📝 Ejercicios recopilados
Aquí haremos una recopilación de los ejercicios planteados a lo largo del curso. Vuelve por aquí si quieres cuando acabas las lecciones para repasar aquellos ejercicios que más te hayan costado.
Primeros pasos
Scripts usados:
- script04.R: toma de contacto. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script04.R
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: en tu consola (parte inferior de tu pantalla), asigna los valores
2 y 5 a dos variables a y b. Tras asignarles valores, multiplica los números en consola (haz click en la flecha para la solución propuesta).
- Solución:
# Para poner comentarios en el código se usa #
# Definición de variables
a <- 2
b <- 5
# Multiplicación
a * b## [1] 10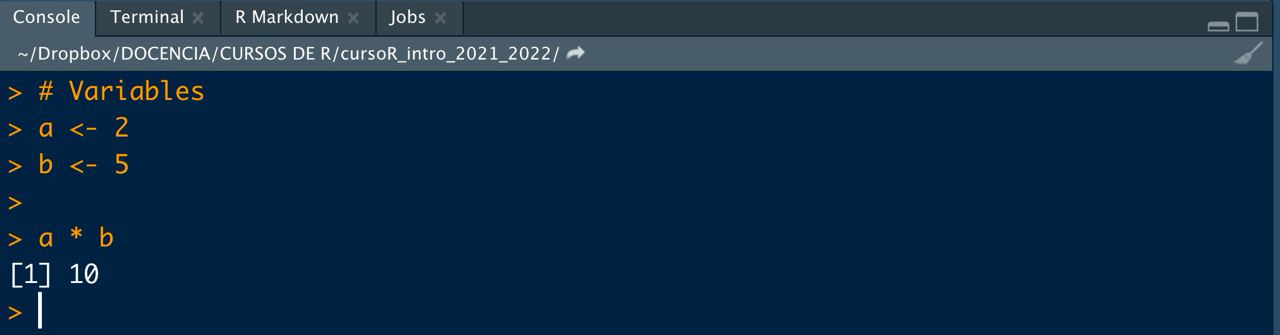
Imagen/gráfica 0.1: Multiplicación de a y b.
📝Ejercicio 2: modifica el código inferior para definir dos variables
c y d, con valores 3 y -1, y calcular la división c/d (haz click en la flecha para la solución propuesta).
# Definición de variables
c <-
d <-
# Operación (división)
c ? d- Solución:
# Definición de variables
c <- 3
d <- -1
# División
a / b## [1] 0.4
📝Ejercicio 3: repite el ejercicio 1 pero ahora guarda el resultado de la multiplicación final en una variable
c. Para ver el resultado guardado en c escribe dicha variable en consola (haz click en la flecha para la solución propuesta).
- Solución:
# Variables
a <- 2
b <- 5
# Resultado
c <- a * b
# Muestro en consola
c## [1] 10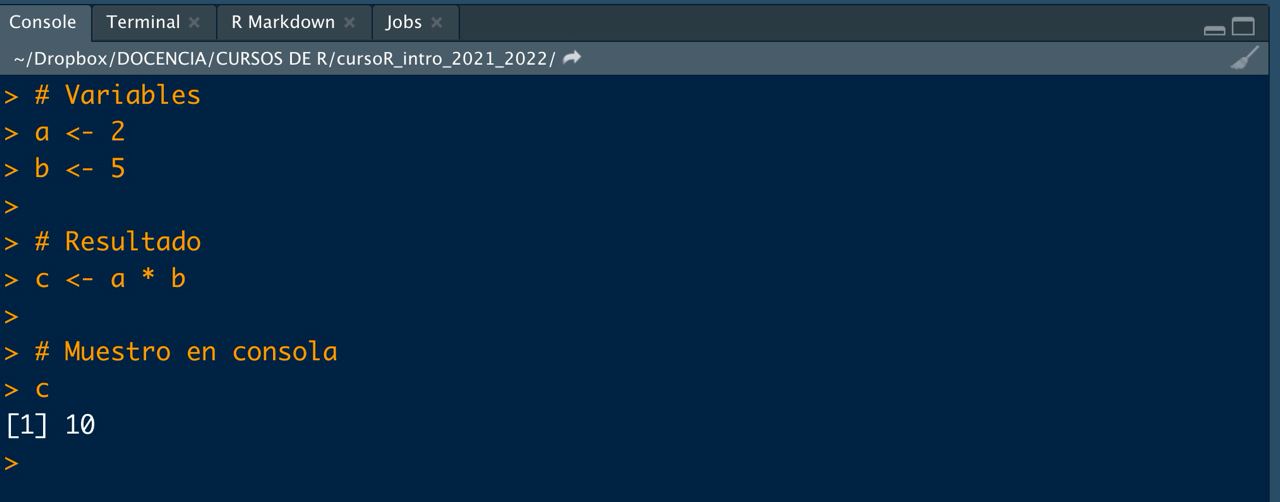
Imagen/gráfica 0.2: Multiplicación de a y b guardando el resultado.
📝Ejercicio 4: asigna ahora los valores
1, -2, 3 a tres variables a, b y c, y calcula la raíz cuadrada de cada uno.
- Solución:
# Variables
a <- 1
b <- -2
c <- 3
# Resultado
sqrt(a)## [1] 1
sqrt(b)## [1] NaN
sqrt(c)## [1] 1.732051
📝Ejercicio 5: repite el ejercicio 3 pero ahora escribe el código en un script (fichero de
.R, guardado en script01.R). Recuerda al acabar seleccionar las líneas a ejecutar y clickar Run, o bien guardar el script con Source on save activado (haz click en la flecha para la solución propuesta).
- Solución:
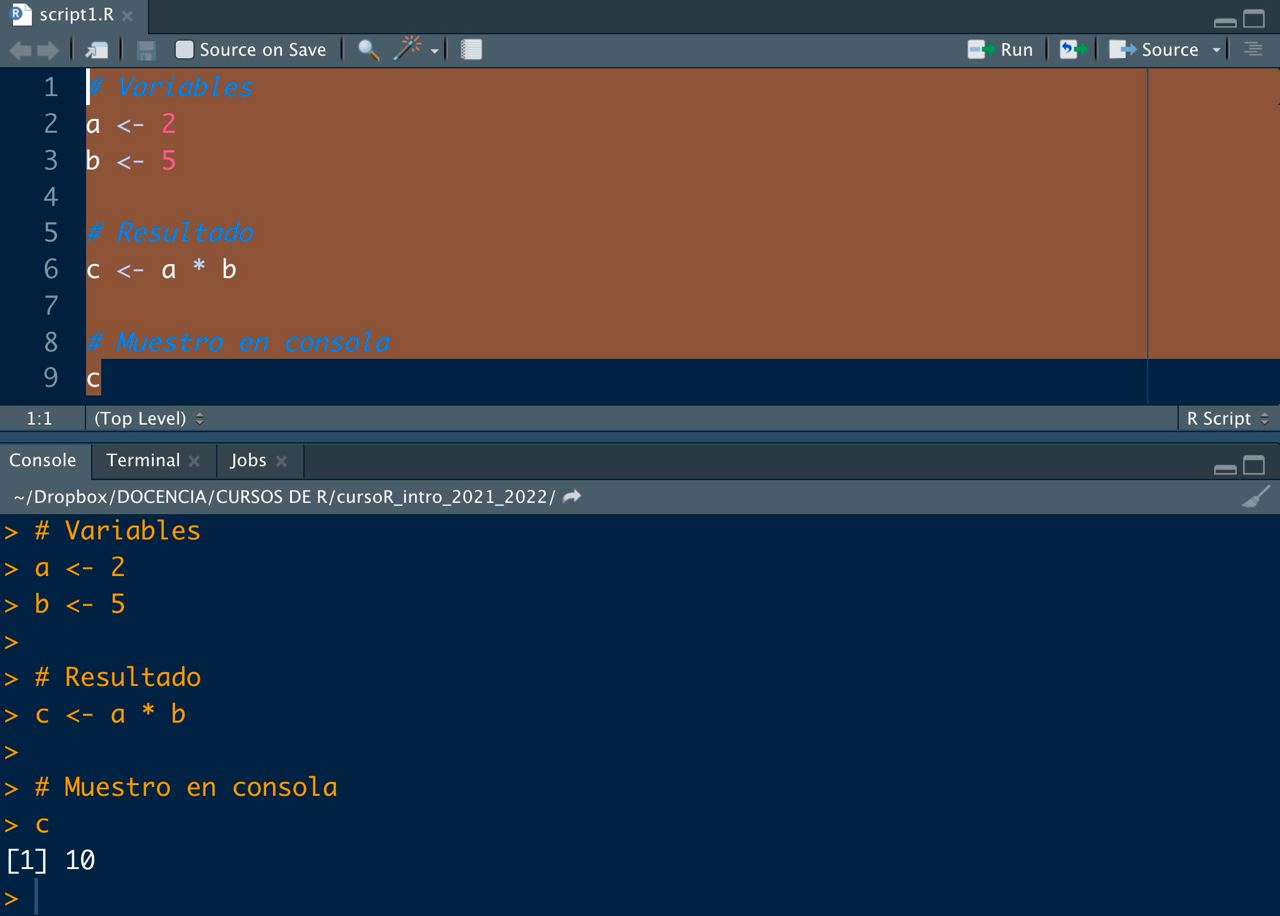
Imagen/gráfica 0.3: Multiplicación de a y b guardando el resultado pero escribiendo en el script.
📝Ejercicio 6: calcula en consola la suma de 3 más 4, y todo ello multiplicado por 10, y asígnalo a una variable
x (haz click en la flecha para la solución propuesta).
- Solución:
x <- (3 + 4) * 10
📝Ejercicio 7: asigna un valor positivo a
x y calcula su raíz cuadrada; asigna otro negativo y calcula su valor absoluto (haz click en la flecha para la solución propuesta).
- Solución:
# Raíz cuadrada
x <- 73
sqrt(x)## [1] 8.544004
# Valor absoluto
y <- -73
abs(y)## [1] 73
CONSEJO:
Las órdenes sqrt(x) y abs(y) se llaman funciones, y la variable que tienen entre paréntesis se llama argumento de la función: una variable que toma de entrada la función y con la que opera internamente.
📝Ejercicio 8: usando la variable
x ya definida, calcula la resta x - 5 y guárdala en una nueva variable z (haz click en la flecha para la solución propuesta).
- Solución:
z <- x - 5
z## [1] 68
📝Ejercicio 9: usando las variables
x y z ya definidas, calcula el máximo de ambas, y guárdalo en una nueva variable t. (haz click en la flecha para la solución propuesta).
- Solución:
t <- max(x, z)
t## [1] 73
WARNING:
No hace falta gastar una línea por cada orden que quieras ejecutar. Tampoco necesitas guardar cada paso intermedio que realices. Cuidado con la memoria: cada asignación que hagas es una variable guardada que consume recursos en tu ordenador.
Tipos de datos
Scripts usados:
- script05.R: tipos de datos y funciones usadas con ellos. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script05.R
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: define una variable que guarde tu edad, otra con tu nombre, otra respondiendo a la pregunta «¿tengo hermanos?» y otra con la fecha de tu nacimiento.
- Solución:
edad <- 32 # tipo numeric
nombre <- "Javier" # tipo caracter
hermanos <- TRUE # tipo hermanos
fecha_nacimiento <- as.Date("1989-09-10") # tipo fecha
📝Ejercicio 2: define otra variable con tus apellidos y junta las variables
nombre y apellidos en una sola variable nombre_completo.
- Solución:
library(glue)
# Apellidos
apellidos <- "Álvarez Liébana"
# Pegamos
nombre_completo <- glue("{nombre} {apellidos}")
nombre_completo## Javier Álvarez Liébana
# Otra forma
nombre_completo <- paste(nombre, apellidos)
nombre_completo## [1] "Javier Álvarez Liébana"
📝Ejercicio 3: construye una frase que diga «Hola, me llamo … y tengo … años. Nací el … de … de …» (con el nombre completo).
- Solución:
library(lubridate)
dia_nacimiento <- day(fecha_nacimiento)
mes_nacimiento <- month(fecha_nacimiento)
a_nacimiento <- year(fecha_nacimiento)
glue("Hola, me llamo {nombre_completo} y tengo {edad} años. Nací el {dia_nacimiento} del {mes_nacimiento} de {a_nacimiento}")## Hola, me llamo Javier Álvarez Liébana y tengo 32 años. Nací el 10 del 9 de 1989
📝Ejercicio 4: calcula los días que han pasado desde la fecha de tu nacimiento
- Solución:
## [1] "11830d 0H 0M 0S"
📝Ejercicio 5: obtén una variable lógica que nos diga si se cumplen (todas) las condiciones i) menor de 30 años (
edad < 30); ii) con hermanos (hermanos == TRUE); iii) nacido en 1990 o posterior (fecha_nacimiento >= as.Date("1990-01-01")).
- Solución:
# Se tienen que cumplir todas
edad < 30 & fecha_nacimiento >= as.Date("1990-01-01") & hermanos## [1] FALSE
# otra forma
edad < 30 & fecha_nacimiento >= as.Date("1990-01-01") & hermanos == TRUE## [1] FALSE
📝Ejercicio 6: modifica el código del ejercicio anterior para obtener una variable lógica que nos diga si se cumplen (al menos) alguna de las condiciones i) menor de 30 años; ii) con hermanos; iii) nacido en 1990 o posterior. Al contrario que antes, no necesitamos que se cumplan todas, nos basta con que se cumple al menos una.
- Solución:
# Se tienen que cumplir todas
edad < 30 | fecha_nacimiento >= as.Date("1990-01-01") | hermanos## [1] TRUE
📝Ejercicio 7: calcula la fecha 11 días más tarde a tu fecha de nacimiento. Obtén la semana del año de dicha fecha y el día de la semana con las funciones
week, wday y weekdays.
- Solución:
# Podemos sumar porque es fecha
fecha_post <- fecha_nacimiento + 11
fecha_post## [1] "1989-09-21"
# Semana del año
week(fecha_post)## [1] 38
# Día de la semana (versión americana, empiezan el domingo)
wday(fecha_post)## [1] 5
# Día de la semana (versión española)
wday(fecha_post, week_start = 1)## [1] 4
# Día de la semana en texto
weekdays(fecha_post)## [1] "Thursday"
📝Ejercicio 8: define dos números cualesquiera en variable
a y b. Calcula su suma y determina cual es mayor.
- Solución:
a <- -5
b <- 7
# Suma
c <- a + b
c## [1] 2
# Comparaciones
a == b # ¿a = b?## [1] FALSE
a < b # ¿a < b?## [1] TRUE
Vectores
Scripts usados:
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: modifica el código anterior para crear un vector de nombre
vector_num que contenga los números 1, 5 y -7.
# Vector de números
vector_num <- c(1)
vector_num- Solución:
# Vector de números
vector_num <- c(1, 5, -7)
vector_num## [1] 1 5 -7
📝Ejercicio 2: define un vector que contenga los números 1, 10, -1 y 2, y guárdalo en una variable llamada
vector_num.
- Solución:
# Vector de números
vector_num <- c(1, 10, -1, 2)
vector_num## [1] 1 10 -1 2
📝Ejercicio 3: obtén la longitud del vector anterior
vector_num.
- Solución:
# Longitud del vector
length(vector_num)## [1] 4
📝Ejercicio 4: crea un vector con las palabras “Hola”, “me”, “llamo” (y tu nombre y apellidos), y pega luego sus elementos de forma que la frase esté correctamente escrita en castellano. Tras hacerlo, añade “y tengo 30 años”.
- Solución:
# Definiendo el vector
vector_char <- c("Hola", "me", "llamo", "Javier",
"Álvarez", "Liébana")
# Pegamos
frase <- paste(vector_char, collapse = " ")
frase## [1] "Hola me llamo Javier Álvarez Liébana"
# Añadimos frase
glue("{frase} y tengo 30 años.")## Hola me llamo Javier Álvarez Liébana y tengo 30 años.
# Otra forma
paste0(frase, " y tengo 30 años.")## [1] "Hola me llamo Javier Álvarez Liébana y tengo 30 años."
# Otra forma
paste(frase, "y tengo 30 años.")## [1] "Hola me llamo Javier Álvarez Liébana y tengo 30 años."
📝Ejercicio 5: el código inferior crea una secuencia de números, que empieza en
-1, que acaba en 32, y que va saltando de 2 en 2. Modíficalo para que haga el salto de 3 en 3 y guárdalo en una variable llamada secuencia.
seq(-1, 32, by = 2)- Solución:
secuencia <- seq(-1, 32, by = 3)
secuencia## [1] -1 2 5 8 11 14 17 20 23 26 29 32
length(secuencia) # longitud de la secuencia## [1] 12
📝Ejercicio 6: crea una secuencia de números, que empiece en
-1, que acabe en 32, y que tenga longitud 12.
- Solución:
secuencia <- seq(-1, 32, l = 12)
secuencia## [1] -1 2 5 8 11 14 17 20 23 26 29 32
length(secuencia) # longitud de la secuencia## [1] 12
📝Ejercicio 7: crea una secuencia que empiece en 1 y recorra todos los naturales hasta el 10. Después crea otra secuencia de longitud 7 que todos los números sean
3.
- Solución:
1:10## [1] 1 2 3 4 5 6 7 8 9 10
rep(3, 7) # secuencia repetida## [1] 3 3 3 3 3 3 3
📝Ejercicio 8: crea una secuencia que repita 5 veces el patrón
1, 2, 3. Después crea otra que repita dicho patrón pero de forma intercalada, con 5 veces 1, después 5 veces 2 y después 5 veces 3.
- Solución:
## [1] 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3## [1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3
📝Ejercicio 9: crea un vector con las edades de cuatro conocidos o familiares. Tras ello, determina cuáles de ellos tienen menos de 20 años, 30 años o más, menos de 40 años y más de 65 años.
- Solución:
edades <- c(27, 32, 60, 61) # en mi caso, por ejemplo
edades < 20 # menos de 20 años## [1] FALSE FALSE FALSE FALSE
edades >= 30 # 30 años o más## [1] FALSE TRUE TRUE TRUE
edades < 40 # menos de 40 años## [1] TRUE TRUE FALSE FALSE
edades > 65 # más de 65 años## [1] FALSE FALSE FALSE FALSEOperaciones con vectores
Scripts usados:
- script07.R: operaciones con vectores. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script07.R
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: define de nuevo el vector
vector_num definido como un vector que contenga los números 1, 10, -1 y 2) y calcula su suma del vector.
- Solución:
## [1] 12
📝Ejercicio 2: define otro vector
vector_num2 que contenga los números 5, -7, 8, -3, y haz la suma de vector_num y vector_num2.
- Solución:
# Vector de números
vector_num2 <- c(5, -7, 8, -3)
# Suma
vector_num + vector_num2## [1] 6 3 7 -1
📝Ejercicio 3: calcula el número de elementos mayores que 0 del resultado de la suma de
vector_num y vector_num2.
- Solución:
# Vector de números
vector_suma <- vector_num + vector_num2
# Suma
sum(vector_suma > 0)## [1] 3
📝Ejercicio 4: calcula la versión ordenada del vector
vector_num.
- Solución:
# Ordenamos el vector (con sort)
sort(vector_num)## [1] -1 1 2 10
# Ordenamos el vector (con order)
vector_num[order(vector_num)]## [1] -1 1 2 10
📝Ejercicio 5: encuentra del vector
vector_num original el lugar (el índice) que ocupa su mínimo y su máximo.
- Solución:
vector_num <- c(1, 10, -1, 2)
# Encontrando el lugar que ocupa el máximo y mínimo
which.max(vector_num)## [1] 2
which.min(vector_num)## [1] 3
📝Ejercicio 6: encuentra del vector
vector_num los elementos mayores que 1 y menores que 7. Encuentra una forma de averiguar si todos los elementos son o no positivos.
- Solución:
# Vector lógico: mayores que 1 y menores que 7
vector_num > 1 & vector_num < 7## [1] FALSE FALSE FALSE TRUE
# ¿Son todos positivos?
all(vector_num > 0)## [1] FALSE
📝Ejercicio 7: define el vector
c(-1, 0, 4, 5, -2), calcula la raíz cuadrada del vector y determina que lugares son ausente de tipo NaN.
- Solución:
# Vector
x <- c(-1, 0, 4, 5, -2)
# ¿Cuáles son ausentes tras aplicar la raíz cuadrada?
is.nan(sqrt(x))## [1] TRUE FALSE FALSE FALSE TRUE
📝Ejercicio 8: define el vector de los primeros números impares (hasta el 21) y extrae los elementos que ocupan los lugares 1, 4, 5, 8. Elimina del vector el segundo elemento
- Solución:
# Vector de impares (de 1 a 21 saltando de dos en dos)
x <- seq(1, 21, by = 2)
# Seleccionamos elementos
x[c(1, 4, 5, 8)]## [1] 1 7 9 15
# Eliminamos elementos
y <- x[-2]
y## [1] 1 5 7 9 11 13 15 17 19 21Estructuras de datos: matrices y tablas (data.frame)
Scripts usados:
- script08.R: matrices y data.frames. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script08.R
(haz click en las flechas para ver soluciones)
Ejercicio 1: modifica el código para definir una matriz
x de ceros de 3 filas y 7 columnas.
# Matriz
x <- matrix(0, nrow = 2, ncol = 3)
x- Solución:
# Matriz
x <- matrix(0, nrow = 3, ncol = 7)
x## [,1] [,2] [,3] [,4] [,5] [,6] [,7]
## [1,] 0 0 0 0 0 0 0
## [2,] 0 0 0 0 0 0 0
## [3,] 0 0 0 0 0 0 0
Ejercicio 2: a la matriz anterior, suma un 1 a cada número de la matriz y divide el resultado entre 5.
- Solución:
(x + 1) / 5## [,1] [,2] [,3] [,4] [,5] [,6] [,7]
## [1,] 0.2 0.2 0.2 0.2 0.2 0.2 0.2
## [2,] 0.2 0.2 0.2 0.2 0.2 0.2 0.2
## [3,] 0.2 0.2 0.2 0.2 0.2 0.2 0.2
Ejercicio 3: tras definir la matriz
x calcula su transpuesta y obtén sus dimensiones
- Solución:
# Transpuesta
t(x)## [,1] [,2] [,3]
## [1,] 0 0 0
## [2,] 0 0 0
## [3,] 0 0 0
## [4,] 0 0 0
## [5,] 0 0 0
## [6,] 0 0 0
## [7,] 0 0 0## [1] 7 3## [1] 3## [1] 7
Ejercicio 4: el siguiente código define una matriz de dimensiones
4 x 3 y calcula la suma por columnas. Modifica el código para que realice la suma por filas.
# Matriz
matriz <- matrix(1:12, nrow = 4)
# Suma por columnas
apply(matriz, MARGIN = 2, FUN = "sum")## [1] 10 26 42- Solución:
## [1] 15 18 21 24
Ejercicio 5: con la matriz anterior definida como
matrix(1:12, nrow = 4), calcula la media de todos los elementos, la media de cada fila y la media de cada columna.
- Solución:
## [1] 6.5
# Media por filas (MARGIN = 1 ya que es una operación por filas)
apply(matriz, MARGIN = 1, FUN = "mean")## [1] 5 6 7 8
# Media por filas (MARGIN = 2 ya que es una operación por filas)
apply(matriz, MARGIN = 2, FUN = "mean")## [1] 2.5 6.5 10.5
Ejercicio 6: el
data.frame llamado airquality, del paquete {datasets}, contiene variables de la calidad del aire de la ciudad de Nueva York desde mayo hasta septiembre de 1973. Obtén el nombre de las variables.
- Solución:
## [1] "Ozone" "Solar.R" "Wind" "Temp" "Month" "Day"
Ejercicio 7: obtén las dimensiones del conjunto de datos. ¿Cuántas variables hay? ¿Cuántos días se han medido?
- Solución:
# Dimensiones
dim(airquality)## [1] 153 6
nrow(airquality)## [1] 153
ncol(airquality)## [1] 6
Ejercicio 8: modifica el código inferior para que nos filtre solo los datos del mes de julio.
# Filtramos filas
filtro_fila <- subset(., subset = Month < 6)
filtro_fila- Solución:
# Filtramos filas
filtro_fila <- subset(airquality, subset = Month == 7)
filtro_fila## Ozone Solar.R Wind Temp Month Day
## 62 135 269 4.1 84 7 1
## 63 49 248 9.2 85 7 2
## 64 32 236 9.2 81 7 3
## 65 NA 101 10.9 84 7 4
## 66 64 175 4.6 83 7 5
## 67 40 314 10.9 83 7 6
## 68 77 276 5.1 88 7 7
## 69 97 267 6.3 92 7 8
## 70 97 272 5.7 92 7 9
## 71 85 175 7.4 89 7 10
## 72 NA 139 8.6 82 7 11
## 73 10 264 14.3 73 7 12
## 74 27 175 14.9 81 7 13
## 75 NA 291 14.9 91 7 14
## 76 7 48 14.3 80 7 15
## 77 48 260 6.9 81 7 16
## 78 35 274 10.3 82 7 17
## 79 61 285 6.3 84 7 18
## 80 79 187 5.1 87 7 19
## 81 63 220 11.5 85 7 20
## 82 16 7 6.9 74 7 21
## 83 NA 258 9.7 81 7 22
## 84 NA 295 11.5 82 7 23
## 85 80 294 8.6 86 7 24
## 86 108 223 8.0 85 7 25
## 87 20 81 8.6 82 7 26
## 88 52 82 12.0 86 7 27
## 89 82 213 7.4 88 7 28
## 90 50 275 7.4 86 7 29
## 91 64 253 7.4 83 7 30
## 92 59 254 9.2 81 7 31
Ejercicio 9: del conjunto
airquality selecciona aquellos datos que no sean ni de julio ni de agosto.
- Solución:
## Ozone Solar.R Wind Temp Month Day
## 1 41 190 7.4 67 5 1
## 2 36 118 8.0 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6
## 7 23 299 8.6 65 5 7
## 8 19 99 13.8 59 5 8
## 9 8 19 20.1 61 5 9
## 10 NA 194 8.6 69 5 10
## 11 7 NA 6.9 74 5 11
## 12 16 256 9.7 69 5 12
## 13 11 290 9.2 66 5 13
## 14 14 274 10.9 68 5 14
## 15 18 65 13.2 58 5 15
## 16 14 334 11.5 64 5 16
## 17 34 307 12.0 66 5 17
## 18 6 78 18.4 57 5 18
## 19 30 322 11.5 68 5 19
## 20 11 44 9.7 62 5 20
## 21 1 8 9.7 59 5 21
## 22 11 320 16.6 73 5 22
## 23 4 25 9.7 61 5 23
## 24 32 92 12.0 61 5 24
## 25 NA 66 16.6 57 5 25
## 26 NA 266 14.9 58 5 26
## 27 NA NA 8.0 57 5 27
## 28 23 13 12.0 67 5 28
## 29 45 252 14.9 81 5 29
## 30 115 223 5.7 79 5 30
## 31 37 279 7.4 76 5 31
## 32 NA 286 8.6 78 6 1
## 33 NA 287 9.7 74 6 2
## 34 NA 242 16.1 67 6 3
## 35 NA 186 9.2 84 6 4
## 36 NA 220 8.6 85 6 5
## 37 NA 264 14.3 79 6 6
## 38 29 127 9.7 82 6 7
## 39 NA 273 6.9 87 6 8
## 40 71 291 13.8 90 6 9
## 41 39 323 11.5 87 6 10
## 42 NA 259 10.9 93 6 11
## 43 NA 250 9.2 92 6 12
## 44 23 148 8.0 82 6 13
## 45 NA 332 13.8 80 6 14
## 46 NA 322 11.5 79 6 15
## 47 21 191 14.9 77 6 16
## 48 37 284 20.7 72 6 17
## 49 20 37 9.2 65 6 18
## 50 12 120 11.5 73 6 19
## 51 13 137 10.3 76 6 20
## 52 NA 150 6.3 77 6 21
## 53 NA 59 1.7 76 6 22
## 54 NA 91 4.6 76 6 23
## 55 NA 250 6.3 76 6 24
## 56 NA 135 8.0 75 6 25
## 57 NA 127 8.0 78 6 26
## 58 NA 47 10.3 73 6 27
## 59 NA 98 11.5 80 6 28
## 60 NA 31 14.9 77 6 29
## 61 NA 138 8.0 83 6 30
## 124 96 167 6.9 91 9 1
## 125 78 197 5.1 92 9 2
## 126 73 183 2.8 93 9 3
## 127 91 189 4.6 93 9 4
## 128 47 95 7.4 87 9 5
## 129 32 92 15.5 84 9 6
## 130 20 252 10.9 80 9 7
## 131 23 220 10.3 78 9 8
## 132 21 230 10.9 75 9 9
## 133 24 259 9.7 73 9 10
## 134 44 236 14.9 81 9 11
## 135 21 259 15.5 76 9 12
## 136 28 238 6.3 77 9 13
## 137 9 24 10.9 71 9 14
## 138 13 112 11.5 71 9 15
## 139 46 237 6.9 78 9 16
## 140 18 224 13.8 67 9 17
## 141 13 27 10.3 76 9 18
## 142 24 238 10.3 68 9 19
## 143 16 201 8.0 82 9 20
## 144 13 238 12.6 64 9 21
## 145 23 14 9.2 71 9 22
## 146 36 139 10.3 81 9 23
## 147 7 49 10.3 69 9 24
## 148 14 20 16.6 63 9 25
## 149 30 193 6.9 70 9 26
## 150 NA 145 13.2 77 9 27
## 151 14 191 14.3 75 9 28
## 152 18 131 8.0 76 9 29
## 153 20 223 11.5 68 9 30
Ejercicio 10: modifica el siguiente código para quedarte solo con las variable
Ozone y Temp.
- Solución:
## Ozone Temp
## 1 41 67
## 2 36 72
## 3 12 74
## 4 18 62
## 5 NA 56
## 6 28 66
## 7 23 65
## 8 19 59
## 9 8 61
## 10 NA 69
## 11 7 74
## 12 16 69
## 13 11 66
## 14 14 68
## 15 18 58
## 16 14 64
## 17 34 66
## 18 6 57
## 19 30 68
## 20 11 62
## 21 1 59
## 22 11 73
## 23 4 61
## 24 32 61
## 25 NA 57
## 26 NA 58
## 27 NA 57
## 28 23 67
## 29 45 81
## 30 115 79
## 31 37 76
## 32 NA 78
## 33 NA 74
## 34 NA 67
## 35 NA 84
## 36 NA 85
## 37 NA 79
## 38 29 82
## 39 NA 87
## 40 71 90
## 41 39 87
## 42 NA 93
## 43 NA 92
## 44 23 82
## 45 NA 80
## 46 NA 79
## 47 21 77
## 48 37 72
## 49 20 65
## 50 12 73
## 51 13 76
## 52 NA 77
## 53 NA 76
## 54 NA 76
## 55 NA 76
## 56 NA 75
## 57 NA 78
## 58 NA 73
## 59 NA 80
## 60 NA 77
## 61 NA 83
## 62 135 84
## 63 49 85
## 64 32 81
## 65 NA 84
## 66 64 83
## 67 40 83
## 68 77 88
## 69 97 92
## 70 97 92
## 71 85 89
## 72 NA 82
## 73 10 73
## 74 27 81
## 75 NA 91
## 76 7 80
## 77 48 81
## 78 35 82
## 79 61 84
## 80 79 87
## 81 63 85
## 82 16 74
## 83 NA 81
## 84 NA 82
## 85 80 86
## 86 108 85
## 87 20 82
## 88 52 86
## 89 82 88
## 90 50 86
## 91 64 83
## 92 59 81
## 93 39 81
## 94 9 81
## 95 16 82
## 96 78 86
## 97 35 85
## 98 66 87
## 99 122 89
## 100 89 90
## 101 110 90
## 102 NA 92
## 103 NA 86
## 104 44 86
## 105 28 82
## 106 65 80
## 107 NA 79
## 108 22 77
## 109 59 79
## 110 23 76
## 111 31 78
## 112 44 78
## 113 21 77
## 114 9 72
## 115 NA 75
## 116 45 79
## 117 168 81
## 118 73 86
## 119 NA 88
## 120 76 97
## 121 118 94
## 122 84 96
## 123 85 94
## 124 96 91
## 125 78 92
## 126 73 93
## 127 91 93
## 128 47 87
## 129 32 84
## 130 20 80
## 131 23 78
## 132 21 75
## 133 24 73
## 134 44 81
## 135 21 76
## 136 28 77
## 137 9 71
## 138 13 71
## 139 46 78
## 140 18 67
## 141 13 76
## 142 24 68
## 143 16 82
## 144 13 64
## 145 23 71
## 146 36 81
## 147 7 69
## 148 14 63
## 149 30 70
## 150 NA 77
## 151 14 75
## 152 18 76
## 153 20 68
Ejercicio 11: del conjunto
airquality selecciona los datos de temperatura y viento de agosto.
- Solución:
# Todo de una vez
filtro <- subset(airquality, subset = Month == 8,
select = c("Temp", "Wind"))
filtro## Temp Wind
## 93 81 6.9
## 94 81 13.8
## 95 82 7.4
## 96 86 6.9
## 97 85 7.4
## 98 87 4.6
## 99 89 4.0
## 100 90 10.3
## 101 90 8.0
## 102 92 8.6
## 103 86 11.5
## 104 86 11.5
## 105 82 11.5
## 106 80 9.7
## 107 79 11.5
## 108 77 10.3
## 109 79 6.3
## 110 76 7.4
## 111 78 10.9
## 112 78 10.3
## 113 77 15.5
## 114 72 14.3
## 115 75 12.6
## 116 79 9.7
## 117 81 3.4
## 118 86 8.0
## 119 88 5.7
## 120 97 9.7
## 121 94 2.3
## 122 96 6.3
## 123 94 6.3
Ejercicio 12: calcula el número de filas borradas del ejercicio anterior. Tras hacer todo ello, traduce a castellano el nombre de las columnas del
data.frame filtrado.
- Solución:
## [1] 122
Ejercicio 13: añade a los datos originales una columna con la fecha completa (recuerda que es del año 1973 todas las observaciones.
- Solución:
# Construimos las fechas (pegamos año-mes-día con "-")
fechas <-
as.Date(paste("1973", airquality$Month, airquality$Day,
sep = "-"))
# Añadimos
data.frame(airquality, fechas)## Ozone Solar.R Wind Temp Month Day fechas
## 1 41 190 7.4 67 5 1 1973-05-01
## 2 36 118 8.0 72 5 2 1973-05-02
## 3 12 149 12.6 74 5 3 1973-05-03
## 4 18 313 11.5 62 5 4 1973-05-04
## 5 NA NA 14.3 56 5 5 1973-05-05
## 6 28 NA 14.9 66 5 6 1973-05-06
## 7 23 299 8.6 65 5 7 1973-05-07
## 8 19 99 13.8 59 5 8 1973-05-08
## 9 8 19 20.1 61 5 9 1973-05-09
## 10 NA 194 8.6 69 5 10 1973-05-10
## 11 7 NA 6.9 74 5 11 1973-05-11
## 12 16 256 9.7 69 5 12 1973-05-12
## 13 11 290 9.2 66 5 13 1973-05-13
## 14 14 274 10.9 68 5 14 1973-05-14
## 15 18 65 13.2 58 5 15 1973-05-15
## 16 14 334 11.5 64 5 16 1973-05-16
## 17 34 307 12.0 66 5 17 1973-05-17
## 18 6 78 18.4 57 5 18 1973-05-18
## 19 30 322 11.5 68 5 19 1973-05-19
## 20 11 44 9.7 62 5 20 1973-05-20
## 21 1 8 9.7 59 5 21 1973-05-21
## 22 11 320 16.6 73 5 22 1973-05-22
## 23 4 25 9.7 61 5 23 1973-05-23
## 24 32 92 12.0 61 5 24 1973-05-24
## 25 NA 66 16.6 57 5 25 1973-05-25
## 26 NA 266 14.9 58 5 26 1973-05-26
## 27 NA NA 8.0 57 5 27 1973-05-27
## 28 23 13 12.0 67 5 28 1973-05-28
## 29 45 252 14.9 81 5 29 1973-05-29
## 30 115 223 5.7 79 5 30 1973-05-30
## 31 37 279 7.4 76 5 31 1973-05-31
## 32 NA 286 8.6 78 6 1 1973-06-01
## 33 NA 287 9.7 74 6 2 1973-06-02
## 34 NA 242 16.1 67 6 3 1973-06-03
## 35 NA 186 9.2 84 6 4 1973-06-04
## 36 NA 220 8.6 85 6 5 1973-06-05
## 37 NA 264 14.3 79 6 6 1973-06-06
## 38 29 127 9.7 82 6 7 1973-06-07
## 39 NA 273 6.9 87 6 8 1973-06-08
## 40 71 291 13.8 90 6 9 1973-06-09
## 41 39 323 11.5 87 6 10 1973-06-10
## 42 NA 259 10.9 93 6 11 1973-06-11
## 43 NA 250 9.2 92 6 12 1973-06-12
## 44 23 148 8.0 82 6 13 1973-06-13
## 45 NA 332 13.8 80 6 14 1973-06-14
## 46 NA 322 11.5 79 6 15 1973-06-15
## 47 21 191 14.9 77 6 16 1973-06-16
## 48 37 284 20.7 72 6 17 1973-06-17
## 49 20 37 9.2 65 6 18 1973-06-18
## 50 12 120 11.5 73 6 19 1973-06-19
## 51 13 137 10.3 76 6 20 1973-06-20
## 52 NA 150 6.3 77 6 21 1973-06-21
## 53 NA 59 1.7 76 6 22 1973-06-22
## 54 NA 91 4.6 76 6 23 1973-06-23
## 55 NA 250 6.3 76 6 24 1973-06-24
## 56 NA 135 8.0 75 6 25 1973-06-25
## 57 NA 127 8.0 78 6 26 1973-06-26
## 58 NA 47 10.3 73 6 27 1973-06-27
## 59 NA 98 11.5 80 6 28 1973-06-28
## 60 NA 31 14.9 77 6 29 1973-06-29
## 61 NA 138 8.0 83 6 30 1973-06-30
## 62 135 269 4.1 84 7 1 1973-07-01
## 63 49 248 9.2 85 7 2 1973-07-02
## 64 32 236 9.2 81 7 3 1973-07-03
## 65 NA 101 10.9 84 7 4 1973-07-04
## 66 64 175 4.6 83 7 5 1973-07-05
## 67 40 314 10.9 83 7 6 1973-07-06
## 68 77 276 5.1 88 7 7 1973-07-07
## 69 97 267 6.3 92 7 8 1973-07-08
## 70 97 272 5.7 92 7 9 1973-07-09
## 71 85 175 7.4 89 7 10 1973-07-10
## 72 NA 139 8.6 82 7 11 1973-07-11
## 73 10 264 14.3 73 7 12 1973-07-12
## 74 27 175 14.9 81 7 13 1973-07-13
## 75 NA 291 14.9 91 7 14 1973-07-14
## 76 7 48 14.3 80 7 15 1973-07-15
## 77 48 260 6.9 81 7 16 1973-07-16
## 78 35 274 10.3 82 7 17 1973-07-17
## 79 61 285 6.3 84 7 18 1973-07-18
## 80 79 187 5.1 87 7 19 1973-07-19
## 81 63 220 11.5 85 7 20 1973-07-20
## 82 16 7 6.9 74 7 21 1973-07-21
## 83 NA 258 9.7 81 7 22 1973-07-22
## 84 NA 295 11.5 82 7 23 1973-07-23
## 85 80 294 8.6 86 7 24 1973-07-24
## 86 108 223 8.0 85 7 25 1973-07-25
## 87 20 81 8.6 82 7 26 1973-07-26
## 88 52 82 12.0 86 7 27 1973-07-27
## 89 82 213 7.4 88 7 28 1973-07-28
## 90 50 275 7.4 86 7 29 1973-07-29
## 91 64 253 7.4 83 7 30 1973-07-30
## 92 59 254 9.2 81 7 31 1973-07-31
## 93 39 83 6.9 81 8 1 1973-08-01
## 94 9 24 13.8 81 8 2 1973-08-02
## 95 16 77 7.4 82 8 3 1973-08-03
## 96 78 NA 6.9 86 8 4 1973-08-04
## 97 35 NA 7.4 85 8 5 1973-08-05
## 98 66 NA 4.6 87 8 6 1973-08-06
## 99 122 255 4.0 89 8 7 1973-08-07
## 100 89 229 10.3 90 8 8 1973-08-08
## 101 110 207 8.0 90 8 9 1973-08-09
## 102 NA 222 8.6 92 8 10 1973-08-10
## 103 NA 137 11.5 86 8 11 1973-08-11
## 104 44 192 11.5 86 8 12 1973-08-12
## 105 28 273 11.5 82 8 13 1973-08-13
## 106 65 157 9.7 80 8 14 1973-08-14
## 107 NA 64 11.5 79 8 15 1973-08-15
## 108 22 71 10.3 77 8 16 1973-08-16
## 109 59 51 6.3 79 8 17 1973-08-17
## 110 23 115 7.4 76 8 18 1973-08-18
## 111 31 244 10.9 78 8 19 1973-08-19
## 112 44 190 10.3 78 8 20 1973-08-20
## 113 21 259 15.5 77 8 21 1973-08-21
## 114 9 36 14.3 72 8 22 1973-08-22
## 115 NA 255 12.6 75 8 23 1973-08-23
## 116 45 212 9.7 79 8 24 1973-08-24
## 117 168 238 3.4 81 8 25 1973-08-25
## 118 73 215 8.0 86 8 26 1973-08-26
## 119 NA 153 5.7 88 8 27 1973-08-27
## 120 76 203 9.7 97 8 28 1973-08-28
## 121 118 225 2.3 94 8 29 1973-08-29
## 122 84 237 6.3 96 8 30 1973-08-30
## 123 85 188 6.3 94 8 31 1973-08-31
## 124 96 167 6.9 91 9 1 1973-09-01
## 125 78 197 5.1 92 9 2 1973-09-02
## 126 73 183 2.8 93 9 3 1973-09-03
## 127 91 189 4.6 93 9 4 1973-09-04
## 128 47 95 7.4 87 9 5 1973-09-05
## 129 32 92 15.5 84 9 6 1973-09-06
## 130 20 252 10.9 80 9 7 1973-09-07
## 131 23 220 10.3 78 9 8 1973-09-08
## 132 21 230 10.9 75 9 9 1973-09-09
## 133 24 259 9.7 73 9 10 1973-09-10
## 134 44 236 14.9 81 9 11 1973-09-11
## 135 21 259 15.5 76 9 12 1973-09-12
## 136 28 238 6.3 77 9 13 1973-09-13
## 137 9 24 10.9 71 9 14 1973-09-14
## 138 13 112 11.5 71 9 15 1973-09-15
## 139 46 237 6.9 78 9 16 1973-09-16
## 140 18 224 13.8 67 9 17 1973-09-17
## 141 13 27 10.3 76 9 18 1973-09-18
## 142 24 238 10.3 68 9 19 1973-09-19
## 143 16 201 8.0 82 9 20 1973-09-20
## 144 13 238 12.6 64 9 21 1973-09-21
## 145 23 14 9.2 71 9 22 1973-09-22
## 146 36 139 10.3 81 9 23 1973-09-23
## 147 7 49 10.3 69 9 24 1973-09-24
## 148 14 20 16.6 63 9 25 1973-09-25
## 149 30 193 6.9 70 9 26 1973-09-26
## 150 NA 145 13.2 77 9 27 1973-09-27
## 151 14 191 14.3 75 9 28 1973-09-28
## 152 18 131 8.0 76 9 29 1973-09-29
## 153 20 223 11.5 68 9 30 1973-09-30
Repaso: empezando a trastear datos
Scripts usados:
1. ¿Cómo cargarías los datos sabiendo su nombre y el paquete en el que está?
Nuestros datos se llaman swiss y son del paquete {datasets}, así que lo primero que debemos hacer es instalar el paquete (en caso de no haberlo hecho aún, con install.packages("datasets")), después llamar a ese paquete (tenemos el libro comprado y lo sacamos de la estantería) con library(datasets) y escribir el nombre del conjunto de datos para mostrarlo.
library(datasets)
swiss## Fertility Agriculture Examination Education Catholic
## Courtelary 80.2 17.0 15 12 9.96
## Delemont 83.1 45.1 6 9 84.84
## Franches-Mnt 92.5 39.7 5 5 93.40
## Moutier 85.8 36.5 12 7 33.77
## Neuveville 76.9 43.5 17 15 5.16
## Porrentruy 76.1 35.3 9 7 90.57
## Broye 83.8 70.2 16 7 92.85
## Glane 92.4 67.8 14 8 97.16
## Gruyere 82.4 53.3 12 7 97.67
## Sarine 82.9 45.2 16 13 91.38
## Veveyse 87.1 64.5 14 6 98.61
## Aigle 64.1 62.0 21 12 8.52
## Aubonne 66.9 67.5 14 7 2.27
## Avenches 68.9 60.7 19 12 4.43
## Cossonay 61.7 69.3 22 5 2.82
## Echallens 68.3 72.6 18 2 24.20
## Grandson 71.7 34.0 17 8 3.30
## Lausanne 55.7 19.4 26 28 12.11
## La Vallee 54.3 15.2 31 20 2.15
## Lavaux 65.1 73.0 19 9 2.84
## Morges 65.5 59.8 22 10 5.23
## Moudon 65.0 55.1 14 3 4.52
## Nyone 56.6 50.9 22 12 15.14
## Orbe 57.4 54.1 20 6 4.20
## Oron 72.5 71.2 12 1 2.40
## Payerne 74.2 58.1 14 8 5.23
## Paysd'enhaut 72.0 63.5 6 3 2.56
## Rolle 60.5 60.8 16 10 7.72
## Vevey 58.3 26.8 25 19 18.46
## Yverdon 65.4 49.5 15 8 6.10
## Conthey 75.5 85.9 3 2 99.71
## Entremont 69.3 84.9 7 6 99.68
## Herens 77.3 89.7 5 2 100.00
## Martigwy 70.5 78.2 12 6 98.96
## Monthey 79.4 64.9 7 3 98.22
## St Maurice 65.0 75.9 9 9 99.06
## Sierre 92.2 84.6 3 3 99.46
## Sion 79.3 63.1 13 13 96.83
## Boudry 70.4 38.4 26 12 5.62
## La Chauxdfnd 65.7 7.7 29 11 13.79
## Le Locle 72.7 16.7 22 13 11.22
## Neuchatel 64.4 17.6 35 32 16.92
## Val de Ruz 77.6 37.6 15 7 4.97
## ValdeTravers 67.6 18.7 25 7 8.65
## V. De Geneve 35.0 1.2 37 53 42.34
## Rive Droite 44.7 46.6 16 29 50.43
## Rive Gauche 42.8 27.7 22 29 58.33
## Infant.Mortality
## Courtelary 22.2
## Delemont 22.2
## Franches-Mnt 20.2
## Moutier 20.3
## Neuveville 20.6
## Porrentruy 26.6
## Broye 23.6
## Glane 24.9
## Gruyere 21.0
## Sarine 24.4
## Veveyse 24.5
## Aigle 16.5
## Aubonne 19.1
## Avenches 22.7
## Cossonay 18.7
## Echallens 21.2
## Grandson 20.0
## Lausanne 20.2
## La Vallee 10.8
## Lavaux 20.0
## Morges 18.0
## Moudon 22.4
## Nyone 16.7
## Orbe 15.3
## Oron 21.0
## Payerne 23.8
## Paysd'enhaut 18.0
## Rolle 16.3
## Vevey 20.9
## Yverdon 22.5
## Conthey 15.1
## Entremont 19.8
## Herens 18.3
## Martigwy 19.4
## Monthey 20.2
## St Maurice 17.8
## Sierre 16.3
## Sion 18.1
## Boudry 20.3
## La Chauxdfnd 20.5
## Le Locle 18.9
## Neuchatel 23.0
## Val de Ruz 20.0
## ValdeTravers 19.5
## V. De Geneve 18.0
## Rive Droite 18.2
## Rive Gauche 19.3Podríamos no pedirle el libro entero sino solo esa página, de ese conjunto de datos, usando datasets::swiss (sin hacer uso del library() previo).
datasets::swiss
2. Tenemos los datos guardados en swiss, ¿qué tipo de objeto es?
Al mostrarlos ya lo habrás intuido pero nuestro conjunto swiss es de tipo data.frame. Para comprobarlo podemos usar la función class().
class(swiss)## [1] "data.frame"Si somos un poco observadores/as vemos que todas las variables parecen numéricas así que…podríamos tener una matriz de números. ¿Cómo convertimos los datos a una matriz?
as.matrix(swiss)## Fertility Agriculture Examination Education Catholic
## Courtelary 80.2 17.0 15 12 9.96
## Delemont 83.1 45.1 6 9 84.84
## Franches-Mnt 92.5 39.7 5 5 93.40
## Moutier 85.8 36.5 12 7 33.77
## Neuveville 76.9 43.5 17 15 5.16
## Porrentruy 76.1 35.3 9 7 90.57
## Broye 83.8 70.2 16 7 92.85
## Glane 92.4 67.8 14 8 97.16
## Gruyere 82.4 53.3 12 7 97.67
## Sarine 82.9 45.2 16 13 91.38
## Veveyse 87.1 64.5 14 6 98.61
## Aigle 64.1 62.0 21 12 8.52
## Aubonne 66.9 67.5 14 7 2.27
## Avenches 68.9 60.7 19 12 4.43
## Cossonay 61.7 69.3 22 5 2.82
## Echallens 68.3 72.6 18 2 24.20
## Grandson 71.7 34.0 17 8 3.30
## Lausanne 55.7 19.4 26 28 12.11
## La Vallee 54.3 15.2 31 20 2.15
## Lavaux 65.1 73.0 19 9 2.84
## Morges 65.5 59.8 22 10 5.23
## Moudon 65.0 55.1 14 3 4.52
## Nyone 56.6 50.9 22 12 15.14
## Orbe 57.4 54.1 20 6 4.20
## Oron 72.5 71.2 12 1 2.40
## Payerne 74.2 58.1 14 8 5.23
## Paysd'enhaut 72.0 63.5 6 3 2.56
## Rolle 60.5 60.8 16 10 7.72
## Vevey 58.3 26.8 25 19 18.46
## Yverdon 65.4 49.5 15 8 6.10
## Conthey 75.5 85.9 3 2 99.71
## Entremont 69.3 84.9 7 6 99.68
## Herens 77.3 89.7 5 2 100.00
## Martigwy 70.5 78.2 12 6 98.96
## Monthey 79.4 64.9 7 3 98.22
## St Maurice 65.0 75.9 9 9 99.06
## Sierre 92.2 84.6 3 3 99.46
## Sion 79.3 63.1 13 13 96.83
## Boudry 70.4 38.4 26 12 5.62
## La Chauxdfnd 65.7 7.7 29 11 13.79
## Le Locle 72.7 16.7 22 13 11.22
## Neuchatel 64.4 17.6 35 32 16.92
## Val de Ruz 77.6 37.6 15 7 4.97
## ValdeTravers 67.6 18.7 25 7 8.65
## V. De Geneve 35.0 1.2 37 53 42.34
## Rive Droite 44.7 46.6 16 29 50.43
## Rive Gauche 42.8 27.7 22 29 58.33
## Infant.Mortality
## Courtelary 22.2
## Delemont 22.2
## Franches-Mnt 20.2
## Moutier 20.3
## Neuveville 20.6
## Porrentruy 26.6
## Broye 23.6
## Glane 24.9
## Gruyere 21.0
## Sarine 24.4
## Veveyse 24.5
## Aigle 16.5
## Aubonne 19.1
## Avenches 22.7
## Cossonay 18.7
## Echallens 21.2
## Grandson 20.0
## Lausanne 20.2
## La Vallee 10.8
## Lavaux 20.0
## Morges 18.0
## Moudon 22.4
## Nyone 16.7
## Orbe 15.3
## Oron 21.0
## Payerne 23.8
## Paysd'enhaut 18.0
## Rolle 16.3
## Vevey 20.9
## Yverdon 22.5
## Conthey 15.1
## Entremont 19.8
## Herens 18.3
## Martigwy 19.4
## Monthey 20.2
## St Maurice 17.8
## Sierre 16.3
## Sion 18.1
## Boudry 20.3
## La Chauxdfnd 20.5
## Le Locle 18.9
## Neuchatel 23.0
## Val de Ruz 20.0
## ValdeTravers 19.5
## V. De Geneve 18.0
## Rive Droite 18.2
## Rive Gauche 19.3## [1] "matrix"
3. ¿Cómo podríamos tener una descripción detallada de los datos?
La forma más inmediata es hacerlo es con la función ? swiss, que nos permite ver la documentación en el panel de ayuda.
? swissTambién podemos ver el nombre de las columnas con names() y el nombre de las filas con row.names()
names(swiss)## [1] "Fertility" "Agriculture" "Examination" "Education"
## [5] "Catholic" "Infant.Mortality"
row.names(swiss)## [1] "Courtelary" "Delemont" "Franches-Mnt" "Moutier" "Neuveville"
## [6] "Porrentruy" "Broye" "Glane" "Gruyere" "Sarine"
## [11] "Veveyse" "Aigle" "Aubonne" "Avenches" "Cossonay"
## [16] "Echallens" "Grandson" "Lausanne" "La Vallee" "Lavaux"
## [21] "Morges" "Moudon" "Nyone" "Orbe" "Oron"
## [26] "Payerne" "Paysd'enhaut" "Rolle" "Vevey" "Yverdon"
## [31] "Conthey" "Entremont" "Herens" "Martigwy" "Monthey"
## [36] "St Maurice" "Sierre" "Sion" "Boudry" "La Chauxdfnd"
## [41] "Le Locle" "Neuchatel" "Val de Ruz" "ValdeTravers" "V. De Geneve"
## [46] "Rive Droite" "Rive Gauche"Los datos representan algunos indicadores de fertilidad y socioeconómicos (estandarizados, entre 0 y 100) de las 47 provincias francoparlantes de Suiza, con datos del año 1888. Como podemos leer en la ayuda, en la web https://opr.princeton.edu/archive/pefp/switz.aspx tenemos los datos de 182 distritos para dicho año.
4. ¿Cómo podríamos «ver» los datos? ¿Cuántas provincias hay incluidas? ¿Cuántas variables han sido medidas en cada una de ellas?
Podemos hacerlo de varias maneras, y una de ellas es pedirle una cabecera de la tabla (las primeras filas) con head().
head(swiss)## Fertility Agriculture Examination Education Catholic
## Courtelary 80.2 17.0 15 12 9.96
## Delemont 83.1 45.1 6 9 84.84
## Franches-Mnt 92.5 39.7 5 5 93.40
## Moutier 85.8 36.5 12 7 33.77
## Neuveville 76.9 43.5 17 15 5.16
## Porrentruy 76.1 35.3 9 7 90.57
## Infant.Mortality
## Courtelary 22.2
## Delemont 22.2
## Franches-Mnt 20.2
## Moutier 20.3
## Neuveville 20.6
## Porrentruy 26.6También podemos ver una versión «excelizada» de los datos con `View()
View(swiss)Para ver las dimensiones de los datos podemos recurrir a dim() (nos dará un vector de longitud 2 con el número de filas y columnas) o a nrow() y ncol()
dim(swiss)## [1] 47 6
nrow(swiss)## [1] 47
ncol(swiss)## [1] 6
5. ¿Cómo podríamos definir una nueva variable de tipo texto con los nombres de filas que obtenemos de row.names()?
La función row.names() nos devuelve los nombres de las filas, que vamos a guardar en una variable (por ejemplo, en nombres).
nombres <- row.names(swiss)
nombres## [1] "Courtelary" "Delemont" "Franches-Mnt" "Moutier" "Neuveville"
## [6] "Porrentruy" "Broye" "Glane" "Gruyere" "Sarine"
## [11] "Veveyse" "Aigle" "Aubonne" "Avenches" "Cossonay"
## [16] "Echallens" "Grandson" "Lausanne" "La Vallee" "Lavaux"
## [21] "Morges" "Moudon" "Nyone" "Orbe" "Oron"
## [26] "Payerne" "Paysd'enhaut" "Rolle" "Vevey" "Yverdon"
## [31] "Conthey" "Entremont" "Herens" "Martigwy" "Monthey"
## [36] "St Maurice" "Sierre" "Sion" "Boudry" "La Chauxdfnd"
## [41] "Le Locle" "Neuchatel" "Val de Ruz" "ValdeTravers" "V. De Geneve"
## [46] "Rive Droite" "Rive Gauche"Estructuras condicionales
Scripts usados:
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: modifica el código inferior para imprimir un mensaje por pantalla si todos los datos del conjunto
airquality son de meses que no sean enero.
library(datasets) # paquete con los adtos
mes <- airquality$Month
if (mes == 2) {
print("Ningún dato es del mes de enero")
}- Solución:
library(datasets) # paquete con los datos
mes <- airquality$Month
if (all(mes != 1)) { # todos con mes distinto de 1
print("Ningún dato es del mes de enero")
}## [1] "Ningún dato es del mes de enero"
📝Ejercicio 2: modifica el código inferior para imprimir un mensaje por pantalla si alguno de los registros tiene una temperatura mayor a 90 (Farenheit).
temperatura <- airquality$Temp
if (temperatura == 100) {
print("Alguno de los registros tiene temperatura superior a 90 Farenheit")
}- Solución:
temperatura <- airquality$Temp
if (any(temperatura > 90)) {
print("Alguno de los registros tiene temperatura superior a 90 Farenheit")
}## [1] "Alguno de los registros tiene temperatura superior a 90 Farenheit"
📝Ejercicio 3: modifica el código inferior para imprimir un mensaje por pantalla si alguno de los días supera la temperatura de 100.
temperatura <- airquality$Temp
if (all(temperatura < 50)) {
print("Alguno de los registros tiene temperatura superior a 100 Farenheit")
}- Solución:
temperatura <- airquality$Temp
if (any(temperatura > 100)) { # nos basta con uno
print("Alguno de los registros tiene temperatura superior a 100 Farenheit")
}No imprime nada porque ninguno cumple la condición.
📝Ejercicio 4: del paquete lubridate, la función
hour() nos devuelve la hora de una fecha dada, y la función now() nos devuelve fecha y hora del momento actual. Con ambas funciones, y usando if, imprime por pantalla "buenas noches" solo a partir de las 21 horas.
- Solución:
📝Ejercicio 5: con las funciones del ejercicio anterior, y usando una estructura
if-else, imprime por pantalla "buenos días" (de 6 a 14 horas), "buenas tardes" (de 14 a 21 horas) o "buenas noches" (de las 21 a las 6 horas).
- Solución:
# Fecha actual
fecha_actual <- now()
# Estructura if-else
if (hour(fecha_actual) > 6 & hour(fecha_actual) < 14) {
cat("Buenos días")
} else if (hour(fecha_actual) > 14 & hour(fecha_actual) < 21) {
cat("Buenas tardes")
} else {
cat("Buenas noches")
}## Buenas noches
📝Ejercicio 6: realiza el ejercicio anterior pero sin estructura de llaves, de forma concisa con
ifelse(). Mira la ayuda si la necesitases poniendo ? ifelse.
- Solución:
# Fecha actual
fecha_actual <- now()
# Estructura if-else
cat(ifelse(hour(fecha_actual) > 6 & hour(fecha_actual) < 14,
"Buenos días",
ifelse(hour(fecha_actual) > 14 &
hour(fecha_actual) < 21,
"Buenas tardes", "Buenas noches")))## Buenas noches
Bucles
Scripts usados:
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: modifica el código interior para diseñar un bucle
for de 5 iteraciones que recorra los 5 primeros impares y les sume uno.
for (i in 1:5) {
print(i)
}## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5- Solución:
## [1] 2
## [1] 4
## [1] 6
## [1] 8
## [1] 10## [1] 2
## [1] 4
## [1] 6
## [1] 8
## [1] 10
📝Ejercicio 2: modifica el código interior para diseñar un bucle
while que parta con una variable conteo <- 1 y pare cuando llegue a 6.
conteo <- 1
while (conteo == 2) {
print(conteo)
}- Solución:
conteo <- 1
while (conteo < 6) {
print(conteo)
conteo <- conteo <- conteo + 1
}## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5
📝Ejercicio 3: construye un bucle que recorra las primeras 8 filas del conjunto de datos
MASS::mammals y que imprima el peso del animal (en kg) multiplicado por 1000 (gramos).
- Solución:
## [1] 3385
## [1] 480
## [1] 1350
## [1] 465000
## [1] 36330
## [1] 27660
## [1] 14830
## [1] 1040
📝Ejercicio 4: diseña un bucle
for de 200 iteraciones que, empezando en un valor inicial de 100 (euros), te sume 3€ si el número actual es par y te reste 5€ si es impar.
Un número par o impar: un número par será todo aquel número que al dividir entre 2, la división es exacta, es decir, que su resto es nulo. Por ejemplo, al dividir 5 entre 2, el resto es 1, pero al dividir 12 entre 2 el resto es 0. Para calcula ese resto usaremos la función %%.
5 %% 2## [1] 1
12 %% 2## [1] 0
23 %% 2## [1] 1
46 %% 2## [1] 0- Solución:
# dinero inicial
dinero <- 100
# Bucle for
for (i in 1:200) {
dinero <- ifelse(dinero %% 2 == 0, dinero + 3, dinero - 5)
}
dinero## [1] -100
📝Ejercicio 5: diseña el anterior bucle pero guardando el dinero de cada iteración.
- Solución:
# vector de importes
dinero <- rep(0, 201)
dinero[1] <- 100 # dinero inicial
# Bucle for
for (i in 2:201) {
# si dinero[i - 1] es par o impar
dinero[i] <- ifelse(dinero[i - 1] %% 2 == 0, dinero[i - 1] + 3,
dinero[i - 1] - 5)
}
dinero## [1] 100 103 98 101 96 99 94 97 92 95 90 93 88 91 86
## [16] 89 84 87 82 85 80 83 78 81 76 79 74 77 72 75
## [31] 70 73 68 71 66 69 64 67 62 65 60 63 58 61 56
## [46] 59 54 57 52 55 50 53 48 51 46 49 44 47 42 45
## [61] 40 43 38 41 36 39 34 37 32 35 30 33 28 31 26
## [76] 29 24 27 22 25 20 23 18 21 16 19 14 17 12 15
## [91] 10 13 8 11 6 9 4 7 2 5 0 3 -2 1 -4
## [106] -1 -6 -3 -8 -5 -10 -7 -12 -9 -14 -11 -16 -13 -18 -15
## [121] -20 -17 -22 -19 -24 -21 -26 -23 -28 -25 -30 -27 -32 -29 -34
## [136] -31 -36 -33 -38 -35 -40 -37 -42 -39 -44 -41 -46 -43 -48 -45
## [151] -50 -47 -52 -49 -54 -51 -56 -53 -58 -55 -60 -57 -62 -59 -64
## [166] -61 -66 -63 -68 -65 -70 -67 -72 -69 -74 -71 -76 -73 -78 -75
## [181] -80 -77 -82 -79 -84 -81 -86 -83 -88 -85 -90 -87 -92 -89 -94
## [196] -91 -96 -93 -98 -95 -100
📝Ejercicio 6: diseña el bucle del ejercicio 4 parando cuando no nos quede dinero.
- Solución:
dinero <- 100 # dinero inicial
# Bucle while
while (dinero > 0) {
dinero <- ifelse(dinero %% 2 == 0, dinero + 3, dinero - 5)
}
dinero## [1] 0Funciones
Scripts usados:
(haz click en las flechas para ver soluciones)
Ejercicio 1: modifica el código inferior para definir una función llamada
funcion_suma, de forma que dados dos elementos, devuelve su suma.
# Definimos función
nombre <- function(x, y) {
# Sumamos
suma <- # código a ejecutar
# ¿Qué devolvemos?
return()
}
# Aplicamos la función
suma(3, 7)- Solución:
# Definimos función
funcion_suma <- function(x, y) {
# Sumamos
suma <- x + y
# Devolvemos la salida
return(suma)
}
# Aplicamos la función
funcion_suma(3, 7)## [1] 10&nsbp;
Ejercicio 2: modifica el código inferior para definir una función llamada
funcion_producto, de forma que dados dos elementos, devuelve su producto.
# Definimos función
nombre <- function(x, y) {
# Multiplicamos
producto <- # código de la multiplicación
# ¿Qué devolvemos?
return()
}
# Aplicamos la función
producto(3, -7)- Solución:
# Definimos función
funcion_producto <- function(x, y) {
# Multiplicamos
producto <- x * y
# Devolvemos la salida
return(producto)
}
# Aplicamos la función
funcion_producto(3, -7)## [1] -21
Ejercicio 3: modifica el código inferior para definir una función llamada
funcion_producto, de forma que dados dos elementos, devuelve su producto, pero que por defecto calcule el cuadrado (es decir, por defecto un solo argumento, y el resultado sea el número por sí mismo)
# Definimos función
nombre <- function(x, y) {
# Multiplicamos
producto <- # código de la multiplicación
# ¿Qué devolvemos?
return()
}
# Aplicamos la función solo con un argumento
producto(3)
# Aplicamos la función con dos argumentos
producto(3, -7)- Solución:
# Definimos función
funcion_producto <- function(x, y = x) {
# Multiplicamos
producto <- x * y
# Devolvemos la salida
return(producto)
}
# Aplicamos la función
funcion_producto(3) # por defecto x = 3, y = 3## [1] 9
funcion_producto(3, -7)## [1] -21
Ejercicio 4: define una función llamada
igualdad_nombres que, dados dos nombres persona_1 e persona_2, nos diga si son iguales o no. Hazlo considerando importantes las mayúsculas, y sin que importen las mayúsculas. Recuerda que con toupper() podemos pasar todo un texto a mayúscula.
- Solución:
# Distinguiendo mayúsculas
igualdad_nombres <- function(persona_1, persona_2) {
return(persona_1 == persona_2)
}
igualdad_nombres("Javi", "javi")## [1] FALSE
igualdad_nombres("Javi", "Lucía")## [1] FALSE
# Sin importar mayúsculas
igualdad_nombres <- function(persona_1, persona_2) {
return(toupper(persona_1) == toupper(persona_2))
}
igualdad_nombres("Javi", "javi")## [1] TRUE
igualdad_nombres("Javi", "Lucía")## [1] FALSE
Ejercicio 5: define una función llamada
pares que, dados dos números x e y, nos diga si la suma de ambos es par o no.
Recuerda que con %% podemos obtener el resto de un número al dividir entre 2.
2 %% 2 # par, resto 0## [1] 0
3 %% 2 # impar, resto 1## [1] 1- Solución:
# Definimos función
pares <- function(x, y) {
# Sumamos
suma <- x + y
# Comprobamos si es par
par <- suma %% 2 == 0
# Devolvemos la salida
return(par)
}
# Aplicamos la función
pares(1, 3) # suma 4 (par)## [1] TRUE
pares(2, 7) # suma 9 (impar)## [1] FALSE
Ejercicio 6: define una función llamada
pasar_a_celsius que, dada una temperatura \(x\) en Fahrenheit, la convierta a grados Celsius (\(ºC = (ºF - 32) * \frac{5}{9}\)). Aplica la función a la columna Temp del conjunto airquality, e incorpórala al fichero en una nueva columna Temp_Celsius.
- Solución:
# Definimos función
pasar_a_celsius <- function(x) {
# Temperatura en Celsius
x_celsius <- (x - 32) * (5 / 9)
# Devolvemos la salida
return(x_celsius)
}
# Aplicamos la función
pasar_a_celsius(0)## [1] -17.77778
pasar_a_celsius(80)## [1] 26.66667
# Aplicamos
data.frame(airquality,
"Temp_Celsius" = pasar_a_celsius(airquality$Temp))## Ozone Solar.R Wind Temp Month Day Temp_Celsius
## 1 41 190 7.4 67 5 1 19.44444
## 2 36 118 8.0 72 5 2 22.22222
## 3 12 149 12.6 74 5 3 23.33333
## 4 18 313 11.5 62 5 4 16.66667
## 5 NA NA 14.3 56 5 5 13.33333
## 6 28 NA 14.9 66 5 6 18.88889
## 7 23 299 8.6 65 5 7 18.33333
## 8 19 99 13.8 59 5 8 15.00000
## 9 8 19 20.1 61 5 9 16.11111
## 10 NA 194 8.6 69 5 10 20.55556
## 11 7 NA 6.9 74 5 11 23.33333
## 12 16 256 9.7 69 5 12 20.55556
## 13 11 290 9.2 66 5 13 18.88889
## 14 14 274 10.9 68 5 14 20.00000
## 15 18 65 13.2 58 5 15 14.44444
## 16 14 334 11.5 64 5 16 17.77778
## 17 34 307 12.0 66 5 17 18.88889
## 18 6 78 18.4 57 5 18 13.88889
## 19 30 322 11.5 68 5 19 20.00000
## 20 11 44 9.7 62 5 20 16.66667
## 21 1 8 9.7 59 5 21 15.00000
## 22 11 320 16.6 73 5 22 22.77778
## 23 4 25 9.7 61 5 23 16.11111
## 24 32 92 12.0 61 5 24 16.11111
## 25 NA 66 16.6 57 5 25 13.88889
## 26 NA 266 14.9 58 5 26 14.44444
## 27 NA NA 8.0 57 5 27 13.88889
## 28 23 13 12.0 67 5 28 19.44444
## 29 45 252 14.9 81 5 29 27.22222
## 30 115 223 5.7 79 5 30 26.11111
## 31 37 279 7.4 76 5 31 24.44444
## 32 NA 286 8.6 78 6 1 25.55556
## 33 NA 287 9.7 74 6 2 23.33333
## 34 NA 242 16.1 67 6 3 19.44444
## 35 NA 186 9.2 84 6 4 28.88889
## 36 NA 220 8.6 85 6 5 29.44444
## 37 NA 264 14.3 79 6 6 26.11111
## 38 29 127 9.7 82 6 7 27.77778
## 39 NA 273 6.9 87 6 8 30.55556
## 40 71 291 13.8 90 6 9 32.22222
## 41 39 323 11.5 87 6 10 30.55556
## 42 NA 259 10.9 93 6 11 33.88889
## 43 NA 250 9.2 92 6 12 33.33333
## 44 23 148 8.0 82 6 13 27.77778
## 45 NA 332 13.8 80 6 14 26.66667
## 46 NA 322 11.5 79 6 15 26.11111
## 47 21 191 14.9 77 6 16 25.00000
## 48 37 284 20.7 72 6 17 22.22222
## 49 20 37 9.2 65 6 18 18.33333
## 50 12 120 11.5 73 6 19 22.77778
## 51 13 137 10.3 76 6 20 24.44444
## 52 NA 150 6.3 77 6 21 25.00000
## 53 NA 59 1.7 76 6 22 24.44444
## 54 NA 91 4.6 76 6 23 24.44444
## 55 NA 250 6.3 76 6 24 24.44444
## 56 NA 135 8.0 75 6 25 23.88889
## 57 NA 127 8.0 78 6 26 25.55556
## 58 NA 47 10.3 73 6 27 22.77778
## 59 NA 98 11.5 80 6 28 26.66667
## 60 NA 31 14.9 77 6 29 25.00000
## 61 NA 138 8.0 83 6 30 28.33333
## 62 135 269 4.1 84 7 1 28.88889
## 63 49 248 9.2 85 7 2 29.44444
## 64 32 236 9.2 81 7 3 27.22222
## 65 NA 101 10.9 84 7 4 28.88889
## 66 64 175 4.6 83 7 5 28.33333
## 67 40 314 10.9 83 7 6 28.33333
## 68 77 276 5.1 88 7 7 31.11111
## 69 97 267 6.3 92 7 8 33.33333
## 70 97 272 5.7 92 7 9 33.33333
## 71 85 175 7.4 89 7 10 31.66667
## 72 NA 139 8.6 82 7 11 27.77778
## 73 10 264 14.3 73 7 12 22.77778
## 74 27 175 14.9 81 7 13 27.22222
## 75 NA 291 14.9 91 7 14 32.77778
## 76 7 48 14.3 80 7 15 26.66667
## 77 48 260 6.9 81 7 16 27.22222
## 78 35 274 10.3 82 7 17 27.77778
## 79 61 285 6.3 84 7 18 28.88889
## 80 79 187 5.1 87 7 19 30.55556
## 81 63 220 11.5 85 7 20 29.44444
## 82 16 7 6.9 74 7 21 23.33333
## 83 NA 258 9.7 81 7 22 27.22222
## 84 NA 295 11.5 82 7 23 27.77778
## 85 80 294 8.6 86 7 24 30.00000
## 86 108 223 8.0 85 7 25 29.44444
## 87 20 81 8.6 82 7 26 27.77778
## 88 52 82 12.0 86 7 27 30.00000
## 89 82 213 7.4 88 7 28 31.11111
## 90 50 275 7.4 86 7 29 30.00000
## 91 64 253 7.4 83 7 30 28.33333
## 92 59 254 9.2 81 7 31 27.22222
## 93 39 83 6.9 81 8 1 27.22222
## 94 9 24 13.8 81 8 2 27.22222
## 95 16 77 7.4 82 8 3 27.77778
## 96 78 NA 6.9 86 8 4 30.00000
## 97 35 NA 7.4 85 8 5 29.44444
## 98 66 NA 4.6 87 8 6 30.55556
## 99 122 255 4.0 89 8 7 31.66667
## 100 89 229 10.3 90 8 8 32.22222
## 101 110 207 8.0 90 8 9 32.22222
## 102 NA 222 8.6 92 8 10 33.33333
## 103 NA 137 11.5 86 8 11 30.00000
## 104 44 192 11.5 86 8 12 30.00000
## 105 28 273 11.5 82 8 13 27.77778
## 106 65 157 9.7 80 8 14 26.66667
## 107 NA 64 11.5 79 8 15 26.11111
## 108 22 71 10.3 77 8 16 25.00000
## 109 59 51 6.3 79 8 17 26.11111
## 110 23 115 7.4 76 8 18 24.44444
## 111 31 244 10.9 78 8 19 25.55556
## 112 44 190 10.3 78 8 20 25.55556
## 113 21 259 15.5 77 8 21 25.00000
## 114 9 36 14.3 72 8 22 22.22222
## 115 NA 255 12.6 75 8 23 23.88889
## 116 45 212 9.7 79 8 24 26.11111
## 117 168 238 3.4 81 8 25 27.22222
## 118 73 215 8.0 86 8 26 30.00000
## 119 NA 153 5.7 88 8 27 31.11111
## 120 76 203 9.7 97 8 28 36.11111
## 121 118 225 2.3 94 8 29 34.44444
## 122 84 237 6.3 96 8 30 35.55556
## 123 85 188 6.3 94 8 31 34.44444
## 124 96 167 6.9 91 9 1 32.77778
## 125 78 197 5.1 92 9 2 33.33333
## 126 73 183 2.8 93 9 3 33.88889
## 127 91 189 4.6 93 9 4 33.88889
## 128 47 95 7.4 87 9 5 30.55556
## 129 32 92 15.5 84 9 6 28.88889
## 130 20 252 10.9 80 9 7 26.66667
## 131 23 220 10.3 78 9 8 25.55556
## 132 21 230 10.9 75 9 9 23.88889
## 133 24 259 9.7 73 9 10 22.77778
## 134 44 236 14.9 81 9 11 27.22222
## 135 21 259 15.5 76 9 12 24.44444
## 136 28 238 6.3 77 9 13 25.00000
## 137 9 24 10.9 71 9 14 21.66667
## 138 13 112 11.5 71 9 15 21.66667
## 139 46 237 6.9 78 9 16 25.55556
## 140 18 224 13.8 67 9 17 19.44444
## 141 13 27 10.3 76 9 18 24.44444
## 142 24 238 10.3 68 9 19 20.00000
## 143 16 201 8.0 82 9 20 27.77778
## 144 13 238 12.6 64 9 21 17.77778
## 145 23 14 9.2 71 9 22 21.66667
## 146 36 139 10.3 81 9 23 27.22222
## 147 7 49 10.3 69 9 24 20.55556
## 148 14 20 16.6 63 9 25 17.22222
## 149 30 193 6.9 70 9 26 21.11111
## 150 NA 145 13.2 77 9 27 25.00000
## 151 14 191 14.3 75 9 28 23.88889
## 152 18 131 8.0 76 9 29 24.44444
## 153 20 223 11.5 68 9 30 20.00000
Listas
Scripts usados:
Ejercicio 1: define una lista de 4 elementos de tipos distintos y accede al segundo de ellos (yo incluiré uno que sea un
data.frame para que veas que en una lista cabe de todo).
- Solución:
# Ejemplo: lista con texto, numérico, lógico y un data.frame
lista_ejemplo <- list("nombre" = "Javier", "cp" = 28019,
"soltero" = TRUE,
"notas" = data.frame("mates" = c(7.5, 8, 9),
"lengua" = c(10, 5, 6)))
lista_ejemplo## $nombre
## [1] "Javier"
##
## $cp
## [1] 28019
##
## $soltero
## [1] TRUE
##
## $notas
## mates lengua
## 1 7.5 10
## 2 8.0 5
## 3 9.0 6
# Longitud
length(lista_ejemplo)## [1] 4
# Accedemos al elemento dos
lista_ejemplo[[2]]## [1] 28019
Ejercicio 2: accede a los elementos que ocupan los lugares 1 y 4 de la lista definida anteriormente.
- Solución:
# Accedemos al 1 y al 4
lista_ejemplo[c(1, 4)]## $nombre
## [1] "Javier"
##
## $notas
## mates lengua
## 1 7.5 10
## 2 8.0 5
## 3 9.0 6Otra opción es acceder con los nombres
# Accedemos al 1 y al 4
lista_ejemplo$nombre## [1] "Javier"
lista_ejemplo$notas## mates lengua
## 1 7.5 10
## 2 8.0 5
## 3 9.0 6
lista_ejemplo[c("nombre", "notas")]## $nombre
## [1] "Javier"
##
## $notas
## mates lengua
## 1 7.5 10
## 2 8.0 5
## 3 9.0 6
Ejercicio 3: define una lista de 4 elementos que contenga, en una sola variable, tu nombre, apellido, edad y si estás soltero/a.
- Solución:
library(lubridate)
# Creamos lista: con lubridate calculamos la diferencia de años desde la fecha de nuestro nacimiento hasta hoy (sea cuando sea hoy)
lista_personal <- list("nombre" = "Javier",
"apellidos" = "Álvarez Liébana",
"edad" = 32,
"soltero" = TRUE)
lista_personal## $nombre
## [1] "Javier"
##
## $apellidos
## [1] "Álvarez Liébana"
##
## $edad
## [1] 32
##
## $soltero
## [1] TRUETibble
Scripts usados:
- script15.R: datos tibble. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script15.R
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: ¿es el conjunto de datos
airquality (del paquete {datasets}) de tipo tibble?
- Solución:
Recuerda que podemos cargar elementos de un paquete (en este caso {datasets}) cargando library(datasets) y luego el elemento, o bien datasets::airquality (prefijo::nombre).
La respuesta: NO. Tienes muchas formas de comprobarlo si imprimes el conjunto por defecto.
library(datasets)
airquality## Ozone Solar.R Wind Temp Month Day
## 1 41 190 7.4 67 5 1
## 2 36 118 8.0 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6
## 7 23 299 8.6 65 5 7
## 8 19 99 13.8 59 5 8
## 9 8 19 20.1 61 5 9
## 10 NA 194 8.6 69 5 10
## 11 7 NA 6.9 74 5 11
## 12 16 256 9.7 69 5 12
## 13 11 290 9.2 66 5 13
## 14 14 274 10.9 68 5 14
## 15 18 65 13.2 58 5 15
## 16 14 334 11.5 64 5 16
## 17 34 307 12.0 66 5 17
## 18 6 78 18.4 57 5 18
## 19 30 322 11.5 68 5 19
## 20 11 44 9.7 62 5 20
## 21 1 8 9.7 59 5 21
## 22 11 320 16.6 73 5 22
## 23 4 25 9.7 61 5 23
## 24 32 92 12.0 61 5 24
## 25 NA 66 16.6 57 5 25
## 26 NA 266 14.9 58 5 26
## 27 NA NA 8.0 57 5 27
## 28 23 13 12.0 67 5 28
## 29 45 252 14.9 81 5 29
## 30 115 223 5.7 79 5 30
## 31 37 279 7.4 76 5 31
## 32 NA 286 8.6 78 6 1
## 33 NA 287 9.7 74 6 2
## 34 NA 242 16.1 67 6 3
## 35 NA 186 9.2 84 6 4
## 36 NA 220 8.6 85 6 5
## 37 NA 264 14.3 79 6 6
## 38 29 127 9.7 82 6 7
## 39 NA 273 6.9 87 6 8
## 40 71 291 13.8 90 6 9
## 41 39 323 11.5 87 6 10
## 42 NA 259 10.9 93 6 11
## 43 NA 250 9.2 92 6 12
## 44 23 148 8.0 82 6 13
## 45 NA 332 13.8 80 6 14
## 46 NA 322 11.5 79 6 15
## 47 21 191 14.9 77 6 16
## 48 37 284 20.7 72 6 17
## 49 20 37 9.2 65 6 18
## 50 12 120 11.5 73 6 19
## 51 13 137 10.3 76 6 20
## 52 NA 150 6.3 77 6 21
## 53 NA 59 1.7 76 6 22
## 54 NA 91 4.6 76 6 23
## 55 NA 250 6.3 76 6 24
## 56 NA 135 8.0 75 6 25
## 57 NA 127 8.0 78 6 26
## 58 NA 47 10.3 73 6 27
## 59 NA 98 11.5 80 6 28
## 60 NA 31 14.9 77 6 29
## 61 NA 138 8.0 83 6 30
## 62 135 269 4.1 84 7 1
## 63 49 248 9.2 85 7 2
## 64 32 236 9.2 81 7 3
## 65 NA 101 10.9 84 7 4
## 66 64 175 4.6 83 7 5
## 67 40 314 10.9 83 7 6
## 68 77 276 5.1 88 7 7
## 69 97 267 6.3 92 7 8
## 70 97 272 5.7 92 7 9
## 71 85 175 7.4 89 7 10
## 72 NA 139 8.6 82 7 11
## 73 10 264 14.3 73 7 12
## 74 27 175 14.9 81 7 13
## 75 NA 291 14.9 91 7 14
## 76 7 48 14.3 80 7 15
## 77 48 260 6.9 81 7 16
## 78 35 274 10.3 82 7 17
## 79 61 285 6.3 84 7 18
## 80 79 187 5.1 87 7 19
## 81 63 220 11.5 85 7 20
## 82 16 7 6.9 74 7 21
## 83 NA 258 9.7 81 7 22
## 84 NA 295 11.5 82 7 23
## 85 80 294 8.6 86 7 24
## 86 108 223 8.0 85 7 25
## 87 20 81 8.6 82 7 26
## 88 52 82 12.0 86 7 27
## 89 82 213 7.4 88 7 28
## 90 50 275 7.4 86 7 29
## 91 64 253 7.4 83 7 30
## 92 59 254 9.2 81 7 31
## 93 39 83 6.9 81 8 1
## 94 9 24 13.8 81 8 2
## 95 16 77 7.4 82 8 3
## 96 78 NA 6.9 86 8 4
## 97 35 NA 7.4 85 8 5
## 98 66 NA 4.6 87 8 6
## 99 122 255 4.0 89 8 7
## 100 89 229 10.3 90 8 8
## 101 110 207 8.0 90 8 9
## 102 NA 222 8.6 92 8 10
## 103 NA 137 11.5 86 8 11
## 104 44 192 11.5 86 8 12
## 105 28 273 11.5 82 8 13
## 106 65 157 9.7 80 8 14
## 107 NA 64 11.5 79 8 15
## 108 22 71 10.3 77 8 16
## 109 59 51 6.3 79 8 17
## 110 23 115 7.4 76 8 18
## 111 31 244 10.9 78 8 19
## 112 44 190 10.3 78 8 20
## 113 21 259 15.5 77 8 21
## 114 9 36 14.3 72 8 22
## 115 NA 255 12.6 75 8 23
## 116 45 212 9.7 79 8 24
## 117 168 238 3.4 81 8 25
## 118 73 215 8.0 86 8 26
## 119 NA 153 5.7 88 8 27
## 120 76 203 9.7 97 8 28
## 121 118 225 2.3 94 8 29
## 122 84 237 6.3 96 8 30
## 123 85 188 6.3 94 8 31
## 124 96 167 6.9 91 9 1
## 125 78 197 5.1 92 9 2
## 126 73 183 2.8 93 9 3
## 127 91 189 4.6 93 9 4
## 128 47 95 7.4 87 9 5
## 129 32 92 15.5 84 9 6
## 130 20 252 10.9 80 9 7
## 131 23 220 10.3 78 9 8
## 132 21 230 10.9 75 9 9
## 133 24 259 9.7 73 9 10
## 134 44 236 14.9 81 9 11
## 135 21 259 15.5 76 9 12
## 136 28 238 6.3 77 9 13
## 137 9 24 10.9 71 9 14
## 138 13 112 11.5 71 9 15
## 139 46 237 6.9 78 9 16
## 140 18 224 13.8 67 9 17
## 141 13 27 10.3 76 9 18
## 142 24 238 10.3 68 9 19
## 143 16 201 8.0 82 9 20
## 144 13 238 12.6 64 9 21
## 145 23 14 9.2 71 9 22
## 146 36 139 10.3 81 9 23
## 147 7 49 10.3 69 9 24
## 148 14 20 16.6 63 9 25
## 149 30 193 6.9 70 9 26
## 150 NA 145 13.2 77 9 27
## 151 14 191 14.3 75 9 28
## 152 18 131 8.0 76 9 29
## 153 20 223 11.5 68 9 30
class(airquality)## [1] "data.frame"- Imprime por defecto todas las filas (tiene 153 filas, debería imprimir solo 10 si fuese un tibble, para no saturar consola).
- No especifica al imprimir que es de tipo
tibble. - No especifica al imprimir el tipo de dato de las columnas.
- Imprime el nombre de las filas (el nombre de los modelos) como si fuera una variable (¡que no existe!).
📝Ejercicio 2: convierte el conjunto
airquality de data.frame a tibble.
- Solución:
Así debería de salir si fuera tibble.
## # A tibble: 153 × 6
## Ozone Solar.R Wind Temp Month Day
## <int> <int> <dbl> <int> <int> <int>
## 1 41 190 7.4 67 5 1
## 2 36 118 8 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6
## 7 23 299 8.6 65 5 7
## 8 19 99 13.8 59 5 8
## 9 8 19 20.1 61 5 9
## 10 NA 194 8.6 69 5 10
## # … with 143 more rows
class(airquality_tb)## [1] "tbl_df" "tbl" "data.frame"
📝Ejercicio 3: define un
tibble con tres variables numéricas a, b, c, tal que la tercera sea el producto de las dos primeras c = a * b. Inténtalo hacer con un data.frame
- Solución:
Un ejemplo:
tibble("a" = 1:7, "b" = 11:17, "c" = a * b)## # A tibble: 7 × 3
## a b c
## <int> <int> <int>
## 1 1 11 11
## 2 2 12 24
## 3 3 13 39
## 4 4 14 56
## 5 5 15 75
## 6 6 16 96
## 7 7 17 119Si lo intentamos con un data.frame, intentará buscar una variable real que tengamos guardada que se llame a y b, sin encontrarlas.
data.frame("a" = 1:7, "b" = 11:17, "c" = a * b)## a b c
## 1 1 11 -35
## 2 2 12 -35
## 3 3 13 -35
## 4 4 14 -35
## 5 5 15 -35
## 6 6 16 -35
## 7 7 17 -35
📝Ejercicio 4: define un
tibble con tres variables de nombres variable, 2, tercera :), e intenta acceder a ellas.
- Solución:
Las variables solo con caracteres del alfabeto se podrán acceder sin necesidad de comillas.
# Definimos el tibble
datos_tb <- tibble("variable" = 1:7, "tercera falsa :)" = 0,
"2" = 11:17)
# Accedemos a sus columnas
datos_tb$variable## [1] 1 2 3 4 5 6 7
datos_tb$`tercera falsa :)`## [1] 0 0 0 0 0 0 0
datos_tb$`2`## [1] 11 12 13 14 15 16 17También se puede acceder por el orden que ocupan:
datos_tb[1]## # A tibble: 7 × 1
## variable
## <int>
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7
datos_tb[2]## # A tibble: 7 × 1
## `tercera falsa :)`
## <dbl>
## 1 0
## 2 0
## 3 0
## 4 0
## 5 0
## 6 0
## 7 0
datos_tb[3]## # A tibble: 7 × 1
## `2`
## <int>
## 1 11
## 2 12
## 3 13
## 4 14
## 5 15
## 6 16
## 7 17Y también por el nombre entre corchetes (doble corchete extrae la variable fuera del tibble, corchete simple en formato tibble):
datos_tb["variable"]## # A tibble: 7 × 1
## variable
## <int>
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7
datos_tb[["variable"]]## [1] 1 2 3 4 5 6 7
datos_tb["tercera falsa :)"]## # A tibble: 7 × 1
## `tercera falsa :)`
## <dbl>
## 1 0
## 2 0
## 3 0
## 4 0
## 5 0
## 6 0
## 7 0
datos_tb["2"]## # A tibble: 7 × 1
## `2`
## <int>
## 1 11
## 2 12
## 3 13
## 4 14
## 5 15
## 6 16
## 7 17
📝Ejercicio 5: obten de los paquetes dplyr y gapminder los conjuntos de datos tibble
starwars y gapminder. Comprueba el número de variables, de registros e imprime los datos
- Solución:
## # A tibble: 87 × 14
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 Luke S… 172 77 blond fair blue 19 male mascu…
## 2 C-3PO 167 75 <NA> gold yellow 112 none mascu…
## 3 R2-D2 96 32 <NA> white, bl… red 33 none mascu…
## 4 Darth … 202 136 none white yellow 41.9 male mascu…
## 5 Leia O… 150 49 brown light brown 19 fema… femin…
## 6 Owen L… 178 120 brown, grey light blue 52 male mascu…
## 7 Beru W… 165 75 brown light blue 47 fema… femin…
## 8 R5-D4 97 32 <NA> white, red red NA none mascu…
## 9 Biggs … 183 84 black light brown 24 male mascu…
## 10 Obi-Wa… 182 77 auburn, wh… fair blue-gray 57 male mascu…
## # … with 77 more rows, and 5 more variables: homeworld <chr>, species <chr>,
## # films <list>, vehicles <list>, starships <list>
glimpse(starwars) # resumen de columnas## Rows: 87
## Columns: 14
## $ name <chr> "Luke Skywalker", "C-3PO", "R2-D2", "Darth Vader", "Leia Or…
## $ height <int> 172, 167, 96, 202, 150, 178, 165, 97, 183, 182, 188, 180, 2…
## $ mass <dbl> 77.0, 75.0, 32.0, 136.0, 49.0, 120.0, 75.0, 32.0, 84.0, 77.…
## $ hair_color <chr> "blond", NA, NA, "none", "brown", "brown, grey", "brown", N…
## $ skin_color <chr> "fair", "gold", "white, blue", "white", "light", "light", "…
## $ eye_color <chr> "blue", "yellow", "red", "yellow", "brown", "blue", "blue",…
## $ birth_year <dbl> 19.0, 112.0, 33.0, 41.9, 19.0, 52.0, 47.0, NA, 24.0, 57.0, …
## $ sex <chr> "male", "none", "none", "male", "female", "male", "female",…
## $ gender <chr> "masculine", "masculine", "masculine", "masculine", "femini…
## $ homeworld <chr> "Tatooine", "Tatooine", "Naboo", "Tatooine", "Alderaan", "T…
## $ species <chr> "Human", "Droid", "Droid", "Human", "Human", "Human", "Huma…
## $ films <list> <"The Empire Strikes Back", "Revenge of the Sith", "Return…
## $ vehicles <list> <"Snowspeeder", "Imperial Speeder Bike">, <>, <>, <>, "Imp…
## $ starships <list> <"X-wing", "Imperial shuttle">, <>, <>, "TIE Advanced x1",…
dim(starwars) # dimensiones## [1] 87 14## # A tibble: 1,704 × 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
## 4 Afghanistan Asia 1967 34.0 11537966 836.
## 5 Afghanistan Asia 1972 36.1 13079460 740.
## 6 Afghanistan Asia 1977 38.4 14880372 786.
## 7 Afghanistan Asia 1982 39.9 12881816 978.
## 8 Afghanistan Asia 1987 40.8 13867957 852.
## 9 Afghanistan Asia 1992 41.7 16317921 649.
## 10 Afghanistan Asia 1997 41.8 22227415 635.
## # … with 1,694 more rows
glimpse(gapminder) # resumen de columnas## Rows: 1,704
## Columns: 6
## $ country <fct> "Afghanistan", "Afghanistan", "Afghanistan", "Afghanistan", …
## $ continent <fct> Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, …
## $ year <int> 1952, 1957, 1962, 1967, 1972, 1977, 1982, 1987, 1992, 1997, …
## $ lifeExp <dbl> 28.801, 30.332, 31.997, 34.020, 36.088, 38.438, 39.854, 40.8…
## $ pop <int> 8425333, 9240934, 10267083, 11537966, 13079460, 14880372, 12…
## $ gdpPercap <dbl> 779.4453, 820.8530, 853.1007, 836.1971, 739.9811, 786.1134, …
dim(gapminder) # dimensiones## [1] 1704 6
Tidy data
Scripts usados:
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: convierte en tidy data el siguiente
data.frame.
library(tibble)
library(tidyr)
tabla_tb <- tibble("trimestre" = c("T1", "T2", "T3"),
"2020" = c(10, 12, 7.5),
"2021" = c(8, 0, 9))- Solución:
El problema es que las dos columnas con nombres de año son en realidad valores que deberían pasar a ser variables, así que deberíamos disminuir aplicar pivot_longer()
# Aplicamos pivot_longer
tabla_tb %>% pivot_longer(cols = c("2020", "2021"),
names_to = "año", values_to = "valores")## # A tibble: 6 × 3
## trimestre año valores
## <chr> <chr> <dbl>
## 1 T1 2020 10
## 2 T1 2021 8
## 3 T2 2020 12
## 4 T2 2021 0
## 5 T3 2020 7.5
## 6 T3 2021 9
📝Ejercicio 2: convierte en tidy data el siguiente
data.frame.
tabla_tb <- tibble("año" = c(2019, 2019, 2020, 2020, 2021, 2021),
"variable" = c("A", "B", "A", "B", "A", "B"),
"valor" = c(10, 9383, 7.58, 10839, 9, 32949))- Solución:
El problema es que las filas que comparten año son el mismo registro (pero con dos características que tenemos divididas en dos filas), así que deberíamos disminuir aplicar pivot_wider()
# Aplicamos pivot_wider
tabla_tb %>% pivot_wider(names_from = "variable", values_from = "valor")## # A tibble: 3 × 3
## año A B
## <dbl> <dbl> <dbl>
## 1 2019 10 9383
## 2 2020 7.58 10839
## 3 2021 9 32949
📝Ejercicio 3: convierte en tidy data la tabla
table5 del paquete tidyr.
- Solución:
Primero uniremos el siglo y las dos últimas cifras del año para obtener el año completo (guardado en año)
table5 %>%
unite(año, century, year, sep = "")## # A tibble: 6 × 3
## country año rate
## <chr> <chr> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583Tras ello deberemos separar el valor del ratio en denominador y numerador (ya que ahora hay dos valores en una celda), y convertiremos el tipo de dato en la salida para que sea número.
table5 %>%
unite(año, century, year, sep = "") %>%
separate(rate, c("numerador", "denominador"), convert = TRUE)## # A tibble: 6 × 4
## country año numerador denominador
## <chr> <chr> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Intro a tidyverse
Scripts usados:
- script19.R: intro a tidyverse. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script19.R
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: carga el conjunto de datos
starwars y determina el tipo de variables, el númwero de filas y el número de columnas.
- Solución:
## # A tibble: 87 × 14
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 Luke S… 172 77 blond fair blue 19 male mascu…
## 2 C-3PO 167 75 <NA> gold yellow 112 none mascu…
## 3 R2-D2 96 32 <NA> white, bl… red 33 none mascu…
## 4 Darth … 202 136 none white yellow 41.9 male mascu…
## 5 Leia O… 150 49 brown light brown 19 fema… femin…
## 6 Owen L… 178 120 brown, grey light blue 52 male mascu…
## 7 Beru W… 165 75 brown light blue 47 fema… femin…
## 8 R5-D4 97 32 <NA> white, red red NA none mascu…
## 9 Biggs … 183 84 black light brown 24 male mascu…
## 10 Obi-Wa… 182 77 auburn, wh… fair blue-gray 57 male mascu…
## # … with 77 more rows, and 5 more variables: homeworld <chr>, species <chr>,
## # films <list>, vehicles <list>, starships <list>
# dimensiones
nrow(starwars)## [1] 87
ncol(starwars)## [1] 14
dim(starwars)## [1] 87 14
# Tipos de variables
glimpse(starwars)## Rows: 87
## Columns: 14
## $ name <chr> "Luke Skywalker", "C-3PO", "R2-D2", "Darth Vader", "Leia Or…
## $ height <int> 172, 167, 96, 202, 150, 178, 165, 97, 183, 182, 188, 180, 2…
## $ mass <dbl> 77.0, 75.0, 32.0, 136.0, 49.0, 120.0, 75.0, 32.0, 84.0, 77.…
## $ hair_color <chr> "blond", NA, NA, "none", "brown", "brown, grey", "brown", N…
## $ skin_color <chr> "fair", "gold", "white, blue", "white", "light", "light", "…
## $ eye_color <chr> "blue", "yellow", "red", "yellow", "brown", "blue", "blue",…
## $ birth_year <dbl> 19.0, 112.0, 33.0, 41.9, 19.0, 52.0, 47.0, NA, 24.0, 57.0, …
## $ sex <chr> "male", "none", "none", "male", "female", "male", "female",…
## $ gender <chr> "masculine", "masculine", "masculine", "masculine", "femini…
## $ homeworld <chr> "Tatooine", "Tatooine", "Naboo", "Tatooine", "Alderaan", "T…
## $ species <chr> "Human", "Droid", "Droid", "Human", "Human", "Human", "Huma…
## $ films <list> <"The Empire Strikes Back", "Revenge of the Sith", "Return…
## $ vehicles <list> <"Snowspeeder", "Imperial Speeder Bike">, <>, <>, <>, "Imp…
## $ starships <list> <"X-wing", "Imperial shuttle">, <>, <>, "TIE Advanced x1",…
📝Ejercicio 2: del conjunto
starwars encuentra todos los personajes cuyo peso esté entre 60kg y 90kg. Imprime todas las columnas del filtro.
- Solución:
## # A tibble: 32 × 14
## name height mass hair_color skin_color eye_color birth_year
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl>
## 1 Luke Skywalker 172 77 blond fair blue 19
## 2 C-3PO 167 75 <NA> gold yellow 112
## 3 Beru Whitesun lars 165 75 brown light blue 47
## 4 Biggs Darklighter 183 84 black light brown 24
## 5 Obi-Wan Kenobi 182 77 auburn, white fair blue-gray 57
## 6 Anakin Skywalker 188 84 blond fair blue 41.9
## 7 Han Solo 180 80 brown fair brown 29
## 8 Greedo 173 74 <NA> green black 44
## 9 Wedge Antilles 170 77 brown fair hazel 21
## 10 Palpatine 170 75 grey pale yellow 82
## sex gender homeworld species films vehicles starships
## <chr> <chr> <chr> <chr> <list> <list> <list>
## 1 male masculine Tatooine Human <chr [5]> <chr [2]> <chr [2]>
## 2 none masculine Tatooine Droid <chr [6]> <chr [0]> <chr [0]>
## 3 female feminine Tatooine Human <chr [3]> <chr [0]> <chr [0]>
## 4 male masculine Tatooine Human <chr [1]> <chr [0]> <chr [1]>
## 5 male masculine Stewjon Human <chr [6]> <chr [1]> <chr [5]>
## 6 male masculine Tatooine Human <chr [3]> <chr [2]> <chr [3]>
## 7 male masculine Corellia Human <chr [4]> <chr [0]> <chr [2]>
## 8 male masculine Rodia Rodian <chr [1]> <chr [0]> <chr [0]>
## 9 male masculine Corellia Human <chr [3]> <chr [1]> <chr [1]>
## 10 male masculine Naboo Human <chr [5]> <chr [0]> <chr [0]>
## # … with 22 more rows
📝Ejercicio 3: añadido al filtro anterior, encuentra todos los personajes que además tengan los ojos que no sean azules.
- Solución:
# todas columnas
filtro <-
starwars %>%
filter(between(mass, 60, 90) & eye_color != "blue")
print(filtro, width = Inf)## # A tibble: 27 × 14
## name height mass hair_color skin_color eye_color
## <chr> <int> <dbl> <chr> <chr> <chr>
## 1 C-3PO 167 75 <NA> gold yellow
## 2 Biggs Darklighter 183 84 black light brown
## 3 Obi-Wan Kenobi 182 77 auburn, white fair blue-gray
## 4 Han Solo 180 80 brown fair brown
## 5 Greedo 173 74 <NA> green black
## 6 Wedge Antilles 170 77 brown fair hazel
## 7 Palpatine 170 75 grey pale yellow
## 8 Boba Fett 183 78.2 black fair brown
## 9 Lando Calrissian 177 79 black dark brown
## 10 Ackbar 180 83 none brown mottle orange
## birth_year sex gender homeworld species films vehicles
## <dbl> <chr> <chr> <chr> <chr> <list> <list>
## 1 112 none masculine Tatooine Droid <chr [6]> <chr [0]>
## 2 24 male masculine Tatooine Human <chr [1]> <chr [0]>
## 3 57 male masculine Stewjon Human <chr [6]> <chr [1]>
## 4 29 male masculine Corellia Human <chr [4]> <chr [0]>
## 5 44 male masculine Rodia Rodian <chr [1]> <chr [0]>
## 6 21 male masculine Corellia Human <chr [3]> <chr [1]>
## 7 82 male masculine Naboo Human <chr [5]> <chr [0]>
## 8 31.5 male masculine Kamino Human <chr [3]> <chr [0]>
## 9 31 male masculine Socorro Human <chr [2]> <chr [0]>
## 10 41 male masculine Mon Cala Mon Calamari <chr [2]> <chr [0]>
## starships
## <list>
## 1 <chr [0]>
## 2 <chr [1]>
## 3 <chr [5]>
## 4 <chr [2]>
## 5 <chr [0]>
## 6 <chr [1]>
## 7 <chr [0]>
## 8 <chr [1]>
## 9 <chr [1]>
## 10 <chr [0]>
## # … with 17 more rows
📝Ejercicio 4: añadido al filtro anterior, encuentra todos los personajes que además tengan menos de 100 años.
- Solución:
# todas columnas
filtro <-
starwars %>%
filter(between(mass, 60, 90) & eye_color != "blue" &
birth_year < 100)
print(filtro, width = Inf)## # A tibble: 15 × 14
## name height mass hair_color skin_color eye_color
## <chr> <int> <dbl> <chr> <chr> <chr>
## 1 Biggs Darklighter 183 84 black light brown
## 2 Obi-Wan Kenobi 182 77 auburn, white fair blue-gray
## 3 Han Solo 180 80 brown fair brown
## 4 Greedo 173 74 <NA> green black
## 5 Wedge Antilles 170 77 brown fair hazel
## 6 Palpatine 170 75 grey pale yellow
## 7 Boba Fett 183 78.2 black fair brown
## 8 Lando Calrissian 177 79 black dark brown
## 9 Ackbar 180 83 none brown mottle orange
## 10 Jar Jar Binks 196 66 none orange orange
## 11 Darth Maul 175 80 none red yellow
## 12 Mace Windu 188 84 none dark brown
## 13 Ki-Adi-Mundi 198 82 white pale yellow
## 14 Plo Koon 188 80 none orange black
## 15 Jango Fett 183 79 black tan brown
## birth_year sex gender homeworld species films vehicles
## <dbl> <chr> <chr> <chr> <chr> <list> <list>
## 1 24 male masculine Tatooine Human <chr [1]> <chr [0]>
## 2 57 male masculine Stewjon Human <chr [6]> <chr [1]>
## 3 29 male masculine Corellia Human <chr [4]> <chr [0]>
## 4 44 male masculine Rodia Rodian <chr [1]> <chr [0]>
## 5 21 male masculine Corellia Human <chr [3]> <chr [1]>
## 6 82 male masculine Naboo Human <chr [5]> <chr [0]>
## 7 31.5 male masculine Kamino Human <chr [3]> <chr [0]>
## 8 31 male masculine Socorro Human <chr [2]> <chr [0]>
## 9 41 male masculine Mon Cala Mon Calamari <chr [2]> <chr [0]>
## 10 52 male masculine Naboo Gungan <chr [2]> <chr [0]>
## 11 54 male masculine Dathomir Zabrak <chr [1]> <chr [1]>
## 12 72 male masculine Haruun Kal Human <chr [3]> <chr [0]>
## 13 92 male masculine Cerea Cerean <chr [3]> <chr [0]>
## 14 22 male masculine Dorin Kel Dor <chr [3]> <chr [0]>
## 15 66 male masculine Concord Dawn Human <chr [1]> <chr [0]>
## starships
## <list>
## 1 <chr [1]>
## 2 <chr [5]>
## 3 <chr [2]>
## 4 <chr [0]>
## 5 <chr [1]>
## 6 <chr [0]>
## 7 <chr [1]>
## 8 <chr [1]>
## 9 <chr [0]>
## 10 <chr [0]>
## 11 <chr [1]>
## 12 <chr [0]>
## 13 <chr [0]>
## 14 <chr [1]>
## 15 <chr [0]>
📝Ejercicio 5: añadido al filtro anterior, selecciona solo las columnas
name, mass, eye_color, birth_year
- Solución:
## # A tibble: 15 × 4
## name mass eye_color birth_year
## <chr> <dbl> <chr> <dbl>
## 1 Biggs Darklighter 84 brown 24
## 2 Obi-Wan Kenobi 77 blue-gray 57
## 3 Han Solo 80 brown 29
## 4 Greedo 74 black 44
## 5 Wedge Antilles 77 hazel 21
## 6 Palpatine 75 yellow 82
## 7 Boba Fett 78.2 brown 31.5
## 8 Lando Calrissian 79 brown 31
## 9 Ackbar 83 orange 41
## 10 Jar Jar Binks 66 orange 52
## 11 Darth Maul 80 yellow 54
## 12 Mace Windu 84 brown 72
## 13 Ki-Adi-Mundi 82 yellow 92
## 14 Plo Koon 80 black 22
## 15 Jango Fett 79 brown 66
📝Ejercicio 5: selecciona solo las columnas que contengan variables numéricas.
- Solución:
starwars %>% select(where(is.numeric))## # A tibble: 87 × 3
## height mass birth_year
## <int> <dbl> <dbl>
## 1 172 77 19
## 2 167 75 112
## 3 96 32 33
## 4 202 136 41.9
## 5 150 49 19
## 6 178 120 52
## 7 165 75 47
## 8 97 32 NA
## 9 183 84 24
## 10 182 77 57
## # … with 77 more rows
📝Ejercicio 6: añadido a la selección anterior, coloca los años de nacimiento como primera columna y cambia los nombres a castellano.
- Solución:
starwars %>%
select(where(is.numeric)) %>%
relocate(height, mass, .after = birth_year) %>%
rename(edad = birth_year, altura = height, peso = mass)## # A tibble: 87 × 3
## edad altura peso
## <dbl> <int> <dbl>
## 1 19 172 77
## 2 112 167 75
## 3 33 96 32
## 4 41.9 202 136
## 5 19 150 49
## 6 52 178 120
## 7 47 165 75
## 8 NA 97 32
## 9 24 183 84
## 10 57 182 77
## # … with 77 more rows
📝Ejercicio 7: calcula una nueva columna que indique el número de naves que ha pilotado cada persona (escribe
? starwars en consola para ver documentación del fichero).
- Solución:
starwars_numero_naves <-
starwars %>%
mutate(n_naves = map_chr(starships, length))
# Imprimimos todas las columnas
print(starwars_numero_naves, width = Inf)## # A tibble: 87 × 15
## name height mass hair_color skin_color eye_color
## <chr> <int> <dbl> <chr> <chr> <chr>
## 1 Luke Skywalker 172 77 blond fair blue
## 2 C-3PO 167 75 <NA> gold yellow
## 3 R2-D2 96 32 <NA> white, blue red
## 4 Darth Vader 202 136 none white yellow
## 5 Leia Organa 150 49 brown light brown
## 6 Owen Lars 178 120 brown, grey light blue
## 7 Beru Whitesun lars 165 75 brown light blue
## 8 R5-D4 97 32 <NA> white, red red
## 9 Biggs Darklighter 183 84 black light brown
## 10 Obi-Wan Kenobi 182 77 auburn, white fair blue-gray
## birth_year sex gender homeworld species films vehicles starships
## <dbl> <chr> <chr> <chr> <chr> <list> <list> <list>
## 1 19 male masculine Tatooine Human <chr [5]> <chr [2]> <chr [2]>
## 2 112 none masculine Tatooine Droid <chr [6]> <chr [0]> <chr [0]>
## 3 33 none masculine Naboo Droid <chr [7]> <chr [0]> <chr [0]>
## 4 41.9 male masculine Tatooine Human <chr [4]> <chr [0]> <chr [1]>
## 5 19 female feminine Alderaan Human <chr [5]> <chr [1]> <chr [0]>
## 6 52 male masculine Tatooine Human <chr [3]> <chr [0]> <chr [0]>
## 7 47 female feminine Tatooine Human <chr [3]> <chr [0]> <chr [0]>
## 8 NA none masculine Tatooine Droid <chr [1]> <chr [0]> <chr [0]>
## 9 24 male masculine Tatooine Human <chr [1]> <chr [0]> <chr [1]>
## 10 57 male masculine Stewjon Human <chr [6]> <chr [1]> <chr [5]>
## n_naves
## <chr>
## 1 2
## 2 0
## 3 0
## 4 1
## 5 0
## 6 0
## 7 0
## 8 0
## 9 1
## 10 5
## # … with 77 more rows
# Solo la columna añadida
starwars %>%
transmute(n_naves = map_chr(starships, length))## # A tibble: 87 × 1
## n_naves
## <chr>
## 1 2
## 2 0
## 3 0
## 4 1
## 5 0
## 6 0
## 7 0
## 8 0
## 9 1
## 10 5
## # … with 77 more rows
📝Ejercicio 8: con la columna anterior añadido, crea una nueva variable
TRUE/FALSE que nos diga si ha conducido o no alguna nave, y filtra después solo aquellos personajes que han conducido alguna nave.
- Solución:
# Nueva columna lógica
starwars_numero_naves %>%
mutate(conducir_nave = n_naves > 0) %>%
filter(conducir_nave)## # A tibble: 20 × 16
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 Luke S… 172 77 blond fair blue 19 male mascu…
## 2 Darth … 202 136 none white yellow 41.9 male mascu…
## 3 Biggs … 183 84 black light brown 24 male mascu…
## 4 Obi-Wa… 182 77 auburn, wh… fair blue-gray 57 male mascu…
## 5 Anakin… 188 84 blond fair blue 41.9 male mascu…
## 6 Chewba… 228 112 brown unknown blue 200 male mascu…
## 7 Han So… 180 80 brown fair brown 29 male mascu…
## 8 Wedge … 170 77 brown fair hazel 21 male mascu…
## 9 Jek To… 180 110 brown fair blue NA male mascu…
## 10 Boba F… 183 78.2 black fair brown 31.5 male mascu…
## 11 Lando … 177 79 black dark brown 31 male mascu…
## 12 Arvel … NA NA brown fair brown NA male mascu…
## 13 Nien N… 160 68 none grey black NA male mascu…
## 14 Ric Ol… 183 NA brown fair blue NA <NA> <NA>
## 15 Darth … 175 80 none red yellow 54 male mascu…
## 16 Plo Ko… 188 80 none orange black 22 male mascu…
## 17 Gregar… 185 85 black dark brown NA male mascu…
## 18 Grievo… 216 159 none brown, wh… green, y… NA male mascu…
## 19 Poe Da… NA NA brown light brown NA male mascu…
## 20 Padmé … 165 45 brown light brown 46 fema… femin…
## # … with 7 more variables: homeworld <chr>, species <chr>, films <list>,
## # vehicles <list>, starships <list>, n_naves <chr>, conducir_nave <lgl>
📝Ejercicio 9: calcula el número de películas en las que han salido y ordena a los personajes de mayor a menor número de películas en las que ha aparecido
- Solución:
starwars %>% # Calculamos primero el número de películas
mutate(n_films = map_int(films, length)) %>%
arrange(desc(n_films)) # Ordenamos de mayor a menor## # A tibble: 87 × 15
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 R2-D2 96 32 <NA> white, bl… red 33 none mascu…
## 2 C-3PO 167 75 <NA> gold yellow 112 none mascu…
## 3 Obi-Wa… 182 77 auburn, wh… fair blue-gray 57 male mascu…
## 4 Luke S… 172 77 blond fair blue 19 male mascu…
## 5 Leia O… 150 49 brown light brown 19 fema… femin…
## 6 Chewba… 228 112 brown unknown blue 200 male mascu…
## 7 Yoda 66 17 white green brown 896 male mascu…
## 8 Palpat… 170 75 grey pale yellow 82 male mascu…
## 9 Darth … 202 136 none white yellow 41.9 male mascu…
## 10 Han So… 180 80 brown fair brown 29 male mascu…
## # … with 77 more rows, and 6 more variables: homeworld <chr>, species <chr>,
## # films <list>, vehicles <list>, starships <list>, n_films <int>
📝Ejercicio 10: selecciona 7 personajes al azar.
- Solución:
# Una extracción aleatoria
starwars %>% slice_sample(n = 7)## # A tibble: 7 × 14
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 Cliegg … 183 NA brown fair blue 82 male mascul…
## 2 Sebulba 112 40 none grey, red orange NA male mascul…
## 3 C-3PO 167 75 <NA> gold yellow 112 none mascul…
## 4 Cordé 157 NA brown light brown NA fema… femini…
## 5 Jango F… 183 79 black tan brown 66 male mascul…
## 6 Lama Su 229 88 none grey black NA male mascul…
## 7 San Hill 191 NA none grey gold NA male mascul…
## # … with 5 more variables: homeworld <chr>, species <chr>, films <list>,
## # vehicles <list>, starships <list>
# otra (que sale distinta, claro)
starwars %>% slice_sample(n = 7)## # A tibble: 7 × 14
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 Captain … NA NA unknown unknown unknown NA <NA> <NA>
## 2 Ki-Adi-M… 198 82 white pale yellow 92 male mascu…
## 3 Boba Fett 183 78.2 black fair brown 31.5 male mascu…
## 4 Darth Ma… 175 80 none red yellow 54 male mascu…
## 5 Bail Pre… 191 NA black tan brown 67 male mascu…
## 6 Chewbacca 228 112 brown unknown blue 200 male mascu…
## 7 Palpatine 170 75 grey pale yellow 82 male mascu…
## # … with 5 more variables: homeworld <chr>, species <chr>, films <list>,
## # vehicles <list>, starships <list>
📝Ejercicio 11: selecciona los 5 personajes que en más películas han salido y los 5 que menos.
- Solución:
# personajes que en más películas han salido (metiendo empates)
starwars %>%
mutate(n_films = map_int(films, length)) %>%
slice_max(n_films, n = 5)## # A tibble: 8 × 15
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 R2-D2 96 32 <NA> white, bl… red 33 none mascu…
## 2 C-3PO 167 75 <NA> gold yellow 112 none mascu…
## 3 Obi-Wan… 182 77 auburn, wh… fair blue-gray 57 male mascu…
## 4 Luke Sk… 172 77 blond fair blue 19 male mascu…
## 5 Leia Or… 150 49 brown light brown 19 fema… femin…
## 6 Chewbac… 228 112 brown unknown blue 200 male mascu…
## 7 Yoda 66 17 white green brown 896 male mascu…
## 8 Palpati… 170 75 grey pale yellow 82 male mascu…
## # … with 6 more variables: homeworld <chr>, species <chr>, films <list>,
## # vehicles <list>, starships <list>, n_films <int>
# personajes que en más películas han salido (sin empates)
starwars %>%
mutate(n_films = map_int(films, length)) %>%
slice_max(n_films, n = 5, with_ties = FALSE)## # A tibble: 5 × 15
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 R2-D2 96 32 <NA> white, bl… red 33 none mascu…
## 2 C-3PO 167 75 <NA> gold yellow 112 none mascu…
## 3 Obi-Wan… 182 77 auburn, wh… fair blue-gray 57 male mascu…
## 4 Luke Sk… 172 77 blond fair blue 19 male mascu…
## 5 Leia Or… 150 49 brown light brown 19 fema… femin…
## # … with 6 more variables: homeworld <chr>, species <chr>, films <list>,
## # vehicles <list>, starships <list>, n_films <int>
# personajes que en menos películas han salido (metiendo empates)
starwars %>%
mutate(n_films = map_int(films, length)) %>%
slice_min(n_films, n = 5)## # A tibble: 46 × 15
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 R5-D4 97 32 <NA> white, red red NA none mascu…
## 2 Biggs D… 183 84 black light brown 24 male mascu…
## 3 Greedo 173 74 <NA> green black 44 male mascu…
## 4 Jek Ton… 180 110 brown fair blue NA male mascu…
## 5 IG-88 200 140 none metal red 15 none mascu…
## 6 Bossk 190 113 none green red 53 male mascu…
## 7 Lobot 175 79 none light blue 37 male mascu…
## 8 Mon Mot… 150 NA auburn fair blue 48 fema… femin…
## 9 Arvel C… NA NA brown fair brown NA male mascu…
## 10 Wicket … 88 20 brown brown brown 8 male mascu…
## # … with 36 more rows, and 6 more variables: homeworld <chr>, species <chr>,
## # films <list>, vehicles <list>, starships <list>, n_films <int>
# personajes que en menos películas han salido (sin empates)
starwars %>%
mutate(n_films = map_int(films, length)) %>%
slice_min(n_films, n = 5, with_ties = FALSE)## # A tibble: 5 × 15
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 R5-D4 97 32 <NA> white, red red NA none mascu…
## 2 Biggs Da… 183 84 black light brown 24 male mascu…
## 3 Greedo 173 74 <NA> green black 44 male mascu…
## 4 Jek Tono… 180 110 brown fair blue NA male mascu…
## 5 IG-88 200 140 none metal red 15 none mascu…
## # … with 6 more variables: homeworld <chr>, species <chr>, films <list>,
## # vehicles <list>, starships <list>, n_films <int>
📝Ejercicio 12: selecciona solo las columnas que se refieren a variables de color (ojos, piel, pelo) (con sufijo
"color")
- Solución:
# Contiene "color" independientemente de que sea sufijo o prefijo
starwars %>% select(contains("color"))## # A tibble: 87 × 3
## hair_color skin_color eye_color
## <chr> <chr> <chr>
## 1 blond fair blue
## 2 <NA> gold yellow
## 3 <NA> white, blue red
## 4 none white yellow
## 5 brown light brown
## 6 brown, grey light blue
## 7 brown light blue
## 8 <NA> white, red red
## 9 black light brown
## 10 auburn, white fair blue-gray
## # … with 77 more rows## # A tibble: 87 × 3
## hair_color skin_color eye_color
## <chr> <chr> <chr>
## 1 blond fair blue
## 2 <NA> gold yellow
## 3 <NA> white, blue red
## 4 none white yellow
## 5 brown light brown
## 6 brown, grey light blue
## 7 brown light blue
## 8 <NA> white, red red
## 9 black light brown
## 10 auburn, white fair blue-gray
## # … with 77 more rowsProfundizando tidyverse: encuestas electorales
Scripts usados:
- script20.R: profundizando tidyverse. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script20.
Vamos a profundizar un poco en el uso de funciones tidyverse para el análisis de datos de encuestas, datos de Our World in Data y datos de Spotify
En la denostada wikipedia se publican de forma bastante completa las encuestas electorales previas a las elecciones de un país, en este caso de España. El enlace donde están los datos es https://en.wikipedia.org/wiki/Opinion_polling_for_the_next_Spanish_general_election
Lo que vamos a hacer primero extraer la información de la web, analizando desde R su código HTML y quedándonos con las encuestas de 2021 y 2022. Para ello haremos uso del paquete rvest (cargaremos también tidyverse):
-
read_html(): nos permite obtener el código HTML de la web -
html_elements(): nos permite seleccionar elementos de dicho html -
html_table(): nos convierte una tabla HTML en untibble.
De esta manera leeremos el HTML, localizaremos las tablas de datos y seleccionaremos solo las dos primeras (encuestas de 2022 y 2021).
library(rvest)
library(tidyverse)
wiki <-
paste0("https://en.wikipedia.org/wiki/Opinion_polling_for_the_next_Spanish_general_election")
# Leemos html
html <- read_html(wiki)
# Seleccionamos las tablas del HTML
tablas <- html_elements(html, ".wikitable")
# Obtenemos las dos primeras tablas: encuestas de 2022 y 2021
encuestas_2022 <- html_table(tablas[[1]])
encuestas_2022## # A tibble: 14 × 21
## `Polling firm/Com… `Fieldwork date` `Sample size` Turnout `` `` ``
## <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Polling firm/Comm… Fieldwork date Sample size Turnout "" "" ""
## 2 ElectoPanel/Elect… 21–28 Jan 1,161 ? "24.2… "22.5… "20.…
## 3 DYM/Henneo[2] 19–23 Jan 1,008 ? "25.7… "26.9… "17.…
## 4 KeyData/Público[3] 21 Jan ? 68.1 "26.0… "25.6… "17.…
## 5 ElectoPanel/Elect… 14–20 Jan 1,190 ? "24.4… "22.9… "20.…
## 6 Celeste-Tel/Onda … 10–14 Jan 1,100 ? "26.2… "27.2… "16.…
## 7 InvyMark/laSexta[… 10–14 Jan ? ? "27.3" "27.9" "16.…
## 8 CIS (SocioMétrica… 3–14 Jan 3,777 59.3 "26.9" "22.4" "19.…
## 9 CIS[9][10][11] 3–14 Jan 3,777 ? "28.5… "21.5… "14.…
## 10 IMOP/El Confidenc… 3–14 Jan 1,312 ? "26.4… "24.9… "17.…
## 11 ElectoPanel/Elect… 7–13 Jan 1,317 ? "24.5… "23.3… "20.…
## 12 Simple Lógica/elD… 3–13 Jan 1,039 63.0 "24.6" "24.3" "18.…
## 13 ElectoPanel/Elect… 31 Dec–6 Jan 1,823 ? "24.9… "23.5… "20.…
## 14 Data10/OKDiario[1… 3–5 Jan 1,000 ? "25.4… "27.8… "17.…
## # … with 14 more variables: <chr>, <chr>, <chr>, <chr>, <chr>, PNV <chr>,
## # <chr>, <chr>, <chr>, <chr>, <chr>, PRC <chr>, <chr>, Lead <chr>
encuestas_2021 <- html_table(tablas[[2]])
encuestas_2021## # A tibble: 209 × 21
## `Polling firm/Com… `Fieldwork date` `Sample size` Turnout `` `` ``
## <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Polling firm/Comm… Fieldwork date Sample size Turnout "" "" ""
## 2 ElectoPanel/Elect… 24–30 Dec 1,189 ? "24.9… "23.9… "19.…
## 3 40dB/Prisa[18][19] 23–30 Dec 2,000 ? "26.1… "23.5… "18.…
## 4 IMOP/El Confidenc… 20–30 Dec 1,315 ? "25.2… "25.0… "18.…
## 5 SocioMétrica/El E… 20–30 Dec 3,000 ? "25.5… "24.2… "17.…
## 6 PSOE[22] 27 Dec ? ? "29.0" "22.0" "17.…
## 7 Sigma Dos/Antena … 26 Dec ? ? "25.7… "28.8… "15.…
## 8 Sigma Dos/El Mund… 20–24 Dec 2,619 ? "26.0… "27.4… "16.…
## 9 ElectoPanel/Elect… 17–23 Dec 1,299 ? "25.3… "24.6… "19.…
## 10 KeyData/Público[2… 22 Dec ? 67.1 "25.7… "26.4… "17.…
## # … with 199 more rows, and 14 more variables: <chr>, <chr>, <chr>, <chr>,
## # <chr>, PNV <chr>, <chr>, <chr>, <chr>, <chr>, <chr>, PRC <chr>,
## # TE <chr>, Lead <chr>Nombrar columnas
Dado que la mayoría de las columnas tienen como nombre de partido el logo del mismo, vamos a renombrar las variables.
nombre_cols <-
c("casa", "fechas", "muestra", "participacion", "PSOE", "PP", "Vox",
"UP", "Cs", "ERC", "MP", "JxCat", "PNV", "EHBildu", "CUP",
"CC", "BNG", "NA+", "PRC", "EV", "ventaja")
names(encuestas_2022) <- names(encuestas_2021) <- nombre_cols
encuestas_2022## # A tibble: 14 × 21
## casa fechas muestra participacion PSOE PP Vox UP Cs ERC MP
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Polli… Field… Sample… Turnout "" "" "" "" "" "" ""
## 2 Elect… 21–28… 1,161 ? "24.… "22.… "20.… "13.… "3.3… "3.5… "2.5…
## 3 DYM/H… 19–23… 1,008 ? "25.… "26.… "17.… "11.… "3.4… "–" "2.8…
## 4 KeyDa… 21 Jan ? 68.1 "26.… "25.… "17.… "11.… "2.9… "3.5… "3.0…
## 5 Elect… 14–20… 1,190 ? "24.… "22.… "20.… "12.… "3.2… "3.5… "2.5…
## 6 Celes… 10–14… 1,100 ? "26.… "27.… "16.… "11.… "3.4… "3.0… "3.6…
## 7 InvyM… 10–14… ? ? "27.… "27.… "16.… "10.… "1.3" "–" "3.0"
## 8 CIS (… 3–14 … 3,777 59.3 "26.… "22.… "19.… "11.… "3.0" "3.1" "2.6"
## 9 CIS[9… 3–14 … 3,777 ? "28.… "21.… "14.… "13.… "4.0… "3.0… "2.8…
## 10 IMOP/… 3–14 … 1,312 ? "26.… "24.… "17.… "11.… "2.6… "3.4… "2.5…
## 11 Elect… 7–13 … 1,317 ? "24.… "23.… "20.… "12.… "3.3… "3.5… "2.6…
## 12 Simpl… 3–13 … 1,039 63.0 "24.… "24.… "18.… "11.… "2.5" "–" "2.3"
## 13 Elect… 31 De… 1,823 ? "24.… "23.… "20.… "12.… "3.2… "3.5… "2.6…
## 14 Data1… 3–5 J… 1,000 ? "25.… "27.… "17.… "10.… "2.7… "3.2… "3.2…
## # … with 10 more variables: JxCat <chr>, PNV <chr>, EHBildu <chr>, CUP <chr>,
## # CC <chr>, BNG <chr>, NA+ <chr>, PRC <chr>, EV <chr>, ventaja <chr>
encuestas_2021## # A tibble: 209 × 21
## casa fechas muestra participacion PSOE PP Vox UP Cs ERC MP
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Polli… Field… Sample… Turnout "" "" "" "" "" "" ""
## 2 Elect… 24–30… 1,189 ? "24.… "23.… "19.… "11.… "3.2… "3.5… "2.7…
## 3 40dB/… 23–30… 2,000 ? "26.… "23.… "18.… "11.… "3.6… "?13" "3.6…
## 4 IMOP/… 20–30… 1,315 ? "25.… "25.… "18.… "12.… "2.8… "3.2… "2.7…
## 5 Socio… 20–30… 3,000 ? "25.… "24.… "17.… "12.… "4.3… "2.8… "3.2…
## 6 PSOE[… 27 Dec ? ? "29.… "22.… "17.… "11.… "–" "–" "–"
## 7 Sigma… 26 Dec ? ? "25.… "28.… "15.… "10.… "3.2… "3.0… "3.0…
## 8 Sigma… 20–24… 2,619 ? "26.… "27.… "16.… "10.… "3.1… "3.0… "3.1…
## 9 Elect… 17–23… 1,299 ? "25.… "24.… "19.… "11.… "3.2… "3.5… "2.7…
## 10 KeyDa… 22 Dec ? 67.1 "25.… "26.… "17.… "11.… "3.1… "3.4… "3.1…
## # … with 199 more rows, and 10 more variables: JxCat <chr>, PNV <chr>,
## # EHBildu <chr>, CUP <chr>, CC <chr>, BNG <chr>, NA+ <chr>, PRC <chr>,
## # EV <chr>, ventaja <chr>Eliminar filas
Tras la lectura sin salirnos de R, tenemos dos tablas de encuestas electorales, a las que les vamos a quitar la primera fila (vacía) con slice(-1).
encuestas_2022 <- encuestas_2022 %>% slice(-1)
encuestas_2022## # A tibble: 13 × 21
## casa fechas muestra participacion PSOE PP Vox UP Cs ERC MP
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Elect… 21–28… 1,161 ? 24.2… 22.5… 20.9… 13.1… 3.31 3.513 2.55
## 2 DYM/H… 19–23… 1,008 ? 25.7… 26.9… 17.1… 11.6… 3.42… – 2.82…
## 3 KeyDa… 21 Jan ? 68.1 26.0… 25.6… 17.4… 11.5… 2.91 3.513 3.04
## 4 Elect… 14–20… 1,190 ? 24.4… 22.9… 20.7… 12.7… 3.21 3.514 2.55
## 5 Celes… 10–14… 1,100 ? 26.2… 27.2… 16.5… 11.0… 3.42 3.012 3.65
## 6 InvyM… 10–14… ? ? 27.3 27.9 16.5 10.9 1.3 – 3.0
## 7 CIS (… 3–14 … 3,777 59.3 26.9 22.4 19.0 11.7 3.0 3.1 2.6
## 8 CIS[9… 3–14 … 3,777 ? 28.5… 21.5… 14.7… 13.1… 4.03 3.013 2.83
## 9 IMOP/… 3–14 … 1,312 ? 26.4… 24.9… 17.9… 11.8… 2.61 3.414 2.53
## 10 Elect… 7–13 … 1,317 ? 24.5… 23.3… 20.5… 12.4… 3.31 3.514 2.66
## 11 Simpl… 3–13 … 1,039 63.0 24.6 24.3 18.7 11.1 2.5 – 2.3
## 12 Elect… 31 De… 1,823 ? 24.9… 23.5… 20.2… 12.0… 3.21 3.514 2.65
## 13 Data1… 3–5 J… 1,000 ? 25.4… 27.8… 17.0… 10.9… 2.71 3.213 3.23
## # … with 10 more variables: JxCat <chr>, PNV <chr>, EHBildu <chr>, CUP <chr>,
## # CC <chr>, BNG <chr>, NA+ <chr>, PRC <chr>, EV <chr>, ventaja <chr>
encuestas_2021 <- encuestas_2021 %>% slice(-1)
encuestas_2021## # A tibble: 208 × 21
## casa fechas muestra participacion PSOE PP Vox UP Cs ERC MP
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Elect… 24–30… 1,189 ? 24.9… 23.9… 19.9… 11.8… 3.21 3.514 2.76
## 2 40dB/… 23–30… 2,000 ? 26.1… 23.5… 18.3… 11.8… 3.62… ?13 3.63…
## 3 IMOP/… 20–30… 1,315 ? 25.2… 25.0… 18.6… 12.1… 2.81 3.213 2.73
## 4 Socio… 20–30… 3,000 ? 25.5… 24.2… 17.7… 12.3… 4.33 2.812 3.25
## 5 PSOE[… 27 Dec ? ? 29.0 22.0 17.0 11.0 – – –
## 6 Sigma… 26 Dec ? ? 25.7… 28.8… 15.7… 10.6… 3.21 3.0? 3.06
## 7 Sigma… 20–24… 2,619 ? 26.0… 27.4… 16.6… 10.9… 3.11 3.012 3.16
## 8 Elect… 17–23… 1,299 ? 25.3… 24.6… 19.5… 11.4… 3.21 3.514 2.76
## 9 KeyDa… 22 Dec ? 67.1 25.7… 26.4… 17.1… 11.1… 3.11 3.413 3.14
## 10 DYM/H… 15–19… 1,012 ? 25.6… 27.6… 16.9… 10.6… 4.72… – 3.22…
## # … with 198 more rows, and 10 more variables: JxCat <chr>, PNV <chr>,
## # EHBildu <chr>, CUP <chr>, CC <chr>, BNG <chr>, NA+ <chr>, PRC <chr>,
## # EV <chr>, ventaja <chr>Juntar tablas
Dado que queremos un solo dataset con las encuestas de ambos años, vamos a juntar ambas tablas con rbind() para tener una sola tabla encuestas.
encuestas <- rbind(encuestas_2022, encuestas_2021)Convertir a numéricas
Si te fijas los valores de muchas variables son erróneos, como tamaño de la muestra o participación: son de tipo texto cuando deberían ser numéricas.
encuestas## # A tibble: 221 × 22
## casa fechas muestra participacion PSOE PP Vox UP Cs ERC MP
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Elect… 21–28… 1,161 ? 24.2… 22.5… 20.9… 13.1… 3.31 3.513 2.55
## 2 DYM/H… 19–23… 1,008 ? 25.7… 26.9… 17.1… 11.6… 3.42… – 2.82…
## 3 KeyDa… 21 Jan ? 68.1 26.0… 25.6… 17.4… 11.5… 2.91 3.513 3.04
## 4 Elect… 14–20… 1,190 ? 24.4… 22.9… 20.7… 12.7… 3.21 3.514 2.55
## 5 Celes… 10–14… 1,100 ? 26.2… 27.2… 16.5… 11.0… 3.42 3.012 3.65
## 6 InvyM… 10–14… ? ? 27.3 27.9 16.5 10.9 1.3 – 3.0
## 7 CIS (… 3–14 … 3,777 59.3 26.9 22.4 19.0 11.7 3.0 3.1 2.6
## 8 CIS[9… 3–14 … 3,777 ? 28.5… 21.5… 14.7… 13.1… 4.03 3.013 2.83
## 9 IMOP/… 3–14 … 1,312 ? 26.4… 24.9… 17.9… 11.8… 2.61 3.414 2.53
## 10 Elect… 7–13 … 1,317 ? 24.5… 23.3… 20.5… 12.4… 3.31 3.514 2.66
## # … with 211 more rows, and 11 more variables: JxCat <chr>, PNV <chr>,
## # EHBildu <chr>, CUP <chr>, CC <chr>, BNG <chr>, NA+ <chr>, PRC <chr>,
## # EV <chr>, ventaja <chr>, anno <dbl>Para ello vamos antes a eliminar las comas"," que separan los millares de los números, con gsub(). Dicha orden nos permite sustituir en un vector los caracteres que queramos. Por ejemplo, de un vector de palabras vamos a cambiar la letra a por un punto *: primero le indicamos el patrón a buscar, después el valor nuevo que le daremos, y por último la variable en la que lo vamos a aplicar.
## [1] "hol*" "c*m*" "elef*nte" "cerrojo" "león" "g*t*"Con esta función localizaremos las "," de muestra para sustituirlas por "" (sin nada), y lo mismo haremos con "?" en la variable participacion con los datos ausentes "?".
encuestas_depurado <-
encuestas %>%
# Quitamos "," como millares en números
mutate(muestra = gsub("?", "", gsub(",", "", muestra)),
participacion = gsub("?", NA, participacion))
encuestas_depurado## # A tibble: 221 × 22
## casa fechas muestra participacion PSOE PP Vox UP Cs ERC MP
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Elect… 21–28… 1161 <NA> 24.2… 22.5… 20.9… 13.1… 3.31 3.513 2.55
## 2 DYM/H… 19–23… 1008 <NA> 25.7… 26.9… 17.1… 11.6… 3.42… – 2.82…
## 3 KeyDa… 21 Jan ? <NA> 26.0… 25.6… 17.4… 11.5… 2.91 3.513 3.04
## 4 Elect… 14–20… 1190 <NA> 24.4… 22.9… 20.7… 12.7… 3.21 3.514 2.55
## 5 Celes… 10–14… 1100 <NA> 26.2… 27.2… 16.5… 11.0… 3.42 3.012 3.65
## 6 InvyM… 10–14… ? <NA> 27.3 27.9 16.5 10.9 1.3 – 3.0
## 7 CIS (… 3–14 … 3777 <NA> 26.9 22.4 19.0 11.7 3.0 3.1 2.6
## 8 CIS[9… 3–14 … 3777 <NA> 28.5… 21.5… 14.7… 13.1… 4.03 3.013 2.83
## 9 IMOP/… 3–14 … 1312 <NA> 26.4… 24.9… 17.9… 11.8… 2.61 3.414 2.53
## 10 Elect… 7–13 … 1317 <NA> 24.5… 23.3… 20.5… 12.4… 3.31 3.514 2.66
## # … with 211 more rows, and 11 more variables: JxCat <chr>, PNV <chr>,
## # EHBildu <chr>, CUP <chr>, CC <chr>, BNG <chr>, NA+ <chr>, PRC <chr>,
## # EV <chr>, ventaja <chr>, anno <dbl>Tras estos cambios, aunque muchas variables numéricas siguen siendo caracter, ya podemos aplicar la función as.numeric(), que aplicaremos a todas las variables menos casa y fechas, con mutate_at, indicándole con vars() primero las columnas a seleccionar (aquellas que no contengan la palabra casa ni fechas), y después la función a aplicar.
encuestas_depurado <-
encuestas_depurado %>%
mutate_at(vars(!contains(c("casa", "fechas"))), as.numeric)
encuestas_depurado## # A tibble: 221 × 22
## casa fechas muestra participacion PSOE PP Vox UP Cs ERC MP
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Elect… 21–28… 1161 NA 24.3 22.6 21.0 13.1 3.31 3.51 2.55
## 2 DYM/H… 19–23… 1008 NA NA NA NA NA NA NA NA
## 3 KeyDa… 21 Jan NA NA 26.0 25.6 17.5 11.5 2.91 3.51 3.04
## 4 Elect… 14–20… 1190 NA 24.5 23.0 20.8 12.7 3.21 3.51 2.55
## 5 Celes… 10–14… 1100 NA 26.2 27.2 16.6 11.0 3.42 3.01 3.65
## 6 InvyM… 10–14… NA NA 27.3 27.9 16.5 10.9 1.3 NA 3
## 7 CIS (… 3–14 … 3777 NA 26.9 22.4 19 11.7 3 3.1 2.6
## 8 CIS[9… 3–14 … 3777 NA 28.5 21.6 14.8 13.1 4.03 3.01 2.83
## 9 IMOP/… 3–14 … 1312 NA 26.4 24.9 18.0 11.8 2.61 3.41 2.53
## 10 Elect… 7–13 … 1317 NA 24.6 23.4 20.6 12.4 3.31 3.51 2.66
## # … with 211 more rows, and 11 more variables: JxCat <dbl>, PNV <dbl>,
## # EHBildu <dbl>, CUP <dbl>, CC <dbl>, BNG <dbl>, NA+ <dbl>, PRC <dbl>,
## # EV <dbl>, ventaja <dbl>, anno <dbl>Convertir las fechas de campo
Las fechas del trabajo de campo deben ser tratadas previamente:
las fechas de tipo
"28 Dec–2 Jan"(por ejemplo, de 2021) deberemos de convertirlas en dos fechas,2021-12-28y2022-01-02.las fechas de tipo
"12–14 Jan"(por ejemplo, de 2021) deberemos de convertirlas en dos fechas,2021-01-12y2021-01-14.las fechas de tipo
"15 Jan"(por ejemplo, de 2021), las convertiremos a dos fechas,2021-01-15y2021-01-15.
Para ello primero que vamos a hacer va a ser separar las fechas por los guiones - con str_plit() (que nos devolverá una lista).
fechas_intermedias <- str_split(encuestas_depurado$fechas, "–")
fechas_intermedias[1:6]## [[1]]
## [1] "21" "28 Jan"
##
## [[2]]
## [1] "19" "23 Jan"
##
## [[3]]
## [1] "21 Jan"
##
## [[4]]
## [1] "14" "20 Jan"
##
## [[5]]
## [1] "10" "14 Jan"
##
## [[6]]
## [1] "10" "14 Jan"En cada lugar de la lista vemos que tenemos dos fechas en la mayoría de casos: las pondremos en columnas fecha_inicio y fecha_inicial, devolviendo un tibble con map_dfr aplicado a la lista
fechas_intermedias <-
map_dfr(fechas_intermedias,
function(x) { tibble("fecha_inicio" = x[1],
"fecha_final" = x[2]) })
fechas_intermedias## # A tibble: 221 × 2
## fecha_inicio fecha_final
## <chr> <chr>
## 1 21 28 Jan
## 2 19 23 Jan
## 3 21 Jan <NA>
## 4 14 20 Jan
## 5 10 14 Jan
## 6 10 14 Jan
## 7 3 14 Jan
## 8 3 14 Jan
## 9 3 14 Jan
## 10 7 13 Jan
## # … with 211 more rowsLos registros donde fecha_final está ausente significa que toma el mismo valor que la fecha de inicio, y así lo modificaremos.
fechas_intermedias <-
fechas_intermedias %>%
mutate(fecha_final = ifelse(is.na(fecha_final),
fecha_inicio, fecha_final))
fechas_intermedias## # A tibble: 221 × 2
## fecha_inicio fecha_final
## <chr> <chr>
## 1 21 28 Jan
## 2 19 23 Jan
## 3 21 Jan 21 Jan
## 4 14 20 Jan
## 5 10 14 Jan
## 6 10 14 Jan
## 7 3 14 Jan
## 8 3 14 Jan
## 9 3 14 Jan
## 10 7 13 Jan
## # … with 211 more rowsLas fechas que no tenga mes en fecha_inicio, asumiremos que es el mismo mes que fecha_final: si solo hay números (dos o menos caracteres), obtenemos el mes de la fecha_final (últimos 3 caracteres) y lo pegamos al día.
fechas_intermedias <-
fechas_intermedias %>%
mutate(fecha_inicio =
ifelse(nchar(fecha_inicio) <= 2,
paste(fecha_inicio,
paste0(rev(rev(unlist(str_split(fecha_final, "")))[1:3]),
collapse = "")), fecha_inicio))
fechas_intermedias## # A tibble: 221 × 2
## fecha_inicio fecha_final
## <chr> <chr>
## 1 21 Jan 28 Jan
## 2 19 Jan 23 Jan
## 3 21 Jan 21 Jan
## 4 14 Jan 20 Jan
## 5 10 Jan 14 Jan
## 6 10 Jan 14 Jan
## 7 3 Jan 14 Jan
## 8 3 Jan 14 Jan
## 9 3 Jan 14 Jan
## 10 7 Jan 13 Jan
## # … with 211 more rowsEsas fechas intermedias las vamos añadir como columnas y, pegándole el año, vamos a convertirlas en datos de tipo fecha. De todas las fechas nos vamos a quedar solo con la fecha_final (recolocando dicha columna tras el nombre de la casa encuestadora).
library(lubridate)
encuestas_depurado <-
bind_cols(encuestas_depurado,
fechas_intermedias) %>%
mutate(fecha_inicio = dmy(paste(fecha_inicio, anno)),
fecha_final = dmy(paste(fecha_final, anno))) %>%
select(-c(fechas, anno, fecha_inicio)) %>%
relocate(fecha_final, .after = casa)
encuestas_depurado## # A tibble: 221 × 21
## casa fecha_final muestra participacion PSOE PP Vox UP Cs ERC
## <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Electo… 2022-01-28 1161 NA 24.3 22.6 21.0 13.1 3.31 3.51
## 2 DYM/He… 2022-01-23 1008 NA NA NA NA NA NA NA
## 3 KeyDat… 2022-01-21 NA NA 26.0 25.6 17.5 11.5 2.91 3.51
## 4 Electo… 2022-01-20 1190 NA 24.5 23.0 20.8 12.7 3.21 3.51
## 5 Celest… 2022-01-14 1100 NA 26.2 27.2 16.6 11.0 3.42 3.01
## 6 InvyMa… 2022-01-14 NA NA 27.3 27.9 16.5 10.9 1.3 NA
## 7 CIS (S… 2022-01-14 3777 NA 26.9 22.4 19 11.7 3 3.1
## 8 CIS[9]… 2022-01-14 3777 NA 28.5 21.6 14.8 13.1 4.03 3.01
## 9 IMOP/E… 2022-01-14 1312 NA 26.4 24.9 18.0 11.8 2.61 3.41
## 10 Electo… 2022-01-13 1317 NA 24.6 23.4 20.6 12.4 3.31 3.51
## # … with 211 more rows, and 11 more variables: MP <dbl>, JxCat <dbl>,
## # PNV <dbl>, EHBildu <dbl>, CUP <dbl>, CC <dbl>, BNG <dbl>, NA+ <dbl>,
## # PRC <dbl>, EV <dbl>, ventaja <dbl>Limpiamos nombres de encuestas
Por último, vamos limpiar los nombres de las encuestas eliminando la referencia a los enlaces de la wikipedia
Consultas
Una vez que tenemos los datos depurados vamos a realizar algunas consultas sencillas usando tidyverse.
¿Cuáles son las 10 encuestas con mayor tamaño muestral?
encuestas_depurado %>% slice_max(muestra, n = 10)## # A tibble: 10 × 21
## casa fecha_final muestra participacion PSOE PP Vox UP Cs ERC
## <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 ELECTO… 2021-05-02 4320 NA 27.1 24.0 17.0 12.3 4.03 3.61
## 2 CIS (S… 2021-02-11 3869 NA 28.1 19.7 16.3 11.3 9 3.3
## 3 CIS 2021-02-11 3869 NA 30.7 18.9 13.6 11.2 9.32 3.52
## 4 CIS (S… 2021-01-25 3862 NA 28.6 22.2 15.9 10 7.4 2.9
## 5 CIS 2021-01-25 3862 NA 30.7 20.6 13.0 10.7 9.32 2.91
## 6 CIS (S… 2021-04-14 3823 NA 30 20.8 18.8 10.8 4 3.2
## 7 CIS 2021-04-14 3823 NA 31.5 20.7 15.5 10.7 6.71 2.81
## 8 CIS 2021-03-11 3820 NA 31.3 18.0 15.1 9.62 9.52 3.21
## 9 CIS 2021-06-15 3814 NA 27.4 23.9 13.0 12.0 5.78 3.61
## 10 CIS 2021-05-13 3814 NA 27.9 23.4 13.7 10.4 5.37 3.01
## # … with 11 more variables: MP <dbl>, JxCat <dbl>, PNV <dbl>, EHBildu <dbl>,
## # CUP <dbl>, CC <dbl>, BNG <dbl>, NA+ <dbl>, PRC <dbl>, EV <dbl>,
## # ventaja <dbl>¿Cuáles son las encuestas más recientes?
## # A tibble: 221 × 21
## casa fecha_final muestra participacion PSOE PP Vox UP Cs ERC
## <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 ELECTO… 2022-01-28 1161 NA 24.3 22.6 21.0 13.1 3.31 3.51
## 2 DYM/HE… 2022-01-23 1008 NA NA NA NA NA NA NA
## 3 KEYDAT… 2022-01-21 NA NA 26.0 25.6 17.5 11.5 2.91 3.51
## 4 ELECTO… 2022-01-20 1190 NA 24.5 23.0 20.8 12.7 3.21 3.51
## 5 CELEST… 2022-01-14 1100 NA 26.2 27.2 16.6 11.0 3.42 3.01
## 6 INVYMA… 2022-01-14 NA NA 27.3 27.9 16.5 10.9 1.3 NA
## 7 CIS (S… 2022-01-14 3777 NA 26.9 22.4 19 11.7 3 3.1
## 8 CIS 2022-01-14 3777 NA 28.5 21.6 14.8 13.1 4.03 3.01
## 9 IMOP/E… 2022-01-14 1312 NA 26.4 24.9 18.0 11.8 2.61 3.41
## 10 ELECTO… 2022-01-13 1317 NA 24.6 23.4 20.6 12.4 3.31 3.51
## # … with 211 more rows, and 11 more variables: MP <dbl>, JxCat <dbl>,
## # PNV <dbl>, EHBildu <dbl>, CUP <dbl>, CC <dbl>, BNG <dbl>, NA+ <dbl>,
## # PRC <dbl>, EV <dbl>, ventaja <dbl>¿Cuáles son las 5 encuestas en las que el PSOE tiene mayor proyección?
encuestas_depurado %>% slice_max(PSOE, n = 5)## # A tibble: 5 × 21
## casa fecha_final muestra participacion PSOE PP Vox UP Cs ERC
## <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 CIS 2021-04-14 3823 NA 31.5 20.7 15.5 10.7 6.71 2.81
## 2 CIS 2021-03-11 3820 NA 31.3 18.0 15.1 9.62 9.52 3.21
## 3 CIS 2021-02-11 3869 NA 30.7 18.9 13.6 11.2 9.32 3.52
## 4 CIS 2021-01-25 3862 NA 30.7 20.6 13.0 10.7 9.32 2.91
## 5 CIS (SO… 2021-04-14 3823 NA 30 20.8 18.8 10.8 4 3.2
## # … with 11 more variables: MP <dbl>, JxCat <dbl>, PNV <dbl>, EHBildu <dbl>,
## # CUP <dbl>, CC <dbl>, BNG <dbl>, NA+ <dbl>, PRC <dbl>, EV <dbl>,
## # ventaja <dbl>¿Cuál es la encuesta del CIS en la que el PP tiene mayor proyección?
## # A tibble: 1 × 21
## casa fecha_final muestra participacion PSOE PP Vox UP Cs ERC
## <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 CIS 2021-06-15 3814 NA 27.4 23.9 13.0 12.0 5.78 3.61
## # … with 11 more variables: MP <dbl>, JxCat <dbl>, PNV <dbl>, EHBildu <dbl>,
## # CUP <dbl>, CC <dbl>, BNG <dbl>, NA+ <dbl>, PRC <dbl>, EV <dbl>,
## # ventaja <dbl>¿Cuál es el promedio de las encuestas del PSOE y PP por casa encuestadora?
encuestas_depurado %>%
select(-fecha_final) %>%
group_by(casa) %>%
summarise(media_PSOE = mean(PSOE), media_PP = mean(PP)) %>%
ungroup()## # A tibble: 28 × 3
## casa media_PSOE media_PP
## <chr> <dbl> <dbl>
## 1 40DB/PRISA NA NA
## 2 ÁGORA INTEGRAL/CANARIAS AHORA 25.8 25.4
## 3 CELESTE-TEL/ONDA CERO 26.3 27.8
## 4 CIS 29.2 21.3
## 5 CIS (SOCIOMÉTRICA) 27.2 22.1
## 6 DATA10/OKDIARIO 25.0 29.2
## 7 DEMOSCOPIA Y SERVICIOS/ESDIARIO 25.3 25.9
## 8 DYM/HENNEO NA NA
## 9 ELECTOPANEL/ELECTOMANÍA 26.2 25.7
## 10 GAD3/ABC 25.5 29.8
## # … with 18 more rows¿Cuál es son las 3 casas encuestadoras más sesgada hacia el PSOE (con mayor diferencia de promedio de PSOE vs PP)? ¿Y hacia el PP?
encuestas_depurado %>%
select(-fecha_final) %>%
group_by(casa) %>%
summarise(media_PSOE = mean(PSOE), media_PP = mean(PP)) %>%
ungroup() %>%
mutate(diferencia = media_PSOE - media_PP) %>%
slice_max(diferencia, n = 3)## # A tibble: 3 × 4
## casa media_PSOE media_PP diferencia
## <chr> <dbl> <dbl> <dbl>
## 1 CIS 29.2 21.3 7.94
## 2 PSOE 29 22 7
## 3 CIS (SOCIOMÉTRICA) 27.2 22.1 5.13
encuestas_depurado %>%
select(-fecha_final) %>%
group_by(casa) %>%
summarise(media_PSOE = mean(PSOE), media_PP = mean(PP)) %>%
ungroup() %>%
mutate(diferencia = media_PP - media_PSOE) %>%
slice_max(diferencia, n = 3)## # A tibble: 3 × 4
## casa media_PSOE media_PP diferencia
## <chr> <dbl> <dbl> <dbl>
## 1 GAD3/ABC 25.5 29.8 4.36
## 2 DATA10/OKDIARIO 25.0 29.2 4.12
## 3 SIGMA DOS/ANTENA 3 25.3 29.3 3.99Visualizando datos: incursión a ggplot2
Scripts usados:
- script21.R: incursión a ggplot2. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script21.
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: del conjunto
starwars (del entorno de paquetes tidyverse), filtra solo los registros que no tenga ausente NA en las columnas mass, height, eye_color
- Solución:
📝Ejercicio 2: con ese conjunto filtrado dibuja un diagrama de puntos enfrentando
x = height en el eje X e y = mass en el eje Y.
- Solución:
ggplot(starwars_filtro, aes(x = height, y = mass)) +
geom_point()
📝Ejercicio 3: modifica el código del gráfico anterior para asignar el tamaño de los puntos en función de la variable
mass.
- Solución:
ggplot(starwars_filtro,
aes(x = height, y = mass, size = mass)) +
geom_point()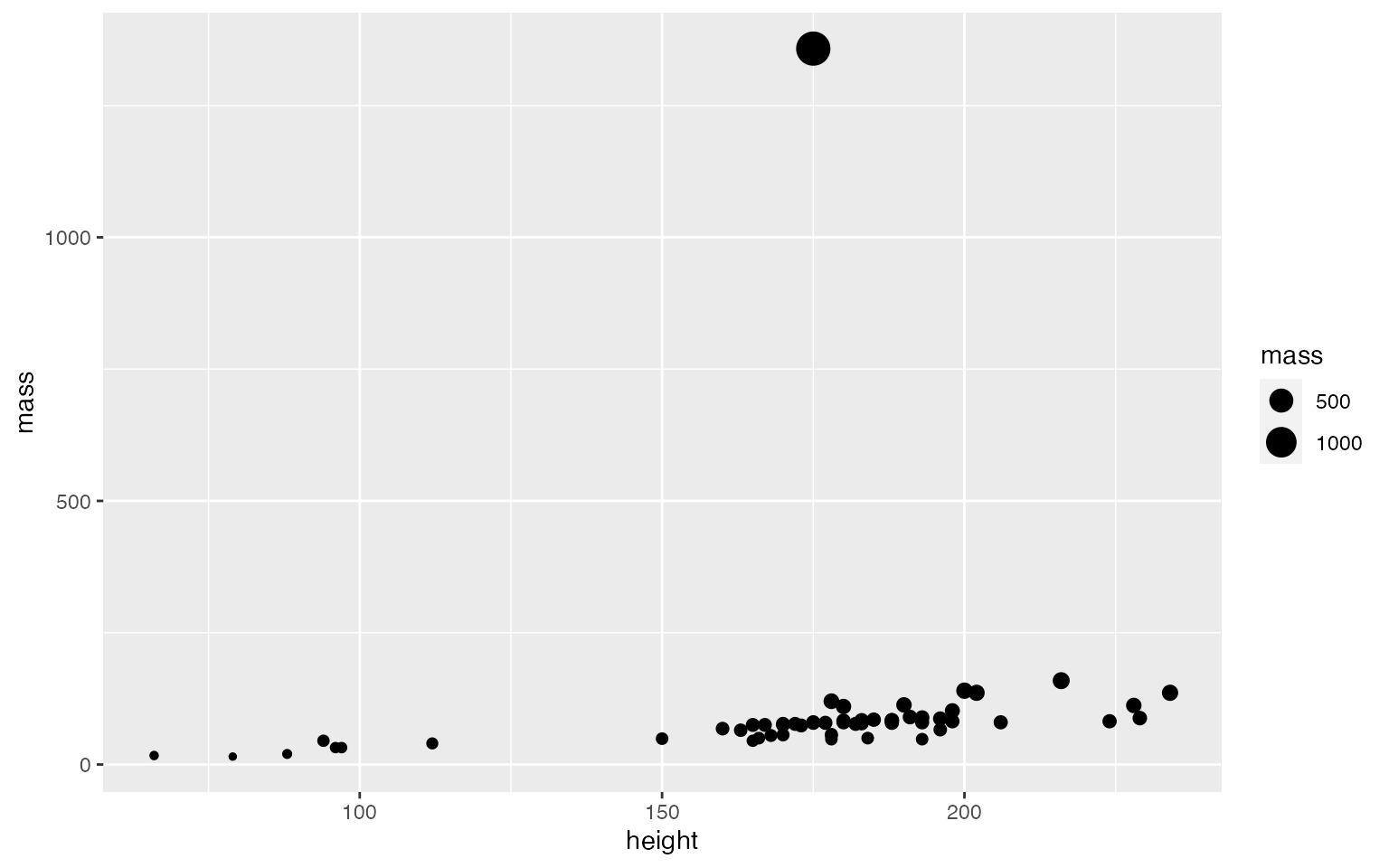
📝Ejercicio 4: modifica el código del gráfico anterior para asignar el color en función de su color de ojos guardado en
eye_color. Antes procesa la variable para quedarte con colores reales: si hay dos colores, quédate con el primero; el color "hazel" pásalo a "brown"; los colores "unknown" pásalo a gris.
- Solución:
# Transformar colores
starwars_filtro <-
starwars_filtro %>%
mutate(eye_color =
case_when(eye_color == "blue-gray" ~ "blue",
eye_color == "hazel" ~ "brown",
eye_color == "unknown" ~ "gray",
eye_color == "green, yellow" ~ "green",
TRUE ~ eye_color))
# Visualizamos
ggplot(starwars_filtro,
aes(x = height, y = mass, size = mass, color = eye_color)) +
geom_point() +
scale_color_manual(values =
c("black", "blue", "brown", "gray", "green",
"orange", "red", "white", "yellow"))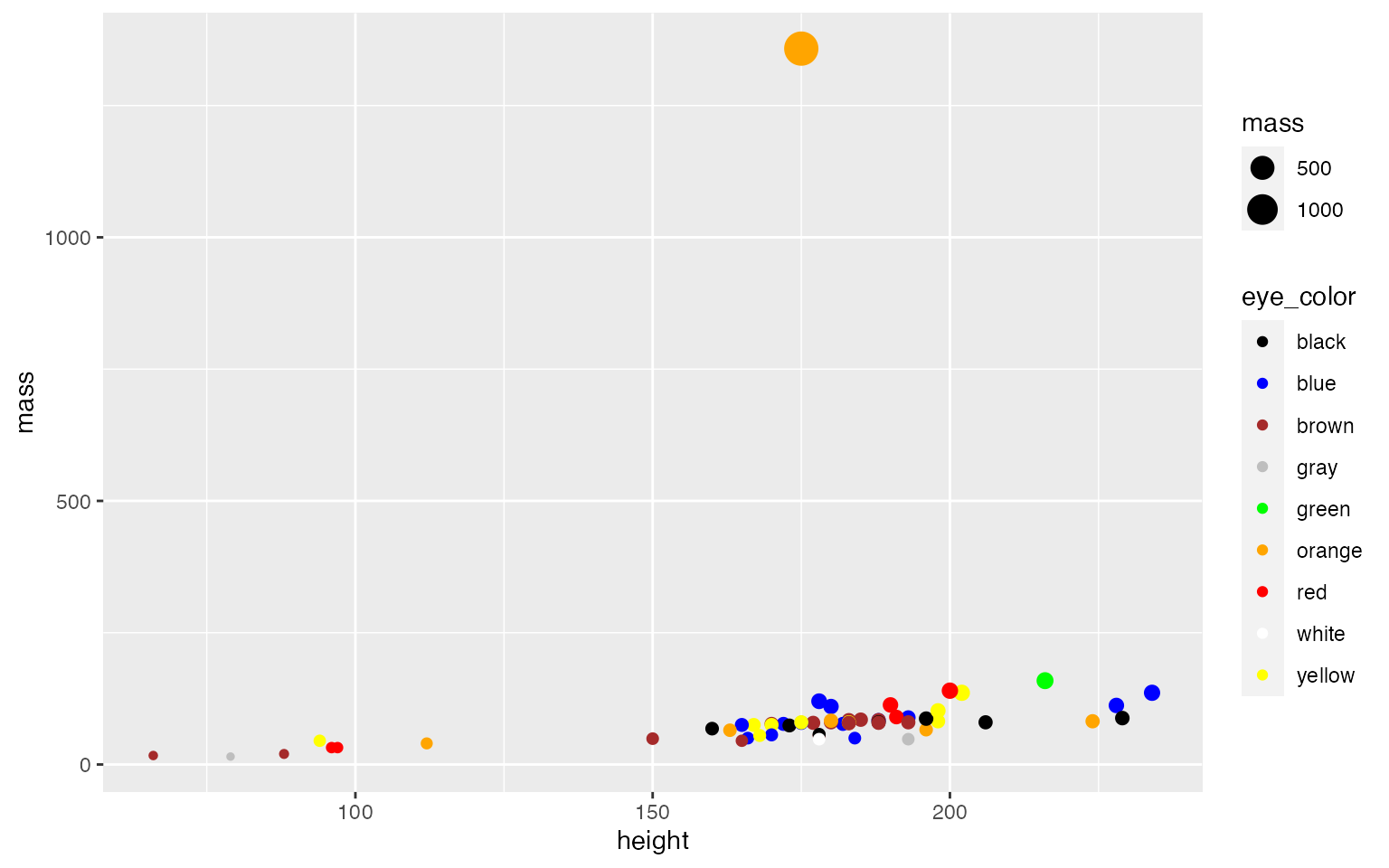
📝Ejercicio 5: repite el gráfico anterior localizando ese dato con un peso extremadamente elevado (outlier), elimínalo y vuelve a repetir la visualización.
- Solución:
# Localizamos el valor
starwars_filtro %>% slice_max(mass, n = 5)## # A tibble: 5 × 14
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 Jabba … 175 1358 <NA> green-tan,… orange 600 herma… mascu…
## 2 Grievo… 216 159 none brown, whi… green NA male mascu…
## 3 IG-88 200 140 none metal red 15 none mascu…
## 4 Darth … 202 136 none white yellow 41.9 male mascu…
## 5 Tarfful 234 136 brown brown blue NA male mascu…
## # … with 5 more variables: homeworld <chr>, species <chr>, films <list>,
## # vehicles <list>, starships <list>## [1] "Jabba Desilijic Tiure" "Grievous" "IG-88"
## [4] "Darth Vader" "Tarfful"
starwars_filtro <- starwars_filtro %>%
filter(name != "Jabba Desilijic Tiure")
# Visualizamos
ggplot(starwars_filtro,
aes(x = height, y = mass,
size = mass, color = eye_color)) +
geom_point() +
scale_color_manual(values =
c("black", "blue", "brown", "gray", "green",
"orange", "red", "white", "yellow"))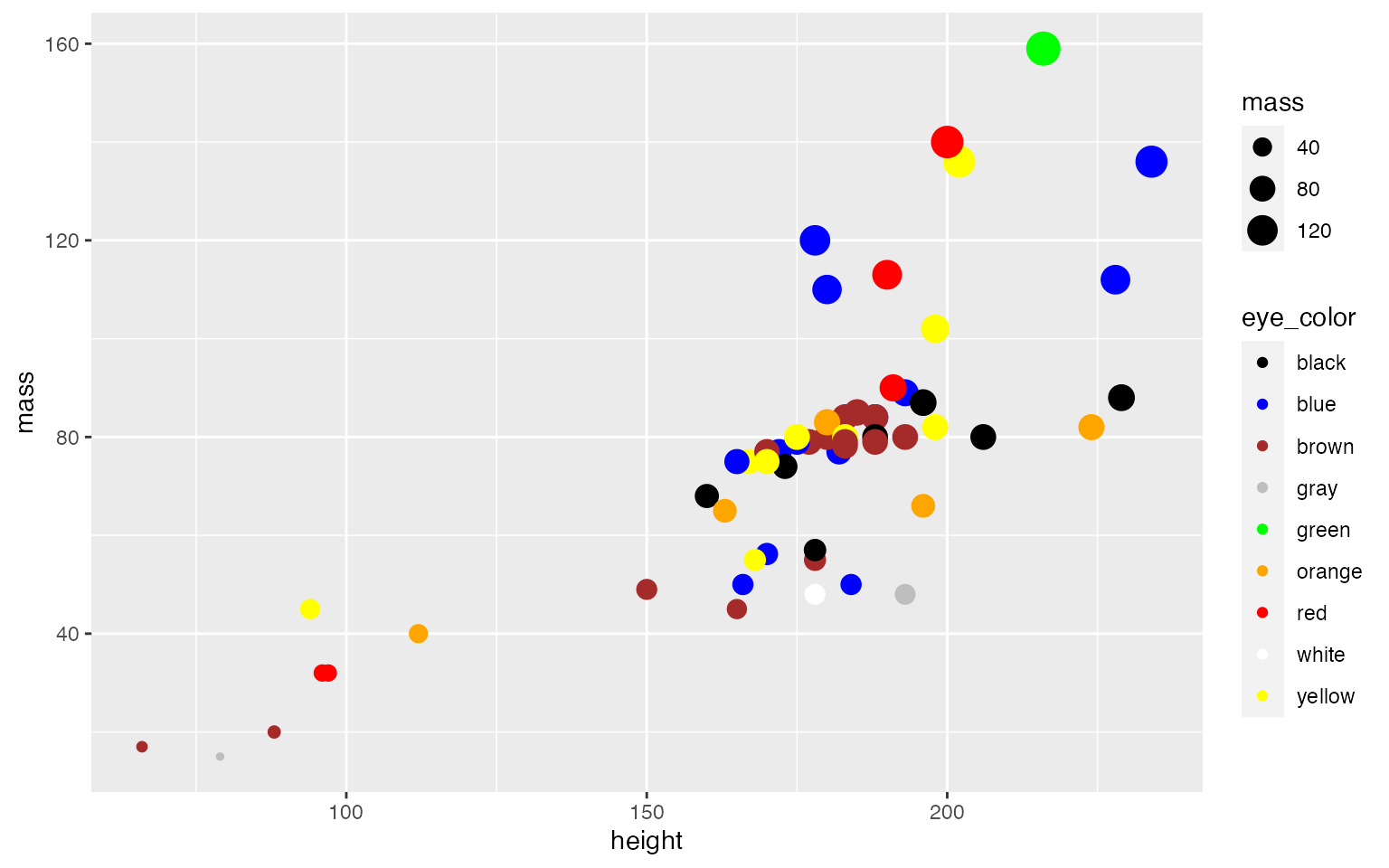
📝Ejercicio 6: repite el gráfico anterior eliminando la leyenda del tamaño del punto y cambia el título de la leyenda del color de ojos a castellano. Añade además transparencia
alpha = 0.6 a los puntos.
- Solución:
ggplot(starwars_filtro,
aes(x = height, y = mass,
size = mass, color = eye_color)) +
geom_point(alpha = 0.6) +
guides(size = "none") +
scale_color_manual(values =
c("black", "blue", "brown", "gray", "green",
"orange", "red", "white", "yellow")) +
labs(color = "color de ojos")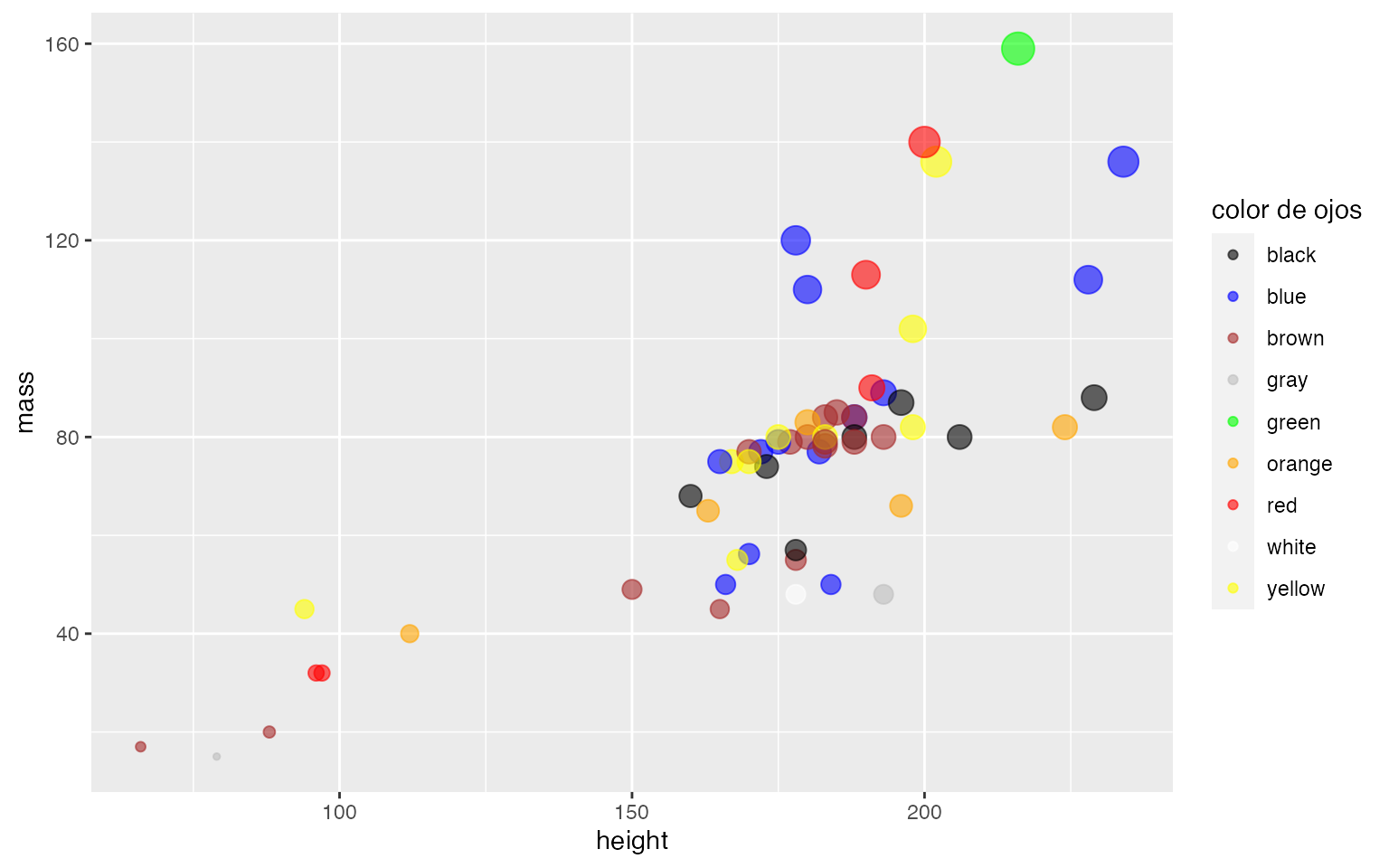
📝Ejercicio 7: repite el gráfico modificando los títulos de los ejes (a castellano) y escribiendo título, subtítulo y caption.
- Solución:
ggplot(starwars_filtro,
aes(x = height, y = mass,
size = mass, color = eye_color)) +
geom_point(alpha = 0.6) +
guides(size = "none") +
scale_color_manual(values =
c("black", "blue", "brown", "gray", "green",
"orange", "red", "white", "yellow")) +
labs(color = "color de ojos",
x = "altura (cm)", y = "peso (kg)",
title = "STARWARS",
subtitle = "Diagrama de puntos altura vs peso",
caption = "Autor: Javier Álvarez Liébana | Datos: starwars")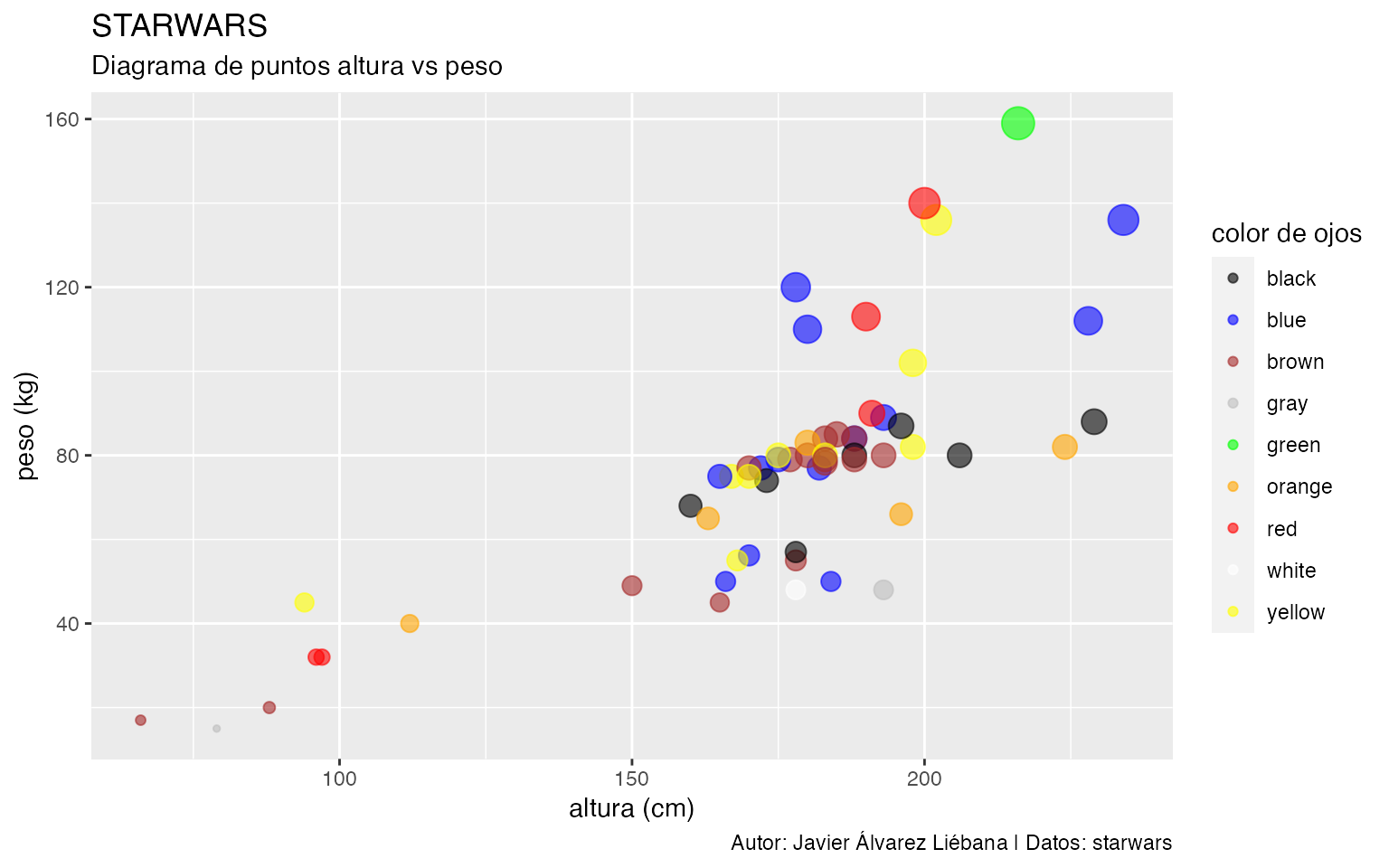
📝Ejercicio 8: repite el gráfico anterior explicitando los cortes en los ejes con
scale_x_continuous() y scale_y_continuous(): el eje X de 60 a 240 (de 30 en 30 cada marca), el eje Y de 20 a 160 (de 20 en 20 cada marca).
- Solución:
ggplot(starwars_filtro,
aes(x = height, y = mass,
size = mass, color = eye_color)) +
geom_point(alpha = 0.6) +
guides(size = "none") +
scale_color_manual(values =
c("black", "blue", "brown", "gray", "green",
"orange", "red", "white", "yellow")) +
scale_y_continuous(breaks = seq(20, 160, by = 20)) +
scale_x_continuous(breaks = seq(60, 240, by = 30)) +
labs(color = "color de ojos",
x = "altura (cm)", y = "peso (kg)",
title = "STARWARS",
subtitle = "Diagrama de puntos altura vs peso",
caption = "Autor: Javier Álvarez Liébana | Datos: starwars")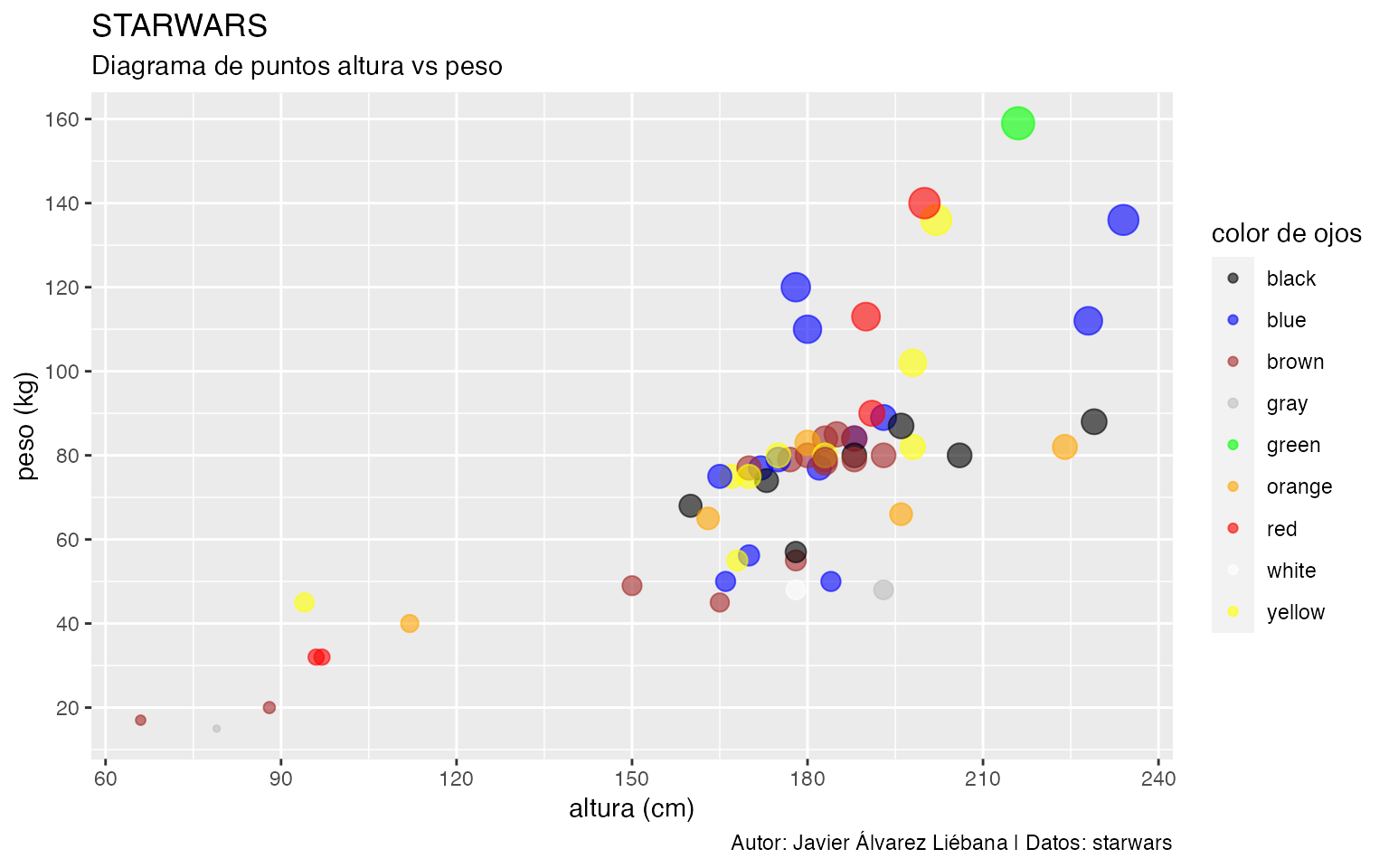
📝Ejercicio 9: del conjunto de datos original, elimina los registros que tengan ausente la variable
sex. Agrupa por dicha variable y contabiliza los personajes de cada sexo. Visualízalo en un diagrama de barras vertical, con la escala de colores de scale_fill_tableau(), cambiando el nombre de leyenda y de ejes, y poniéndo títulos y subtítulos.
- Solución:
library(ggthemes)
starwars_filtro <- starwars %>% drop_na(sex)
# Vertical
ggplot(starwars_filtro %>% group_by(sex) %>% count(),
aes(x = sex, y = n, fill = sex)) +
geom_col() +
scale_fill_tableau() +
labs(fill = "Sexo",
x = "Sexo", y = "Número de personajes",
title = "STARWARS",
subtitle = "Diagrama de barras verticales",
caption = "Autor: Javier Álvarez Liébana | Datos: starwars")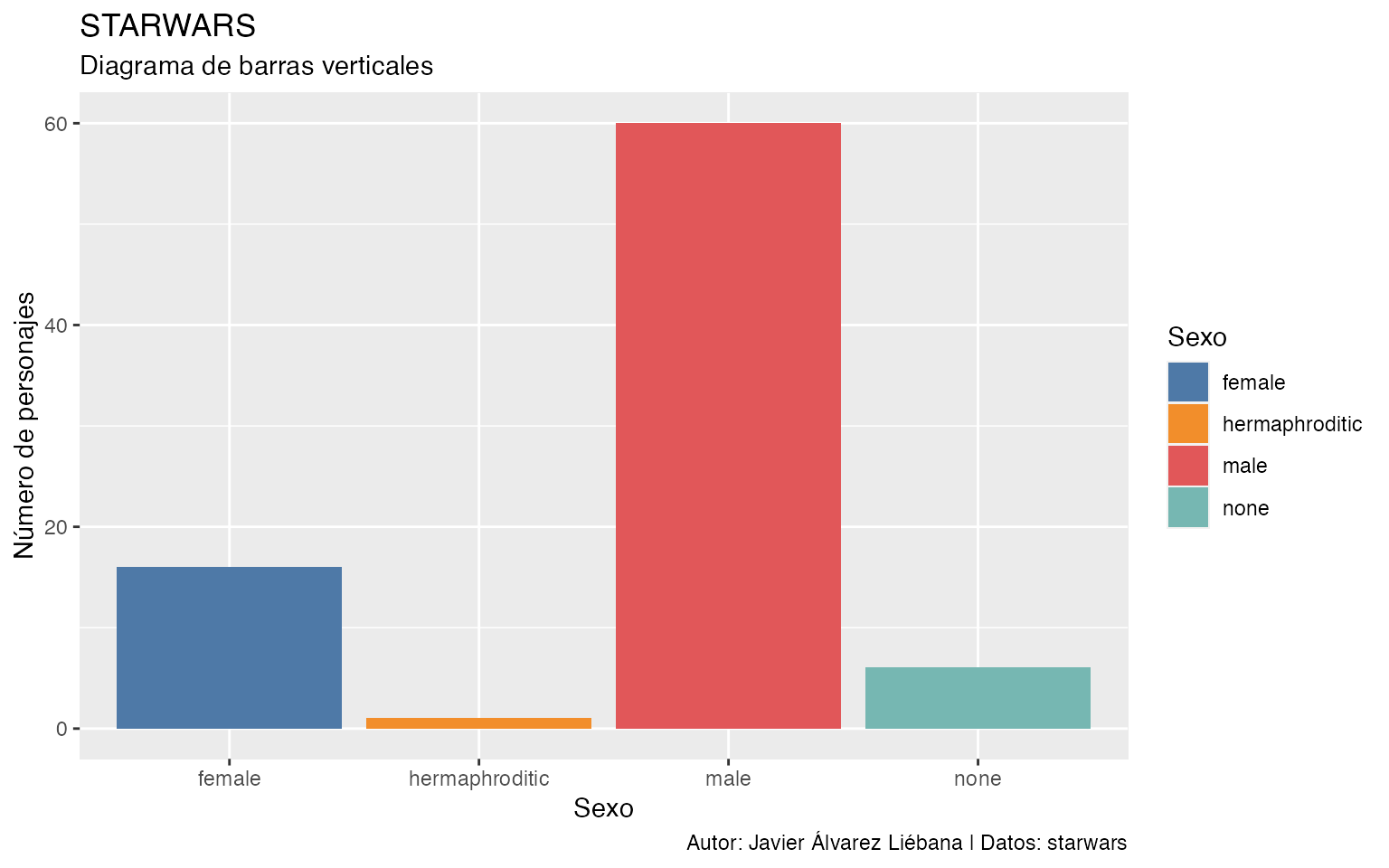
# Horizontal
ggplot(starwars_filtro %>% group_by(sex) %>% count(),
aes(x = sex, y = n, fill = sex)) +
geom_col() +
coord_flip() +
scale_fill_tableau() +
labs(fill = "Sexo",
x = "Sexo", y = "Número de personajes",
title = "STARWARS",
subtitle = "Diagrama de barras vertical",
caption = "Autor: Javier Álvarez Liébana | Datos: starwars")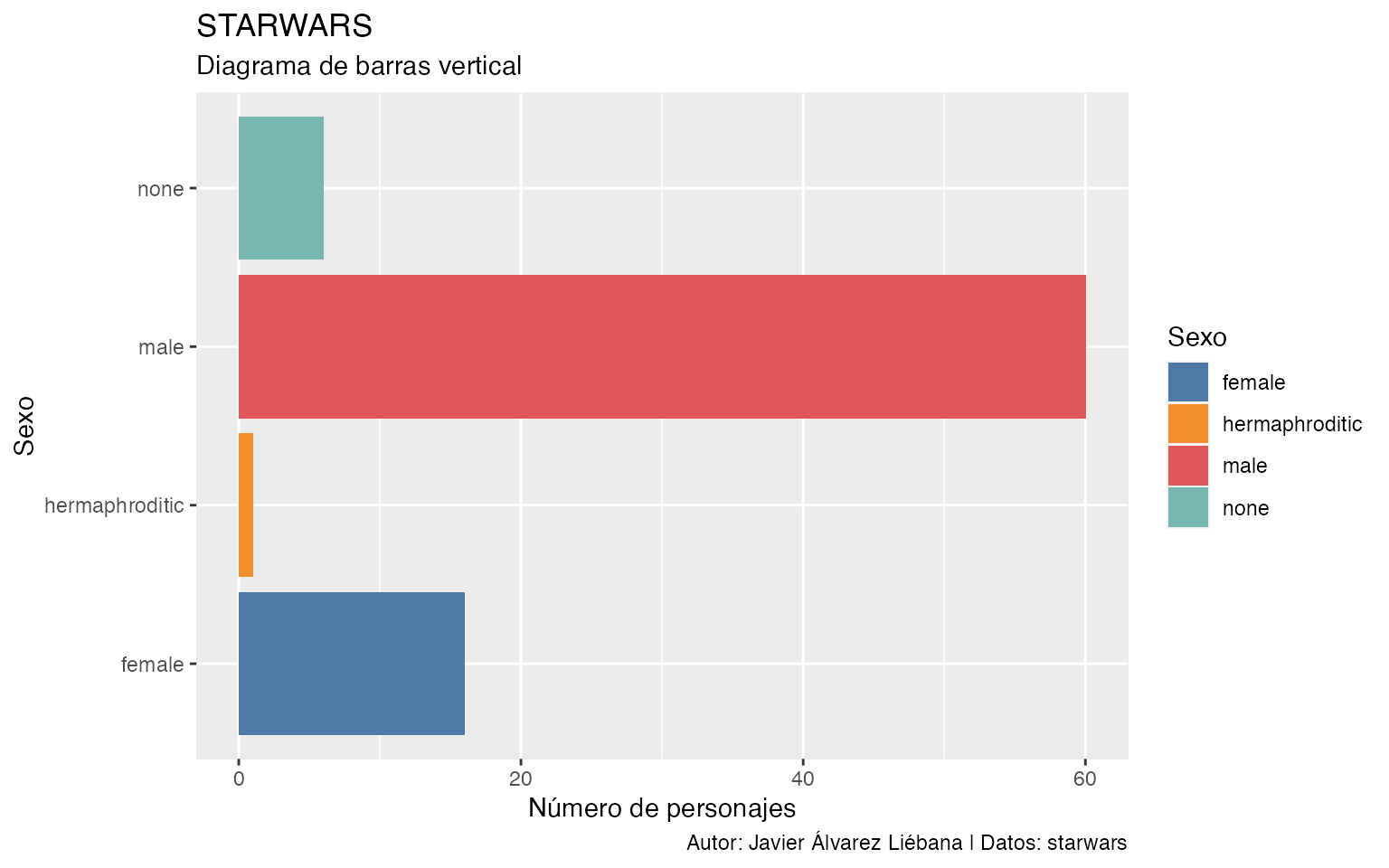
Profundizando en ggplot2
Scripts usados:
- script22.R: profundizando en ggplot2. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script22.
(haz click en las flechas para ver soluciones)
El ejercicio está basado en el gráfico de Tobias Stadler, cuyo código original puedes encontrarlo en Github, al tutorial de Tomás Capretto y al material en R Graph Gallery.
Se ruega citar la autoría del gráfico añadiendo el siguiente caption
caption_chart <- "Dataviz by Tobias Stalder\ntobias-stalder.netlify.app\nSource: TidyX Crew (Ellis Hughes, Patrick Ward)\n Data: github.com/rfordatascience/tidytuesday/blob/master/data/2020/2020-11-24/readme.md"Los datos provienen originalmente de la «Washington Trails Association», con datos de sendas de senderismo en Washington. Tienes el archivo hiking.csv en la carpeta DATOS. Los datos han sido descargados desde https://github.com/rfordatascience/tidytuesday/blob/master/data/2020/2020-11-24
📝Ejercicio 1: carga los datos
hiking.csv y muestra las variables.
- Solución:
## # A tibble: 1,958 × 8
## name location length gain highpoint rating features description
## <chr> <chr> <chr> <dbl> <dbl> <dbl> <lgl> <chr>
## 1 Lake H… Puget Sound… 2.3 mi… 50 330 3.67 NA "Hike through a…
## 2 Snow L… Snoqualmie … 7.2 mi… 1800 4400 4.16 NA "A relatively s…
## 3 Skooku… Mount Raini… 7.8 mi… 300 2550 3.68 NA "Choose between…
## 4 Teneri… Snoqualmie … 5.6 mi… 1585 2370 3.92 NA "You'll work up…
## 5 Twin F… Snoqualmie … 2.6 mi… 500 1000 4.14 NA "Visit a trio (…
## 6 Chenui… Mount Raini… 8.0 mi… 500 2200 3.14 NA "A long walk (o…
## 7 Old Mi… Mount Raini… 3.4 mi… 425 2150 5 NA "An infrequentl…
## 8 Flamin… Puget Sound… 4.0 mi… 450 425 2.68 NA "The striking n…
## 9 Salmon… North Casca… 5.4 mi… 300 2400 4 NA "With gentle te…
## 10 May Va… Issaquah Al… 6.6 mi… 1684 2024 2.96 NA "This forested …
## # … with 1,948 more rows
glimpse(hike_data)## Rows: 1,958
## Columns: 8
## $ name <chr> "Lake Hills Greenbelt", "Snow Lake", "Skookum Flats", "Ten…
## $ location <chr> "Puget Sound and Islands -- Seattle-Tacoma Area", "Snoqual…
## $ length <chr> "2.3 miles, roundtrip", "7.2 miles, roundtrip", "7.8 miles…
## $ gain <dbl> 50, 1800, 300, 1585, 500, 500, 425, 450, 300, 1684, 80, 65…
## $ highpoint <dbl> 330, 4400, 2550, 2370, 1000, 2200, 2150, 425, 2400, 2024, …
## $ rating <dbl> 3.67, 4.16, 3.68, 3.92, 4.14, 3.14, 5.00, 2.68, 4.00, 2.96…
## $ features <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ description <chr> "Hike through a pastoral area first settled and farmed in …
📝Ejercicio 2: transforma la variable
location para obtener la region (es la primera palabra, antes del " -- ". Para ello puedes usar la función word(), que nos permite seleccionar la palabra enésima de una frase, indicándole en sep = ... el separado entre palabra y palabra. Conviértela a factor la nueva variable region.
- Solución:
hike_data <-
hike_data %>%
mutate(region = as_factor(word(location, 1, sep = " -- ")))
📝Ejercicio 3: transforma la variable
length para obtener la longitud en millas de la ruta. Está en formato "12.7 miles, roundtrip", así que puedes volver a usar la función word(), y pasar luego la cadena de texto a número.
- Solución:
hike_data <-
hike_data %>%
mutate(miles = as.numeric(word(length, 1)))
📝Ejercicio 4: calcula la longitud total (acumulada) y la media de desnivel (
gain), con las rutas agrupadas por la variable region, así como el número de rutas por región.
- Solución:
resumen <-
hike_data %>%
group_by(region) %>%
summarise(sum_miles = sum(miles),
mean_gain = round(mean(as.numeric(gain))),
n = n())
resumen## # A tibble: 11 × 4
## region sum_miles mean_gain n
## <fct> <dbl> <dbl> <int>
## 1 Puget Sound and Islands 810. 452 191
## 2 Snoqualmie Region 1915. 2206 219
## 3 Mount Rainier Area 1602. 1874 196
## 4 North Cascades 3347. 2500 301
## 5 Issaquah Alps 383. 973 77
## 6 Central Washington 453. 814 80
## 7 South Cascades 1630. 1649 193
## 8 Central Cascades 2131. 2260 226
## 9 Southwest Washington 825. 1185 123
## 10 Olympic Peninsula 1700. 1572 209
## 11 Eastern Washington 1334. 1591 143
📝Ejercicio 5: dibuja un diagrama de barras con la región en el eje X, la suma de millas en el eje Y y el relleno en función del número de rutas.
- Solución:
ggplot(resumen,
aes(x = region, y = sum_miles, fill = n)) +
geom_col() +
labs(caption = caption_chart)
📝Ejercicio 6: repite el ejercicio anterior pero personaliza el tema dando un título a los ejes y una fuente de tamaño adecuada para el eje X. Usa la función
str_wrap() para convertir los nombres de regiones en párrafos con salto de línea, indicándole en width la anchura máxima (no romperá palabras a mitad).
- Solución:
ggplot(resumen,
aes(x = str_wrap(region, width = 7),
y = sum_miles, fill = n)) +
geom_col() +
labs(caption = caption_chart,
fill = "Nº de rutas",
y = "Suma acumulada de millas",
x = "Región") +
theme(axis.title.x = element_text(face = "bold", size = 13),
axis.title.y = element_text(face = "bold", size = 13),
axis.text.x = element_text(face = "bold", size = 9),
axis.text.y = element_text(face = "bold", size = 9))
📝Ejercicio 7: repite el ejercicio anterior pero usando
scale_fill_gradientn() para dar una escala de colores continua (en forma de gradiente) con cuatro colores. Introduce en geom_col() una transparencia de alpha = 0.8
- Solución:
gg <-
ggplot(resumen,
aes(x = str_wrap(region, width = 7),
y = sum_miles, fill = n)) +
geom_col(alpha = 0.8) +
scale_fill_gradientn("Cantidad de rutas",
colours =
c("#6C5B7B", "#C06C84", "#F67280", "#F8B195")) +
labs(caption = caption_chart,
fill = "Nº de rutas",
y = "Suma acumulada de millas",
x = "Región") +
theme(axis.title.x = element_text(face = "bold", size = 13),
axis.title.y = element_text(face = "bold", size = 13),
axis.text.x = element_text(face = "bold", size = 9),
axis.text.y = element_text(face = "bold", size = 9))
gg
📝Ejercicio 8: usa
geom_point() para añadir al gráfico anterior la media de desnivel de las rutas. Pon por ejemplo size = 3, alpha = 0.85 y color = "gray20".
- Solución:
gg <-
gg +
geom_point(aes(x = str_wrap(region, 7), y = mean_gain),
size = 3, color = "gray20", alpha = 0.85)
gg
📝Ejercicio 9: usa
coord_polar() para convertir el gráfico anterior a coordenadas polares.
- Solución:
gg <- gg + coord_polar()
gg
📝Ejercicio 10: usa
geom_segment() para añadir líneas que vayan del centro hacía fuera, pasando por los puntos de desnivel. Hay que pensar que lo tuviésemos en vertical, indicándole la posición inicial x y final xend del segmento (en este caso, para cada región, así que x = str_wrap(region, 7)), y la posición inicial y = 0 e yend un poco más que el máximo de desnivel.
- Solución:
gg <- gg +
geom_segment(aes(x = str_wrap(region, 7), y = 0,
xend = str_wrap(region, 7),
yend = max(mean_gain) * 1.2),
linetype = "dashed", color = "gray20")
gg
📝Ejercicio 11: ordena los gajos en orden ascendente con
reorder().
- Solución:
gg <-
ggplot(resumen,
aes(x = reorder(str_wrap(region, width = 7), sum_miles),
y = sum_miles, fill = n)) +
geom_col(alpha = 0.8) +
scale_fill_gradientn("Cantidad de rutas",
colours =
c("#6C5B7B", "#C06C84", "#F67280", "#F8B195")) +
labs(caption = caption_chart,
fill = "Nº de rutas",
y = "Suma acumulada de millas",
x = "Región") +
theme(axis.title.x = element_text(face = "bold", size = 10),
axis.title.y = element_text(face = "bold", size = 10),
axis.text.x = element_text(face = "bold", size = 7),
axis.text.y = element_text(face = "bold", size = 7)) +
geom_point(aes(x = reorder(str_wrap(region, 7), sum_miles),
y = mean_gain),
size = 3, color = "gray20", alpha = 0.85) +
coord_polar() +
geom_segment(aes(x = reorder(str_wrap(region, 7), sum_miles),
y = 0,
xend = str_wrap(region, 7),
yend = max(mean_gain) * 1.2),
linetype = "dashed", color = "gray20")
gg
📝Ejercicio 12: con
annotate() añade en uno de los gajos la indicación de que la altura hasta el punto nos indica el desnivel medio. Usaremos además la fuente "Libre Caslon Text", muy similar a la del gráfico original
- Solución:
library(sysfonts)
library(showtext)
font_add_google(family = "Libre Caslon Text",
name = "Libre Caslon Text")
showtext_auto()
gg <- gg +
annotate(x = 11.2, y = 1500, label = "Desnivel medio",
geom = "text", angle = -78, color = "gray20",
size = 2, family = "Libre Caslon Text")
gg
📝Ejercicio 13: con
annotate() añade en uno de los gajos la indicación de que el radio del gajo nos indica la longitud acumulada de las rutas de esa región. Usaremos además la fuente "Libre Caslon Text", muy similar a la del gráfico original
- Solución:
library(sysfonts)
library(showtext)
font_add_google(family = "Libre Caslon Text",
name = "Libre Caslon Text")
showtext_auto()
gg <- gg +
annotate(x = 11, y = 3200, label = "Longitud acum.",
geom = "text", angle = 18, color = "gray20",
size = 2, family = "Libre Caslon Text")
gg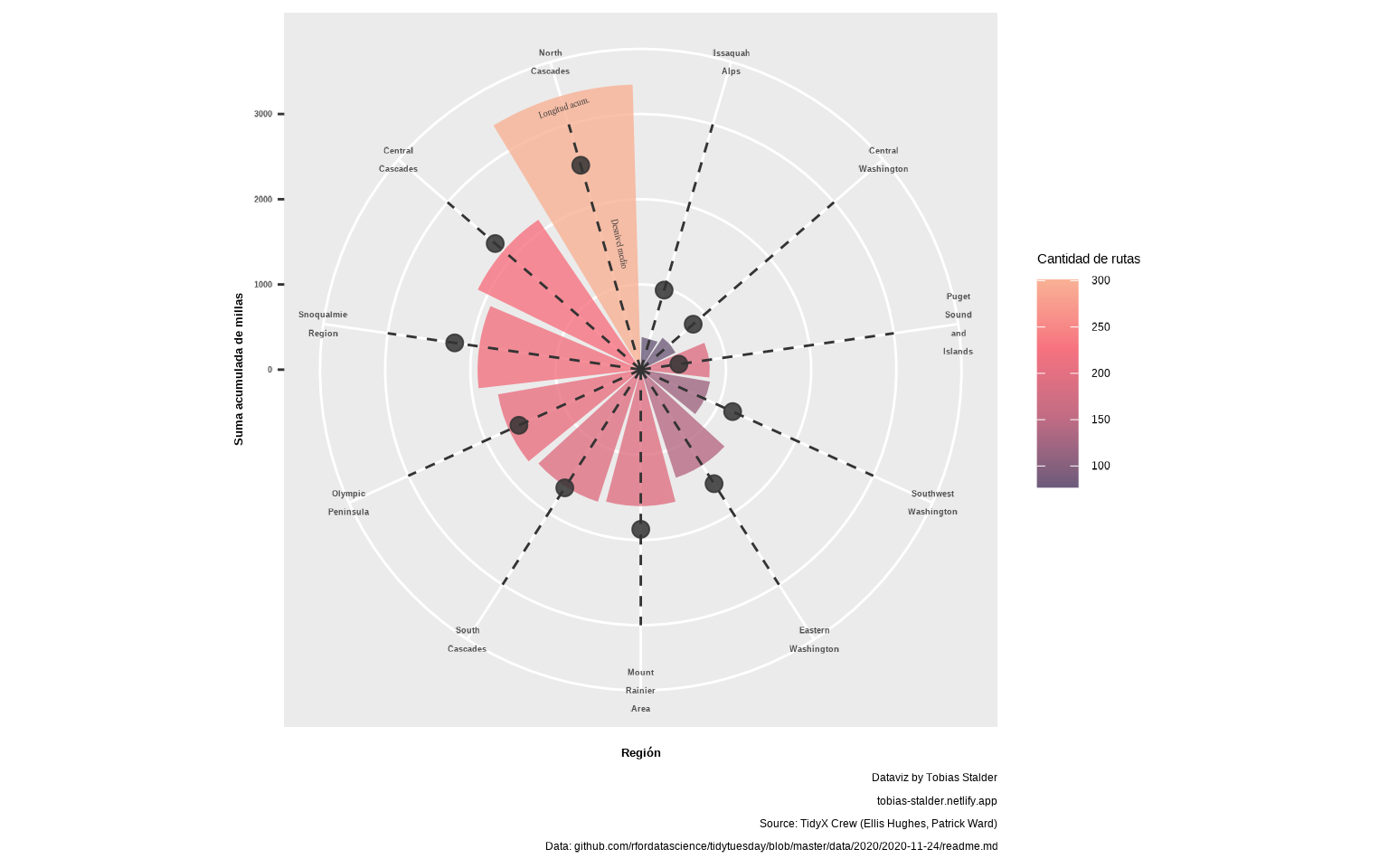
Por último hacemos que los gajos no empiecen del centro, y añadimos algún ajuste estético más (ver el post original)
gg +
scale_y_continuous(limits = c(-1500, 3500),
expand = c(0, 0),
breaks = c(0, 1000, 2000, 3000)) +
# Make the guide for the fill discrete
guides(fill =
guide_colorsteps(barwidth = 11, barheight = 0.7,
title.position = "top",
title.hjust = .5)) +
labs(title = "Senderismo en Washington",
caption = caption_chart) +
theme(text = element_text(color = "gray20",
family = "Libre Caslon Text"),
legend.position = "bottom",
panel.background =
element_rect(fill = "white", color = "white"),
panel.grid = element_blank(),
panel.grid.major.x = element_blank())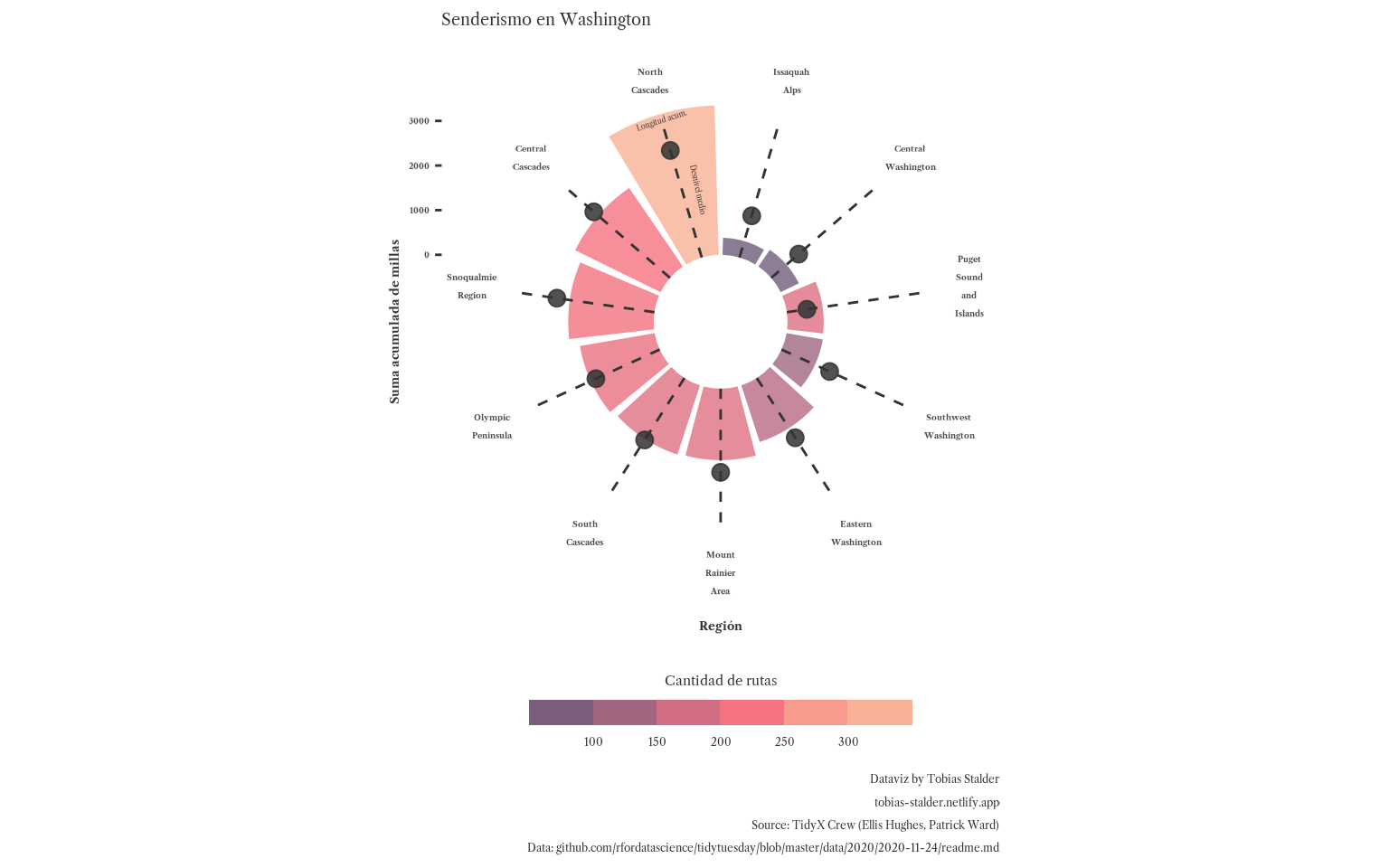
Extrayendo información: estadística descriptiva con cualitativas
Scripts usados:
- script23.R: intro a la descriptiva con cualitativas. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script23.R
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: usando dplyr de
{tidvyerse} calcula la tabla de frecuencias absolutas de la variableskin_color del conjunto de datos de starwars.
- Solución:
## # A tibble: 31 × 2
## skin_color n
## <chr> <int>
## 1 blue 2
## 2 blue, grey 2
## 3 brown 4
## 4 brown mottle 1
## 5 brown, white 1
## 6 dark 6
## 7 fair 17
## 8 fair, green, yellow 1
## 9 gold 1
## 10 green 6
## # … with 21 more rows
📝Ejercicio 2: repite el ejercicio anterior pero reagrupa los niveles poco frecuentes (poco frecuente definido como que aparezca dos o menos veces) con
fct_lump_min().
- Solución:
## # A tibble: 8 × 2
## fskin_color n
## <fct> <int>
## 1 brown 4
## 2 dark 6
## 3 fair 17
## 4 green 6
## 5 grey 6
## 6 light 11
## 7 pale 5
## 8 Other 32
📝Ejercicio 3: añade a la tabla anterior la tabla de frecuencias relativas de la columna
skin_color.
- Solución:
freq_skin <-
starwars %>%
mutate(fskin_color =
fct_lump_min(skin_color, min = 3)) %>%
count(fskin_color) %>%
rename(ni = n) %>%
mutate(fi = ni / sum(ni))
freq_skin## # A tibble: 8 × 3
## fskin_color ni fi
## <fct> <int> <dbl>
## 1 brown 4 0.0460
## 2 dark 6 0.0690
## 3 fair 17 0.195
## 4 green 6 0.0690
## 5 grey 6 0.0690
## 6 light 11 0.126
## 7 pale 5 0.0575
## 8 Other 32 0.368
📝Ejercicio 4: recategoriza la variable
height usando la función cut con 6 cortes (filtrando antes los valores ausentes). Formatea esa nueva columna como un factor, calculando sus frecuencias y agrupa para no tener clases con menos de 7 valores.
- Solución:
starwars_fheight <-
starwars %>%
filter(!is.na(height)) %>%
mutate(fheight = factor(cut(height, breaks = 6)))
# Frecuencias
fct_count(starwars_fheight$fheight)## # A tibble: 6 × 2
## f n
## <fct> <int>
## 1 (65.8,99] 7
## 2 (99,132] 2
## 3 (132,165] 10
## 4 (165,198] 51
## 5 (198,231] 9
## 6 (231,264] 2
# Reagrupamos
starwars_fheight <-
starwars_fheight %>%
mutate(fheight =
fct_lump_min(fheight, min = 7,
other_level = "otros"))
fct_count(starwars_fheight$fheight)## # A tibble: 5 × 2
## f n
## <fct> <int>
## 1 (65.8,99] 7
## 2 (132,165] 10
## 3 (165,198] 51
## 4 (198,231] 9
## 5 otros 4
📝Ejercicio 5: genera las frecuencias acumuladas resultantes de la columna recategorizada del ejercicio anterior.
- Solución:
freq_fheight <-
starwars_fheight %>%
count(fheight) %>%
rename(ni = n) %>%
mutate(fi = ni / sum(ni),
Ni = cumsum(ni),
Fi = cumsum(fi))
freq_fheight## # A tibble: 5 × 5
## fheight ni fi Ni Fi
## <fct> <int> <dbl> <int> <dbl>
## 1 (65.8,99] 7 0.0864 7 0.0864
## 2 (132,165] 10 0.123 17 0.210
## 3 (165,198] 51 0.630 68 0.840
## 4 (198,231] 9 0.111 77 0.951
## 5 otros 4 0.0494 81 1Extrayendo información: estadística descriptiva con cuantitativas continuas
Scripts usados:
- script24.R: intro a la descriptiva con cuantitativas continuas. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script24.R
(haz click en las flechas para ver soluciones)
En la carpeta DATOS, en el fichero coches.csv, dispones de una tabla que contiene información de distintos tipos de vehículos. La información que contiene es:
-
name: nombre del vehículo -
sports_car, suv, wagon, minivan, pickup, all_wheel, rear_wheel: variables lógicas, nos dicen si son de ese tipo o no. -
msrp: precio de fábrica -
dealer_cost: precio de coste -
eng_size: tamaño del motor -
ncyl: número de cilindros -
city_mpg, hwy_mpg: consumo en distintos entornos -
weight, wheel_base, length, width: distintas medidas de dimensión del vehículo
📝Ejercicio 1: genera una columna de tipo factor que aglutine las columnas binarias
sports_car, suv, wagon, minivan, pickup en una sola que contenga el tipo (por ejemplo, si suv es TRUE, esa columna contendrá "suv")
- Solución:
library(tidyverse)
coches <- read_csv("./DATOS/coches.csv")
coches <-
coches %>%
mutate(tipo =
case_when(sports_car ~ "sports_car",
suv ~ "suv",
wagon ~ "wagon",
minivan ~ "minivan",
pickup ~ "pickup",
all_wheel ~ "all_wheel",
rear_wheel ~ "rear_wheel",
TRUE ~ "otros"),
tipo = as_factor(tipo)) %>%
select(-c(sports_car, suv, wagon, minivan, pickup))
fct_count(coches$tipo)## # A tibble: 8 × 2
## f n
## <fct> <int>
## 1 otros 166
## 2 all_wheel 25
## 3 rear_wheel 54
## 4 sports_car 49
## 5 suv 60
## 6 wagon 30
## 7 minivan 20
## 8 pickup 24
📝Ejercicio 2: para ver si hay diferencia de consumo, ¿podrías calcular la media y desviación de
city_mpg y hwy_mpg? Haz un diagrama que permita hacernos una idea de cómo se distribuye el consumo.
- Solución:
coches %>%
summarise_at(vars(c("city_mpg", "hwy_mpg")),mean, na.rm = TRUE)## # A tibble: 1 × 2
## city_mpg hwy_mpg
## <dbl> <dbl>
## 1 20.1 26.9
coches %>%
summarise_at(vars(c("city_mpg", "hwy_mpg")),
sd, na.rm = TRUE)## # A tibble: 1 × 2
## city_mpg hwy_mpg
## <dbl> <dbl>
## 1 5.21 5.70
# densidades
ggplot(coches %>%
pivot_longer(cols = c("city_mpg", "hwy_mpg"),
names_to = "consumo",
values_to = "values") %>%
drop_na(values),
aes(x = values, fill = consumo)) +
geom_density(alpha = 0.5) +
scale_fill_discrete(labels = c("Ciudad", "Autopista"))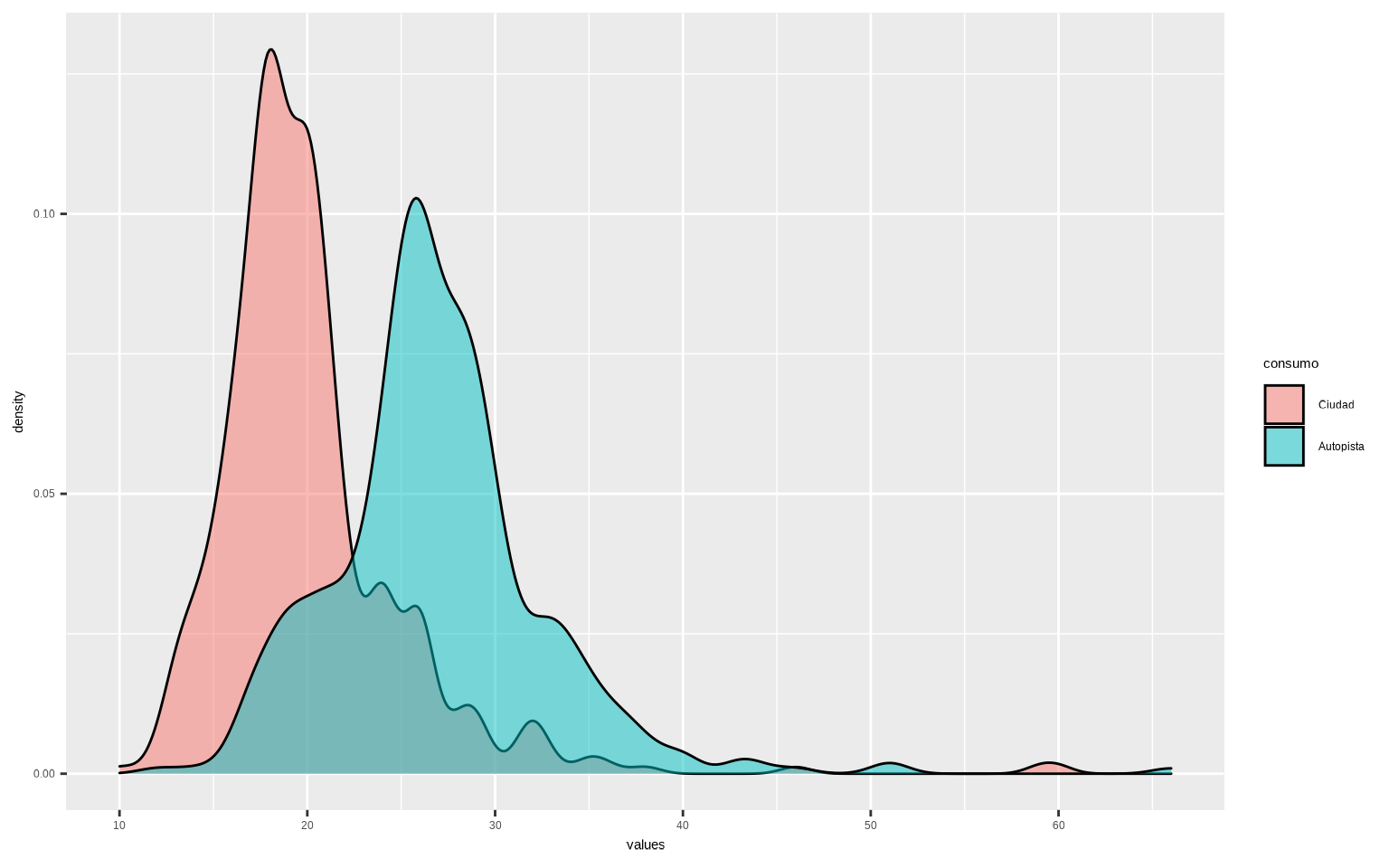
labs(y = "densidad", x = "consumo (mpg)",
fill = "Consumo")## $y
## [1] "densidad"
##
## $x
## [1] "consumo (mpg)"
##
## $fill
## [1] "Consumo"
##
## attr(,"class")
## [1] "labels"
📝Ejercicio 3: para ver si hay diferencia de consumo por tipo de coche, calcula la media de
city_mpg y hwy_mpg para los distintos tipos de coche.
- Solución:
coches %>%
group_by(tipo) %>%
summarise_at(vars(c("city_mpg", "hwy_mpg")),
c(mean = mean, sd = sd), na.rm = TRUE)## # A tibble: 8 × 5
## tipo city_mpg_mean hwy_mpg_mean city_mpg_sd hwy_mpg_sd
## <fct> <dbl> <dbl> <dbl> <dbl>
## 1 otros 23.6 31.3 6.19 5.49
## 2 all_wheel 18.6 25.8 1.71 1.83
## 3 rear_wheel 18.0 25.5 1.48 2.35
## 4 sports_car 18.6 25.7 2.53 2.72
## 5 suv 16.2 20.6 2.73 3.22
## 6 wagon 21.0 27.8 4.22 4.45
## 7 minivan 17.9 24.4 1.45 2.46
## 8 pickup 16.7 21.2 3.24 3.82
ggplot(coches %>% filter(tipo != "otros") %>%
pivot_longer(cols = c("city_mpg", "hwy_mpg"),
names_to = "consumo",
values_to = "values") %>%
drop_na(values), aes(x = values, fill = consumo)) + geom_density(alpha = 0.5) + facet_wrap( ~ tipo)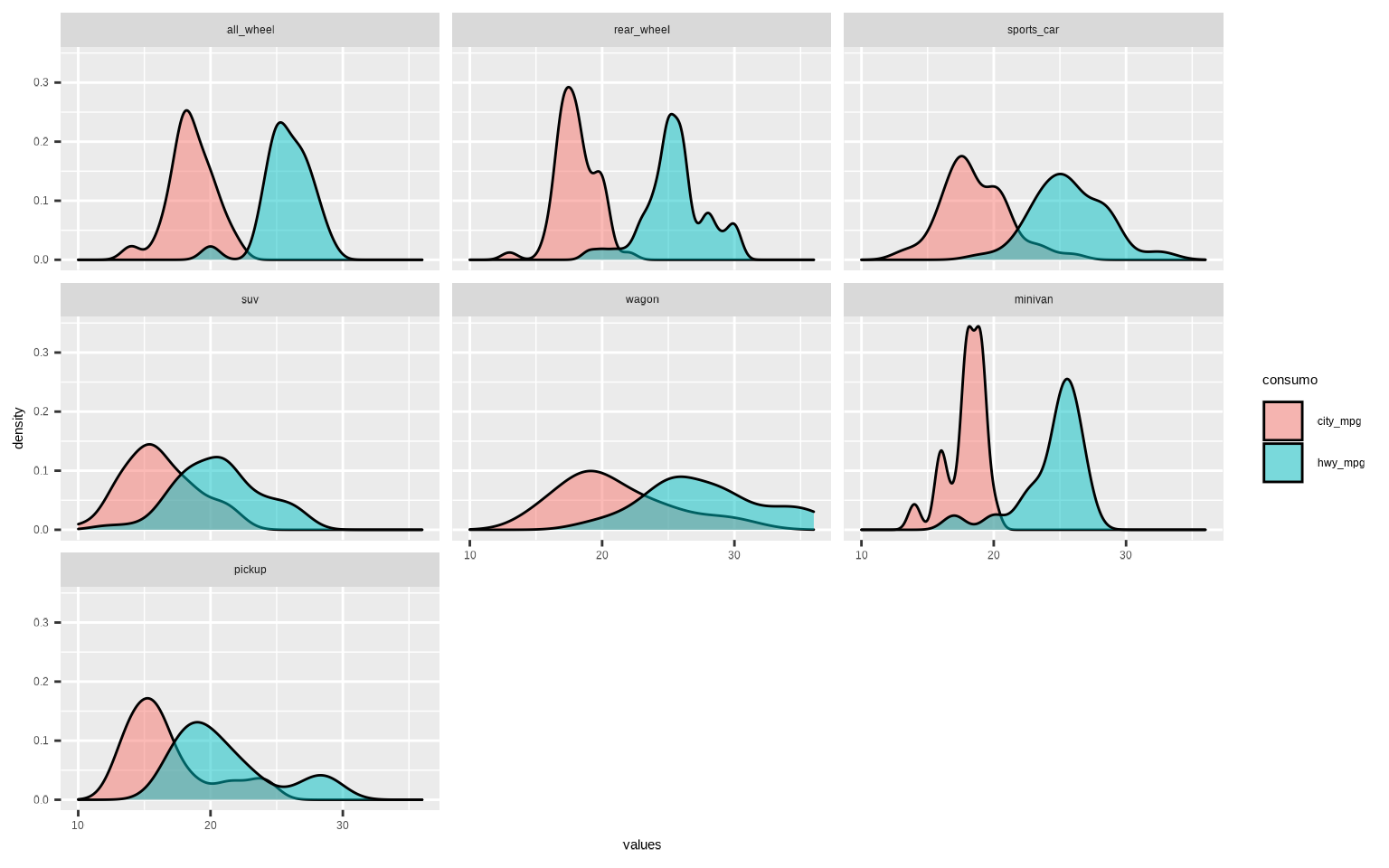
📝Ejercicio 4: a la vista de los resultados previos, seleccionar los 3 tipos de mayor consumo, filtra la tabla y representa la variable
cyl con un gráfico de violín
- Solución:
coches_filtro <-
coches %>%
filter(tipo %in%
c("wagon", "all_wheel", "sports_car"))
library(ggthemes)
ggplot(coches_filtro,
aes(x = tipo, y = ncyl,
fill = tipo, color = tipo)) +
geom_violin(alpha = 0.5, bw = 0.5) +
scale_fill_tableau(labels = c("todo terreno",
"deportivo",
"ranchera/familiar")) +
scale_color_tableau() +
guides(color = "none") +
scale_x_discrete(labels = c("todo terreno", "deportivo",
"ranchera/familiar")) +
labs(fill = "Tipos de coche",
x = "Tipos de coche", y = "Cilindrada")
Resumiendo y relacionado datos
Scripts usados:
- script25.R: resumiendo y relacionando datos. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script25.R
en construcción (cuarteto de anscombe)