitidas. Es decir: debes “adaptar” el código anterior a una función.
Simplemente debes copiar y pegar el código de los dos anteriores (salvo el vector de provincias que ahora será un argumento), y adaptarlo a que las provincias están en prov_iso y la tabla en datos.
La idea es que el código sea legible, como si fuese una lista de instrucciones que al leerla nos diga de manera muy evidente lo que está haciendo.
Hipótesis: tidydata
Toda la depuración que vamos a realizar es sobre la hipótesis de que nuestros datos están en tidydata
Recuerda que en {tidyverse} será clave el operador pipe (tubería) definido como |> (ctrl+shift+M): será una tubería que recorre los datos y los transforma.
Vamos a practicar con el dataset starwars del paquete cargado {dplyr}
library(tidyverse)starwars
Muestreo
Una de las operaciones más comunes es lo que se conoce en estadística como muestreo: una selección o filtrado de registros (una submuestra)
No aleatorio (por cuotas): en base a condiciones lógicas sobre los registros (filter())
No aleatorio (intencional/discreccional): en base a posición (slice())
El más simple es cuando filtramos registros en base a alguna condición lógica: con filter() se seleccionarán solo individuos que cumplan ciertas condiciones (muestreo no aleatorio por condiciones)
==, !=: igual o distinto que (|> filter(variable == "a"))
>, <: mayor o menor que (|> filter(variable < 3))
>=, <=: mayor o igual o menor o igual que (|> filter(variable >= 5))
%in%: valores pertenencen a un listado de opciones (|> filter(variable %in% c("azul", "verde")))
between(variable, val1, val2): si los valores (continuos) caen dentro de un rango de valores (|> filter(between(variable, 160, 180)))
Filtrar filas: filter()
Dichas condiciones lógicas las podemos combinar de diferentes maneras (y, o, o excluyente)
Importante
Recuerda que dentro de filter() debe ir siempre algo que devuelva un vector de valores lógicos.
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías para… filtrar los personajes de ojos marrones?
¿Qué tipo de variable es? –> La variable eye_color es cualitativa así que está representada por textos
starwars |>filter(eye_color =="brown")
# A tibble: 21 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Leia Or… 150 49 brown light brown 19 fema… femin…
2 Biggs D… 183 84 black light brown 24 male mascu…
3 Han Solo 180 80 brown fair brown 29 male mascu…
4 Yoda 66 17 white green brown 896 male mascu…
5 Boba Fe… 183 78.2 black fair brown 31.5 male mascu…
6 Lando C… 177 79 black dark brown 31 male mascu…
7 Arvel C… NA NA brown fair brown NA male mascu…
8 Wicket … 88 20 brown brown brown 8 male mascu…
9 Padmé A… 185 45 brown light brown 46 fema… femin…
10 Quarsh … 183 NA black dark brown 62 male mascu…
# ℹ 11 more rows
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías para… filtrar los personajes que no tienen ojos marrones?
starwars |>filter(eye_color !="brown")
# A tibble: 66 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Luke Sk… 172 77 blond fair blue 19 male mascu…
2 C-3PO 167 75 <NA> gold yellow 112 none mascu…
3 R2-D2 96 32 <NA> white, bl… red 33 none mascu…
4 Darth V… 202 136 none white yellow 41.9 male mascu…
5 Owen La… 178 120 brown, gr… light blue 52 male mascu…
6 Beru Wh… 165 75 brown light blue 47 fema… femin…
7 R5-D4 97 32 <NA> white, red red NA none mascu…
8 Obi-Wan… 182 77 auburn, w… fair blue-gray 57 male mascu…
9 Anakin … 188 84 blond fair blue 41.9 male mascu…
10 Wilhuff… 180 NA auburn, g… fair blue 64 male mascu…
# ℹ 56 more rows
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías para … filtrar los personajes que tengan los ojos marrones o azules?
# A tibble: 40 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Luke Sk… 172 77 blond fair blue 19 male mascu…
2 Leia Or… 150 49 brown light brown 19 fema… femin…
3 Owen La… 178 120 brown, gr… light blue 52 male mascu…
4 Beru Wh… 165 75 brown light blue 47 fema… femin…
5 Biggs D… 183 84 black light brown 24 male mascu…
6 Anakin … 188 84 blond fair blue 41.9 male mascu…
7 Wilhuff… 180 NA auburn, g… fair blue 64 male mascu…
8 Chewbac… 228 112 brown unknown blue 200 male mascu…
9 Han Solo 180 80 brown fair brown 29 male mascu…
10 Jek Ton… 180 110 brown fair blue NA <NA> <NA>
# ℹ 30 more rows
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
Fíjate que %in% es equivalente a concatenar varios == con una conjunción o (|)
# A tibble: 40 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Luke Sk… 172 77 blond fair blue 19 male mascu…
2 Leia Or… 150 49 brown light brown 19 fema… femin…
3 Owen La… 178 120 brown, gr… light blue 52 male mascu…
4 Beru Wh… 165 75 brown light blue 47 fema… femin…
5 Biggs D… 183 84 black light brown 24 male mascu…
6 Anakin … 188 84 blond fair blue 41.9 male mascu…
7 Wilhuff… 180 NA auburn, g… fair blue 64 male mascu…
8 Chewbac… 228 112 brown unknown blue 200 male mascu…
9 Han Solo 180 80 brown fair brown 29 male mascu…
10 Jek Ton… 180 110 brown fair blue NA <NA> <NA>
# ℹ 30 more rows
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías para … filtrar los personajes que midan entre 120 y 160 cm?
¿Qué tipo de variable es? –> La variable height es cuantitativa continua así que deberemos filtrar por rangos de valores (intervalos) –> usaremos between()
starwars |>filter(between(height, 120, 160))
# A tibble: 6 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Leia Org… 150 49 brown light brown 19 fema… femin…
2 Mon Moth… 150 NA auburn fair blue 48 fema… femin…
3 Nien Nunb 160 68 none grey black NA male mascu…
4 Watto 137 NA black blue, grey yellow NA male mascu…
5 Gasgano 122 NA none white, bl… black NA male mascu…
6 Cordé 157 NA brown light brown NA <NA> <NA>
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías… filtrar los personajes que tengan ojos y no sean humanos?
starwars |>filter(eye_color =="brown"& species !="Human")
# A tibble: 3 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Yoda 66 17 white green brown 896 male mascu…
2 Wicket S… 88 20 brown brown brown 8 male mascu…
3 Eeth Koth 171 NA black brown brown NA male mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Filtrar filas: filter()
datos |>filtro(condicion)
starwars |>filter(condicion)
¿Cómo harías… filtrar los personajes que tengan ojos y no sean humanos, o que tengan más de 60 años? Piénsalo bien: los paréntesis son importantes: no es lo mismo \((a+b)*c\) que \(a+(b*c)\)
starwars |>filter((eye_color =="brown"& species !="Human") | birth_year >60)
# A tibble: 18 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 C-3PO 167 75 <NA> gold yellow 112 none mascu…
2 Wilhuff… 180 NA auburn, g… fair blue 64 male mascu…
3 Chewbac… 228 112 brown unknown blue 200 male mascu…
4 Jabba D… 175 1358 <NA> green-tan… orange 600 herm… mascu…
5 Yoda 66 17 white green brown 896 male mascu…
6 Palpati… 170 75 grey pale yellow 82 male mascu…
7 Wicket … 88 20 brown brown brown 8 male mascu…
8 Qui-Gon… 193 89 brown fair blue 92 male mascu…
9 Finis V… 170 NA blond fair blue 91 male mascu…
10 Quarsh … 183 NA black dark brown 62 male mascu…
11 Shmi Sk… 163 NA black fair brown 72 fema… femin…
12 Mace Wi… 188 84 none dark brown 72 male mascu…
13 Ki-Adi-… 198 82 white pale yellow 92 male mascu…
14 Eeth Ko… 171 NA black brown brown NA male mascu…
15 Cliegg … 183 NA brown fair blue 82 male mascu…
16 Dooku 193 80 white fair brown 102 male mascu…
17 Bail Pr… 191 NA black tan brown 67 male mascu…
18 Jango F… 183 79 black tan brown 66 male mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Eliminar ausentes: drop_na()
datos |>retirar_ausentes(var1, var2, ...)
starwars |>drop_na(var1, var2, ...)
Hay un filtro especial para una de las operaciones más habituales en depuración: retirar los ausentes. Para ello podemos usar dentro de un filtro is.na(), que nos devuelve TRUE/FALSE en función de si es ausente, o bien …
Usar drop_na(): si no indicamos variable, elimina registros con ausente en cualquier variable. Más adelante veremos como imputar esos ausentes
starwars |>drop_na(mass, height)
# A tibble: 7 × 4
name mass height hair_color
<chr> <dbl> <int> <chr>
1 Luke Skywalker 77 172 blond
2 C-3PO 75 167 <NA>
3 R2-D2 32 96 <NA>
4 Darth Vader 136 202 none
5 Leia Organa 49 150 brown
6 Owen Lars 120 178 brown, grey
7 Beru Whitesun Lars 75 165 brown
starwars |>drop_na()
# A tibble: 7 × 4
name mass height hair_color
<chr> <dbl> <int> <chr>
1 Luke Skywalker 77 172 blond
2 Darth Vader 136 202 none
3 Leia Organa 49 150 brown
4 Owen Lars 120 178 brown, grey
5 Beru Whitesun Lars 75 165 brown
6 Biggs Darklighter 84 183 black
7 Obi-Wan Kenobi 77 182 auburn, white
💻 Tu turno
Intenta realizar los siguientes ejercicios sin mirar las soluciones
📝 Selecciona del conjunto original de starwars los personajes no humanos, male en el sexo y que midan entre 120 y 170 cm, o los personajes con ojos marrones o rojos.
📝 Busca información en la ayuda de la función str_detect() del paquete {stringr} (cargado en {tidyverse}). Consejo: prueba antes las funciones que vayas a usar con algún vector de prueba para poder comprobar su funcionamiento. Tras saber lo que hace, filtra solo aquellos personajes con apellido Skywalker
Code
starwars |>filter(str_detect(name, "Skywalker"))
Rebanadas de datos: slice()
datos |>rebanadas(posiciones)
starwars |>slice(posiciones)
A veces nos puede interesar realizar un muestreo no aleatorio discreccional, o lo que es lo mismo, filtrar por posición: con slice(posiciones) podremos seleccionar filas concretas pasando como argumento un vector de índices
# fila 1starwars |>slice(1)
# A tibble: 1 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Luke Skywalker 172 77 blond
# filas de la 7 a la 9starwars |>slice(7:9)
# A tibble: 3 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Beru Whitesun Lars 165 75 brown
2 R5-D4 97 32 <NA>
3 Biggs Darklighter 183 84 black
# A tibble: 4 × 8
name height mass hair_color skin_color eye_color birth_year sex
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 C-3PO 167 75 <NA> gold yellow 112 none
2 Beru Whitesun L… 165 75 brown light blue 47 fema…
3 Obi-Wan Kenobi 182 77 auburn, w… fair blue-gray 57 male
4 Qui-Gon Jinn 193 89 brown fair blue 92 male
Rebanadas de datos: slice()
datos |>rebanadas(posiciones)
starwars |>slice(posiciones)
Disponemos de opciones por defecto:
con slice_head(n = ...) y slice_tail(n = ...) podemos obtener la cabecera y cola de la tabla
starwars |>slice_head(n =2)
# A tibble: 2 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Luke Skywalker 172 77 blond
2 C-3PO 167 75 <NA>
starwars |>slice_tail(n =2)
# A tibble: 2 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 BB8 NA NA none
2 Captain Phasma NA NA none
Rebanadas de datos: slice()
datos |>rebanadas(posiciones)
starwars |>slice(posiciones)
Disponemos de opciones por defecto:
con slice_max() y slice_min() obtenemos la filas con menor/mayor valor de una variable (si empate, todas salvo que with_ties = FALSE) que indicamos en order_by = ...
starwars |>slice_min(mass, n =2)
# A tibble: 2 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Ratts Tyerel 79 15 none
2 Yoda 66 17 white
starwars |>slice_max(height, n =2)
# A tibble: 2 × 4
name height mass hair_color
<chr> <int> <dbl> <chr>
1 Yarael Poof 264 NA none
2 Tarfful 234 136 brown
Aleatorio: slice_sample()
datos |>rebanadas_aleatorias(posiciones)
starwars |>slice_sample(posiciones)
El conocido como muestreo aleatorio simple se basa en seleccionar individuos aleatoriamente, de forma que cada uno tenga ciertas probabilidades de ser seleccionado. Con slice_sample(n = ...) podemos extraer n registros aleatoriamente (a priori equiprobables).
starwars |>slice_sample(n =2)
# A tibble: 2 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Gregar T… 185 85 black dark brown NA <NA> <NA>
2 Anakin S… 188 84 blond fair blue 41.9 male mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Importante…
«Aleatorio» no implica equiprobable: es igual de aleatorio un dado normal que uno trucado. No hay cosas «más aleatorias» que otras, simplemente tienen subyacente distintas leyes de probabilidad.
Aleatorio: slice_sample()
datos |>rebanadas_aleatorias(posiciones)
starwars |>slice_sample(posiciones)
También podremos indicarle la proporción de datos a samplear (en lugar del número) y si queremos que sea con reemplazamiento (que se puedan repetir).
# 5% de registros aleatorios con reemplazamientostarwars |>slice_sample(prop =0.05, replace =TRUE)
# A tibble: 4 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Luke Sky… 172 77 blond fair blue 19 male mascu…
2 Bib Fort… 180 NA none pale pink NA male mascu…
3 Padmé Am… 185 45 brown light brown 46 fema… femin…
4 Obi-Wan … 182 77 auburn, w… fair blue-gray 57 male mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Aleatorio: slice_sample()
datos |>rebanadas_aleatorias(posiciones)
starwars |>slice_sample(posiciones)
Como decíamos, «aleatorio» no es igual que «equiprobable», así que podemos pasarle un vector de probabilidades. Por ejemplo, vamos a forzar que sea muy improbable sacar una fila que no sean las dos primeras
# A tibble: 2 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 C-3PO 167 75 <NA> gold yellow 112 none mascu…
2 Luke Sky… 172 77 blond fair blue 19 male mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Paréntesis: sample()
La función slice_sample() es simplemente una integración de {tidyverse} de la función básica de R conocida como sample() que nos permite muestrear elementos
Por ejemplo, vamos a muestrear 10 tiradas de un dado, indicándole
soporte de nuestra variable aleatorio (valores permitidos en x)
tamaño muestral (size)
reemplazamiento (si TRUE entonces pueden salir repetidas, como en el caso del dado)
sample(x =1:6, size =10, replace =TRUE)
[1] 4 6 4 6 6 1 2 1 6 6
Paréntesis: sample()
La opción anterior lo que genera son sucesos de una variable aleatoria equiprobable pero al igual que antes, podemos asignarle un vector de probabilidades o función de masa concreta con el argumento prob = ...
Supongamos que en una ciudad se han estudiado episodios de gripe estacional. Sean las variables aleatorias \(X_m\) y \(X_p\) tal que \(X_m=1\) si la madre tiene gripe, \(X_m=0\) si la madre no tiene gripe, \(X_p=1\) si el padre tiene gripe y \(X_p=0\) si el padre no tiene gripe. El modelo teórico asociado a este tipo de epidemias indica que la distribución conjunta viene dada por \(P(X_m = 1, X_p=1)=0.02\), \(P(X_m = 1, X_p=0)=0.08\), \(P(X_m = 1, X_p=0)=0.1\) y \(P(X_m = 0, X_p=0)=0.8\)
Genera una muestra de tamaño \(n = 1000\) (soporte "10", "01", "00" y "11") haciendo uso de runif() y haciendo uso de sample()
Reordenar filas: arrange()
datos |>ordenar(var1, var2, ...)
starwars |>arrange(var1, var2, ...)
También podemos ordenar filas en función de alguna variable con arrange()
starwars |>arrange(mass)
# A tibble: 5 × 6
name height mass hair_color skin_color eye_color
<chr> <int> <dbl> <chr> <chr> <chr>
1 Ratts Tyerel 79 15 none grey, blue unknown
2 Yoda 66 17 white green brown
3 Wicket Systri Warrick 88 20 brown brown brown
4 R2-D2 96 32 <NA> white, blue red
5 R5-D4 97 32 <NA> white, red red
Por defecto de menor a mayor pero podemos invertir el orden con desc()
starwars |>arrange(desc(height))
# A tibble: 5 × 3
name height mass
<chr> <int> <dbl>
1 Yarael Poof 264 NA
2 Tarfful 234 136
3 Lama Su 229 88
4 Chewbacca 228 112
5 Roos Tarpals 224 82
📝 Para saber que valores únicos hay en el color de pelo, elimina duplicados de la variable hair_color, eliminando antes los ausentes de dicha variable.
📝 De los personajes que son humanos y miden más de 160 cm, elimina duplicados en color de ojos, elimina ausentes en peso, selecciona los 3 más altos, y orden de mayor a menor peso. Devuelve la tabla.
La clave de {tidyverse} es la legibilidad: es importantísimo que el código se entienda, por nuestro yo el futuro pero también por la transparencia algorítmica hacia los demás
Por ejemplo: quitaremos ausentes de la variable peso, filtraremos los personajes humanos y altura superior a 140cm, sin duplicados en el color de pelo, extrayendo los 5 más altos y obteniendo 2 personajes aleatorios finalmente.
starwars |>elimino_ausentes(peso) |>filtro(especie humana Y altura >140 cm) |>sin_duplicados(color de pelo) |>rebanadas_max(peso, n =5) |>rebanadas_aleatorias(n =2)
La clave de {tidyverse} es la legibilidad: es importantísimo que el código se entienda, por nuestro yo el futuro pero también por la transparencia algorítmica hacia los demás
Por ejemplo: quitaremos ausentes de la variable peso, filtraremos los personajes humanos y altura superior a 140cm, sin duplicados en el color de pelo, extrayendo los 5 más altos y obteniendo 2 personajes aleatorios finalmente.
starwars |>elimino_ausentes(peso) |>filtro(especie humana Y altura >140 cm) |>sin_duplicados(color de pelo) |>rebanadas_max(peso, n =5) |>rebanadas_aleatorias(n =2)
La clave de {tidyverse} es la legibilidad: es importantísimo que el código se entienda, por nuestro yo el futuro pero también por la transparencia algorítmica hacia los demás
Por ejemplo: quitaremos ausentes de la variable peso, filtraremos los personajes humanos y altura superior a 140cm, sin duplicados en el color de pelo, extrayendo los 5 más altos y obteniendo 2 personajes aleatorios finalmente.
starwars |>elimino_ausentes(peso) |>filtro(especie humana Y altura >140 cm) |>sin_duplicados(color de pelo) |>rebanadas_max(peso, n =5) |>rebanadas_aleatorias(n =2)
La clave de {tidyverse} es la legibilidad: es importantísimo que el código se entienda, por nuestro yo el futuro pero también por la transparencia algorítmica hacia los demás
Por ejemplo: quitaremos ausentes de la variable peso, filtraremos los personajes humanos y altura superior a 140cm, sin duplicados en el color de pelo, extrayendo los 5 más altos y obteniendo 2 personajes aleatorios finalmente.
starwars |>elimino_ausentes(peso) |>filtro(especie humana Y altura >140 cm) |>sin_duplicados(color de pelo) |>rebanadas_max(peso, n =5) |>rebanadas_aleatorias(n =2)
La clave de {tidyverse} es la legibilidad: es importantísimo que el código se entienda, por nuestro yo el futuro pero también por la transparencia algorítmica hacia los demás
Por ejemplo: quitaremos ausentes de la variable peso, filtraremos los personajes humanos y altura superior a 140cm, sin duplicados en el color de pelo, extrayendo los 5 más altos y obteniendo 2 personajes aleatorios finalmente.
starwars |>elimino_ausentes(peso) |>filtro(especie humana Y altura >140 cm) |>sin_duplicados(color de pelo) |>rebanadas_max(peso, n =5) |>rebanadas_aleatorias(n =2)
Vamos a volver aun viejo conocido: en el paquete {datasets} (ya instalado por defecto) teníamos diversos conjuntos de datos y uno de ellos era airquality con el que ya trabajamos. Los datos capturan medidas diarias (n = 153 observaciones) de la calidad del aire en Nueva York, de mayo a septiembre de 1973.
En ese momento lo trabajamos desde la perspectiva de R base y extrayendo algunas variables del mismo. El objetivo ahora será trabajarlo desde la perspectiva de {tidyverse} fijándonos en las diferencias de una y otra forma.
library(datasets)airquality
Intenta responder a las preguntas planteadas en el workbook.
Hasta ahora todas las operaciones realizadas (aunque usásemos info de columnas) eran por filas. En elc aso de columnas, la acción más sencilla es seleccionar variables por nombre con select(), dando como argumentos los nombres de columnas sin comillas.
starwars |>select(name, hair_color)
# A tibble: 87 × 2
name hair_color
<chr> <chr>
1 Luke Skywalker blond
2 C-3PO <NA>
3 R2-D2 <NA>
4 Darth Vader none
5 Leia Organa brown
6 Owen Lars brown, grey
7 Beru Whitesun Lars brown
8 R5-D4 <NA>
9 Biggs Darklighter black
10 Obi-Wan Kenobi auburn, white
# ℹ 77 more rows
Selección columnas: select()
datos |>selecciono(var1, var2, ...)
starwars |>select(var1, var2, ...)
La función select() nos permite seleccionar varias variables a la vez, incluso concatenando sus nombres como si fuesen índices numéricos
starwars |>select(name:eye_color)
# A tibble: 4 × 6
name height mass hair_color skin_color eye_color
<chr> <int> <dbl> <chr> <chr> <chr>
1 Luke Skywalker 172 77 blond fair blue
2 C-3PO 167 75 <NA> gold yellow
3 R2-D2 96 32 <NA> white, blue red
4 Darth Vader 202 136 none white yellow
Y podemos deseleccionar columnas con - delante
starwars |>select(-mass, -(eye_color:starships))
# A tibble: 4 × 4
name height hair_color skin_color
<chr> <int> <chr> <chr>
1 Luke Skywalker 172 blond fair
2 C-3PO 167 <NA> gold
3 R2-D2 96 <NA> white, blue
4 Darth Vader 202 none white
Selección columnas: select()
datos |>selecciono(var1, var2, ...)
starwars |>select(var1, var2, ...)
Tenemos además palabras reservadas: everything()todas las variables…
starwars |>select(mass, homeworld, everything())
# A tibble: 4 × 14
mass homeworld name height hair_color skin_color eye_color birth_year sex
<dbl> <chr> <chr> <int> <chr> <chr> <chr> <dbl> <chr>
1 77 Tatooine Luke … 172 blond fair blue 19 male
2 75 Tatooine C-3PO 167 <NA> gold yellow 112 none
3 32 Naboo R2-D2 96 <NA> white, bl… red 33 none
4 136 Tatooine Darth… 202 none white yellow 41.9 male
# ℹ 5 more variables: gender <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
…y last_col() para referirnos a la última columna.
# A tibble: 4 × 5
name height mass homeworld starships
<chr> <int> <dbl> <chr> <list>
1 Luke Skywalker 172 77 Tatooine <chr [2]>
2 C-3PO 167 75 Tatooine <chr [0]>
3 R2-D2 96 32 Naboo <chr [0]>
4 Darth Vader 202 136 Tatooine <chr [1]>
Selección columnas: select()
datos |>selecciono(var1, var2, ...)
starwars |>select(var1, var2, ...)
También podemos jugar con patrones en el nombre, aquellas que comiencen por un prefijo (starts_with()), terminen con un sufijo (ends_with()), contengan un texto (contains()) o cumplan una expresión regular (matches()).
# variables cuyo nombre acaba en "color" y contengan sexo o génerostarwars |>select(ends_with("color"), matches("sex|gender"))
# A tibble: 87 × 5
hair_color skin_color eye_color sex gender
<chr> <chr> <chr> <chr> <chr>
1 blond fair blue male masculine
2 <NA> gold yellow none masculine
3 <NA> white, blue red none masculine
4 none white yellow male masculine
5 brown light brown female feminine
6 brown, grey light blue male masculine
7 brown light blue female feminine
8 <NA> white, red red none masculine
9 black light brown male masculine
10 auburn, white fair blue-gray male masculine
# ℹ 77 more rows
Selección columnas: select()
datos |>selecciono(var1, var2, ...)
starwars |>select(var1, var2, ...)
Incluso podemos seleccionar por rango numérico si tenemos variables con un prefijo y números.
Con num_range() podemos seleccionar con un prefijo y una secuencia numérica.
datos |>select(num_range("semana", 1:4))
# A tibble: 3 × 4
semana1 semana2 semana3 semana4
<dbl> <dbl> <dbl> <dbl>
1 115 7 95 11
2 141 NA 162 19
3 232 17 NA 15
Selección columnas: select()
datos |>selecciono(var1, var2, ...)
starwars |>select(var1, var2, ...)
Por último, podemos seleccionar columnas por tipo de dato haciendo uso de where() y dentro una función que devuelva un valor lógico de tipo de dato.
# Solo columnas numéricas o de textostarwars |>select(where(is.numeric) |where(is.character))
# A tibble: 87 × 11
height mass birth_year name hair_color skin_color eye_color sex gender
<int> <dbl> <dbl> <chr> <chr> <chr> <chr> <chr> <chr>
1 172 77 19 Luke Sk… blond fair blue male mascu…
2 167 75 112 C-3PO <NA> gold yellow none mascu…
3 96 32 33 R2-D2 <NA> white, bl… red none mascu…
4 202 136 41.9 Darth V… none white yellow male mascu…
5 150 49 19 Leia Or… brown light brown fema… femin…
6 178 120 52 Owen La… brown, gr… light blue male mascu…
7 165 75 47 Beru Wh… brown light blue fema… femin…
8 97 32 NA R5-D4 <NA> white, red red none mascu…
9 183 84 24 Biggs D… black light brown male mascu…
10 182 77 57 Obi-Wan… auburn, w… fair blue-gray male mascu…
# ℹ 77 more rows
# ℹ 2 more variables: homeworld <chr>, species <chr>
Mover columnas: relocate()
datos |>recolocar(var1, despues_de = var2)
starwars |>relocate(var1, .after = var2)
Para facilitar la recolocación de variables tenemos una función para ello, relocate(), indicándole en .after o .beforedetrás o delante de qué columnas queremos moverlas.
starwars |>relocate(species, .before = name)
# A tibble: 87 × 14
species name height mass hair_color skin_color eye_color birth_year sex
<chr> <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 Human Luke S… 172 77 blond fair blue 19 male
2 Droid C-3PO 167 75 <NA> gold yellow 112 none
3 Droid R2-D2 96 32 <NA> white, bl… red 33 none
4 Human Darth … 202 136 none white yellow 41.9 male
5 Human Leia O… 150 49 brown light brown 19 fema…
6 Human Owen L… 178 120 brown, gr… light blue 52 male
7 Human Beru W… 165 75 brown light blue 47 fema…
8 Droid R5-D4 97 32 <NA> white, red red NA none
9 Human Biggs … 183 84 black light brown 24 male
10 Human Obi-Wa… 182 77 auburn, w… fair blue-gray 57 male
# ℹ 77 more rows
# ℹ 5 more variables: gender <chr>, homeworld <chr>, films <list>,
# vehicles <list>, starships <list>
Renombrar: rename()
datos |>renombrar(nuevo = antiguo)
starwars |>rename(nuevo = antiguo)
A veces también podemos querer modificar la «metainformación» de los datos, renombrando columnas. Para ello usaremos de rename() poniendo primero el nombre nuevo y luego el antiguo.
📝 Filtra el conjunto de personajes y quédate solo con aquellos que en la variable height no tengan un dato ausente. Con los datos obtenidos del filtro anterior, selecciona solo las variables name, height, así como todas aquellas variables que CONTENGAN la palabra color en su nombre.
📝 Con los datos obtenidos del ejercicio 1, coloca la variable de color de pelo justo detrás de la variable de nombres.
Code
starwars_2 |>relocate(hair_color, .after = name)
📝 Con los datos obtenidos del ejercicio 1, comprueba cuántas modalidades únicas hay en la variable de color de pelo (sin usar unique()).
Code
starwars_2 |>distinct(hair_color) |>nrow()
📝 Del conjunto de datos originales, elimina las columnas de tipo lista, y tras ello elimina duplicados en la variable eye_color. Tras eliminar duplicados extrae dicha columna en un vector.
📝 Del conjunto de datos original de starwars, con solo los personajes cuya altura es conocida, extrae en un vector con dicha variable.
Code
starwars |>drop_na(height) |>pull(height)
📝 Tras obtener el vector del ejercicio anterior, usa dicho vector para realizar un muestreo aleatorio del 50% de los datos de manera que la probabilidad de cada personaje de ser elegido sea inversamente proporcional a su altura (más bajitos, más opciones).
# A tibble: 87 × 16
height_m IMC name height mass hair_color skin_color eye_color birth_year
<dbl> <dbl> <chr> <int> <dbl> <chr> <chr> <chr> <dbl>
1 1.72 26.0 Luke … 172 77 blond fair blue 19
2 1.67 26.9 C-3PO 167 75 <NA> gold yellow 112
3 0.96 34.7 R2-D2 96 32 <NA> white, bl… red 33
4 2.02 33.3 Darth… 202 136 none white yellow 41.9
5 1.5 21.8 Leia … 150 49 brown light brown 19
6 1.78 37.9 Owen … 178 120 brown, gr… light blue 52
7 1.65 27.5 Beru … 165 75 brown light blue 47
8 0.97 34.0 R5-D4 97 32 <NA> white, red red NA
9 1.83 25.1 Biggs… 183 84 black light brown 24
10 1.82 23.2 Obi-W… 182 77 auburn, w… fair blue-gray 57
# ℹ 77 more rows
# ℹ 7 more variables: sex <chr>, gender <chr>, homeworld <chr>, species <chr>,
# films <list>, vehicles <list>, starships <list>
Modificar columnas: mutate()
datos |>modificar(nueva =funcion())
starwars |>mutate(nueva =funcion())
Importante…
Cuando aplicamos mutate(), debemos de acordarnos que las operaciones se realizan de manera vectorial, elemento a elemento, por lo que la función que usemos dentro debe devolver un vector de igual longitud. En caso contrario, devolverá una constante
# A tibble: 87 × 15
constante name height mass hair_color skin_color eye_color birth_year sex
<dbl> <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 97.3 Luke… 172 77 blond fair blue 19 male
2 97.3 C-3PO 167 75 <NA> gold yellow 112 none
3 97.3 R2-D2 96 32 <NA> white, bl… red 33 none
4 97.3 Dart… 202 136 none white yellow 41.9 male
5 97.3 Leia… 150 49 brown light brown 19 fema…
6 97.3 Owen… 178 120 brown, gr… light blue 52 male
7 97.3 Beru… 165 75 brown light blue 47 fema…
8 97.3 R5-D4 97 32 <NA> white, red red NA none
9 97.3 Bigg… 183 84 black light brown 24 male
10 97.3 Obi-… 182 77 auburn, w… fair blue-gray 57 male
# ℹ 77 more rows
# ℹ 6 more variables: gender <chr>, homeworld <chr>, species <chr>,
# films <list>, vehicles <list>, starships <list>
Recategorizar: if_else()
También podemos combinar mutate() con la expresión de control if_else() para recategorizar la variable: si se cumple una condición, hace una cosa, en caso contrario otra.
# A tibble: 87 × 4
name human height mass
<chr> <chr> <int> <dbl>
1 Luke Skywalker Human 172 77
2 C-3PO Not Human 167 75
3 R2-D2 Not Human 96 32
4 Darth Vader Human 202 136
5 Leia Organa Human 150 49
6 Owen Lars Human 178 120
7 Beru Whitesun Lars Human 165 75
8 R5-D4 Not Human 97 32
9 Biggs Darklighter Human 183 84
10 Obi-Wan Kenobi Human 182 77
# ℹ 77 more rows
Recategorizar: case_when()
Para recategorizaciones más complejas tenemos case_when(), por ejemplo, para crear una categoría de los personajes en función de su altura.
# A tibble: 81 × 15
altura name height mass hair_color skin_color eye_color birth_year sex
<chr> <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 normal Luke S… 172 77 blond fair blue 19 male
2 normal C-3PO 167 75 <NA> gold yellow 112 none
3 enanos R2-D2 96 32 <NA> white, bl… red 33 none
4 gigante Darth … 202 136 none white yellow 41.9 male
5 bajito Leia O… 150 49 brown light brown 19 fema…
6 normal Owen L… 178 120 brown, gr… light blue 52 male
7 normal Beru W… 165 75 brown light blue 47 fema…
8 enanos R5-D4 97 32 <NA> white, red red NA none
9 alto Biggs … 183 84 black light brown 24 male
10 alto Obi-Wa… 182 77 auburn, w… fair blue-gray 57 male
# ℹ 71 more rows
# ℹ 6 more variables: gender <chr>, homeworld <chr>, species <chr>,
# films <list>, vehicles <list>, starships <list>
Datos anidados
También podemos anidar o incrustar datasets uno dentro de otro. Imagina que tenemos un dataset de variables x e y con 2 registros, otro con las mismas variables pero solo un registro y otro de 3 registros.
Hasta ahora la única manera que sabemos de juntar los 3 datasets es haciendo uso de bind_rows() (por cierto, si usas el argumento .id = "nombre_variable" podemos hacer que se añade sola una nueva variable que nos diga a que dataset pertenecía cada fila
data <-bind_rows(data_1, data_2, data_3, .id ="dataset")data
# A tibble: 6 × 3
dataset x y
<chr> <dbl> <dbl>
1 1 0 -1
2 1 2 NA
3 2 NA 5
4 3 -2 1.5
5 3 6 NA
6 3 7 -2
Datos anidados
data <-bind_rows(data_1, data_2, data_3, .id ="dataset")data
# A tibble: 6 × 3
dataset x y
<chr> <dbl> <dbl>
1 1 0 -1
2 1 2 NA
3 2 NA 5
4 3 -2 1.5
5 3 6 NA
6 3 7 -2
Sin embargo en muchas ocasiones lo que querremos es tener los 3 en un mismo objeto PERO cada dataset por su cuenta: un objeto (una lista) que almacene los 3 datasets separados entre sí.
Para ello usaremos la función nest() indicando que variables comunes forman los datasets (en este caso x e y)
📝 Selecciona solo las variables nombre, altura y así como todas aquellas variables relacionadas con el color, a la vez que te quedas solo con aquellos que no tengan ausente en la altura.
📝 Del dataset original, selecciona solo las variables numéricas y de tipo texto. Tras ello define una nueva variable llamada under_18 que nos recategorice la variable de edad: TRUE si es menor de edad y FALSE en caso contrario
📝 Del dataset original, crea una nueva columna llamada auburn (cobrizo/caoba) que nos diga TRUE si el color de pelo contiene dicha palabra y FALSE en caso contrario (reminder str_detect()).
📝 Del dataset original, incluye una columna que calcule el IMC. Tras ello, crea una nueva variable que valga NA si no es humano, delgadez por debajo de 18, normal entre 18 y 30, sobrepeso por encima de 30.
Haciendo uso de todo lo aprendido, vamos a proceder a crear una tabla con datos de bebés de tamaño n = 20 en donde simulemos el sexo de los bebés y su peso
Crea un tibble con dos columnas, una llamada id_bebe y otra llamada sexo. En el primer caso debe ir de 1 a 20. En el segundo caso, simula su sexo de manera que haya un 0.5 de probabilidad de chico y 0.5 de chica.
Conocido el sexo, crea una tercera columna llamada peso en la que simules dicho valor. Supondremos que para los chicos el peso sigue una distribución \(N(\mu = 3.266kg, \sigma = 0.514)\) y que para las chicas sigue una distribución \(N(\mu = 3.155kg, \sigma = 0.495)\).
¿Te acuerdas de la entrega de Taylor Swift? Vamos a repetir exactamente las mismas cuestiones pero ahora en modo tidyverse: prohibidos [], $ y demás.
Intenta responder a las preguntas planteadas en el workbook
🐣 Caso práctico III: señor de los anillos
Para practicar algunas funciones de {dplyr} vamos a usar datos de las películas de la trilogía de El Señor de los Anillos. Los datos los cargaremos directamente desde la web (Github en este caso), sin pasar por el ordenador antes, simplemente indicando como ruta la web donde está el archivo
Hasta ahora solo hemos transformado o consultado los datos pero no hemos generado estadísticas. Empecemos por lo sencillo: ¿cómo contar (frecuencias)?
Cuando lo usamos en solitario count() nos devolverá simplemente el número de registros , pero cuando lo usamos con variables count() calcula lo que se conoce como frecuencias: número de elementos de cada modalidad.
starwars |>count(sex)
# A tibble: 5 × 2
sex n
<chr> <int>
1 female 16
2 hermaphroditic 1
3 male 60
4 none 6
5 <NA> 4
Contar: count()
datos |>contar(var1, var2)
starwars |>count(var1, var2)
Además si pasamos varias variables nos calcula lo que se conoce como una tabla de contigencia. Con sort = TRUE nos devolverá el conteo ordenado (más frecuentes primero).
starwars |>count(sex, gender, sort =TRUE)
# A tibble: 6 × 3
sex gender n
<chr> <chr> <int>
1 male masculine 60
2 female feminine 16
3 none masculine 5
4 <NA> <NA> 4
5 hermaphroditic masculine 1
6 none feminine 1
Agrupar: group_by()
datos |>agrupar(var1, var2) |>accion() |>desagrupar()
Cuando apliquemos group_by() es importante entender que NO MODIFICA los datos, sino que nos crea una variable de grupo (subtablas por cada grupo) que modificará las acciones futuras: las operaciones se aplicarán a cada subtabla por separado
Por ejemplo, imaginemos que queremos extraer el personaje más alto con slice_max().
starwars |>slice_max(height)
# A tibble: 1 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Yarael P… 264 NA none white yellow NA male mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Agrupar: group_by()
datos |>agrupar(var1, var2) |>accion() |>desagrupar()
# A tibble: 5 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Taun We 213 NA none grey black NA fema… femin…
2 Jabba De… 175 1358 <NA> green-tan… orange 600 herm… mascu…
3 Yarael P… 264 NA none white yellow NA male mascu…
4 IG-88 200 140 none metal red 15 none mascu…
5 Gregar T… 185 85 black dark brown NA <NA> <NA>
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Agrupar: group_by()
datos |>agrupar(var1, var2) |>accion() |>desagrupar()
Recuerda siempre hacer ungroup para eliminar la variable de grupo creada
En la nueva versión de {dplyr} ahora se permite incluir la variable de grupo en la llamada a muchas funciones con el argumento by = ... o .by = ...
starwars |>slice_max(height, by = sex)
# A tibble: 5 × 6
name height mass hair_color skin_color eye_color
<chr> <int> <dbl> <chr> <chr> <chr>
1 Yarael Poof 264 NA none white yellow
2 IG-88 200 140 none metal red
3 Taun We 213 NA none grey black
4 Jabba Desilijic Tiure 175 1358 <NA> green-tan, brown orange
5 Gregar Typho 185 85 black dark brown
Fila-a-fila: rowwise()
Una opción muy útil usada antes de una operación también es rowwise(): toda operación que venga después se aplicará en cada fila por separado. Por ejemplo, vamos a definir un conjunto dummy de notas.
Si aplicamos la media directamente el valor será idéntico ya que nos ha hecho la media global, pero nos gustaría sacar una media por registro. Para eso usaremos rowwise()
Fíjate que mutate() devuelve tantas filas como registros originales, mientras que con summarise() calcula un nuevo dataset de resumen, solo incluyendo aquello que esté indicado.
Resumir: summarise()
datos |>resumir()
starwars |>summarise()
Si además esto lo combinamos con la agrupación de group_by() o .by = ..., en pocas líneas de código puedes obtener estadísticas desagreagadas
Warning: Returning more (or less) than 1 row per `summarise()` group was deprecated in
dplyr 1.1.0.
ℹ Please use `reframe()` instead.
ℹ When switching from `summarise()` to `reframe()`, remember that `reframe()`
always returns an ungrouped data frame and adjust accordingly.
📝 Calcula cuántos personajes hay de cada especie, ordenados de más a menor frecuencia.
Code
starwars |>count(species, sort =TRUE)
📝 Tras eliminar ausentes en las variables de peso y estatura, añade una nueva variable que nos calcule el IMC de cada personaje, y determina el IMC medio de nuestros personajes desagregada por sexo
Vamos a hacer un repaso de lo aprendido en {tidyverse} con la tabla billboard del paquete {tidyr}. El dataset representa algo parecido a Los 40 principales (pero versión americana y un top 100 en lugar de 40): para cada artista y canción se guarda la fecha en la que entró en el ranking, y la posición que ocupaba en el ranking en cada una de las semanas (wk1, wk2, …)
billboard
# A tibble: 317 × 8
artist track date.entered wk1 wk2 wk3 wk4 wk5
<chr> <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2 Pac Baby Don't Cry (Ke… 2000-02-26 87 82 72 77 87
2 2Ge+her The Hardest Part O… 2000-09-02 91 87 92 NA NA
3 3 Doors Down Kryptonite 2000-04-08 81 70 68 67 66
4 3 Doors Down Loser 2000-10-21 76 76 72 69 67
5 504 Boyz Wobble Wobble 2000-04-15 57 34 25 17 17
6 98^0 Give Me Just One N… 2000-08-19 51 39 34 26 26
7 A*Teens Dancing Queen 2000-07-08 97 97 96 95 100
8 Aaliyah I Don't Wanna 2000-01-29 84 62 51 41 38
9 Aaliyah Try Again 2000-03-18 59 53 38 28 21
10 Adams, Yolanda Open My Heart 2000-08-26 76 76 74 69 68
# ℹ 307 more rows
Intenta responder a las preguntas planteadas en el workbook
🐣 Caso práctico II: fútbol
Vamos a seguir practicando lo aprendido en {tidyverse} con el fichero futbol.csv, donde tenemos datos de los jugadores de las 5 principales ligas de futbol masculinas, desde 2005 hasta 2019, recopilando diferentes estadísticas. Los datos se han extraído directamente haciendo uso del paquete {worldfootballR}, que nos permite extraer datos de https://www.fbref.com
datos <-read_csv(file ="./datos/futbol.csv")datos
# A tibble: 40,393 × 16
season team league player country position date_birth minutes_playing
<dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 2005 Ajaccio Ligue 1 Djamel Ab… ALG MF 1986 30
2 2005 Ajaccio Ligue 1 Gaspar Az… POR DF 1975 1224
3 2005 Ajaccio Ligue 1 Yacine Be… ALG MF 1981 140
4 2005 Ajaccio Ligue 1 Nicolas B… FRA MF 1976 892
5 2005 Ajaccio Ligue 1 Marcelinh… BRA MF 1971 704
6 2005 Ajaccio Ligue 1 Cyril Cha… FRA FW 1979 1308
7 2005 Ajaccio Ligue 1 Xavier Co… FRA DF 1974 2734
8 2005 Ajaccio Ligue 1 Renaud Co… FRA MF 1980 896
9 2005 Ajaccio Ligue 1 Yohan Dem… FRA DF,MF 1978 2658
10 2005 Ajaccio Ligue 1 Christoph… FRA DF 1973 74
# ℹ 40,383 more rows
# ℹ 8 more variables: minutes_per_match_playing <dbl>, goals <dbl>,
# assist <dbl>, goals_minus_pk <dbl>, pk <dbl>, pk_attemp <dbl>,
# yellow_card <dbl>, red_card <dbl>
🐣 Caso práctico II: fútbol
Las variables capturan la siguiente información:
season, team, league: temporada, equipo y liga
player, country, position, date_birth: nombre del jugador, país, posición y año de nacimiento.
minutes_playing, matches: minutos totales jugados y partidos jugados en media (es decir, cuantos partidos de 90 minutos ha jugado con los minutos jugados).
goals, assist: goles y asistencias totales
pk, pk_attemp, goals_minus_pk: penalties marcados, penalties tirados y goles marcados sin contar los penalties.
yellow_card, red_card: tarjetas amarillas/rojas.
🐣 Caso práctico II: fútbol
datos
# A tibble: 40,393 × 16
season team league player country position date_birth minutes_playing
<dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 2005 Ajaccio Ligue 1 Djamel Ab… ALG MF 1986 30
2 2005 Ajaccio Ligue 1 Gaspar Az… POR DF 1975 1224
3 2005 Ajaccio Ligue 1 Yacine Be… ALG MF 1981 140
4 2005 Ajaccio Ligue 1 Nicolas B… FRA MF 1976 892
5 2005 Ajaccio Ligue 1 Marcelinh… BRA MF 1971 704
6 2005 Ajaccio Ligue 1 Cyril Cha… FRA FW 1979 1308
7 2005 Ajaccio Ligue 1 Xavier Co… FRA DF 1974 2734
8 2005 Ajaccio Ligue 1 Renaud Co… FRA MF 1980 896
9 2005 Ajaccio Ligue 1 Yohan Dem… FRA DF,MF 1978 2658
10 2005 Ajaccio Ligue 1 Christoph… FRA DF 1973 74
# ℹ 40,383 more rows
# ℹ 8 more variables: minutes_per_match_playing <dbl>, goals <dbl>,
# assist <dbl>, goals_minus_pk <dbl>, pk <dbl>, pk_attemp <dbl>,
# yellow_card <dbl>, red_card <dbl>
Intenta responder a las preguntas planteadas en el workbook
🐣 Caso práctico III: discursos
Vamos a hacer un ejercicio con textos. En el workbook tienes no solo un caso práctico sino un mini tutorial de cómo trabajar con textos en R haciendo uso del paquete {stringr}. En concreto vamos a analizar los discursos de Navidad de los jefes de Estado españoles
load(file ="./datos/discursos.RData")
Intenta responder a las preguntas planteadas en el workbook
🐣 Caso práctico IV: covid
Vamos a volver al dataset de covid de la entrega II pero esta vez desde una perspectiva tidyverse
Al trabajar con datos no siempre tendremos la información en una sola tabla y a veces nos interesará cruzar la información de distintas fuentes.
Para ello usaremos un clásico de todo lenguaje que maneja datos: los famosos join, que nos permitirán cruzar una o varias tablas, haciendo uso de una columna identificadora de cada una de ellas (por ejemplo, imagina que cruzamos datos de hacienda y de antecedentes penales, haciendo join por la columna DNI).
Relacionando datos
La estructura básica es la siguiente:
tabla_1 |>xxx_join(tabla_2, by = id)
Vamos a probar los distintos joins con un ejemplo sencillo
left_join(): mantiene todos los registros de la primera tabla, y busca cuales tienen id también en la segunda (en caso de no tenerlo se rellena con NA los campos de la 2ª tabla).
En nuestra caso queremos incorporar a tb_1 la información de tb_2, identificando los registros por la columna key (by = "key", la columna por la que tiene que cruzar)
Además podemos cruzar por varias columnas a la vez (interpretará como igual registro aquel que tenga el conjunto de claves igual), con by = c("var1_t1" = "var1_t2", "var2_t1" = "var2_t2", ...). Modifiquemos el ejemplo anterior
full_join(): mantiene todos los registros de ambas tablas.
Los dos anteriores casos forman lo que se conoce como outer joins: cruces donde se mantienen observaciones que salgan en al menos una tabla. El tercer outer join es el conocido como full_join() que nos mantendrá las observaciones de ambas tablas, añadiendo las filas que no casen con la otra tabla.
inner_join(): solo sobreviven los registros cuyo id esté en ambas tablas.
Frente a los outer join está lo que se conoce como inner join, con inner_join(): un cruce en el que solo se mantienen las observaciones que salgan en ambas tablas, solo mantiene aquellos registros matcheados.
Fíjate que en términos de registros, inner_join si es conmutativa, nos da igual el orden de las tablas: lo único que cambia es el orden de las columnas que añade.
Por último tenemos dos herramientas interesantes para filtrar (no cruzar) registros: semi_join() y anti_join(). El semi join nos deja en la primera tabla los registros que cuya clave está también en la segunda (como un inner join pero sin añadir la info de la segunda tabla). Y el segundo, los anti join, hace justo lo contrario (aquellos que no están).
# semijointb_1 |>semi_join(tb_2, by =c("key_1"="key_2"))
# A tibble: 2 × 2
key_1 val
<int> <chr>
1 1 x1
2 2 x2
# antijointb_1 |>anti_join(tb_2, by =c("key_1"="key_2"))
# A tibble: 1 × 2
key_1 val
<int> <chr>
1 3 x3
💻 Tu turno
Intenta realizar los siguientes ejercicios sin mirar las soluciones
Para los ejercicios usaremos las tablas disponibles en el paquete {nycflights13} (echa un vistazo antes)
library(nycflights13)
airlines: nombre de aerolíneas (con su abreviatura).
airports: datos de aeropuertos (nombres, longitud, latitud, altitud, etc).
flights: datos de vuelos.
planes: datos de los aviones.
weather: datos meteorológicos horarios de las estaciones LGA, JFK y EWR.
💻 Tu turno
Intenta realizar los siguientes ejercicios sin mirar las soluciones
📝 Del paquete {nycflights13} cruza la tabla flights con airlines. Queremos mantener todos los registros de vuelos, añadiendo la información de las aerolíneas a la tabla de aviones.
Code
flights_airlines <- flights |>left_join(airlines, by ="carrier")flights_airlines
📝 A la tabla obtenida del cruce del apartado anterior, cruza después con los datos de los aviones en planes, pero incluyendo solo aquellos vuelos de los que tengamos información de sus aviones (y viceversa).
Code
flights_airlines_planes <- flights_airlines |>inner_join(planes, by ="tailnum")flights_airlines_planes
📝 Repite el ejercicio anterior pero conservando ambas variables year (en una es el año del vuelo, en la otra es el año de construcción del avión), y distinguiéndolas entre sí
Code
flights_airlines_planes <- flights_airlines |>inner_join(planes, by ="tailnum",suffix =c("_flight", "_build_aircraft"))flights_airlines_planes
📝 Al cruce obtenido del ejercicio anterior incluye la longitud y latitud de los aeropuertos en airports, distinguiendo entre la latitud/longitud del aeropuerto en destino y en origen.
Code
flights_airlines_planes %>%left_join(airports %>%select(faa, lat, lon),by =c("origin"="faa")) |>rename(lat_origin = lat, lon_origin = lon) |>left_join(airports %>%select(faa, lat, lon),by =c("dest"="faa")) |>rename(lat_dest = lat, lon_dest = lon)
📝 Filtra de airports solo aquellos aeropuertos de los que salgan vuelos. Repite el proceso filtrado solo aquellos a los que lleguen vuelos
Code
airports |>semi_join(flights, by =c("faa"="origin"))airports |>semi_join(flights, by =c("faa"="dest"))
📝 ¿De cuántos vuelos no disponemos información del avión? Elimina antes los vuelos que no tengan identificar (diferente a NA) del avión
Code
flights |>drop_na(tailnum) |>anti_join(planes, by ="tailnum") |>count(tailnum, sort =TRUE) # de mayor a menor ya de paso
🐣 Caso práctico I: Beatles
Vamos a empezar a practicar joins sencillos con la tabla band_members y band_instruments ya incluidos en el paquete {dplyr}.
library(dplyr)band_members
# A tibble: 3 × 2
name band
<chr> <chr>
1 Mick Stones
2 John Beatles
3 Paul Beatles
band_instruments
# A tibble: 3 × 2
name plays
<chr> <chr>
1 John guitar
2 Paul bass
3 Keith guitar
Intenta responder a las preguntas planteadas en el workbook
🐣 Caso práctico II: renta municipios
En el archivo municipios.csv tenemos guardada la información de los municipios de España a fecha de 2019.
Por otro lado el archivo renta_mun contiene datos de la renta per capita edmai de cada unidad administrativa (municipios, distritos, provincias, comunidades autonónomas, etc) para diferentes años.
Intenta responder a las preguntas planteadas en el workbook
Importar/exportar
Hasta ahora sólo hemos utilizado datos ya cargados en paquetes, pero muchas veces necesitaremos importar datos externamente. Una de las principales fortalezas de R es que podemos importar datos muy fácilmente en diferentes formatos:
Formatos nativos de R: archivos .rda, .RData y .rds
Rectangular data (datos tabulados): archivos .csv y .tsv
Datos sin tabular: archivos .txt.
Datos en excel: archivos .xls y.xlsx.
Datos desde SAS/Stata/SPSS: archivos .sas7bdat, .sav y .dat.
Datos desde Google Drive
Datos desde API’s: aemet, catastro, censo, spotify, etc.
Formatos nativos
Los ficheros más sencillos para importar a R (y que suelen ocupar menos espacio en disco) son sus propias extensiones nativas: ficheros en formatos .RData, .rda y .rds. Para cargar los primeros basta con utilizar la funciónload() proporcionándole la ruta del fichero.
Archivos RData: vamos a importar el archivo world_bank_pop.RData que incluye la tabla world_bank_pop
Tenga en cuenta que los archivos cargados con load() se cargan automáticamente en el entorno (con el nombre guardado originalmente), y no sólo se pueden cargar conjuntos de datos: load() nos permite cargar múltiples objetos (no sólo datos tabulares).
Los archivos nativos .rda y .RData son una forma adecuada de guardar el entorno.
load(file ="./datos/multiple_objects.rda")
Formatos nativos
Archivos .rds: para este tipo debemos utilizar readRDS(), y necesitamos incorporar un argumento file con la ruta. En este caso vamos a importar datos de cáncer de pulmón del North Central Cancer Treatment Group. Observe que ahora los archivos .rds incorporar solo una tabla, no un objeto en general
Las [rutas]{.hl-yellow deben ser siempre sin espacios, ñ, ni acentos.
Datos tabulados: readr
El paquete {readr} dentro del entorno {tidyverse} contiene varias funciones útiles para cargar datos rectangulares (sin formatear pero tabulados).
read_csv(): archivos .csvvariables separadas por comas
read_csv2(): variables separadas por punto y coma
read_tsv(): variables separadas por tabuladores.
read_table(): variables separadas por espacios.
read_delim(): función generar con opción de especificar el delimitador.
Todos ellos necesitan como argumento la ruta del fichero más otros opcionales (saltar cabecera o no, decimales, etc). Ver más en https://readr.tidyverse.org/
Datos tabulados (.csv, .tsv)
La principal ventaja de {readr} es que automatiza el formato para pasar de un fichero plano (sin formato) a un tibble (en filas y columnas, con formato).
Archivo .csv: con read_csv() cargaremos archivos separados por comas, pasando como argumento la ruta en file = .... Vamos a importar el conjunto de datos chickens.csv (sobre pollos de dibujos animados, por qué no). Si nos fijamos en la salida nos da el tipo de variables.
# A tibble: 5 × 4
chicken sex eggs_laid motto
<chr> <chr> <dbl> <chr>
1 Foghorn Leghorn rooster 0 That's a joke, ah say, that's a jok…
2 Chicken Little hen 3 The sky is falling!
3 Ginger hen 12 Listen. We'll either die free chick…
4 Camilla the Chicken hen 7 Bawk, buck, ba-gawk.
5 Ernie The Giant Chicken rooster 0 Put Captain Solo in the cargo hold.
Datos tabulados (.csv, .tsv)
El formato de la variable se hará normalmente automáticamente por read_csv(), y podemos consultarlo con spec().
Aunque normalmente lo hace bien automáticamente podemos especificar el formato explícitamente en col_types = lista() (en formato lista, con col_xxx() para cada tipo de variable, por ejemplo eggs_laid se importará como carácter).
# A tibble: 5 × 4
chicken sex eggs_laid motto
<chr> <chr> <chr> <chr>
1 Foghorn Leghorn rooster 0 That's a joke, ah say, that's a jok…
2 Chicken Little hen 3 The sky is falling!
3 Ginger hen 12 Listen. We'll either die free chick…
4 Camilla the Chicken hen 7 Bawk, buck, ba-gawk.
5 Ernie The Giant Chicken rooster 0 Put Captain Solo in the cargo hold.
Datos tabulados (.csv, .tsv)
Incluso podemos indicar que variables queremos seleccionar (sin ocupar memoria), indicándolo en col_select = ... (en formato lista, con col_select = ...).
# A tibble: 5 × 3
chicken sex eggs_laid
<chr> <chr> <dbl>
1 Foghorn Leghorn rooster 0
2 Chicken Little hen 3
3 Ginger hen 12
4 Camilla the Chicken hen 7
5 Ernie The Giant Chicken rooster 0
Datos tabulados (.txt)
¿Qué ocurre cuando el separador no es correcto?
Si usamos read_csv() espera que el separador entre columnas sea una coma pero, como puedes ver con el siguiente .txt, lo interpreta todo como una sola columna: no tiene coma y no sabe dónde separar
# A tibble: 18 × 6
`Lots of people` ...2 ...3 ...4 ...5 ...6
<chr> <chr> <chr> <chr> <chr> <chr>
1 simply cannot resist writing <NA> <NA> <NA> <NA> some…
2 at the top <NA> of thei…
3 or merging <NA> <NA> <NA> cells
4 Name Profession Age Has … Date… Date…
5 David Bowie musician 69 TRUE 17175 42379
6 Carrie Fisher actor 60 TRUE 20749 42731
7 Chuck Berry musician 90 TRUE 9788 42812
8 Bill Paxton actor 61 TRUE 20226 42791
9 Prince musician 57 TRUE 21343 42481
10 Alan Rickman actor 69 FALSE 16854 42383
11 Florence Henderson actor 82 TRUE 12464 42698
12 Harper Lee author 89 FALSE 9615 42419
13 Zsa Zsa Gábor actor 99 TRUE 6247 42722
14 George Michael musician 53 FALSE 23187 42729
15 Some <NA> <NA> <NA> <NA> <NA>
16 <NA> also like to write stuff <NA> <NA> <NA> <NA>
17 <NA> <NA> at t… bott… <NA> <NA>
18 <NA> <NA> <NA> <NA> <NA> too!
Datos Excel (.xls, .xlsx)
deaths |>slice(1:6)
# A tibble: 6 × 6
`Lots of people` ...2 ...3 ...4 ...5 ...6
<chr> <chr> <chr> <chr> <chr> <chr>
1 simply cannot resist writing <NA> <NA> <NA> <NA> some not…
2 at the top <NA> of their sp…
3 or merging <NA> <NA> <NA> cells
4 Name Profession Age Has kids Date of birth Date of …
5 David Bowie musician 69 TRUE 17175 42379
6 Carrie Fisher actor 60 TRUE 20749 42731
Una desgracia muy común es que haya algún tipo de comentario o texto al principio del fichero, teniendo que saltar esas filas.
Datos Excel (.xls, .xlsx)
Podemos saltar estas filas directamente en la carga con skip = ... (indicando el número de filas a saltar).
# A tibble: 14 × 6
nombre profesion edad hijos nacimiento muerte
<chr> <chr> <chr> <chr> <dttm> <date>
1 David Bowie musician 69 TRUE 1947-01-08 00:00:00 2016-01-10
2 Carrie Fisher actor 60 TRUE 1956-10-21 00:00:00 2016-12-27
3 Chuck Berry musician 90 TRUE 1926-10-18 00:00:00 2017-03-18
4 Bill Paxton actor 61 TRUE 1955-05-17 00:00:00 2017-02-25
5 Prince musician 57 TRUE 1958-06-07 00:00:00 2016-04-21
6 Alan Rickman actor 69 FALSE 1946-02-21 00:00:00 2016-01-14
7 Florence Henderson actor 82 TRUE 1934-02-14 00:00:00 2016-11-24
8 Harper Lee author 89 FALSE 1926-04-28 00:00:00 2016-02-19
9 Zsa Zsa Gábor actor 99 TRUE 1917-02-06 00:00:00 2016-12-18
10 George Michael musician 53 FALSE 1963-06-25 00:00:00 2016-12-25
11 Some <NA> <NA> <NA> NA NA
12 <NA> also like to w… <NA> <NA> NA NA
13 <NA> <NA> at t… bott… NA NA
14 <NA> <NA> <NA> <NA> NA NA
Datos Excel (.xls, .xlsx)
También podemos cargar un Excel con varias hojas: para indicar la hoja (ya sea por su nombre o por su número) utilizaremos el argumento sheet = ....
De la misma forma que podemos importar también podemos exportar
exportar en .RData (opción recomendada para variables almacenadas en R). Recuerda que esta extensión sólo se puede utilizar en R. Para ello, basta con utilizar save(object, file = path).
# A tibble: 4 × 2
a b
<int> <int>
1 1 1
2 2 2
3 3 3
4 4 4
Exportar
exportado en .csv. Para ello simplemente utilizamos write_csv(object, file = path), y es el más recomendable para exportar bases de datos de tamaño pequeño o mediano. Ver https://arrow.apache.org/docs/r/ para bases de datos masivas.
# A tibble: 4 × 2
a b
<dbl> <dbl>
1 1 1
2 2 2
3 3 3
4 4 4
Importar desde web
Una de las principales ventajas de R es que podemos hacer uso de todas las funciones anteriores de importar pero directamente desde una web, sin necesidad de realizar la descarga manual: en lugar de pasarle la ruta local le indicaremos el enlace. Por ejemplo, vamos a descargar los datos covid del ISCIII (https://cnecovid.isciii.es/covid19/#documentaci%C3%B3n-y-datos)
# A tibble: 500 × 8
provincia_iso sexo grupo_edad fecha num_casos num_hosp num_uci num_def
<chr> <chr> <chr> <date> <dbl> <dbl> <dbl> <dbl>
1 A H 0-9 2020-01-01 0 0 0 0
2 A H 10-19 2020-01-01 0 0 0 0
3 A H 20-29 2020-01-01 0 0 0 0
4 A H 30-39 2020-01-01 0 0 0 0
5 A H 40-49 2020-01-01 0 0 0 0
6 A H 50-59 2020-01-01 0 0 0 0
7 A H 60-69 2020-01-01 0 0 0 0
8 A H 70-79 2020-01-01 0 0 0 0
9 A H 80+ 2020-01-01 0 0 0 0
10 A H NC 2020-01-01 0 0 0 0
# ℹ 490 more rows
Importar desde wikipedia
El paquete {rvest}, uno de los más útiles de {tidyverse} nos permite importar (scrappear) directamente desde un html. Por ejemplo, para exportar tablas de wikipedia basta con read_html() para importar el html, html_element(«table») para extraer los objetos tabla, y html_table() para convertir la tabla html a tibble.
# A tibble: 19 × 5
Mark Wind Athlete Place Date
<chr> <chr> <chr> <chr> <chr>
1 7.61 m (24 ft 11+1⁄2 in) "" Peter O'Connor (IRE) Dublin, Ire… 5 Au…
2 7.69 m (25 ft 2+3⁄4 in) "" Edward Gourdin (USA) Cambridge, … 23 J…
3 7.76 m (25 ft 5+1⁄2 in) "" Robert LeGendre (USA) Paris, Fran… 7 Ju…
4 7.89 m (25 ft 10+1⁄2 in) "" DeHart Hubbard (USA) Chicago, Un… 13 J…
5 7.90 m (25 ft 11 in) "" Edward Hamm (USA) Cambridge, … 7 Ju…
6 7.93 m (26 ft 0 in) "0.0" Sylvio Cator (HAI) Paris, Fran… 9 Se…
7 7.98 m (26 ft 2 in) "0.5" Chuhei Nambu (JPN) Tokyo, Japan 27 O…
8 8.13 m (26 ft 8 in) "1.5" Jesse Owens (USA) Ann Arbor, … 25 M…
9 8.21 m (26 ft 11 in) "0.0" Ralph Boston (USA) Walnut, Uni… 12 A…
10 8.24 m (27 ft 1⁄4 in) "1.8" Ralph Boston (USA) Modesto, Un… 27 M…
11 8.28 m (27 ft 1+3⁄4 in) "1.2" Ralph Boston (USA) Moscow, Sov… 16 J…
12 8.31 m (27 ft 3 in) A "−0.1" Igor Ter-Ovanesyan (URS) Yerevan, So… 10 J…
13 8.33 m (27 ft 3+3⁄4 in)[2] "" Phil Shinnick (USA) Modesto, Un… 25 M…
14 8.31 m (27 ft 3 in) "0.0" Ralph Boston (USA) Kingston, J… 15 A…
15 8.34 m (27 ft 4+1⁄4 in) "1.0" Ralph Boston (USA) Los Angeles… 12 S…
16 8.35 m (27 ft 4+1⁄2 in)[5] "0.0" Ralph Boston (USA) Modesto, Un… 29 M…
17 8.35 m (27 ft 4+1⁄2 in) A "0.0" Igor Ter-Ovanesyan (URS) Mexico City… 19 O…
18 8.90 m (29 ft 2+1⁄4 in) A "2.0" Bob Beamon (USA) Mexico City… 18 O…
19 8.95 m (29 ft 4+1⁄4 in) "0.3" Mike Powell (USA) Tokyo, Japan 30 A…
Importar desde google drive
Otra opción disponible (especialmente si trabajamos con otras personas trabajando) es importar desde una hoja de cálculo de Google Drive, haciendo uso de read_sheet() del paquete {googlesheets4}.
La primera vez se te pedirá un permiso tidyverse para interactuar con tu drive
# A tibble: 3 × 4
a b c d
<chr> <dbl> <dbl> <chr>
1 d1 0.5 1 hombre
2 d2 -0.3 2 hombre
3 d3 1.1 3 mujer
Importar desde API (owid)
Otra opción interesante es la descarga de datos desde una API: un intermediario entre una app o proveedor de datos y nuestro R. Por ejemplo, carguemos la librería {owidR}, que nos permite descargar datos de la web https://ourworldindata.org/. Por ejemplo, la función owid_covid() carga sin darnos cuenta más de 400 000 registros con más de 60 variables de 238 países.
En muchas ocasiones para conectarnos a la API primero tendremos que registrarnos y obtener una clave, este es el caso del paquete {climaemet} para acceder a datos meteorológicos de España (https://opendata.aemet.es/centrodedescargas/inicio).
Una vez tengamos la clave API la registramos en nuestro RStudio para poder utilizarla en el futuro.
library(climaemet)# Api keyapikey <-"eyJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJqYXZhbHYwOUB1Y20uZXMiLCJqdGkiOiI4YTU1ODUxMS01MTE3LTQ4MTYtYmM4OS1hYmVkNDhiODBkYzkiLCJpc3MiOiJBRU1FVCIsImlhdCI6MTY2NjQ2OTcxNSwidXNlcklkIjoiOGE1NTg1MTEtNTExNy00ODE2LWJjODktYWJlZDQ4YjgwZGM5Iiwicm9sZSI6IiJ9.HEMR77lZy2ASjmOxJa8ppx2J8Za1IViurMX3p1reVBU"aemet_api_key(apikey, install =TRUE)
Importar desde API (aemet)
Con este paquete podemos hacer una búsqueda de estaciones para conocer tanto su código postal como su código identificador dentro de la red AEMET
stations <-aemet_stations()stations
Importar desde API (aemet)
Por ejemplo, para obtener datos de la estación del aeropuerto de El Prat, Barcelona, el código a proporcionar es «0076», obteniendo datos horarios.
aemet_last_obs("0076")
Importar desde API (US census)
Una de las herramientas más útiles de los últimos años es la conocida como {tidycensus}: una herramienta para facilitar el proceso de descarga de datos censales de Estados Unidos desde R
library(tidycensus)
get_decennial(): para acceder a los datos de censos (US Decennial Census), se hacen cada 10 años (años 2000, 2010 y 2020).
get_acs(): para acceder a los datos anuales y quinquenales (5 años) de la ACS (American Community Survey) (censo != encuesta)
get_estimates(): para acceder a las estimaciones anuales de población, natalidad y mortalidad
get_pums(): para acceder a los microdatos (datos sin agregar) de la ACS (anonimizados a nivel individual)
get_flows(): para acceder a los datos de flujo de migraciones
Importar desde API (US census)
Por ejemplo vamos a descargarnos los datos censales (get_decennial()) a nivel estado (geography = "state") de la población (variable variables = "P001001") para el año 2010 (ver variables en tidycensus::load_variables())
📝 El conjunto de datos who2 del paquete {tidyr} que hemos utilizado en ejercicios anteriores, expórtalo a un formato nativo R en la carpeta datos de tu proyecto de RStudio
La aparición de gráficos estadísticos es relativamente reciente en la ciencia ya que hasta la Edad Media la única visualización estaba en los mapas. 1 Las propias palabras chart y cartography derivan del mismo origen latino, charta, aunque el primer uso de coordenadas viene de los egipcios. 23
No es hasta la Edad Media, cuando la navegación y la astronomía empezaban a tomar relevancia, cuando aparece la primera gráfica (no propiamente estadística), del movimiento cíclico de los planetas (siglos X y XI)
Primer gráfico estadístico
La mayoría de expertos, como Tufte 12, consideran este gráfico casi longitudinal como la primera visualización de datos de la historia, hecha por Van Langren en 1644, representando la distancia entre Toledo y Roma.
¿Qué es una dataviz?
¿Es una gráfica estadística? ¿Por qué sí o por qué no?
No hay ninguna INFORMACIÓN representada
¿Qué es una dataviz?
¿Es una gráfica estadística? ¿Por qué sí o por qué no?
No hay ningún PROCESO DE MEDIDA representado, no cuantifica nada (real).
¿Qué es una dataviz?
¿Es una gráfica estadística? ¿Por qué sí o por qué no?
No hay ningún DATO representado en él, es una magnitud física teórica, no un dato (medido empíricamente o simulado).
¿Qué es una dataviz?
Esas mismas preguntas se hizo Joaquín Sevilla1, proporcionando 3 requisitos:
Que se base en el esquema de composición de eje métrico (proceso de medida): debe medir algo.
Debe incluir información estadística (datos)
La relación de representatividad debe ser reversible: los datos deberían poder «recuperarse» a partir de la gráfica .
Vizfails
La figura elegida (persona caminando) sin relación con lo visualizado: mala metáfora.
Los sectores señalados sin relación con el ítem a representar, lo que dificulta su interpretación.
Los colores sin codificar: no dan información de ningún tipo.
Las formas irregulares impiden la comparación de las áreas (amén de que la suma total supera el 100%).
Sin fuente
Vizfails
Vizfails
La importancia del CONTEXTO
Una buena idea puede estar mal ejecutada: la forma de llevarla a cabo es importante
Dataviz: historia
En el siglo XVII hubo un boom de la estadística al empezar a aplicarse en demografía. Uno de los autores más importantes fue J. Graunt, autor de «Natural and Political Observations Made upon the Bills of Mortality» (1662), estimando la población de Londres con las primeras tablas de natalidad y mortalidad.
Son precisamente las tablas de Graunt las que usó Christiaan Huygens para generar la primera gráfica de densidad de una distribución continua (esperanza de vida vs edad).
Primera función de densidad, extraída de https://omeka.lehigh.edu/exhibits/show/data_visualization/vital_statistics/huygen
Gráficos de Playfair
La figura que cambió el dataviz fue, sin lugar a dudas, el economista y político William Playfair (1759-1823), publicando en 1786 el «Atlas político y comercial»1 [^12] con 44 gráficas (43 series temporales y el diagrama de barras más famoso de la historia).
Extraídas de Funkhouser y Walker (1935)
Extraídas de Funkhouser y Walker (1935)
Gráficos de Playfair
Playfair es además el autor del gráfico de barras más famoso (no fue el primero pero sí quien lo hizo mainstream).
Gráficas de Playfair de importaciones (barras grises) y exportaciones (negras) de Escocia en 1781, extraídas de la wikipedia.
Primer diagrama de barras (P. Buache y G. de L’Isle), visualizando los niveles del Sena (1732 - 1766), extraída de https://friendly.github.io/HistDataVis
Mapas de Minard
Otro pionero en combinar visualizaciones fue Minard, autor del famoso «Carte figurative des pertes successives en hommes de l’Armée Française dans la campagne de Russie 1812-1813», según Tufte «el mejor gráfico estadístico jamás dibujado», publicado en 1869 sobre la desastrosa campaña rusa de Napoleón en 1812 (3 variables en un gráfico bidimensional)
Extraída de https://friendly.github.io/HistDataVis.
Primer scatter plot
Según J. Sevilla, se considera al astrónomo británico John Frederick William Herschel el autor del primer diagrama de dispersión o scatterplot en 1833, visualizando el movimiento de la estrella doble Virginis (tiempo en el eje horizontal, posición angular en el eje vertical)
Extraído de https://friendly.github.io/HistDataVis.
Florence Nigthingale
El 21 de octubre de 1854 Florence Nigthingale fue enviada para mejorar las condiciones sanitarias de los soldados británicos en la guerra de Crimea.
A su regreso demostró que los soldados fallecían por las condiciones sanitarias. Nigthingale es la creadora del famoso diagrama de rosa, visualizando tres variables a la vez y su estacionalidad.
El 8 de febrero de 1955, The Times la describió como la «ángel guardián» de los hospitales, y acabó siendo conocida como «The Lady with the Lamp» tras un poema de H. W. Longfellow (1857).
Años después se convirtió en la primera mujer en la Royal Statistical Society.
Diagrama de rosa
Florence Nigthingale es la creadora del famoso diagrama de rosa, permitiendo pintar tres variables a la vez y su estacionalidad: tiempo (cada gajo es un mes), nº de muertes (área del gajo) y causa de la muerte (color del gajo: azules enfermedades infecciosas, rojas por heridas, negras otras causas).
El paquete {ggplot2} se basa en la idea de Wilkinson en «Grammar of graphics»: dotar a los gráficos de una gramática propia. Una de las principales fortalezas de R es la visualización con {ggplot2}.
library(ggplot2)
La visualización de datos debería ser una parte fundamental de todo análisis de datos. No es solo una cuestión estética.
Dataviz en R: ggplot2
La filosofía detrás de {ggplot2} es entender los gráficos como parte del flujo de trabajo, dotándoles de una gramática. El objetivo es empezar con un lienzo en blanco e ir añadiendo capas a tu gráfico. La ventaja de {ggplot2} es poder mapear atributos estéticos (color, forma, tamaño) de objetos geométricos (puntos, barras, líneas) en función de los datos.
Mapeado (aesthetics) de elementos estéticos: ejes, color, forma, etc (en función de los datos)
Geometría (geom): puntos, líneas, barras, polígonos, etc.
Componer gráficas (facet)
Transformaciones (stat): ordenar, resumir, etc.
Coordenadas (coord): coordenadas cartesianas, polares, grids, etc.
Temas (theme): fuente, tamaño de letra, subtítulos, captions, leyenda, ejes, etc.
Primer intento: scatter plot
Veamos un primer intento para entender la filosofía ggplot. Imagina que queremos dibujar un scatter plot (diagrama de dispersión de puntos). Para ello vamos a usar el conjunto de datos gapminder, del paquete homónimo: un fichero con datos de esperanzas de vida, poblaciones y renta per cápita de distintos países en distintos momentos temporales.
library(gapminder)gapminder
# A tibble: 1,704 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
7 Afghanistan Asia 1982 39.9 12881816 978.
8 Afghanistan Asia 1987 40.8 13867957 852.
9 Afghanistan Asia 1992 41.7 16317921 649.
10 Afghanistan Asia 1997 41.8 22227415 635.
# ℹ 1,694 more rows
Primer intento: scatter plot
El fichero consta de 1704 registros y 6 variables: country, continent, year, lifeExp (esperanza de vida), pop (población) y gdpPercap (renta per cápita).
Los colores también podemos asignárselos por su código hexadecimal, consultando en https://htmlcolorcodes.com/es/, eligiendo el color que queramos. El código hexadecimal siempre comenzará con #
# Color en hexadecimal# https://htmlcolorcodes.com/es/ggplot(gapminder_2007,aes(y = gdpPercap, x = lifeExp)) +geom_point(color ="#A02B85",alpha =0.4, size =7)
Mapeado estético: aes()
Hasta ahora los atributos estéticos se los hemos pasado fijos y constantes. Pero la verdadera potencia y versatilidad de ggplot es que podemos mapear los atributos estéticos en función de los datos en aes() para que dependan de variables de los datos.
Por ejemplo, vamos a asignar un color a cada dato en función de su continente con aes(color = continent)
# Tamaño fijo# Color por continentesggplot(gapminder_2007,aes(y = gdpPercap, x = lifeExp,color = continent)) +geom_point(size =7)
Mapeado estético: aes()
Podemos combinarlo con lo que hemos hecho anteriormente:
A este scatter plot particular se le conoce BUBBLE CHART
Visualización multivariante
Reflexionemos sobre el gráfico anterior:
color en función del continente.
tamaño en función de la población
transparencia fija del 50%
Usando los datos hemos conseguido dibujar en un gráfico bidimensional 4 variables: lifeExp y gdpPercap en los ejes , continent como color y pop como tamaño de la geometría, con muy pocas líneas de código.
Etiquetas sencillas: labs()
Podemos personalizar de manera sencilla haciendo uso de la capa labs():
title, subtitle: título/subtítulo
caption: pie de gráfica
x, y: nombres de los ejes
size, color, fill, ...: nombre en la leyenda de las variables que codifiquen los distintos atributos
ggplot(gapminder_2007,aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(alpha =0.7) +labs(x ="Esperanza de vida", y ="Renta per cápita",title ="Primer ggplot", subtitle ="Datos de gapminder",caption ="J. Álvarez Liébana", color ="continente", size ="población")
Eliminar de la leyenda
Podemos eliminar variables de la leyenda con guides(atributo = "none")
ggplot(gapminder_2007,aes(y = gdpPercap, x = lifeExp,color = continent, size = pop)) +geom_point(alpha =0.7) +guides(size ="none") +labs(x ="Esperanza de vida",y ="Renta per cápita",title ="Primer ggplot",caption ="J. Álvarez Liébana",color ="continente")
Escalas (scale): colores
Una de las capas más importantes es la capa de escalas (personalizar) ya que dentro de aes() solo le indicamos qué variable mapeamos pero no sus ajustes.
Por ejemplo, con scale_color_...() y scale_fill_...() podremos personalizar qué colores usar.
pal <-c("#A02B85", "#2DE86B", "#4FB2CA", "#E8DA2D", "#E84C2D")ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent)) +geom_point(alpha =0.7) +scale_color_manual(values = pal) +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente")
Escalas (scale): colores
Otra opción es elegir alguna de las paletas de colores diseñadas en el paquete {ggthemes}:
scale_color_economist(): paleta de colores basada en los colores de The Economist.
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(alpha =0.7) + ggthemes::scale_color_economist() +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente")
Escalas (scale): colores
Otra opción es elegir alguna de las paletas de colores diseñadas en el paquete {ggthemes}:
scale_color_colorblind(): paleta de colores basada en los colores de daltónicos/as.
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(alpha =0.7) + ggthemes::scale_color_colorblind() +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente")
Escalas (scale): colores
Incluso cargar paletas de colores diseñadas en base a películas o arte
películas: paquete {harrypotter} (repositorio de Github aljrico/harrypotter) usando scale_color_hp_d().
Paleta basada en la casa Ravenclaw
devtools::install_github(repo ="aljrico/harrypotter") ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(alpha =0.7) + harrypotter::scale_color_hp_d(option ="ravenclaw")+labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente")
Escalas (scale): colores
Incluso cargar paletas de colores diseñadas en base a películas o arte
devtools::install_github(repo ="BlakeRMills/MetBrewer") library(MetBrewer)ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(alpha =0.7) +scale_color_manual(values =met.brewer("Monet")) +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente")
Escalas (scale): colores
Incluso cargar paletas de colores diseñadas en base a películas o arte
devtools::install_github(repo ="jbgb13/peRReo") library(peRReo)ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(alpha =0.7) +scale_color_manual(values =latin_palette("rosalia")) +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente")
Esclas (scale): colores
Incluso cargar paletas de colores diseñadas en base a películas o arte
discos: paquete {taylor} usando scale_color_taylor_d(album = ...) para usar paletas de álbumes de Taylor Swift.
library(taylor)ggplot(gapminder_2007,aes(y = gdpPercap, x = lifeExp,color = continent, size = pop)) +geom_point(alpha =0.7) +scale_color_taylor_d(album ="Speak Now") +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente")
Clase 17: ggplot1
scale: colores continuos
Ya vimos como definir paletas de colores pero si te fijas la variable que codifica el color era cualitativa o discreta, ¿y si la variable que codifica color fuese cuantitativa numérica?
Existen unas paletas de colores conocidas como ColorBrewer pudiendo definirse de manera secuencial, divergente o de manera cualitativa (ver info en https://colorbrewer2.org)
RColorBrewer::brewer.pal.info
maxcolors category colorblind
BrBG 11 div TRUE
PiYG 11 div TRUE
PRGn 11 div TRUE
PuOr 11 div TRUE
RdBu 11 div TRUE
RdGy 11 div FALSE
RdYlBu 11 div TRUE
RdYlGn 11 div FALSE
Spectral 11 div FALSE
Accent 8 qual FALSE
Dark2 8 qual TRUE
Paired 12 qual TRUE
Pastel1 9 qual FALSE
Pastel2 8 qual FALSE
Set1 9 qual FALSE
Set2 8 qual TRUE
Set3 12 qual FALSE
Blues 9 seq TRUE
BuGn 9 seq TRUE
BuPu 9 seq TRUE
GnBu 9 seq TRUE
Greens 9 seq TRUE
Greys 9 seq TRUE
Oranges 9 seq TRUE
OrRd 9 seq TRUE
PuBu 9 seq TRUE
PuBuGn 9 seq TRUE
PuRd 9 seq TRUE
Purples 9 seq TRUE
RdPu 9 seq TRUE
Reds 9 seq TRUE
YlGn 9 seq TRUE
YlGnBu 9 seq TRUE
YlOrBr 9 seq TRUE
YlOrRd 9 seq TRUE
scale: colores continuos
Con RColorBrewer::brewer.pal() podemos obtener el vector de n colores para una paleta dada, por ejemplo la paleta divergenteRdYlBu
Con RColorBrewer::display.brewer.pal() podemos visualizar los colores de dicha paleta
RColorBrewer::display.brewer.pal(n =10, name ="RdYlBu")
scale: colores continuos
Un ejemplo de paleta secuencial es PuBuGn
RColorBrewer::display.brewer.pal(n =8, name ="PuBuGn")
scale: colores continuos
Un ejemplo de paleta cualitativa es Pastel1
RColorBrewer::display.brewer.pal(n =8, name ="Pastel1")
scale: colores continuos
Para incluirlo podemos usar scale_color_brewer() o bien scale_color_distiller() si queremos crear una escala continua (interpolando entre los colores)
ggplot(gapminder_2007, aes(y = gdpPercap, x = pop, color = lifeExp)) +geom_point(alpha =0.7, size =3) +scale_color_distiller(palette ="RdYlBu") +guides(size ="none") +labs(x ="Población", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="esperanza de vida") +theme_minimal()
scale: gradiente de color
También podemos crear gradientes de color personalizados con scale_color_gradient(), scale_fill_gradient(), scale_color_gradient2(), scale_fill_gradient2()
Vamos a usar scale_color_gradient2(low = ..., mid = ..., high = ..., midpoint = ...) indicándole el color más bajo y el más alto, pero también el de en medio (y el valor numérico al que queremos asociarlo)
ggplot(gapminder_2007, aes(y = gdpPercap, x = pop, color = lifeExp)) +geom_point(alpha =0.7, size =3) +scale_color_gradient2(low ="#825598", mid ="#9dd0c1",high ="#d93535", midpoint =60) +guides(size ="none") +labs(x ="Población", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="esperanza de vida") +theme_minimal()
Escalas (scale): ejes
La misma idea que usamos para personalizar colores la podemos aplicar para, por ejemplo, personalizar los ejes
Vamos a personalizar las marcas del eje x con scale_x_continuous(breaks = ...) para tener marcas cada 10 unidades.
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent)) +geom_point(alpha =0.7) + ggthemes::scale_color_colorblind() +scale_x_continuous(breaks =seq(30, 90, by =10)) +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente")
Escalas (scale): ejes
Vamos a profundizar un poco dentro de nuestro scatter plot en escalas
¿Cómo fijar límites en los ejes? En scale_x_continuous() y scale_y_continuous(), además de “saltos” podemos indicar límites con limits = ...
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(alpha =0.7) +scale_x_continuous(limits =c(50, 70), breaks =seq(50, 70, by =5)) +scale_y_continuous(limits =c(1000, 18000), breaks =seq(0, 18000, by =1000)) + ggthemes::scale_color_colorblind() +guides(size ="none") +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
Escalas (scale): ejes
¿Cómo etiquetar las unidades de los ejes? Haciendo uso del paquete {scales} podemos añadir prefijos/sufijos con labels = label_number(...)
library(scales)ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(alpha =0.7) +scale_x_continuous(limits =c(50, 70), breaks =seq(50, 70, by =5),labels =label_number(suffix =" años")) +scale_y_continuous(limits =c(1000, 18000), breaks =seq(0, 18000, by =1000),labels =label_number(suffix =" $")) + ggthemes::scale_color_colorblind() +guides(size ="none") +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
Escalas (scale): otros
Vamos a profundizar un poco dentro de nuestro scatter plot en escalas
¿Cómo cambiar los ajustes de tamaño, alpha, etc? Igual que tenemos scale_x_...() o scale_color_...(), tenemos también scale_size_...() y scale_alpha_...()
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(aes(alpha = pop)) +scale_size(range =c(4, 12)) +scale_alpha(range =c(0.1, 0.5)) + ggthemes::scale_color_colorblind() +guides(size ="none", alpha ="none") +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
Escalas (scale): ejes
Vamos a profundizar un poco dentro de nuestro scatter plot en escalas
¿Cómo cambiar la escala (relación) lineal entre los ejes? Con scale_x_sqrt() o scale_x_log10() podemos cambiar la escala de los ejes.
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(alpha =0.7) +scale_y_log10() + ggthemes::scale_color_colorblind() +guides(size ="none") +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
theme: capa de temas
En {ggplot2} vamos a poder personalizar todo el gráfico incluido definir nuestro propio tema estético haciendo uso de las capas theme_...()
Por ejemplo, vamos a usar theme_minimal() para tener un tema “austero” y minimalista (aprenderemos a definir cada detalle).
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(alpha =0.7) +scale_x_continuous(breaks =seq(35, 85, by =10)) + ggthemes::scale_color_colorblind() +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
coord: capa de coordenadas
Además de escalas tenemos una capa de coordenadas con coord_... para indicar si queremos un sistema cartesiano, coordenadas polares (coord_polar()), si queremos coordenadas iguales (coord_equal()) o invertir su rol (coord_flip())
ggplot(gapminder_2007, aes(y = gdpPercap, x = pop, color = lifeExp)) +geom_point(alpha =0.8, size =3) +scale_x_log10() +scale_color_gradient2(low ="#E92745", mid ="#F4ED5B", high ="#56B1F7", midpoint =60) +coord_flip() +labs(x ="Población", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="esperanza de vida") +theme_minimal()
stats: capa estadística
Una capa también importante es la capa de estadísticas
stat_smooth(): visualiza un ajuste suavizado de los datos (reg. lineal, glm, loess, gam, etc). Con stat_smooth(method = "lm") una recta de regresión. También con geom_smooth(method = "lm")
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp)) +geom_point(aes(color = continent, size = pop), alpha =0.8) +stat_smooth(method ="lm", se =FALSE, linewidth =1.5) +scale_y_log10() +guides(size ="none") + ggthemes::scale_color_colorblind() +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
stats: capa estadística
Fíjate que si usas en la primera capa parámetros estéticos se acaban heredando a capas posteriores, en concreto al ajuste visualizado.
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, color = continent, size = pop)) +geom_point(alpha =0.8) +stat_smooth(method ="lm", se =FALSE, linewidth =1.5) +scale_y_log10() +guides(size ="none") + ggthemes::scale_color_colorblind() +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
stats: capa estadística
Dentro de stat_smooth() podemos especificarle otro ajuste polinómico dándole expresión en formula = ..., por ejemplo un polinomio de grado 5formula = y ~ x + I(x^2) + I(x^3) + I(x^4) + I(x^5)
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp)) +geom_point(aes(color = continent, size = pop), alpha =0.8) +stat_smooth(method ="lm", formula = y ~ x +I(x^2) +I(x^3) +I(x^4) +I(x^5),color ="firebrick", se =FALSE, linewidth =1.2) +guides(size ="none") + ggthemes::scale_color_colorblind() +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
stats: capa estadística
Con stat_summary() podemos incluso añadir estadísticas por grupos, como la media o mediana.
ggplot(gapminder, aes(y = gdpPercap, x = year)) +geom_point(size =1.7, alpha =0.2) +stat_summary(fun ="mean", size =0.4, color ="coral") +stat_summary(fun ="median", size =0.4, color ="darkcyan") + ggthemes::scale_color_colorblind() +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
facet: composición
Por último la capa facet_(): podemos desagregar los gráficos (facetar) por grupos, equivalente al group_by() en tidyverse.
Por ejemplo, vamos a crear un gráfico por continente, mostrando todos los gráficos a la vez (pero por separado) con facet_wrap(~continent).
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, size = pop, color = continent)) +geom_point(alpha =0.75) + ggthemes::scale_color_colorblind() +facet_wrap(~continent) +guides(size ="none") +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
Componiendo (facet)
También podemos desagregar los gráficos (facetar) por grupos, equivalente al group_by() en tidyverse.
Por defecto las escalas en los ejes son compartidas. Si queremos que la escala de los ejes vaya por libre debemos usar scales = "free_x", scales = "free_y" o scales = "free"
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, size = pop, color = continent)) +geom_point(alpha =0.75) + ggthemes::scale_color_colorblind() +facet_wrap(~continent, scales ="free") +guides(size ="none") +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
Componiendo (facet)
También podemos desagregar los gráficos (facetar) por grupos, equivalente al group_by() en tidyverse.
Con nrow = ... y ncol = ... podemos especificar cuantas columnas y filas tenemos en la cuadrícula de gráficas
ggplot(gapminder_2007, aes(y = gdpPercap, x = lifeExp, size = pop, color = continent)) +geom_point(alpha =0.75) + ggthemes::scale_color_colorblind() +facet_wrap(~continent, scales ="free", nrow =3) +guides(size ="none") +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
Componiendo (facet)
También le podemos pasar dos argumentos (variables) para formar un grid de gráficas con facet_grid(var1 ~ var2)
ggplot(gapminder |>filter(year >=1962), aes(y = gdpPercap, x = lifeExp, size = pop, color = continent)) +geom_point(alpha =0.7) + ggthemes::scale_color_colorblind() +facet_grid(continent ~ year, scales ="free") +guides(size ="none") +labs(x ="Esperanza de vida", y ="Renta per cápita", title ="Primer ggplot",caption ="J. Álvarez Liébana", color ="continente") +theme_minimal()
Clase 18: ggplot2
Variables continuas
Hemos aprendido a realizar uno de los gráficos más famosos, un diagrama de dispersión, pero…¿qué propiedades deben cumplir las variables?
Para visualizar dos variables con un diagrama de dispersión es necesario que ambas sean variables numéricas continuas
¿Se te ocurre algúna gráfico básico para variables discretas?
Cualis: barras
¿Y si tengo variables discretas o cualitativas?
Vamos a usar el ya conocido conjunto starwars para visualizar en un diagrama de barras: vamos a representar la frecuencia de una variable cualitativa como es sex.
starwars |>count(sex)
# A tibble: 5 × 2
sex n
<chr> <int>
1 female 16
2 hermaphroditic 1
3 male 60
4 none 6
5 <NA> 4
Cualis: barras
La ventaja de ggplot es que, al trabajar por capas, todo lo que hemos aprendido nos sirve: solo tenemos que cambiar la geometría.
En este caso para realizar un diagrama de barras usaremos geom_bar() en lugar de geom_point(), indicando solo la variable de grupo con x = sex (ggplot hará solo el recuento)
Podemos aplicar lo aprendido sobre colores para codificar la información, en este caso vamos a usar las paletas ya cargadas en scale_color_colorblind() del paquete {ggthemes}
¿Podríamos visualizar dos variables discretas/cualis a la vez?
Podemos incluir una en x = ... y otra en fill = ..., de manera que por defecto nos visualiza barras apiladas, por ejemplo, para ver el reparto de sexos entre humanos y no humanos.
starwars |>drop_na(sex) |>mutate(Human = species =="Human") |>ggplot(aes(x = Human)) +geom_bar(aes(fill = sex), alpha =0.5) +scale_fill_colorblind() +labs(x ="¿Humanos?", y ="frecuencia absoluta", fill ="sexo", title ="Primer diagrama de barras",subtitle ="Sexos: femenino, masculino, hemafrodita, ninguno y ausente",caption ="J. Álvarez Liébana")
Cualis: barras solapas
Con position = "dodge2" visualizamos las barras sin apilar, solapadas una al lado de otra
starwars |>drop_na(sex) |>mutate(Human = species =="Human") |>ggplot(aes(x = Human)) +geom_bar(aes(fill = sex), alpha =0.5, position ="dodge2") +scale_fill_colorblind() +labs(x ="¿Humanos?", y ="frecuencia absoluta", fill ="sexo", title ="Primer diagrama de barras",subtitle ="Sexos: femenino, masculino, hemafrodita, ninguno y ausente",caption ="J. Álvarez Liébana")
Cualis: barras fill
Con position = "fill" visualizamos las barras en forma de frecuencia relativa, con las barras de la misma altura para facilitar la comparativa.
starwars |>drop_na(sex) |>mutate(Human = species =="Human") |>ggplot(aes(x = Human)) +geom_bar(aes(fill = sex), alpha =0.5, position ="fill") +scale_fill_colorblind() +labs(x ="¿Humanos?", y ="frecuencia relativa", fill ="sexo", title ="Primer diagrama de barras",subtitle ="Sexos: femenino, masculino, hemafrodita, ninguno y ausente",caption ="J. Álvarez Liébana")
Paréntesis: factores
En el caso de las variables cualitativas, llamaremos niveles o modalidades a los diferentes valores que pueden tomar estos datos. Por ejemplo, en el caso de la variable sex del conjunto starwars, tenemos 4 niveles permitidos: female, hermaphroditic, male y none (amén de datos ausentes).
starwars |>count(sex)
# A tibble: 5 × 2
sex n
<chr> <int>
1 female 16
2 hermaphroditic 1
3 male 60
4 none 6
5 <NA> 4
Paréntesis: factores
Este tipo de variables se conocen en R como factores. Y el paquete fundamental para tratarlos es {forcats} (del entorno {tidyverse}).
Paréntesis: factores
Este paquete nos permite fijar los niveles (guardados internamente como levels) que toma una determinada variable categórica, dándoles un tratamiento diferente a las cadena de texto normales.
Veamos un ejempo sencillo definiendo una variable estado que tome los valores "sano", "leve" y "grave" de la siguiente manera.
La variable estado actualmente es de tipo texto, de tipo chr, algo que podemos comprobar con class(estado).
class(estado)
[1] "character"
Paréntesis: factores
Desde un punto de vista estadístico y computacional, para R esta variable ahora mismo sería equivalente una variable de nombres. Pero estadísticamente no es lo mismo una variable con nombres (que identifican muchas veces el registro) que una variable categórica como estado que solo puede tomar esos 3 niveles. ¿Cómo convertir a factor?
Haciendo uso de la función as_factor() del paquete {forcats}.
No solo ha cambiado la clase de la variable sino que ahora, debajo del valor guardado, nos aparece la frase Levels: grave leve sano: son las modalidades o niveles de nuestra cualitativa.
Imagina que ese día en el hospital no tuviésemos a nadie en estado grave: aunque ese día nuestra variable no tome dicho valor, el estado grave es un nivel permitido en la base de datos, así que aunque lo eliminemos, por ser un factor, el nivel permanece (no lo tenemos ahora pero es un nivel permitido).
Esta forma de trabajar con variables cualitativas nos permite dar una definición teórica de nuestra base de datos, pudiendo incluso contar valores que aún no existen (pero que podrían), haciendo uso de fct_count()
# A tibble: 3 × 2
f n
<ord> <int>
1 sano 6
2 grave 4
3 leve 3
Paréntesis: factores
A veces querremos agrupar niveles, por ejemplo, no permitiendo niveles que no sucedan un mínimo de veces con fct_lump_min(.., min = ..) (las observaciones que no lo cumplan irán a un nivel genérico llamado Other, aunque se puede cambiar con el argumento other_level).
estado_fct |>pull(estado) |>fct_lump_min(min =4)
[1] Other grave sano sano Other sano sano grave grave Other grave sano
[13] sano
Levels: sano < grave < Other
[1] otros otros sano sano otros sano sano otros otros otros otros sano
[13] sano
Levels: sano < otros
Paréntesis: factores
Esto lo podemos aplicar a nuestros conjuntos de datos para recategorizar variables de forma muy rápida.
starwars |>drop_na(species) |>mutate(species =fct_lump_min(species, min =3,other_level ="Otras")) |>count(species)
# A tibble: 4 × 2
species n
<fct> <int>
1 Droid 6
2 Gungan 3
3 Human 35
4 Otras 39
Paréntesis: factores
Con fct_reorder() podemos también indicar que queremos ordenar los factores en función de una función aplicada a otra variable.
starwars_factor <- starwars |>drop_na(height, species) |>mutate(species =fct_lump_min(species, min =3,other_level ="Otras"))
starwars_factor |>pull(species)
[1] Human Droid Droid Human Human Human Human Droid Human Human
[11] Human Human Otras Human Otras Otras Human Otras Human Human
[21] Droid Otras Human Human Otras Human Otras Otras Human Otras
[31] Human Human Gungan Gungan Gungan Human Otras Otras Human Human
[41] Otras Otras Otras Otras Otras Otras Otras Human Otras Otras
[51] Otras Otras Otras Otras Otras Otras Human Otras Otras Otras
[61] Human Human Human Human Otras Otras Otras Otras Human Droid
[71] Otras Otras Otras Otras Otras Human Otras
Levels: Droid Gungan Human Otras
[1] Human Droid Droid Human Human Human Human Droid Human Human
[11] Human Human Otras Human Otras Otras Human Otras Human Human
[21] Droid Otras Human Human Otras Human Otras Otras Human Otras
[31] Human Human Gungan Gungan Gungan Human Otras Otras Human Human
[41] Otras Otras Otras Otras Otras Otras Otras Human Otras Otras
[51] Otras Otras Otras Otras Otras Otras Human Otras Otras Otras
[61] Human Human Human Human Otras Otras Otras Otras Human Droid
[71] Otras Otras Otras Otras Otras Human Otras
Levels: Droid Otras Human Gungan
Cualis: barras ordenadas
Haciendo uso de los que sabemos sobre factores podemos indicarle que nos ordene las columnas de manera personalizada definiendo la variable cuali como un factor.
starwars |>drop_na(sex) |>mutate(sex =factor(sex, levels =c("female", "male", "hermaphroditic", "none"))) |>ggplot(aes(x = sex)) +geom_bar(aes(fill = sex), alpha =0.5) +scale_fill_colorblind() +labs(x ="Sexo", y ="frecuencia absoluta", fill ="sexo", title ="Primer diagrama de barras",subtitle ="Sexos: femenino, masculino, hemafrodita, ninguno y ausente",caption ="J. Álvarez Liébana")
Cualis: barras ordenadas
También podemos indicarle que nos ordene las columnas de mayor a menor frecuencia usando simplemente fct_infreq()
starwars |>drop_na(sex) |>mutate(sex =factor(sex, levels =c("female", "male", "hermaphroditic", "none"))) |>ggplot(aes(x =fct_infreq(sex))) +geom_bar(aes(fill = sex), alpha =0.5) +scale_fill_colorblind() +labs(x ="Sexo", y ="frecuencia absoluta", fill ="sexo", title ="Primer diagrama de barras",subtitle ="Sexos: femenino, masculino, hemafrodita, ninguno y ausente",caption ="J. Álvarez Liébana")
Cualis: barras ordenadas
Para invertir el orden de los factores basta usar fct_rev()
starwars |>drop_na(sex) |>mutate(sex =factor(sex, levels =c("female", "male", "hermaphroditic", "none"))) |>ggplot(aes(x =fct_rev(fct_infreq(sex)))) +geom_bar(aes(fill = sex), alpha =0.5) +scale_fill_colorblind() +labs(x ="Sexo", y ="frecuencia absoluta", fill ="sexo", title ="Primer diagrama de barras",subtitle ="Sexos: femenino, masculino, hemafrodita, ninguno y ausente",caption ="J. Álvarez Liébana")
Cualis: geom_col()
La capa geom_bar() está solo pensada para conteos de variables discretas o cualitativas. ¿Y si queremos visualizar en el peso por sexo?
Usaremos geom_col() (ahora si necesitamos x,y)
starwars |>drop_na(mass, sex) |>ggplot(aes(x = sex, y = mass)) +geom_col(aes(fill = sex), alpha =0.5) +scale_fill_colorblind() +labs(x ="Sexo", y ="Peso", fill ="sexo", title ="Primer diagrama de columnas",subtitle ="Sexos: femenino, masculino, hemafrodita, ninguno y ausente", caption ="J. Álvarez Liébana")
Cualis: geom_col()
Fíjate que por defecto lo que hace es sumar la variable continua. ¿Cómo pedir que visualice, por ejemplo, la media por grupos?
La forma más inmediata es hacer un geom_col() pero en lugar de a la tabla original a un resumen de la misma.
starwars |>drop_na(mass, sex) |>summarise(mean_mass =mean(mass), .by = sex) |>ggplot(aes(x = sex, y = mean_mass)) +geom_col(aes(fill = sex), alpha =0.5) +scale_fill_colorblind() +labs(x ="Sexo", y ="Peso (medio)", fill ="sexo", title ="Primer diagrama de columnas",subtitle ="Sexos: femenino, masculino, hemafrodita, ninguno y ausente", caption ="J. Álvarez Liébana")
Cualis: geom_col()
Otra opción es no usar la capa geométrica sino la capa estadística, con stat_summary() e indicándole la función a visualizar y el geometría
starwars |>drop_na(mass, sex) |>mutate(sex =factor(sex, levels =c("female", "male", "hermaphroditic", "none"))) |>ggplot(aes(x = sex, y = mass, fill = sex)) +stat_summary(geom ="col", fun = mean, alpha =0.5) +scale_fill_colorblind() +labs(x ="Sexo", y ="Peso (medio)", fill ="sexo",title ="Primer diagrama de columnas",subtitle ="Sexos: femenino, masculino, hemafrodita, ninguno y ausente",caption ="J. Álvarez Liébana")
Cualis: geom_col()
Fíjate que ambas formas nos permiten visualizar cualquier otro estadístico, por ejempo, la mediana
starwars |>drop_na(mass, sex) |>mutate(sex =factor(sex, levels =c("female", "male", "hermaphroditic", "none"))) |>ggplot(aes(x = sex, y = mass, fill = sex)) +stat_summary(geom ="col", fun = median, alpha =0.5) +scale_fill_colorblind() +labs(x ="Sexo", y ="Peso (mediana)", fill ="sexo",title ="Primer diagrama de columnas",subtitle ="Sexos: femenino, masculino, hemafrodita, ninguno y ausente",caption ="J. Álvarez Liébana")
Cualis: geom_col()
La última opción es volver a nuestra conocida geom_bar(), indicándole stat = "summary", fun = "mean", por ejemplo (por defecto stat = "count") con ahora sí dos variables
starwars |>drop_na(mass, sex) |>mutate(sex =factor(sex, levels =c("female", "male", "hermaphroditic", "none"))) |>ggplot(aes(x = sex, y = mass)) +geom_bar(aes(fill = sex), alpha =0.5,stat ="summary", fun ="mean") +scale_fill_colorblind() +labs(x ="Sexo", y ="Peso (media)", fill ="sexo",title ="Primer diagrama de columnas",subtitle ="Sexos: femenino, masculino, hemafrodita, ninguno y ausente",caption ="J. Álvarez Liébana")
Imitando a Nightingale
Vamos a intentar replicar el famoso gráfico de rosa o diagrama de área polar de Florence Nightingale, cargando los datos de {HistData}. Los datos representan, por meses, las diferentes causas de mortalidad de los soldados ingleses en la Guerra de Crimea (busca en la ayuda para saber qué es cada cosa)
library(HistData)datos <-as_tibble(Nightingale)
Imitando a Nightingale
Filtra solo las variables relativas a fecha y las relativadas a tasas de mortalidad (por cada 1000 habitantes), aquellas que acaban por ".rate". Tras ello prepara los datos de manera adecuada para su visualización (todo en castellano)
Code
datos_filtrados <- datos |>select(Date:Year, contains("rate")) |>pivot_longer(cols =contains("rate"),names_to ="causa",values_to ="tasa") |>rename(fecha = Date, mes = Month, anno = Year) |>mutate(causa =case_when(causa =="Disease.rate"~"infecciosas", causa =="Wounds.rate"~"heridas",TRUE~"otras"))datos_filtrados
# A tibble: 72 × 5
fecha mes anno causa tasa
<date> <ord> <int> <chr> <dbl>
1 1854-04-01 Apr 1854 infecciosas 1.4
2 1854-04-01 Apr 1854 heridas 0
3 1854-04-01 Apr 1854 otras 7
4 1854-05-01 May 1854 infecciosas 6.2
5 1854-05-01 May 1854 heridas 0
6 1854-05-01 May 1854 otras 4.6
7 1854-06-01 Jun 1854 infecciosas 4.7
8 1854-06-01 Jun 1854 heridas 0
9 1854-06-01 Jun 1854 otras 2.5
10 1854-07-01 Jul 1854 infecciosas 150
# ℹ 62 more rows
Imitando a Nightingale
Realiza las transformaciones en los datos que consideres y replica el gráfico.
Imitando a Nightingale
Code
datos_filtrados <- datos_filtrados |>mutate(periodo =ifelse(fecha >="1855-04-01", "Abril 1855 - Marzo 1856", "Abril 1854 - Marzo 1855"),periodo =factor(periodo, levels =c("Abril 1854 - Marzo 1855", "Abril 1855 - Marzo 1856"),ordered =TRUE))theme_set(theme_minimal())ggplot(datos_filtrados, aes(x = mes, y = tasa, fill = causa)) +geom_col(alpha =0.85) +scale_fill_manual(values =c("#e3aeae", "#a5acb0", "#594b4a")) +facet_wrap(~periodo) +labs(fill ="Causas", title ="Causas de mortalidad",subtitle ="Periodos: Abril 1854 - Marzo 1855 y Abril 1855 - Marzo 1856",caption ="Autor: J. Álvarez Liébana | Data: {HistData}")
Imitando a Nightingale
Nuestros datos abarcan dos periodos: de abril 1854 a marzo 1855, y de abril 1855 a marzo 1856. Realiza los cambios necesarios para obtener el siguiente gráfico.
Imitando a Nightingale
Code
datos_filtrados <- datos_filtrados |>mutate(periodo =ifelse(fecha >="1855-04-01", "Abril 1855 - Marzo 1856", "Abril 1854 - Marzo 1855"),periodo =factor(periodo, levels =c("Abril 1854 - Marzo 1855", "Abril 1855 - Marzo 1856"),ordered =TRUE),mes =fct_relevel(mes, "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov","Dec", "Jan", "Feb", "Mar"))theme_set(theme_minimal())ggplot(datos_filtrados, aes(x = mes, y = tasa, fill = causa)) +geom_col(alpha =0.85) +scale_fill_manual(values =c("#e3aeae", "#a5acb0", "#594b4a")) +facet_wrap(~periodo) +labs(fill ="Causas", title ="Causas de mortalidad",subtitle ="Periodos: Abril 1854 - Marzo 1855 y Abril 1855 - Marzo 1856",caption ="Autor: J. Álvarez Liébana | Data: {HistData}")
Imitando a Nightingale
Piensa que cambio hemos realizado en el siguiente gráfico. ¿Qué se ha cambiado en las coordenadas? ¿Tenemos alguna capa que pueda ayudarnos a realizarlo? Investiga
Imitando a Nightingale
Code
theme_set(theme_minimal())ggplot(datos_filtrados, aes(x = mes, y = tasa, fill = causa)) +geom_col(alpha =0.85) +scale_fill_manual(values =c("#e3aeae", "#a5acb0", "#594b4a")) +coord_polar() +facet_wrap(~periodo) +labs(fill ="Causas", title ="Causas de mortalidad",subtitle ="Periodos: Abril 1854 - Marzo 1855 y Abril 1855 - Marzo 1856",caption ="Autor: J. Álvarez Liébana | Data: {HistData}")
Imitando a Nightingale
Ahora mismo se notan mucho las diferencias entre gajos. ¿Cómo podríamos reducir esa diferencia? ¿Qué tipo de cambio deberíamos realizar (qué tipo de capa usar)?
Imitando a Nightingale
Code
theme_set(theme_minimal())ggplot(datos_filtrados, aes(x = mes, y = tasa, fill = causa)) +geom_col(alpha =0.85) +scale_fill_manual(values =c("#e3aeae", "#a5acb0", "#594b4a")) +coord_polar() +scale_y_sqrt() +facet_wrap(~periodo) +labs(fill ="Causas", title ="Causas de mortalidad",subtitle ="Periodos: Abril 1854 - Marzo 1855 y Abril 1855 - Marzo 1856",caption ="Autor: J. Álvarez Liébana | Data: {HistData}")
Imitando a Nightingale
Dado que en el gráfico original no hay marcas en el eje Y, vamos eliminar el eje Y (sin título, sin textos, sin marcas). ¿Qué habría que cambiar? Investiga en theme() Situa además la leyenda en la parte inferior
Para que sea más legible vamos a reducir el tamaño de las etiquetas de los meses y vamos a darle etiquetas correctas a los meses (July en lugar de Jul, December en lugar de Dec, etc).
Solo haciendo uso de los gráficos aprendidos hasta ahora, ¿cómo visualizarías dicho dataset? Realiza las tranformaciones que consideres para una correcta preparación de los datos.

.png)