Capítulo 22 Profundizando en ggplot2
Scripts usados:
- script22.R: profundizando en tidyverse. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script22.R
22.1 Personalizando el tema
22.1.1 Datos
En est ocasión vamos a usar los datos de Netflix proporcionados por Paula Casado en El Arte del Dato, página en la que se basará esta visualización: visualizaremos el número de películas y series de instituto que se han estrenado en Netflix en cada año.
netflix <-
read_csv('https://raw.githubusercontent.com/elartedeldato/datasets/main/netflix_titles.csv')
netflix## # A tibble: 7,787 × 12
## show_id type title director cast country date_added release_year rating
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <chr>
## 1 s1 TV Show 3% <NA> João … Brazil August 14… 2020 TV-MA
## 2 s2 Movie 7:19 Jorge Mi… Demiá… Mexico December … 2016 TV-MA
## 3 s3 Movie 23:59 Gilbert … Tedd … Singap… December … 2011 R
## 4 s4 Movie 9 Shane Ac… Elija… United… November … 2009 PG-13
## 5 s5 Movie 21 Robert L… Jim S… United… January 1… 2008 PG-13
## 6 s6 TV Show 46 Serdar A… Erdal… Turkey July 1, 2… 2016 TV-MA
## 7 s7 Movie 122 Yasir Al… Amina… Egypt June 1, 2… 2019 TV-MA
## 8 s8 Movie 187 Kevin Re… Samue… United… November … 1997 R
## 9 s9 Movie 706 Shravan … Divya… India April 1, … 2019 TV-14
## 10 s10 Movie 1920 Vikram B… Rajne… India December … 2008 TV-MA
## # … with 7,777 more rows, and 3 more variables: duration <chr>,
## # listed_in <chr>, description <chr>Los datos provienen originalmente de Kaggle, y contienen las películas y series de Netflix hasta enero de 2021. Para visualizar vamos a filtrar las películas y series de instituto, usando la función str_detect() (del paquete stringr), que nos devolverá TRUE si detecta en la variable description (pasándola a mayúsculas) el patrón de texto "HIGH SCHOOL".
netflix_hs <- netflix %>%
filter(str_detect(toupper(description), "HIGH SCHOOL"))
netflix_hs ## # A tibble: 150 × 12
## show_id type title director cast country date_added release_year rating
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <chr>
## 1 s8 Movie 187 Kevin R… Samuel… United… November … 1997 R
## 2 s32 Movie #Frien… Rako Pr… Adipat… Indone… May 21, 2… 2018 TV-G
## 3 s34 Movie #reali… Fernand… Nesta … United… September… 2017 TV-14
## 4 s47 Movie 1 Chan… Adam De… Lexi G… United… July 1, 2… 2014 TV-PG
## 5 s48 Movie 1 Mile… Leif Ti… Billy … United… July 7, 2… 2017 TV-14
## 6 s56 Movie 100 Th… <NA> Isabel… United… November … 2014 TV-Y
## 7 s58 Movie 100% H… Jastis … Anisa … Indone… January 7… 2020 TV-14
## 8 s148 Movie A Baby… Rachel … Tamara… United… October 1… 2020 TV-PG
## 9 s251 Movie A Walk… Adam Sh… Mandy … United… July 1, 2… 2002 PG
## 10 s297 Movie Across… Julien … Sarah … Canada April 1, … 2015 TV-MA
## # … with 140 more rows, and 3 more variables: duration <chr>, listed_in <chr>,
## # description <chr>Tras dicho filtro vamos a añadir el año en el que se estrenó, con la función year() de lubridate, que nos devuelve el año de una fecha concreta. Esa fecha concreta la vamos a construir con mdy().
## [1] "2016-08-26"Como ves en netflix_final hemos eliminado aquellos registros de los que no tengamos su año de estreno.
22.1.2 Diagrama de barras
Tras la depuración vamos a
- agrupar por año con
group_by(year) - contar el número de elementos en cada uno con
count()
## # A tibble: 9 × 2
## year n
## <dbl> <int>
## 1 2011 2
## 2 2013 1
## 3 2015 1
## 4 2016 6
## 5 2017 18
## 6 2018 28
## 7 2019 42
## 8 2020 46
## 9 2021 6Con estos datos ya estamos condiciones de poder hacer nuestro diagrama de barras.
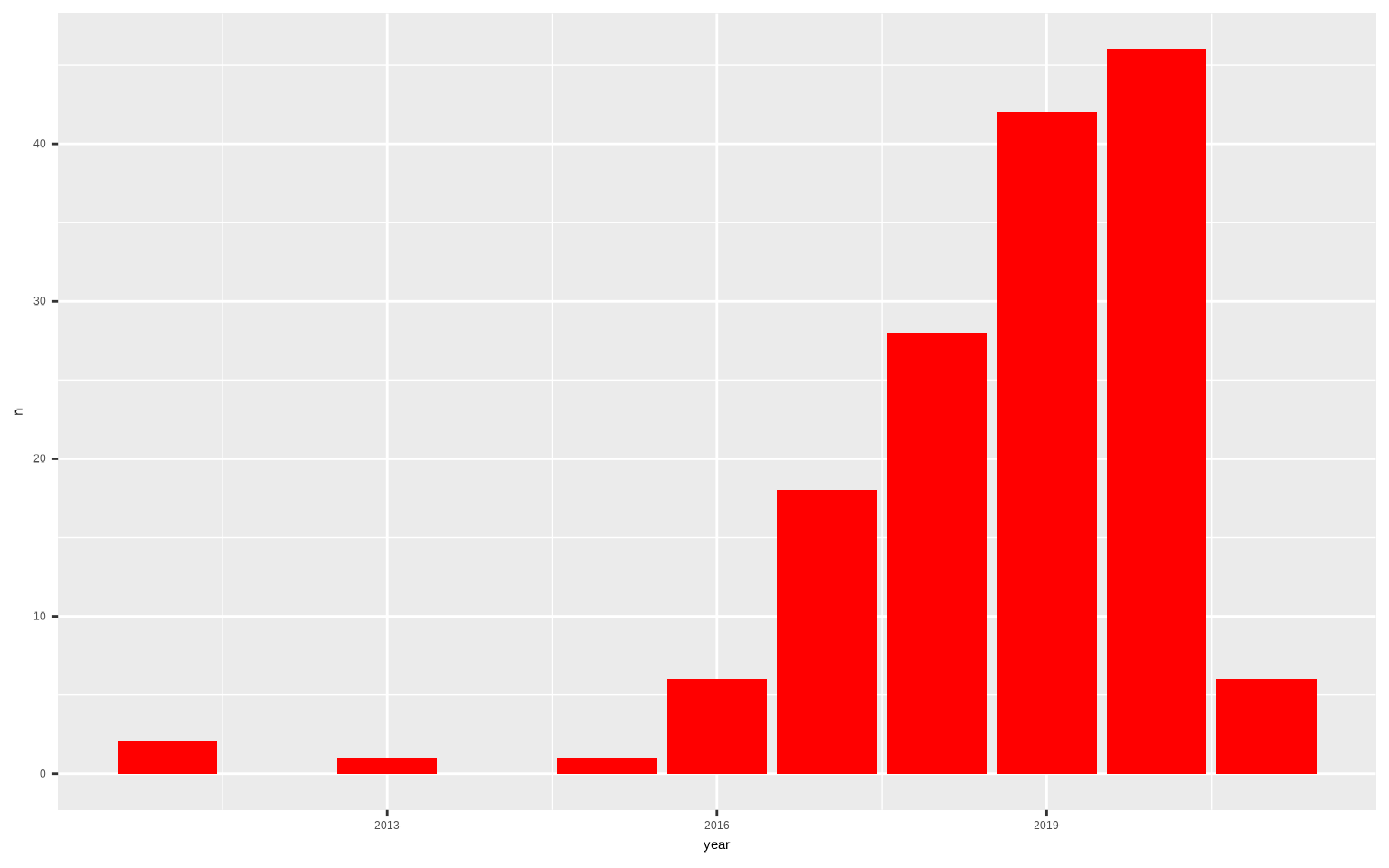
22.1.3 Modificando la escala de los ejes
Si te fijas solo nos ha mostrado algunos años en el eje X, así le vamos a indicar la escala concreta que queremos en dicho eje con scale_x_continuous(), usando el argumento breaks en el que le indicaremos los valores donde queremos que «corte» el eje X (los corte serán los años guardados en netflix_resumen$year)
ggplot(netflix_resumen, aes(x = year, y = n)) +
geom_col(fill = "red") +
scale_x_continuous(breaks = netflix_resumen$year)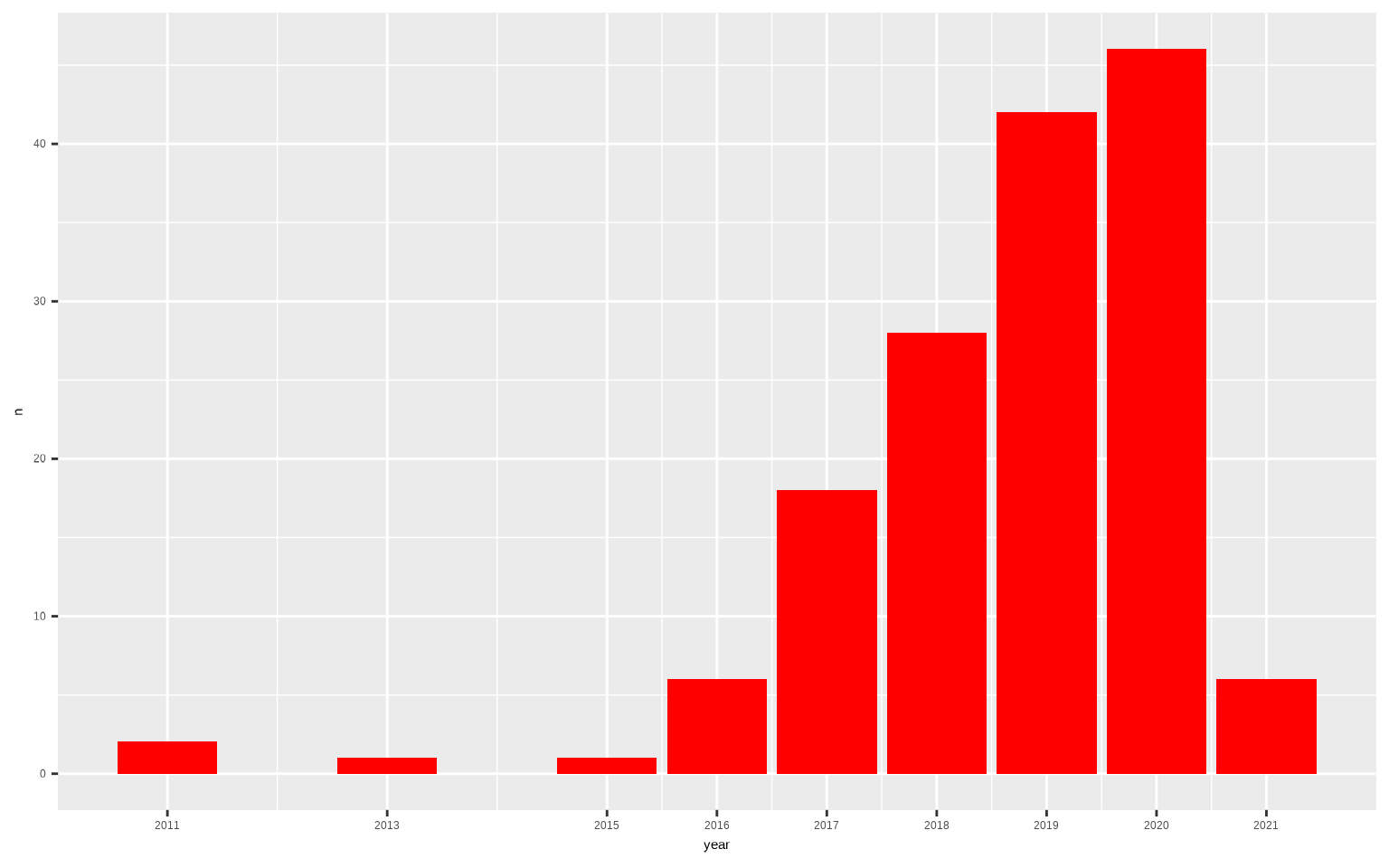
Cuando uno de los ejes representa una fecha podemos indicárselo con scale_x_date(), asigándole en date_breaks el lapso temporal que queremos en las marcas (por ejemplo, date_breaks = '1 month'). Como ejemplo, vamos a visualizar el número de películas y series generales estrenadas en Netflix desde el 1 de julio de 2020.
ggplot(netflix %>%
mutate(date_added = mdy(date_added)) %>%
filter(!is.na(date_added) &
date_added > as.Date("2020-07-01")) %>%
group_by(date_added) %>% count(),
aes(x = date_added, y = n)) +
geom_col(fill = "red") +
scale_x_date(date_breaks = '1 month') 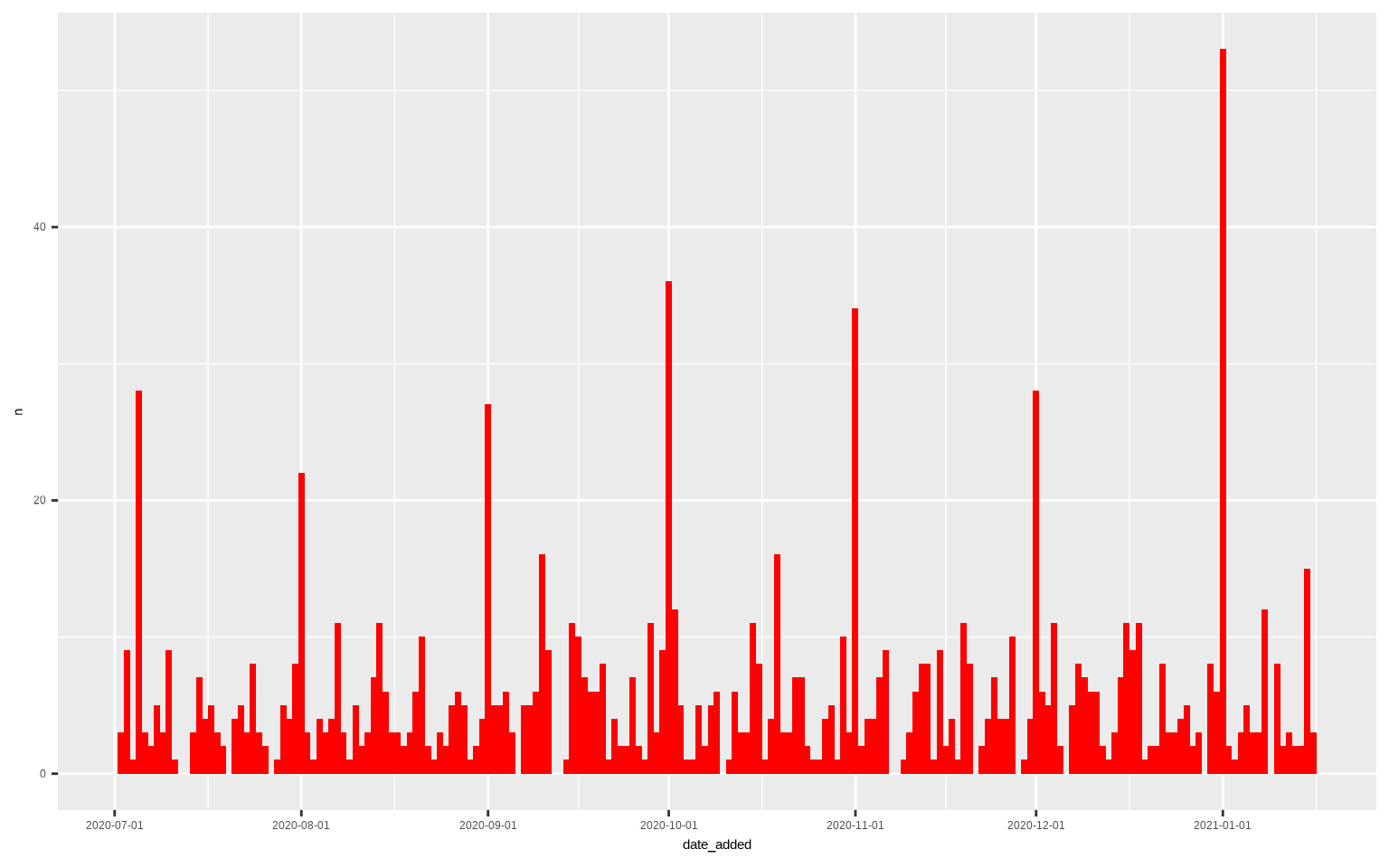
22.1.4 Personalizando tema
Lo primero que vamos a hacer es añadir título y otras opciones del tema que ya conocemos.
ggplot(netflix_resumen, aes(x = year, y = n)) +
geom_col(fill = "red") +
scale_x_continuous(breaks = netflix_resumen$year) +
labs(title = "NETFLIX",
subtitle = "Películas y series de instituto",
caption = "Basada en El Arte del Dato (https://elartedeldato.com) | Datos: Kaggle")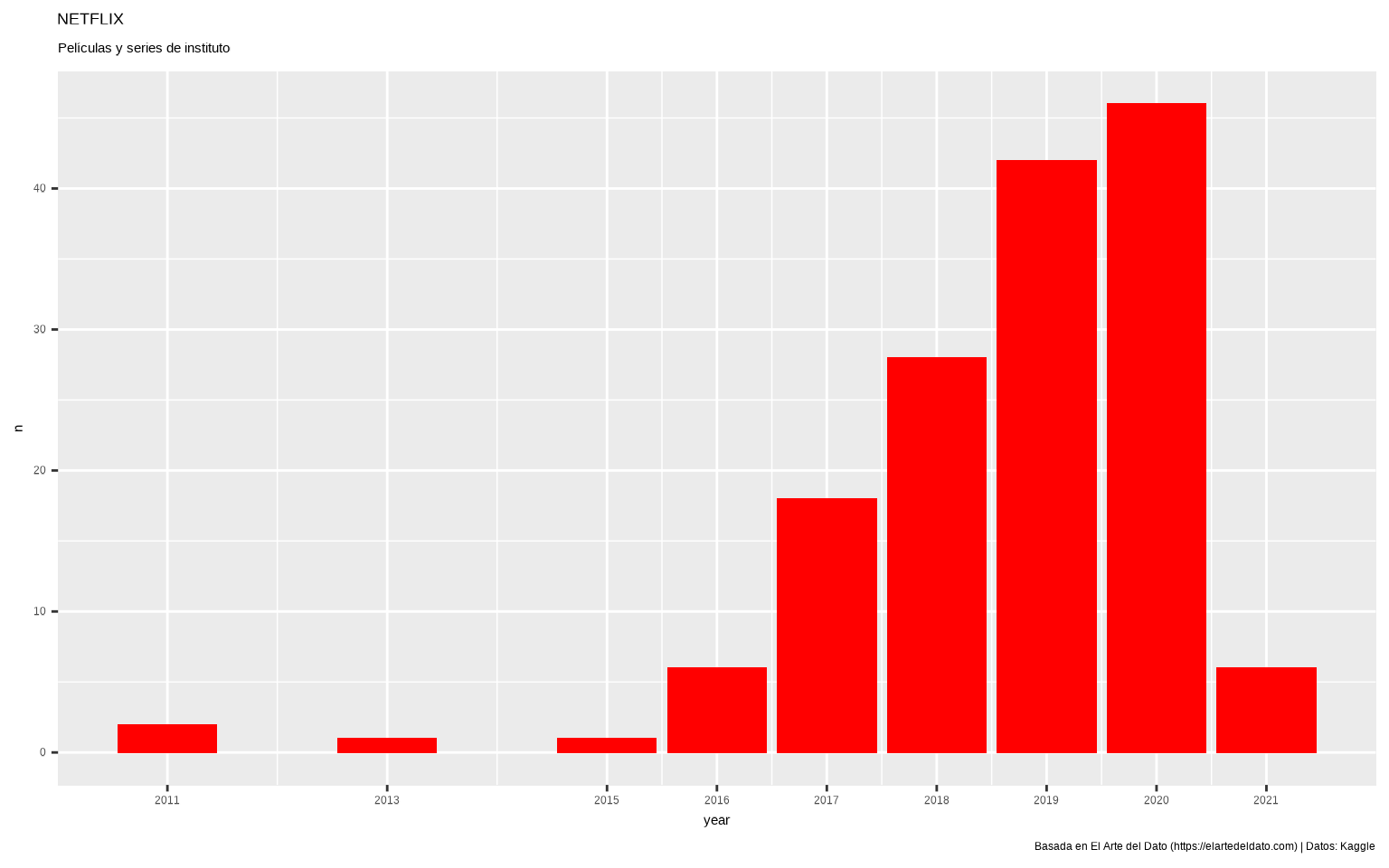
En este caso, al ser datos de Netflix, la propia palabara de es una marca por sí misma, y quizás nos interese usar alguna fuente de Google para cambiar la fuente por defecto. En este caso vamos a usar la fuente de Netflix, la fuente Bebas Neue, y para poder usarla usaremos font_add_google()
library(sysfonts)
library(showtext)
font_add_google(family = "Bebas Neue",
name = "Bebas Neue")
showtext_auto()Tras ello vamos a personalizar totalmente nuestro tema. Lo primero que haremos será «resetear» el tema que podamos tener por defecto con theme_void(). Tras dicho reseteo, le indicaremos con theme()
-
legend.position = "none": sin leyenda. -
plot.title = element_text(family = "Bebas Neue", color = "red", size = 50): le indicaremos la fuente, el color y el tamaño de nuestro título.
gg <- ggplot(netflix_resumen, aes(x = year, y = n)) +
geom_col(fill = "red") +
scale_x_continuous(breaks = netflix_resumen$year) +
theme_void() +
theme(legend.position = "none",
plot.title = element_text(family = "Bebas Neue",
color = "red", size = 80)) +
labs(title = "NETFLIX",
subtitle = "Películas y series de instituto",
caption = "Basada en El Arte del Dato (https://elartedeldato.com) | Datos: Kaggle")
gg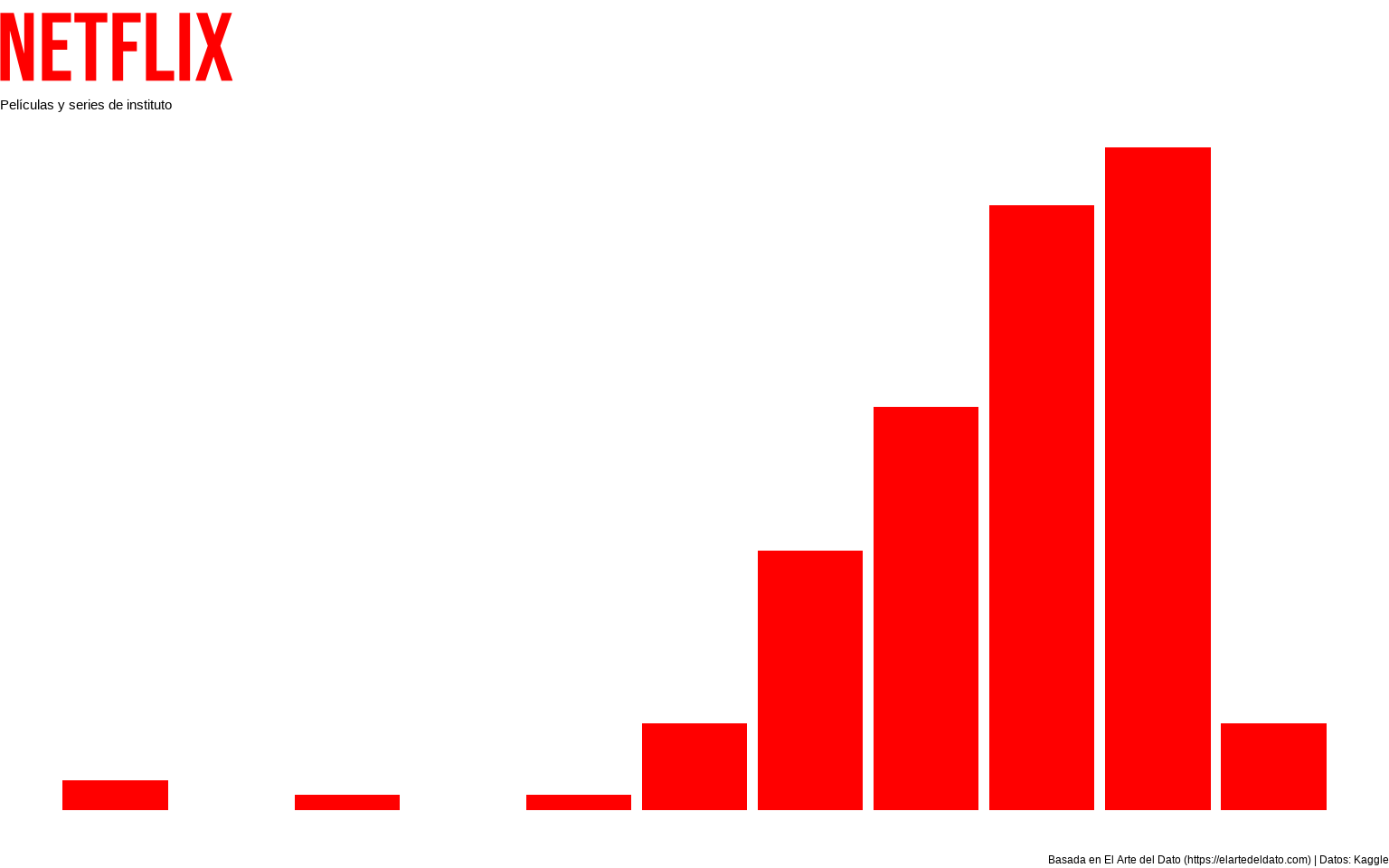
Ahora el título "NETFLIX" está en la fuente de la propia marca, lo que hace nuestro gráfico tenga un contexto más allá de la mera estadística: está intentando comunicar algo y llamar la atención con un esquema visual conocido.
Tras cambiar la fuente del título vamos a indicarle que el fondo del gráfico sea todo negro.
gg <-
gg +
theme(panel.background = element_rect(fill = "black"),
plot.background = element_rect(fill = "black",
color = "black"))
gg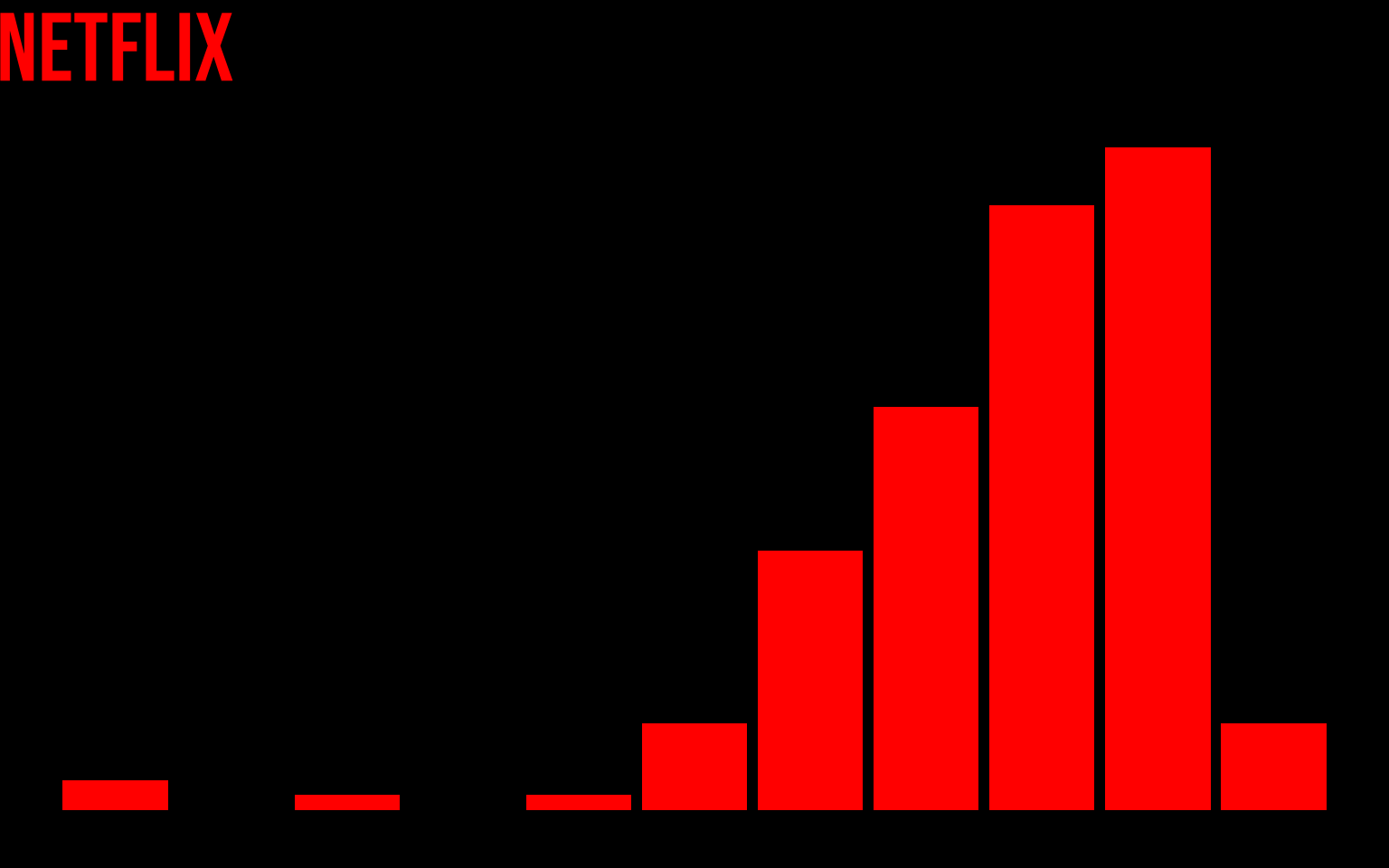
También vamos a personalizar el grid horizontal (el que marca las alturas del eje y), indicándole color y tamaño.
gg <- gg +
theme(panel.grid.major.y =
element_line(size = 0.1, color = "white"))
gg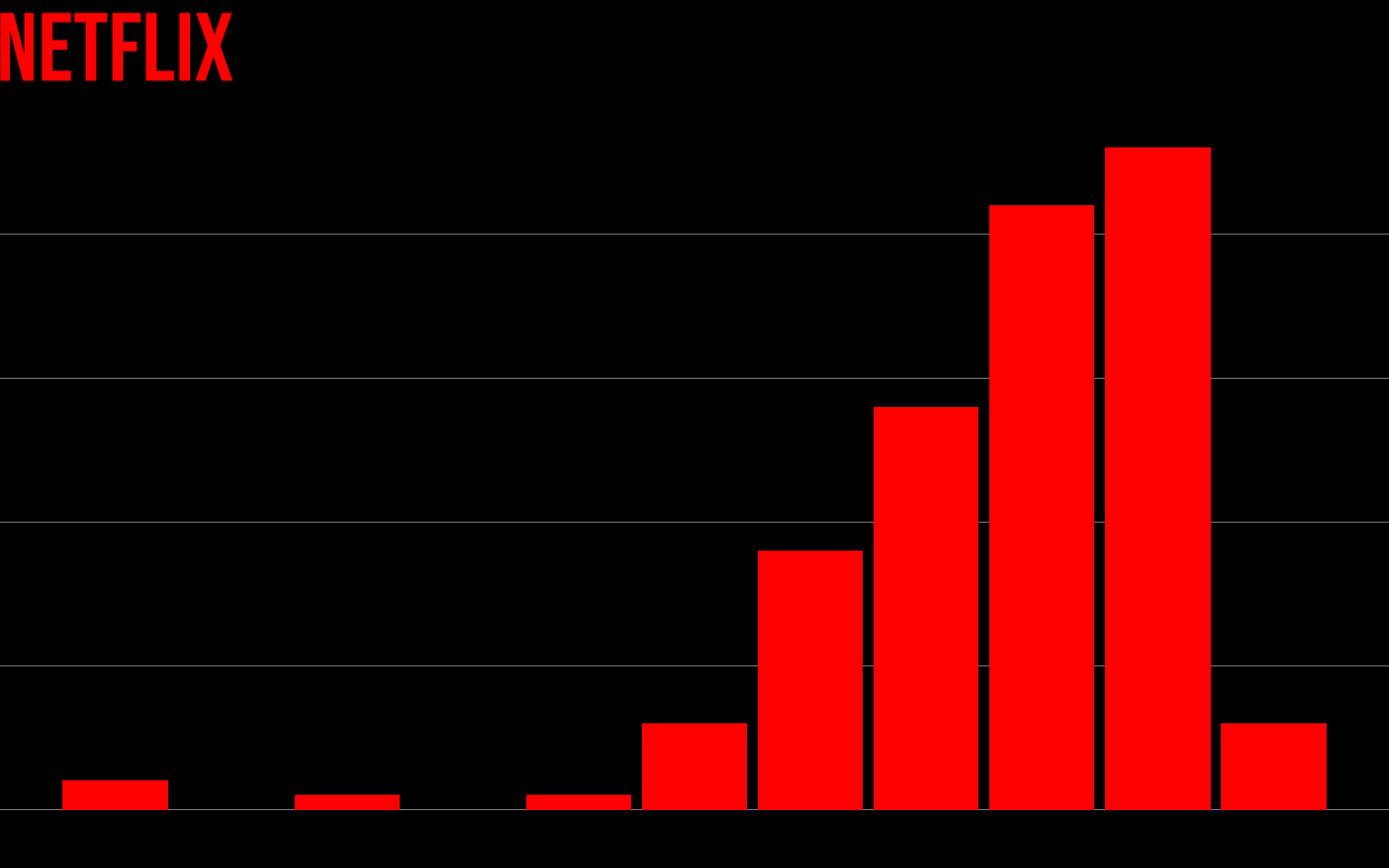
Vamos a personalizar también la fuente del subtítulo y caption y los textos de los ejes.
font_add_google(family = "Permanent Marker",
name = "Permanent Marker")
showtext_auto()
gg <- gg +
theme(plot.subtitle = element_text(family = "Permanent Marker",
size = 21, color = "white"),
plot.caption = element_text(family = "Permanent Marker",
color = "white", size = 19),
axis.text =
element_text(size = 15, family = "Permanent Marker",
color = "white"))
gg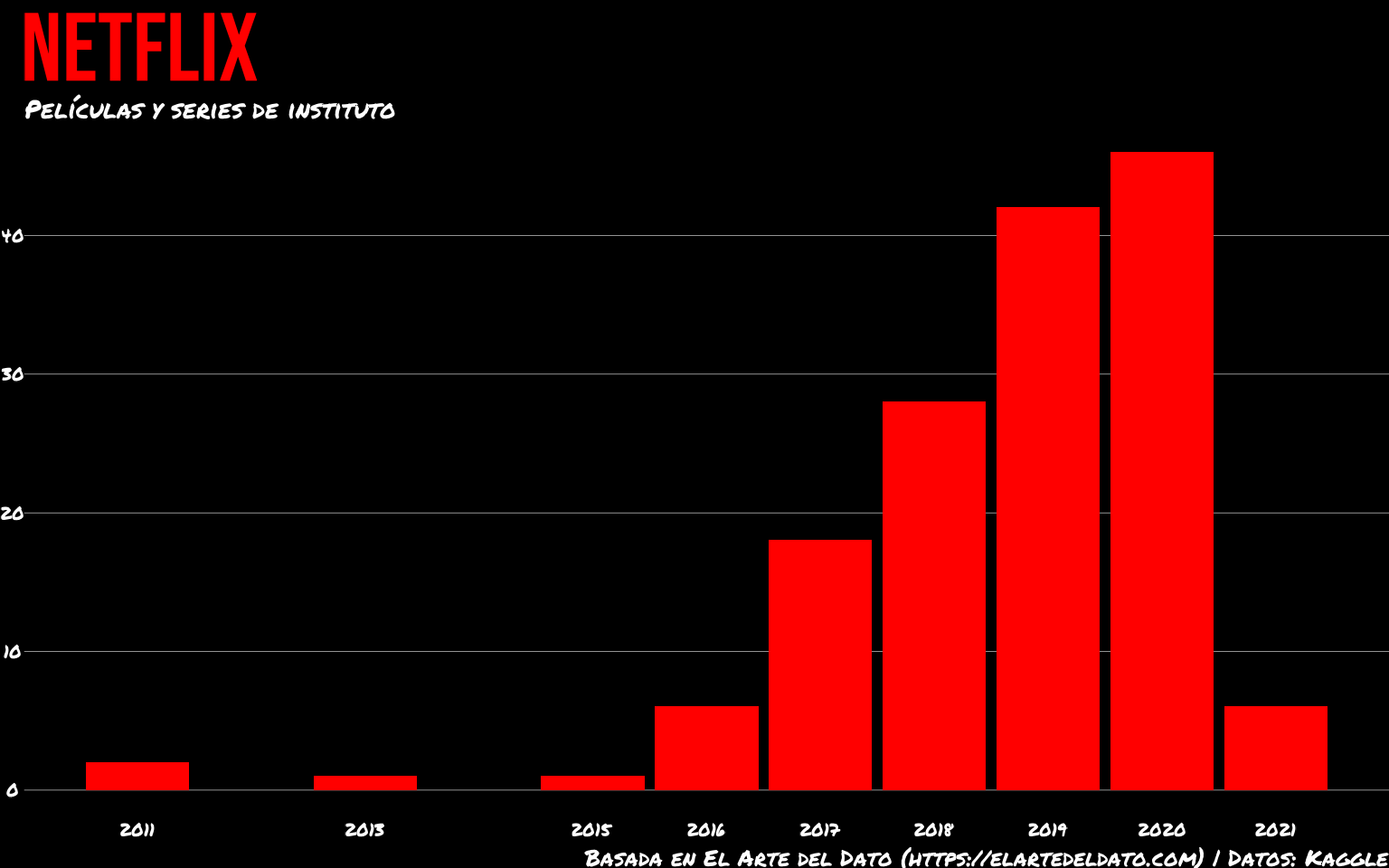
Por último vamos a darle un poco de aire añadiendo márgenes
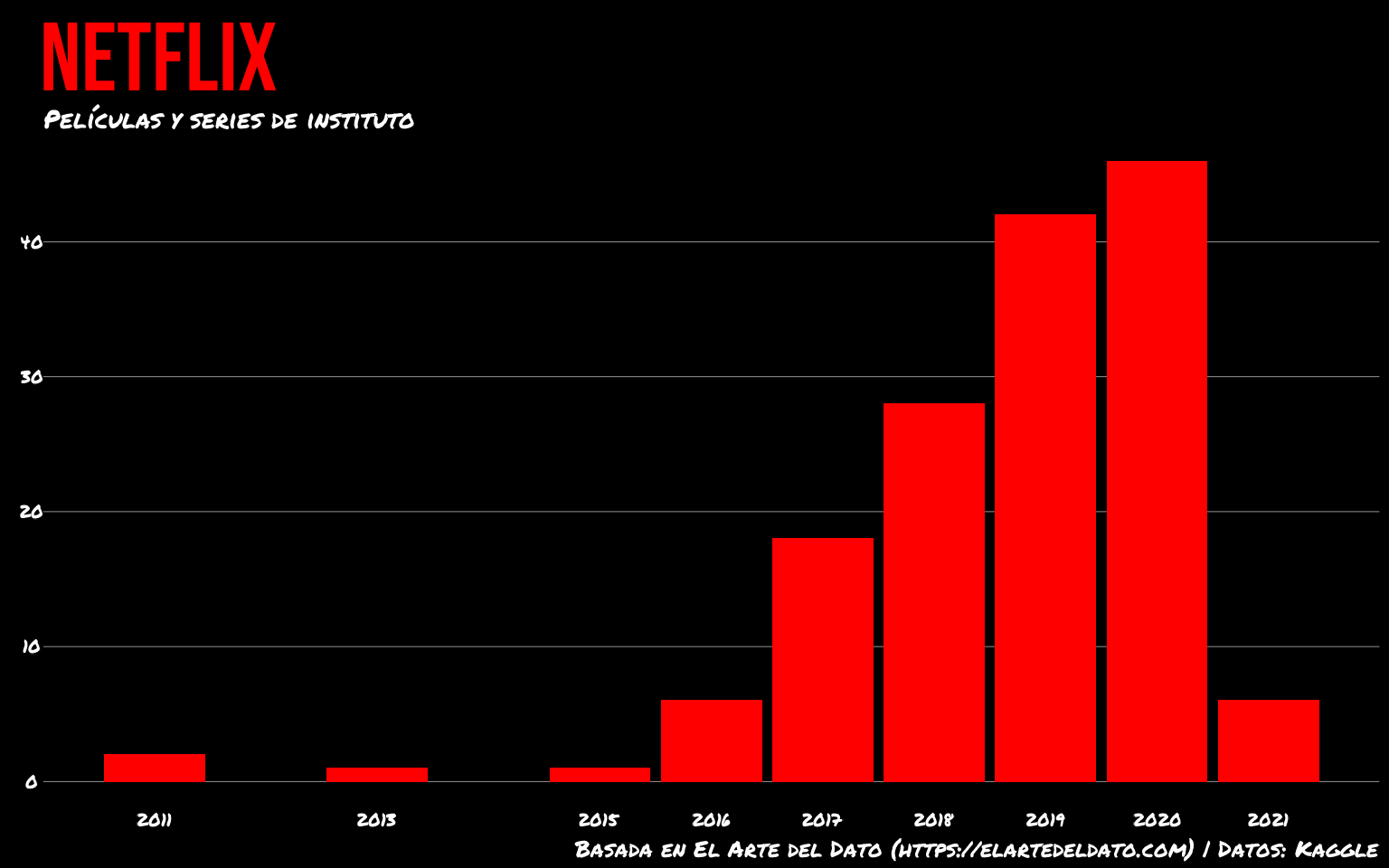
Por último con annotate() podemos añadir anotaciones al gráfico, por ejemplo, escribiendo el mes de enero en la última barra para remarcar que solo llega hasta enero de 2021, con una fina curva como «flecha».
gg <- gg +
annotate("text", label = "(hasta enero)",
x = 2021, y = 11, hjust = 0.3, vjust = 0, family = "Permanent Marker", size = 5, color='white', angle = 20) +
annotate("curve", x = 2021, y = 9, xend = 2021, yend = 5,
color = "white")
gg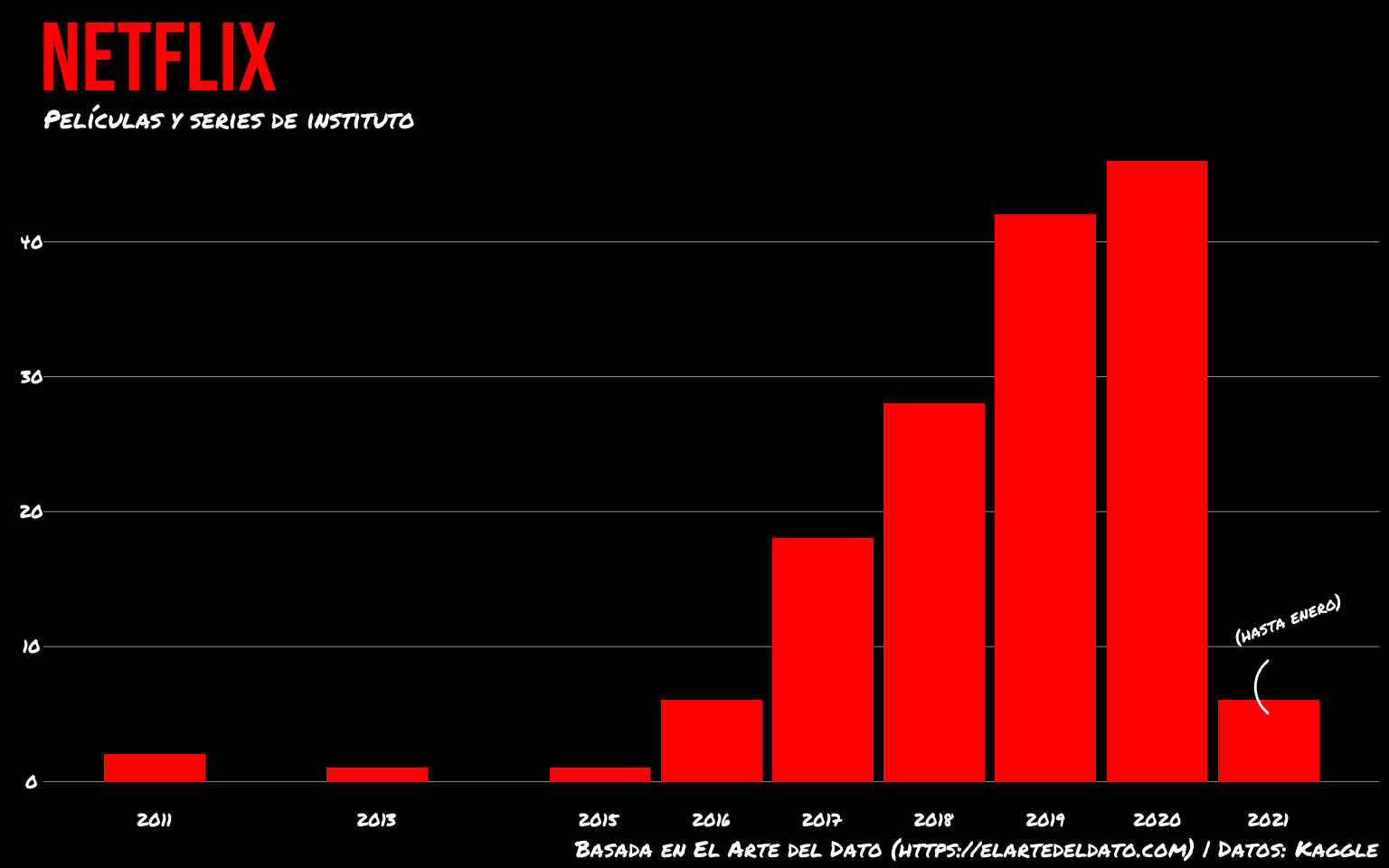
Hemos pasado de un gráfico de barras cualquiera a un gráfico que ya solo por la estética nos lleva automáticamente a Netflix. Puedes ver más gráficas y trucos en la web de Paula Casado El Arte del Dato, de donde ha salido parte de la idea de este capítulo.
22.2 Gráficos en coordenadas polares
«Florence, sé enfermera», 1837. Dios no sabía que se anunciaba a la mujer que cambió la visualización de datos.
Florence Nightingale (nacida en 1820 en Toscana), tras formarse en la Kaiserswerth luterana en el cuidado de marginados, fue enviada el 21 de octubre de 1854 para mejorar las condiciones sanitarias de los soldados británicos en la guerra de Crimea (1854-1856).
Horrorizada, Florence observó las condiciones en las que se atendía a los soldados heridos. De esa observación contabilizó una tasa de mortalidad de 1174 por cada 10 000 soldados: 1023 se debía a enfermedades infecciosas. A su regreso a Londres se dedicó a reunir estadísticas para demostrar que los soldados fallecían por las condiciones sanitarias: eran muertes evitables.
¿Cómo demostrar algo así a tus superiores cuando era vista como una mera niñera de enfermos? «Lograr a través de los ojos lo que no somos capaces de transmitir a las mentes de los ciudadanos a través de sus oídos insensibles». A través de la visualización de datos
Es en ese momento cuando creó el famoso diagrama de la Rosa o de área polar.
El gráfico fue una absoluta revolución ya que permitía representar tres variables a la vez:
- tiempo (cada gajo es un mes)
- nº de muertes (área del gajo)
- causa de la muerte (color del gajo): azules para enfermedades infecciosas, rojas para heridas, negras para otras causas.
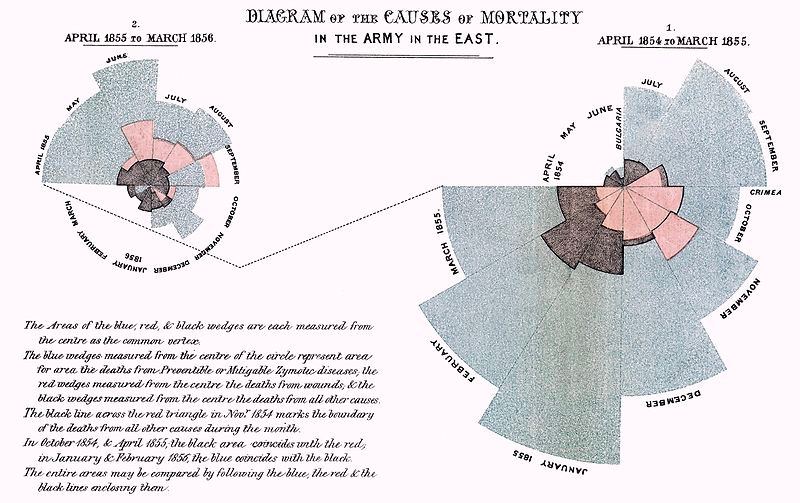
Imagen/gráfica 22.1: Gráfico original de Florence Nightingale
Florence quería demostrar que el enorme nº de bajas debidas a enfermedades infecciosas era evitable y así lo hizo con el gráfico de la izquierda, comparado con el de la derecha: al margen de junio de 1855, el % de muertes por enfermedades (área azul) descendió tras sus medidas para mejorar las condiciones de los hospitales.
El 8 de febrero de 1955, The Times la describió como la «ángel guardián» de los hospitales, y al finalizar la contienda, fue recibida como una heroína, conocida como «The Lady with the Lamp» tras un poema de H. W. Longfellow publicado en 1857. Años después se convirtió en la primera mujer en la Royal Statistical Society y renunció a su puesto para crear las primeras escuelas de enfermería.
Vamos a intentar recrear su brillante visualización. Los datos los podemos obtener de un paquete muy interesante con datos relacionados con eventos de la historia de la estadística y dataviz, el paquete {HistData}, y el conjunto Nightingale
library(HistData)
Nightingale## Date Month Year Army Disease Wounds Other Disease.rate Wounds.rate
## 1 1854-04-01 Apr 1854 8571 1 0 5 1.4 0.0
## 2 1854-05-01 May 1854 23333 12 0 9 6.2 0.0
## 3 1854-06-01 Jun 1854 28333 11 0 6 4.7 0.0
## 4 1854-07-01 Jul 1854 28722 359 0 23 150.0 0.0
## 5 1854-08-01 Aug 1854 30246 828 1 30 328.5 0.4
## 6 1854-09-01 Sep 1854 30290 788 81 70 312.2 32.1
## 7 1854-10-01 Oct 1854 30643 503 132 128 197.0 51.7
## 8 1854-11-01 Nov 1854 29736 844 287 106 340.6 115.8
## 9 1854-12-01 Dec 1854 32779 1725 114 131 631.5 41.7
## 10 1855-01-01 Jan 1855 32393 2761 83 324 1022.8 30.7
## 11 1855-02-01 Feb 1855 30919 2120 42 361 822.8 16.3
## 12 1855-03-01 Mar 1855 30107 1205 32 172 480.3 12.8
## 13 1855-04-01 Apr 1855 32252 477 48 57 177.5 17.9
## 14 1855-05-01 May 1855 35473 508 49 37 171.8 16.6
## 15 1855-06-01 Jun 1855 38863 802 209 31 247.6 64.5
## 16 1855-07-01 Jul 1855 42647 382 134 33 107.5 37.7
## 17 1855-08-01 Aug 1855 44614 483 164 25 129.9 44.1
## 18 1855-09-01 Sep 1855 47751 189 276 20 47.5 69.4
## 19 1855-10-01 Oct 1855 46852 128 53 18 32.8 13.6
## 20 1855-11-01 Nov 1855 37853 178 33 32 56.4 10.5
## 21 1855-12-01 Dec 1855 43217 91 18 28 25.3 5.0
## 22 1856-01-01 Jan 1856 44212 42 2 48 11.4 0.5
## 23 1856-02-01 Feb 1856 43485 24 0 19 6.6 0.0
## 24 1856-03-01 Mar 1856 46140 15 0 35 3.9 0.0
## Other.rate
## 1 7.0
## 2 4.6
## 3 2.5
## 4 9.6
## 5 11.9
## 6 27.7
## 7 50.1
## 8 42.8
## 9 48.0
## 10 120.0
## 11 140.1
## 12 68.6
## 13 21.2
## 14 12.5
## 15 9.6
## 16 9.3
## 17 6.7
## 18 5.0
## 19 4.6
## 20 10.1
## 21 7.8
## 22 13.0
## 23 5.2
## 24 9.1
glimpse(Nightingale)## Rows: 24
## Columns: 10
## $ Date <date> 1854-04-01, 1854-05-01, 1854-06-01, 1854-07-01, 1854-08-…
## $ Month <ord> Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec, Jan, Feb, Ma…
## $ Year <int> 1854, 1854, 1854, 1854, 1854, 1854, 1854, 1854, 1854, 185…
## $ Army <int> 8571, 23333, 28333, 28722, 30246, 30290, 30643, 29736, 32…
## $ Disease <int> 1, 12, 11, 359, 828, 788, 503, 844, 1725, 2761, 2120, 120…
## $ Wounds <int> 0, 0, 0, 0, 1, 81, 132, 287, 114, 83, 42, 32, 48, 49, 209…
## $ Other <int> 5, 9, 6, 23, 30, 70, 128, 106, 131, 324, 361, 172, 57, 37…
## $ Disease.rate <dbl> 1.4, 6.2, 4.7, 150.0, 328.5, 312.2, 197.0, 340.6, 631.5, …
## $ Wounds.rate <dbl> 0.0, 0.0, 0.0, 0.0, 0.4, 32.1, 51.7, 115.8, 41.7, 30.7, 1…
## $ Other.rate <dbl> 7.0, 4.6, 2.5, 9.6, 11.9, 27.7, 50.1, 42.8, 48.0, 120.0, …De los datos solo nos interesan las variables de fecha Date, Month, Year y las tasas relativas (que contienen "rate" en el nombre).
## Date Month Year Disease.rate Wounds.rate Other.rate
## 1 1854-04-01 Apr 1854 1.4 0.0 7.0
## 2 1854-05-01 May 1854 6.2 0.0 4.6
## 3 1854-06-01 Jun 1854 4.7 0.0 2.5
## 4 1854-07-01 Jul 1854 150.0 0.0 9.6
## 5 1854-08-01 Aug 1854 328.5 0.4 11.9
## 6 1854-09-01 Sep 1854 312.2 32.1 27.7
## 7 1854-10-01 Oct 1854 197.0 51.7 50.1
## 8 1854-11-01 Nov 1854 340.6 115.8 42.8
## 9 1854-12-01 Dec 1854 631.5 41.7 48.0
## 10 1855-01-01 Jan 1855 1022.8 30.7 120.0
## 11 1855-02-01 Feb 1855 822.8 16.3 140.1
## 12 1855-03-01 Mar 1855 480.3 12.8 68.6
## 13 1855-04-01 Apr 1855 177.5 17.9 21.2
## 14 1855-05-01 May 1855 171.8 16.6 12.5
## 15 1855-06-01 Jun 1855 247.6 64.5 9.6
## 16 1855-07-01 Jul 1855 107.5 37.7 9.3
## 17 1855-08-01 Aug 1855 129.9 44.1 6.7
## 18 1855-09-01 Sep 1855 47.5 69.4 5.0
## 19 1855-10-01 Oct 1855 32.8 13.6 4.6
## 20 1855-11-01 Nov 1855 56.4 10.5 10.1
## 21 1855-12-01 Dec 1855 25.3 5.0 7.8
## 22 1856-01-01 Jan 1856 11.4 0.5 13.0
## 23 1856-02-01 Feb 1856 6.6 0.0 5.2
## 24 1856-03-01 Mar 1856 3.9 0.0 9.1Tras la selección de variables vamos a convertir los datos a tidy data, pasando todos los valores de tasas e mortalidad a la misma columna tasa, y las causas de la muerte a una columna llamada causa. Además renombramos las variables de fecha.
datos <-
datos %>%
pivot_longer(cols = 4:6, names_to = "causa",
values_to = "tasa") %>%
rename(fecha = Date, mes = Month, year = Year)
datos## # A tibble: 72 × 5
## fecha mes year causa tasa
## <date> <ord> <int> <chr> <dbl>
## 1 1854-04-01 Apr 1854 Disease.rate 1.4
## 2 1854-04-01 Apr 1854 Wounds.rate 0
## 3 1854-04-01 Apr 1854 Other.rate 7
## 4 1854-05-01 May 1854 Disease.rate 6.2
## 5 1854-05-01 May 1854 Wounds.rate 0
## 6 1854-05-01 May 1854 Other.rate 4.6
## 7 1854-06-01 Jun 1854 Disease.rate 4.7
## 8 1854-06-01 Jun 1854 Wounds.rate 0
## 9 1854-06-01 Jun 1854 Other.rate 2.5
## 10 1854-07-01 Jul 1854 Disease.rate 150
## # … with 62 more rowsPor último vamos a eliminar ".rate" de las causas, y traducirlas a castellano, así como crear una nueva variable llamada periodo que nos dirá si fuese antes del 1 de marzo de 1855 o después (para recrear los gráficos por separado, antes y después de las intervenciones llevadas a cabo por Nightingale).
datos <-
datos %>%
mutate(causa = gsub(".rate", "", causa),
causa =
case_when(causa == "Disease" ~ "infecciosas",
causa == "Wounds" ~ "heridas",
causa == "Other" ~ "otras",
TRUE ~ "otras"),
periodo =
factor(ifelse(fecha >= as.Date("1855-04-01"),
"APRIL 1855 TO MARCH 1856",
"APRIL 1854 TO MARCH 1855"),
levels = c("APRIL 1855 TO MARCH 1856",
"APRIL 1854 TO MARCH 1855")))
datos## # A tibble: 72 × 6
## fecha mes year causa tasa periodo
## <date> <ord> <int> <chr> <dbl> <fct>
## 1 1854-04-01 Apr 1854 infecciosas 1.4 APRIL 1854 TO MARCH 1855
## 2 1854-04-01 Apr 1854 heridas 0 APRIL 1854 TO MARCH 1855
## 3 1854-04-01 Apr 1854 otras 7 APRIL 1854 TO MARCH 1855
## 4 1854-05-01 May 1854 infecciosas 6.2 APRIL 1854 TO MARCH 1855
## 5 1854-05-01 May 1854 heridas 0 APRIL 1854 TO MARCH 1855
## 6 1854-05-01 May 1854 otras 4.6 APRIL 1854 TO MARCH 1855
## 7 1854-06-01 Jun 1854 infecciosas 4.7 APRIL 1854 TO MARCH 1855
## 8 1854-06-01 Jun 1854 heridas 0 APRIL 1854 TO MARCH 1855
## 9 1854-06-01 Jun 1854 otras 2.5 APRIL 1854 TO MARCH 1855
## 10 1854-07-01 Jul 1854 infecciosas 150 APRIL 1854 TO MARCH 1855
## # … with 62 more rowsLa manera más inmediata de representar las tasas por causa es hacer uso de un sencillo diagrama de barras apiladas, cada periodo por separado, con un título, subtítulo y caption.
ggplot(datos %>%
filter(periodo == "APRIL 1854 TO MARCH 1855"),
aes(mes, tasa, fill = causa)) +
geom_col() +
labs(fill = "Causas",
title = "DIAGRAM OF THE CAUSES OF MORTALITY",
subtitle = "IN THE ARMY IN THE EAST (April 1854 - March 1855)",
caption = "Author: J. Álvarez Liébana | Data: HistData")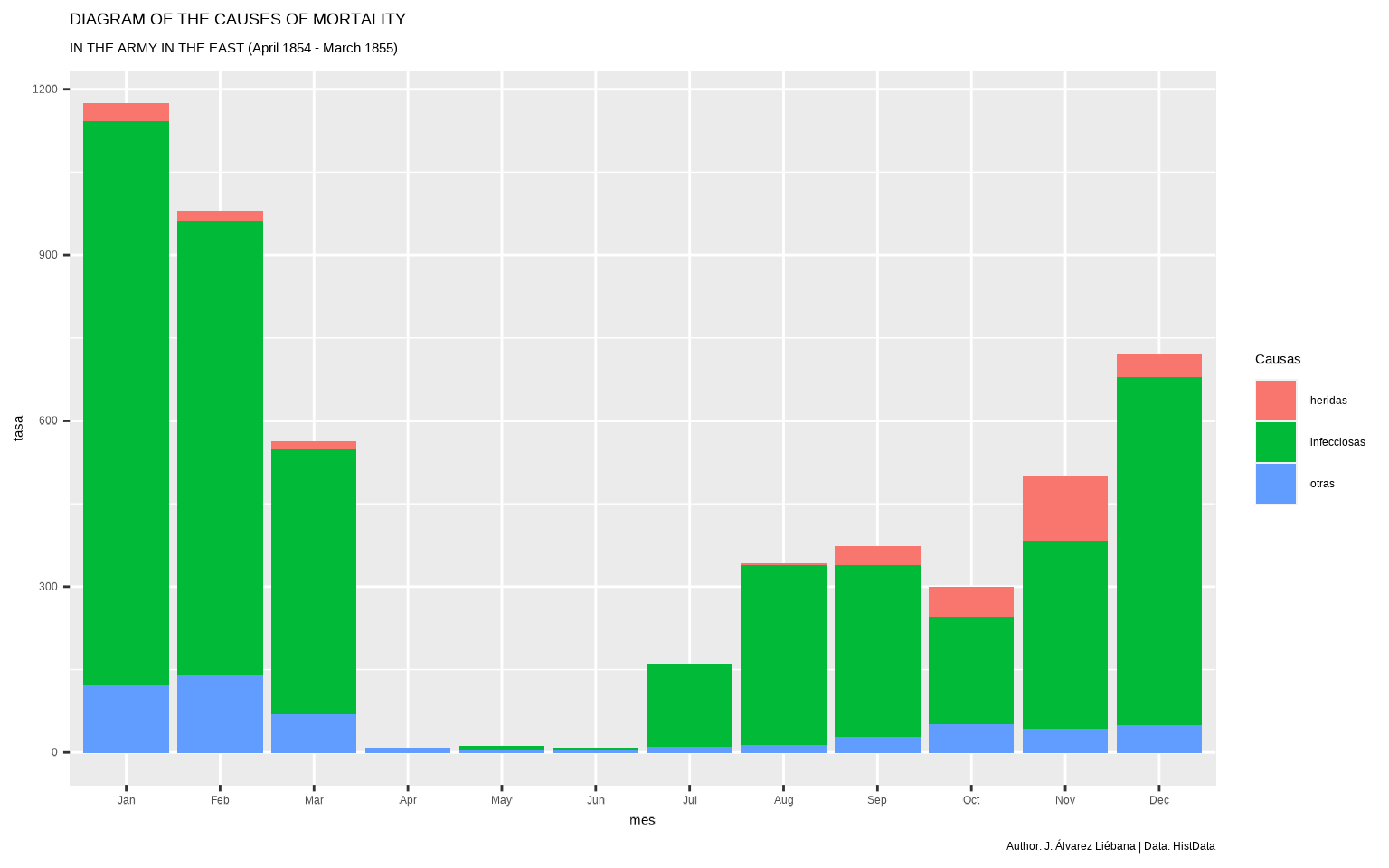
ggplot(datos %>%
filter(periodo == "APRIL 1855 TO MARCH 1856"),
aes(mes, tasa, fill = causa)) +
geom_col() +
labs(fill = "Causas",
title = "DIAGRAM OF THE CAUSES OF MORTALITY",
subtitle = "IN THE ARMY IN THE EAST (April 1855 - March 1856)",
caption = "Author: J. Álvarez Liébana | Data: HistData")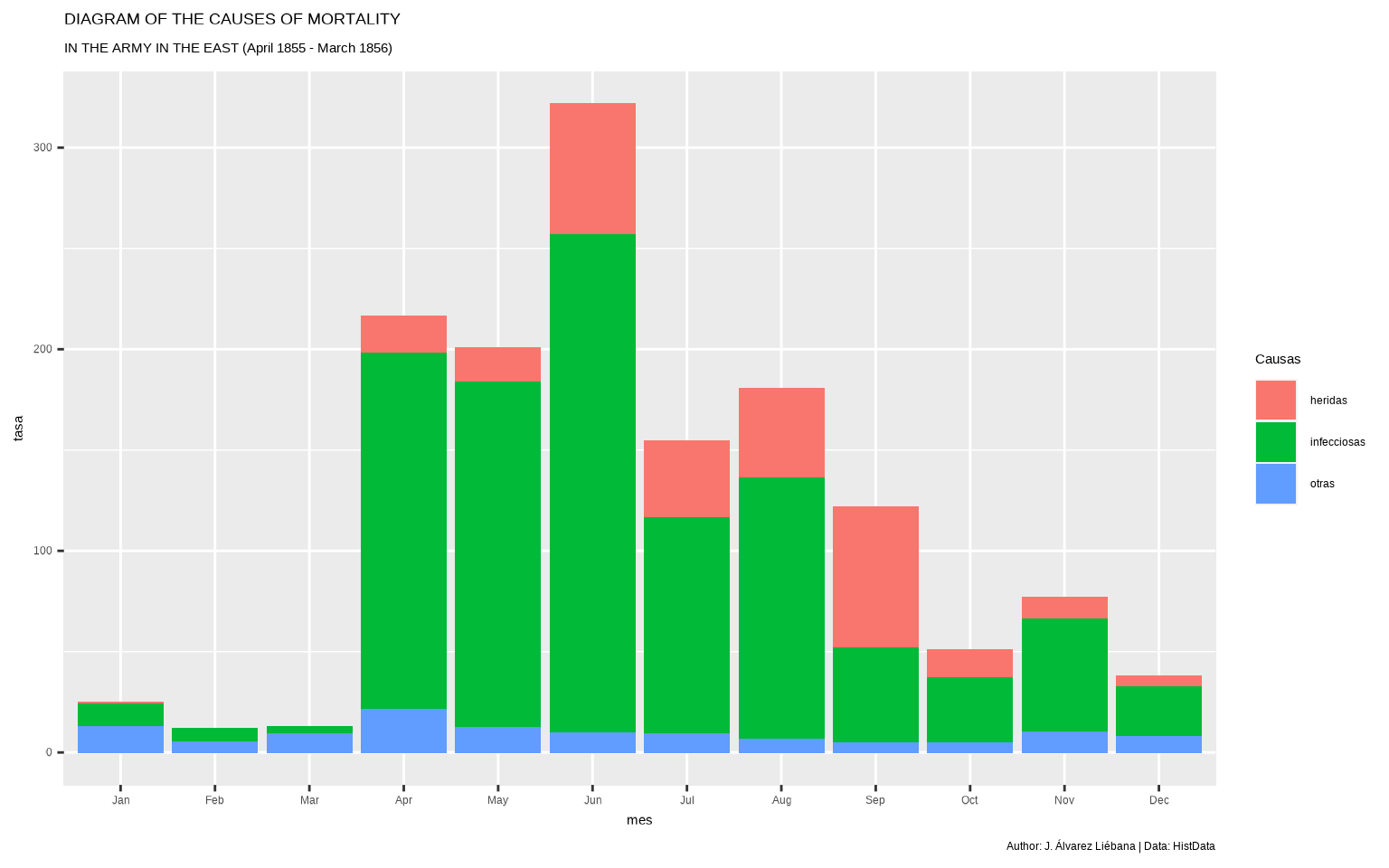
Ambos periodos podemos juntarlos en una misma gráfica con facet_wrap()
ggplot(datos, aes(mes, tasa, fill = causa)) +
geom_col() +
facet_wrap( ~ periodo) +
labs(fill = "Causas",
title = "DIAGRAM OF THE CAUSES OF MORTALITY",
subtitle = "IN THE ARMY IN THE EAST",
caption = "Author: J. Álvarez Liébana | Data: HistData")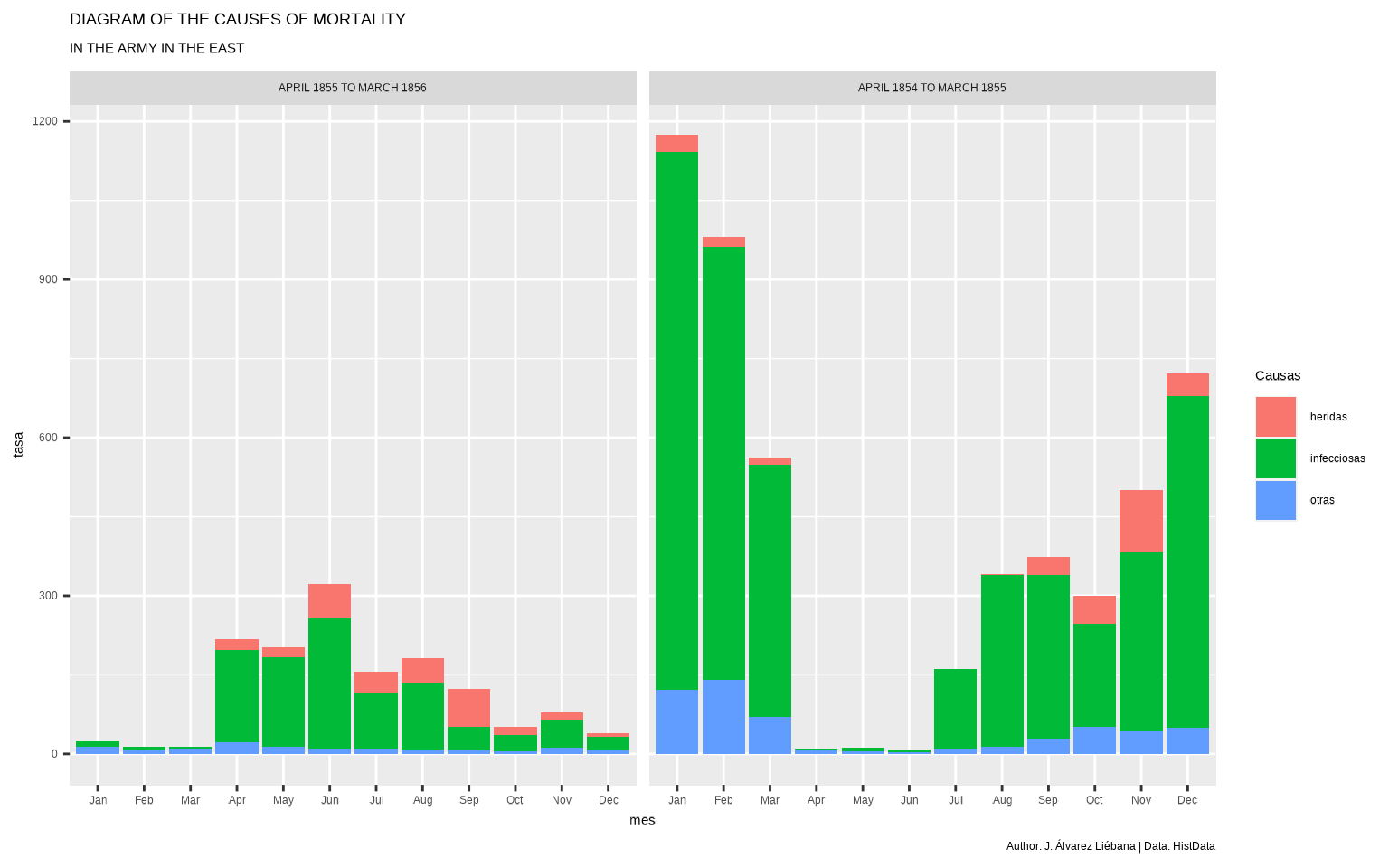
Vamos a ir acercándonos al gráfico de Florence Nighitingale, proporcionando colores similares a los originales para las causas de fallecimiento
ggplot(datos, aes(mes, tasa, fill = causa)) +
geom_col() +
facet_wrap( ~ periodo) +
scale_fill_manual(values =
c("#C42536", "#5aa7d1", "#6B6B6B")) +
labs(fill = "Causas",
title = "DIAGRAM OF THE CAUSES OF MORTALITY",
subtitle = "IN THE ARMY IN THE EAST",
caption = "Author: J. Álvarez Liébana | Data: HistData")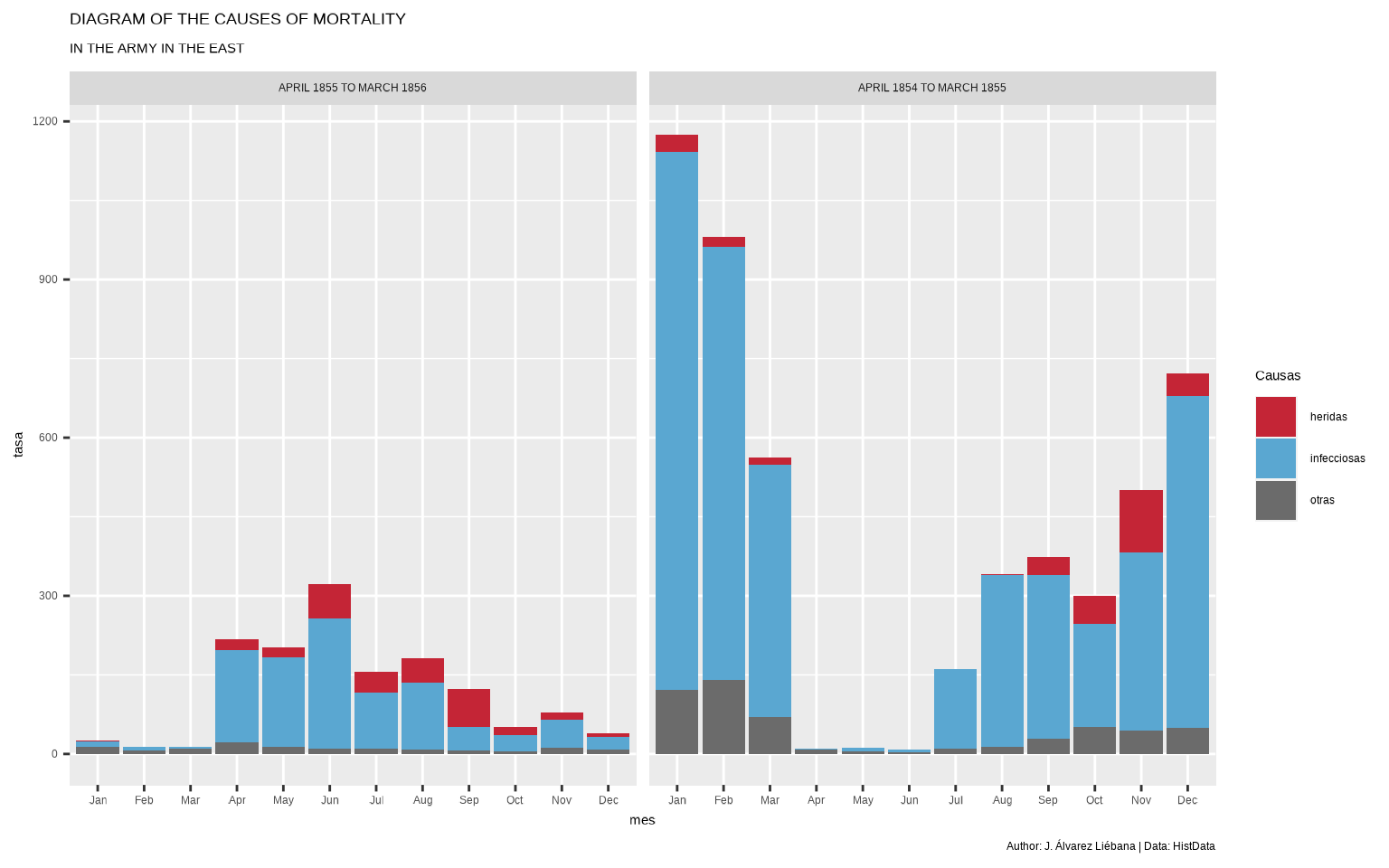
Nuestros datos abarcan dos periodos: de abril 1854 a marzo 1855, y de abril 1855 a marzo 1856. Para tener los datos ordenados cronológicamente, vamos a indicarle que el año irá desde abril a marzo, en ese orden los meses, con fct_relevel, del paquete forcats incluido en tidyverse.
datos <-
datos %>%
mutate(mes =
fct_relevel(mes, "Apr", "May", "Jun", "Jul",
"Aug", "Sep", "Oct", "Nov", "Dec",
"Jan", "Feb", "Mar"))
gg <-
ggplot(datos, aes(mes, tasa, fill = causa)) +
geom_col() +
facet_wrap( ~ periodo) +
scale_fill_manual(values =
c("#C42536", "#5aa7d1", "#6B6B6B")) +
labs(fill = "Causas",
title = "DIAGRAM OF THE CAUSES OF MORTALITY",
subtitle = "IN THE ARMY IN THE EAST",
caption = "Author: J. Álvarez Liébana | Data: HistData")
gg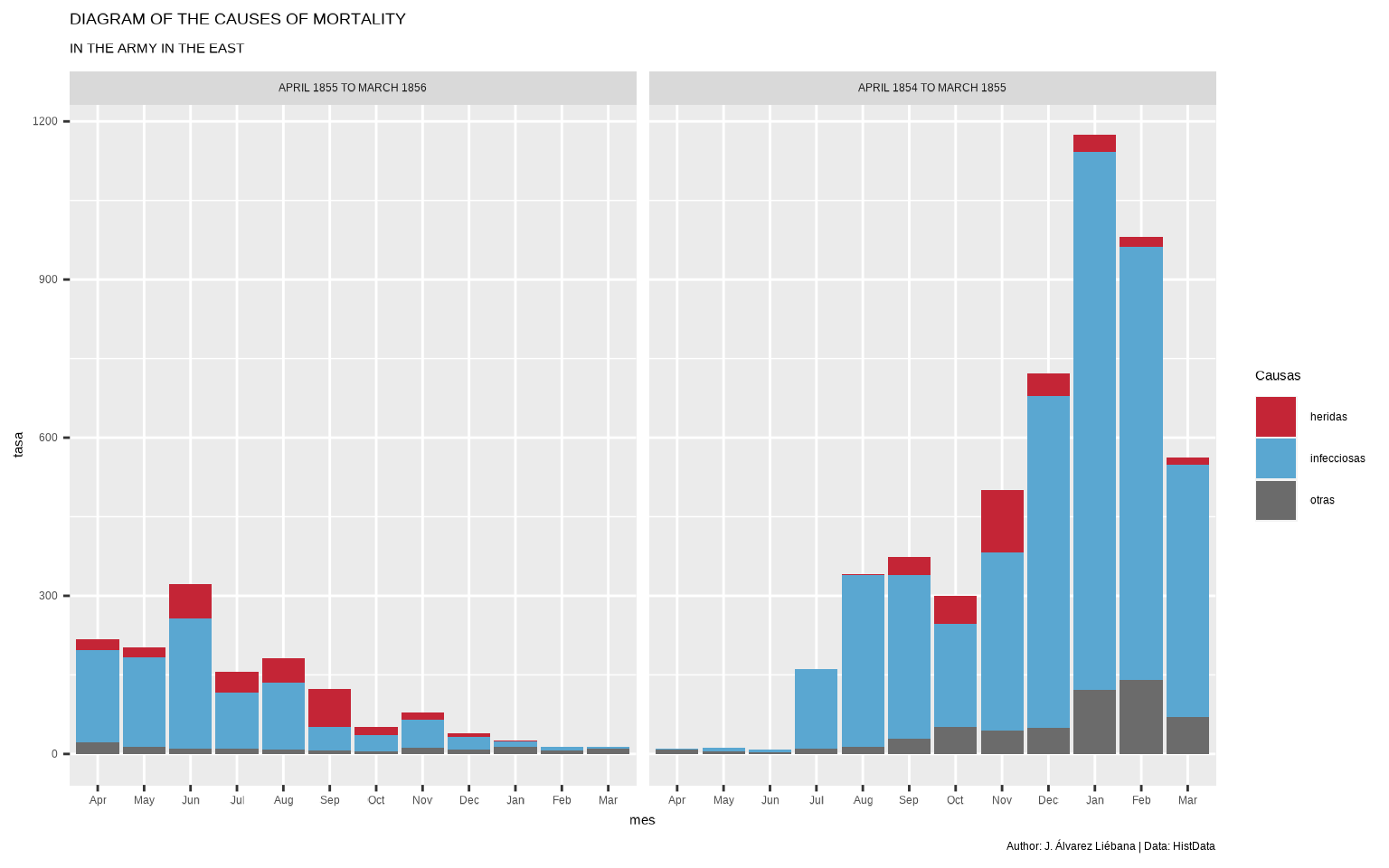
Como habrás advertido, el gráfico original está en coordenadas polares, coordenadas en torno a un círculo. Para convertir nuestro gráfico a coordenadas polares basta con usar coord_polar(). Además los meses originales están desde julio hasta junio ordenados cronológicamente.
datos <-
datos %>%
mutate(mes =
fct_relevel(mes, "Jul", "Aug", "Sep", "Oct",
"Nov", "Dec", "Jan", "Feb",
"Mar", "Apr", "May", "Jun"))
ggplot(datos, aes(mes, tasa, fill = causa)) +
geom_col(width = 1) +
coord_polar() +
scale_fill_manual(values =
c("#C42536", "#5aa7d1", "#6B6B6B")) +
facet_wrap( ~ periodo) +
labs(fill = "Causas",
title = "DIAGRAM OF THE CAUSES OF MORTALITY",
subtitle = "IN THE ARMY IN THE EAST",
caption = "Author: J. Álvarez Liébana | Data: HistData")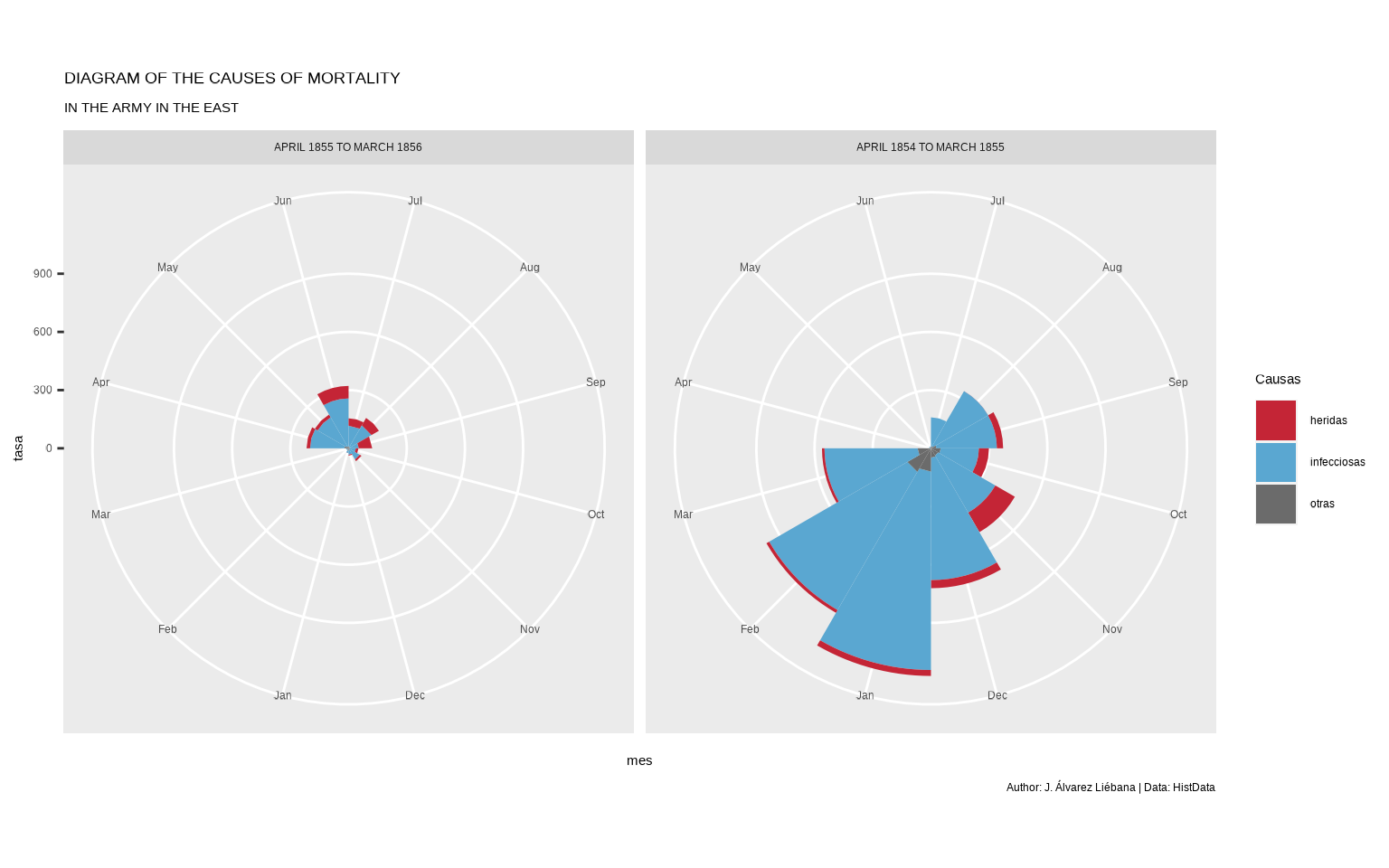
Dado que en el gráfico original no hay marcas en el eje Y, vamos eliminar el eje Y, vamos a darle etiquetas correctas a los meses (como en el original), y vamos a cambiar la escala del eje Y con scale_y_sqrt() (para que las diferencias no sean tan exageradas entre un círculo y otro por la escala).
gg <-
ggplot(datos, aes(mes, tasa, fill = causa)) +
geom_col(width = 1) +
coord_polar() +
scale_fill_manual(values =
c("#C42536", "#5aa7d1", "#6B6B6B")) +
scale_y_sqrt() +
scale_x_discrete(labels =
c("JULY", "AUGUST", "SEPT.",
"OCTOBER", "NOVEMBER", "DECEMBER",
"JANUARY", "FEBRUARY", "MARCH",
"APRIL", "MAY", "JUNE")) +
facet_wrap( ~ periodo) +
labs(fill = "Causas",
title = "DIAGRAM OF THE CAUSES OF MORTALITY",
subtitle = "IN THE ARMY IN THE EAST",
caption = "Author: J. Álvarez Liébana | Data: HistData")
gg + theme(axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank())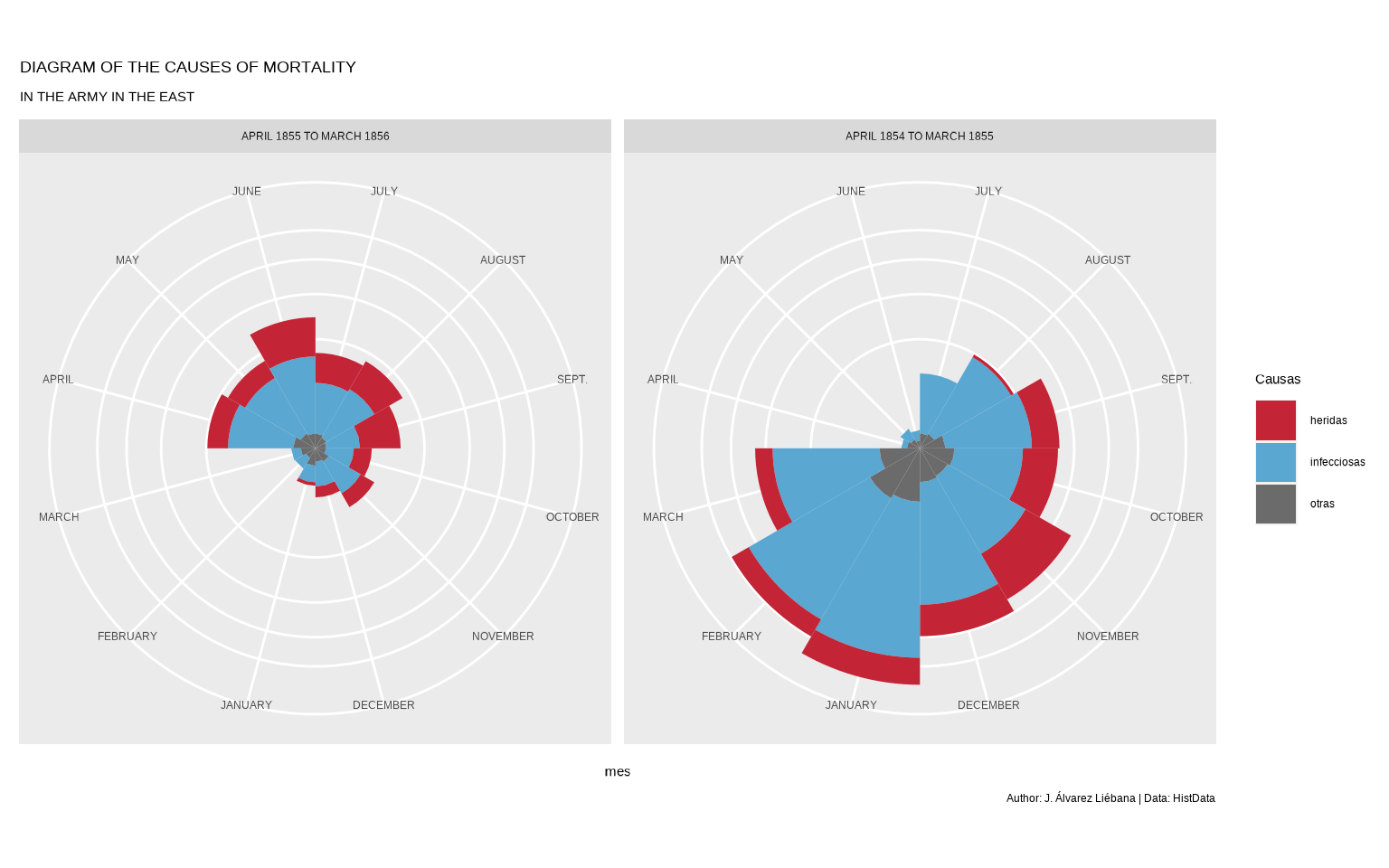
Por último podemos personalizar el fondo, los ejes, los títulos, el ángulo de las etiquetas de los meses, etc.
library(sysfonts)
library(showtext)
font_add_google(family = "Roboto",
name = "Roboto")
font_add_google(family = "Cinzel Decorative",
name = "Cinzel Decorative")
font_add_google(family = "Quattrocento",
name = "Quattrocento")
showtext_auto()
angulo <- seq(-20, -340, length.out = 12)
gg + theme_void() +
theme(
# Eje y limpio
axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
# Eje x (el radial)
axis.text.x =
element_text(face = "bold", size = 9, angle = angulo,
family = "Roboto"),
panel.grid.major.x = element_line(size = 0.01, color = "black"),
legend.position = "bottom",
plot.background = element_rect(fill = alpha("cornsilk", 0.5)),
plot.title =
element_text(hjust = 0.5, size = 21,
family = "Cinzel Decorative"),
plot.subtitle =
element_text(hjust = 0.5, size = 15,
family = "Cinzel Decorative"),
plot.caption =
element_text(size = 9, family = "Quattrocento"),
strip.text =
element_text(hjust = 0.5, size = 7,
family = "Quattrocento"),
plot.margin = margin(t = 5, r = 7, b = 5, l = 7, "pt"))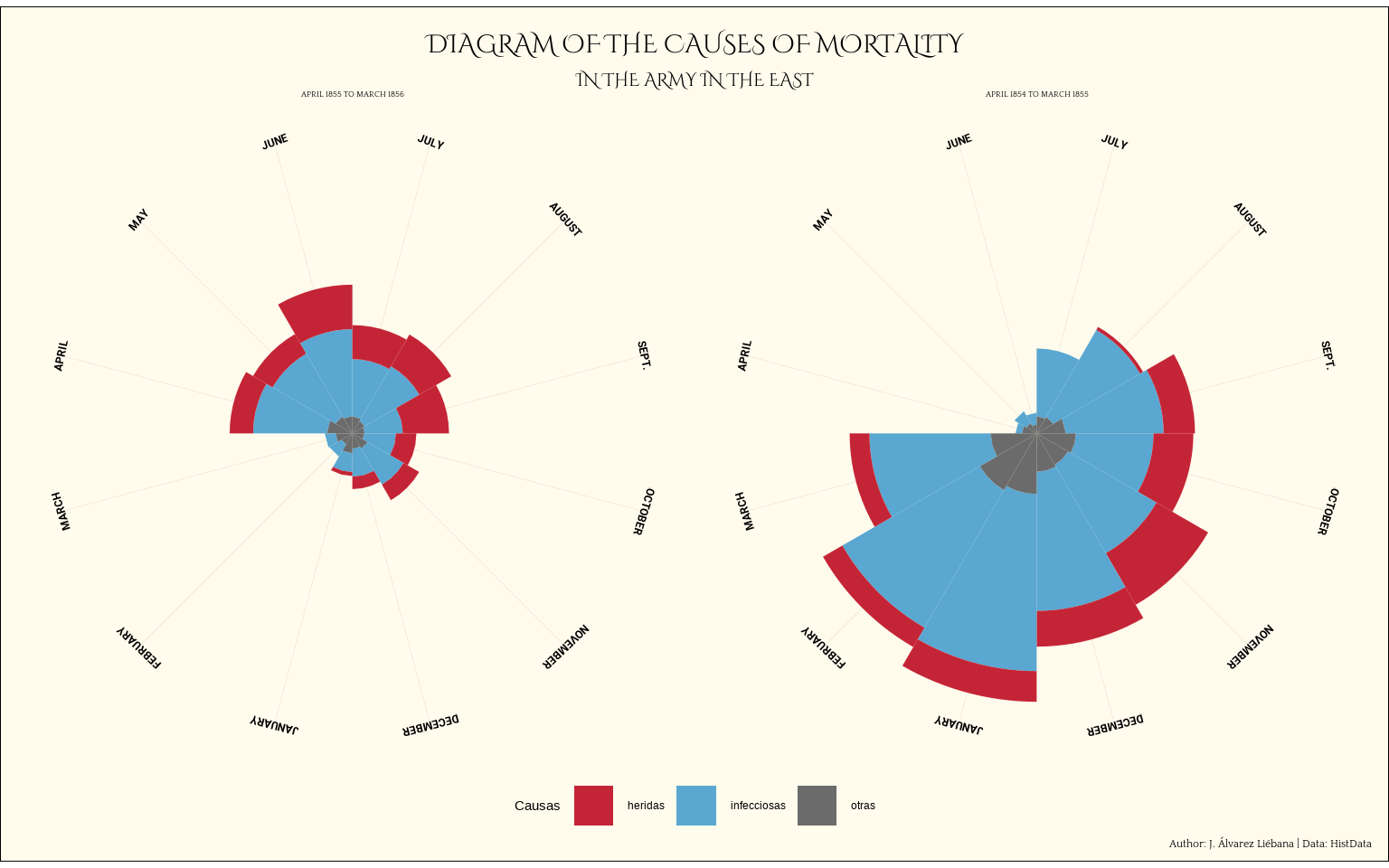
22.3 Recursos para seguir profundizando
En la web de Paula Casado El Arte del Dato puedes encontrar tutoriales cortos y sencillos con multitud de trucos para personalizar tus gráficas. En la web https://www.r-graph-gallery.com/ tienes una colección muy completa de gráficos generados en ggplot2 para aprender y tomar ideas.
22.4 📝 Ejercicios
(haz click en las flechas para ver soluciones)
El ejercicio está basado en el gráfico de Tobias Stadler, cuyo código original puedes encontrarlo en Github, al tutorial de Tomás Capretto y al material en R Graph Gallery.
Se ruega citar la autoría del gráfico añadiendo el siguiente caption
caption_chart <- "Dataviz by Tobias Stalder\ntobias-stalder.netlify.app\nSource: TidyX Crew (Ellis Hughes, Patrick Ward)\n Data: github.com/rfordatascience/tidytuesday/blob/master/data/2020/2020-11-24/readme.md"Los datos provienen originalmente de la «Washington Trails Association», con datos de sendas de senderismo en Washington. Tienes el archivo hiking.csv en la carpeta DATOS. Los datos han sido descargados desde https://github.com/rfordatascience/tidytuesday/blob/master/data/2020/2020-11-24
📝Ejercicio 1: carga los datos
hiking.csv y muestra las variables.
- Solución:
## # A tibble: 1,958 × 8
## name location length gain highpoint rating features description
## <chr> <chr> <chr> <dbl> <dbl> <dbl> <lgl> <chr>
## 1 Lake H… Puget Sound… 2.3 mi… 50 330 3.67 NA "Hike through a…
## 2 Snow L… Snoqualmie … 7.2 mi… 1800 4400 4.16 NA "A relatively s…
## 3 Skooku… Mount Raini… 7.8 mi… 300 2550 3.68 NA "Choose between…
## 4 Teneri… Snoqualmie … 5.6 mi… 1585 2370 3.92 NA "You'll work up…
## 5 Twin F… Snoqualmie … 2.6 mi… 500 1000 4.14 NA "Visit a trio (…
## 6 Chenui… Mount Raini… 8.0 mi… 500 2200 3.14 NA "A long walk (o…
## 7 Old Mi… Mount Raini… 3.4 mi… 425 2150 5 NA "An infrequentl…
## 8 Flamin… Puget Sound… 4.0 mi… 450 425 2.68 NA "The striking n…
## 9 Salmon… North Casca… 5.4 mi… 300 2400 4 NA "With gentle te…
## 10 May Va… Issaquah Al… 6.6 mi… 1684 2024 2.96 NA "This forested …
## # … with 1,948 more rows
glimpse(hike_data)## Rows: 1,958
## Columns: 8
## $ name <chr> "Lake Hills Greenbelt", "Snow Lake", "Skookum Flats", "Ten…
## $ location <chr> "Puget Sound and Islands -- Seattle-Tacoma Area", "Snoqual…
## $ length <chr> "2.3 miles, roundtrip", "7.2 miles, roundtrip", "7.8 miles…
## $ gain <dbl> 50, 1800, 300, 1585, 500, 500, 425, 450, 300, 1684, 80, 65…
## $ highpoint <dbl> 330, 4400, 2550, 2370, 1000, 2200, 2150, 425, 2400, 2024, …
## $ rating <dbl> 3.67, 4.16, 3.68, 3.92, 4.14, 3.14, 5.00, 2.68, 4.00, 2.96…
## $ features <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ description <chr> "Hike through a pastoral area first settled and farmed in …
📝Ejercicio 2: transforma la variable
location para obtener la region (es la primera palabra, antes del " -- ". Para ello puedes usar la función word(), que nos permite seleccionar la palabra enésima de una frase, indicándole en sep = ... el separado entre palabra y palabra. Conviértela a factor la nueva variable region.
- Solución:
📝Ejercicio 3: transforma la variable
length para obtener la longitud en millas de la ruta. Está en formato "12.7 miles, roundtrip", así que puedes volver a usar la función word(), y pasar luego la cadena de texto a número.
- Solución:
hike_data <-
hike_data %>%
mutate(miles = as.numeric(word(length, 1)))
📝Ejercicio 4: calcula la longitud total (acumulada) y la media de desnivel (
gain), con las rutas agrupadas por la variable region, así como el número de rutas por región.
- Solución:
resumen <-
hike_data %>%
group_by(region) %>%
summarise(sum_miles = sum(miles),
mean_gain = round(mean(as.numeric(gain))),
n = n())
resumen## # A tibble: 11 × 4
## region sum_miles mean_gain n
## <fct> <dbl> <dbl> <int>
## 1 Puget Sound and Islands 810. 452 191
## 2 Snoqualmie Region 1915. 2206 219
## 3 Mount Rainier Area 1602. 1874 196
## 4 North Cascades 3347. 2500 301
## 5 Issaquah Alps 383. 973 77
## 6 Central Washington 453. 814 80
## 7 South Cascades 1630. 1649 193
## 8 Central Cascades 2131. 2260 226
## 9 Southwest Washington 825. 1185 123
## 10 Olympic Peninsula 1700. 1572 209
## 11 Eastern Washington 1334. 1591 143
📝Ejercicio 5: dibuja un diagrama de barras con la región en el eje X, la suma de millas en el eje Y y el relleno en función del número de rutas.
- Solución:
ggplot(resumen,
aes(x = region, y = sum_miles, fill = n)) +
geom_col() +
labs(caption = caption_chart)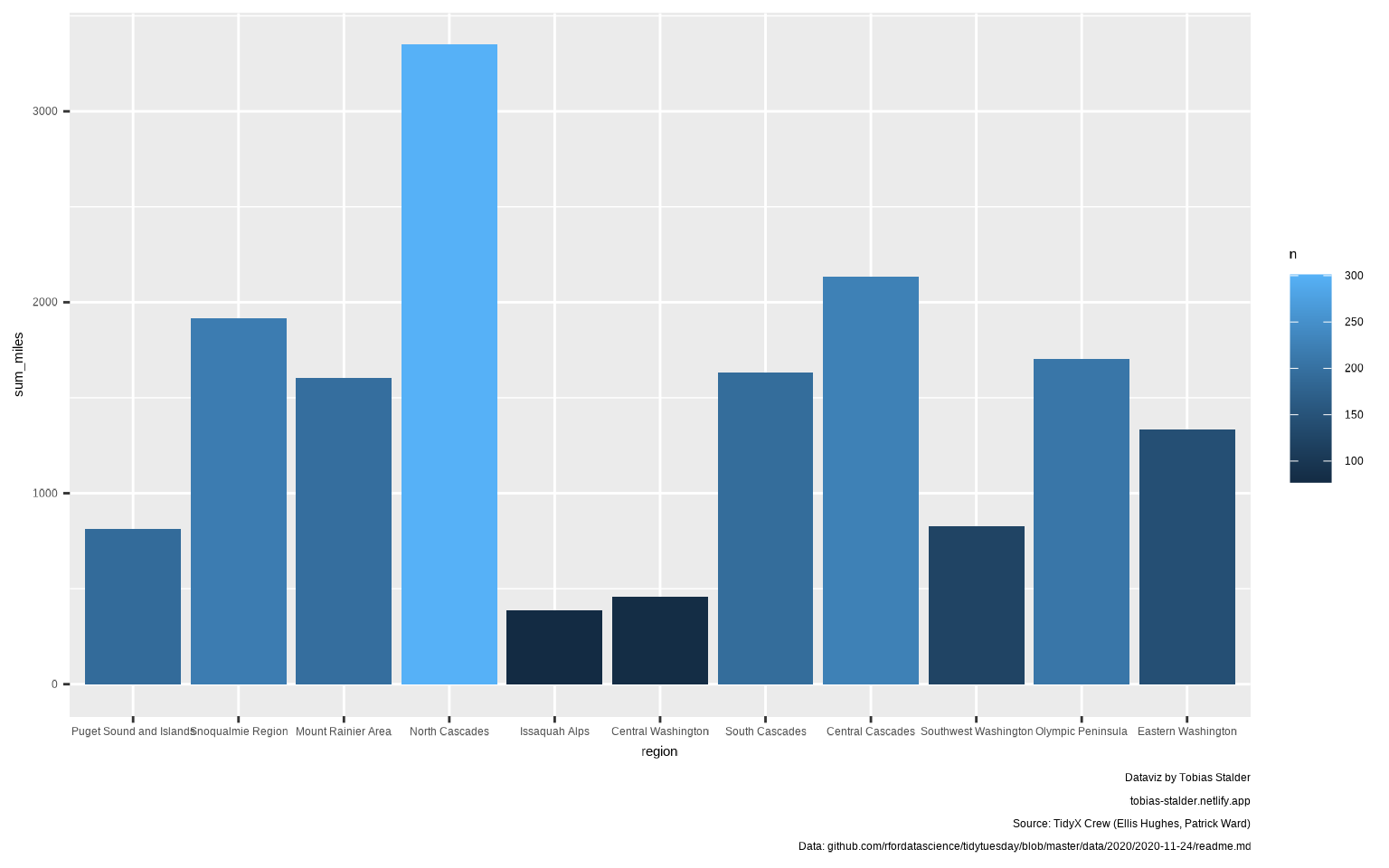
📝Ejercicio 6: repite el ejercicio anterior pero personaliza el tema dando un título a los ejes y una fuente de tamaño adecuada para el eje X. Usa la función
str_wrap() para convertir los nombres de regiones en párrafos con salto de línea, indicándole en width la anchura máxima (no romperá palabras a mitad).
- Solución:
ggplot(resumen,
aes(x = str_wrap(region, width = 7),
y = sum_miles, fill = n)) +
geom_col() +
labs(caption = caption_chart,
fill = "Nº de rutas",
y = "Suma acumulada de millas",
x = "Región") +
theme(axis.title.x = element_text(face = "bold", size = 13),
axis.title.y = element_text(face = "bold", size = 13),
axis.text.x = element_text(face = "bold", size = 9),
axis.text.y = element_text(face = "bold", size = 9))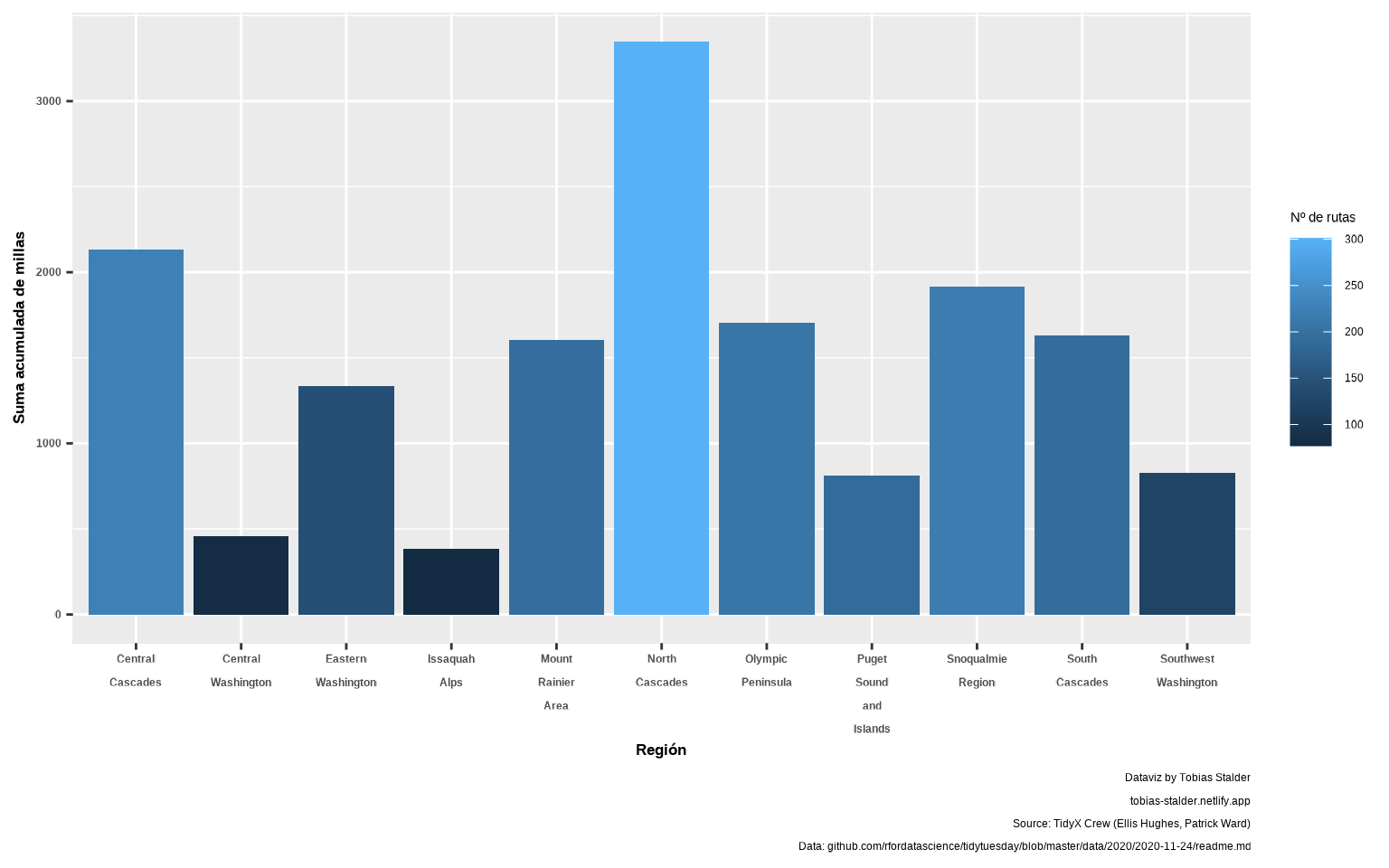
📝Ejercicio 7: repite el ejercicio anterior pero usando
scale_fill_gradientn() para dar una escala de colores continua (en forma de gradiente) con cuatro colores. Introduce en geom_col() una transparencia de alpha = 0.8
- Solución:
gg <-
ggplot(resumen,
aes(x = str_wrap(region, width = 7),
y = sum_miles, fill = n)) +
geom_col(alpha = 0.8) +
scale_fill_gradientn("Cantidad de rutas",
colours =
c("#6C5B7B", "#C06C84", "#F67280", "#F8B195")) +
labs(caption = caption_chart,
fill = "Nº de rutas",
y = "Suma acumulada de millas",
x = "Región") +
theme(axis.title.x = element_text(face = "bold", size = 13),
axis.title.y = element_text(face = "bold", size = 13),
axis.text.x = element_text(face = "bold", size = 9),
axis.text.y = element_text(face = "bold", size = 9))
gg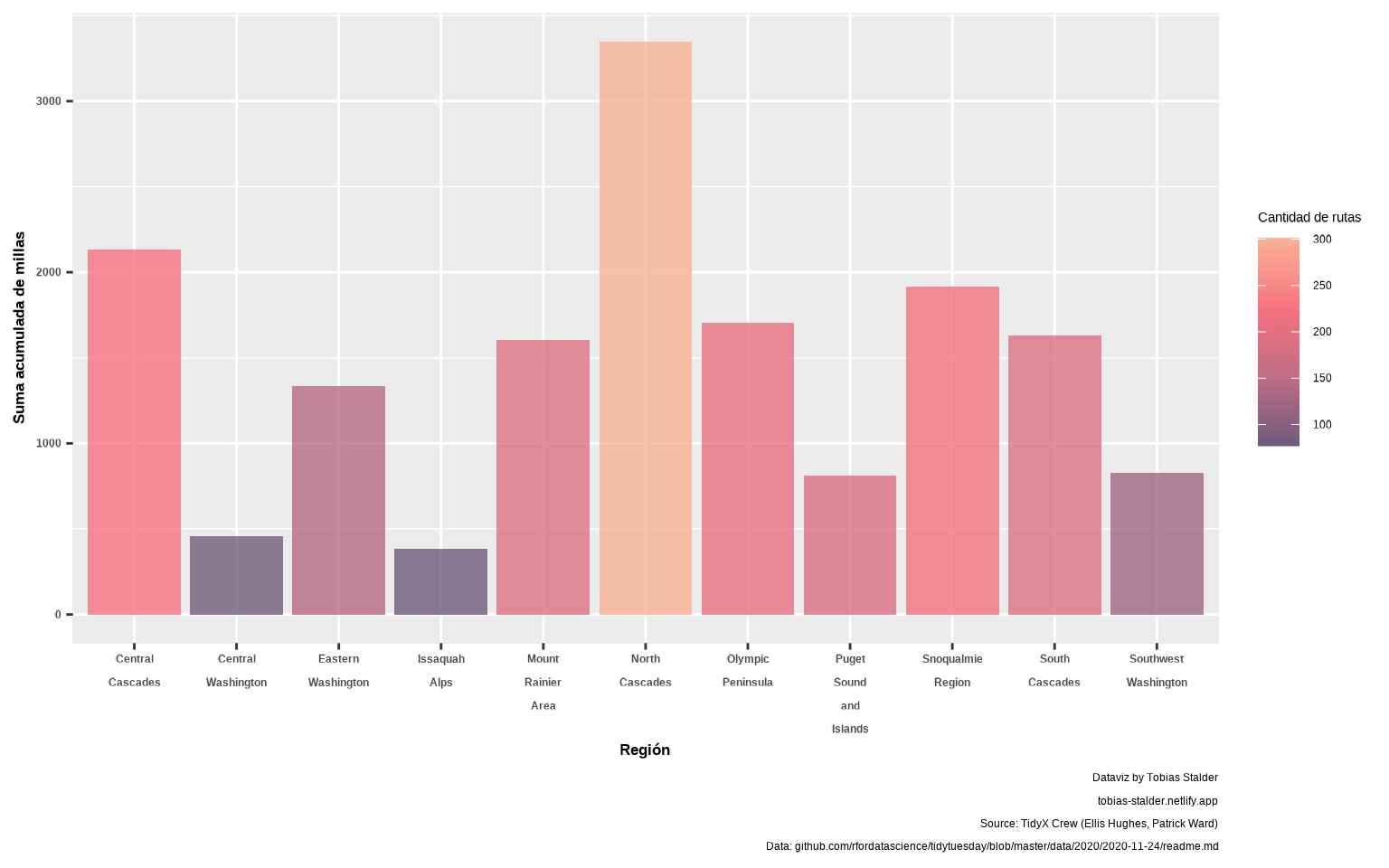
📝Ejercicio 8: usa
geom_point() para añadir al gráfico anterior la media de desnivel de las rutas. Pon por ejemplo size = 3, alpha = 0.85 y color = "gray20".
- Solución:
gg <-
gg +
geom_point(aes(x = str_wrap(region, 7), y = mean_gain),
size = 3, color = "gray20", alpha = 0.85)
gg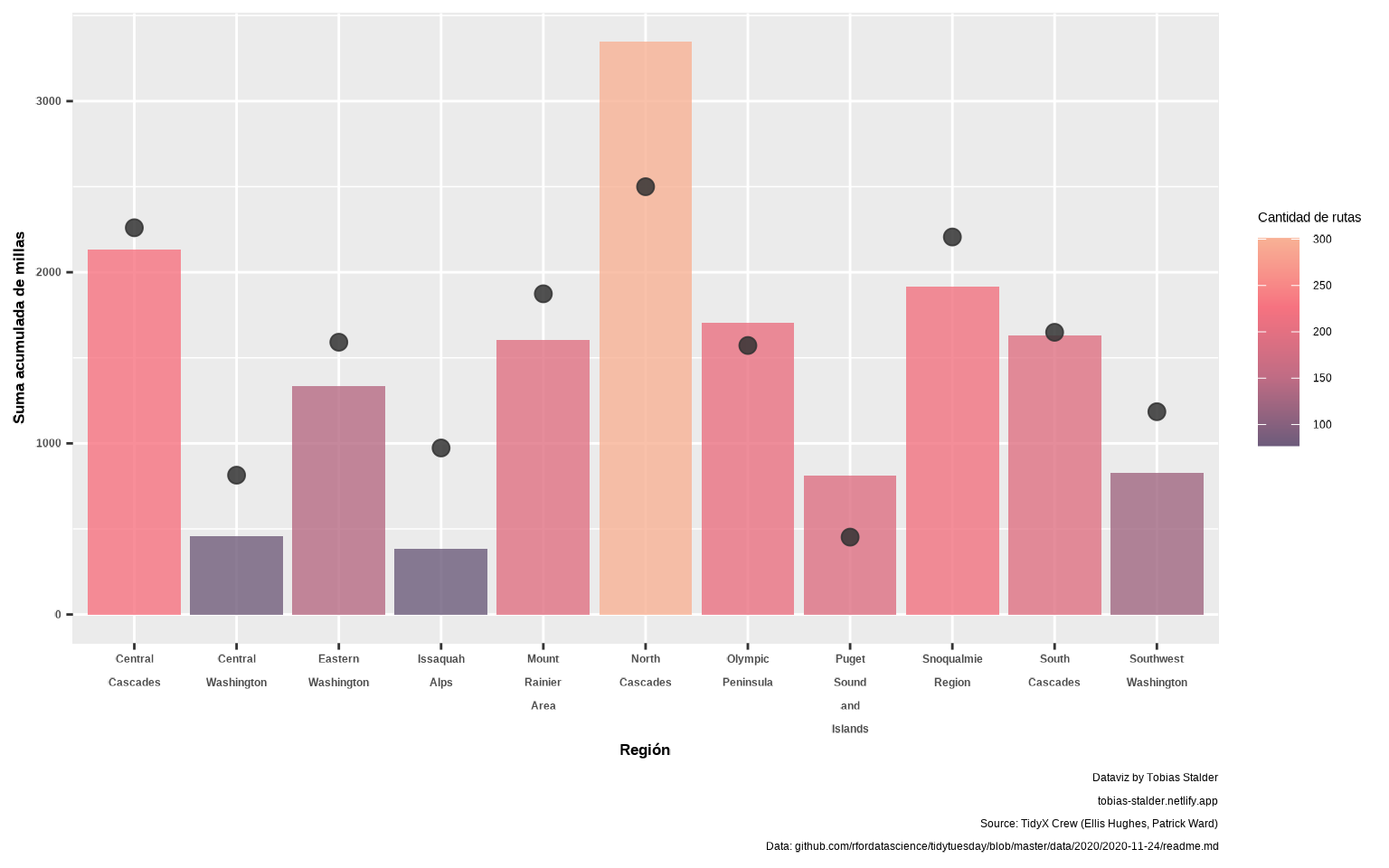
📝Ejercicio 9: usa
coord_polar() para convertir el gráfico anterior a coordenadas polares.
- Solución:
gg <- gg + coord_polar()
gg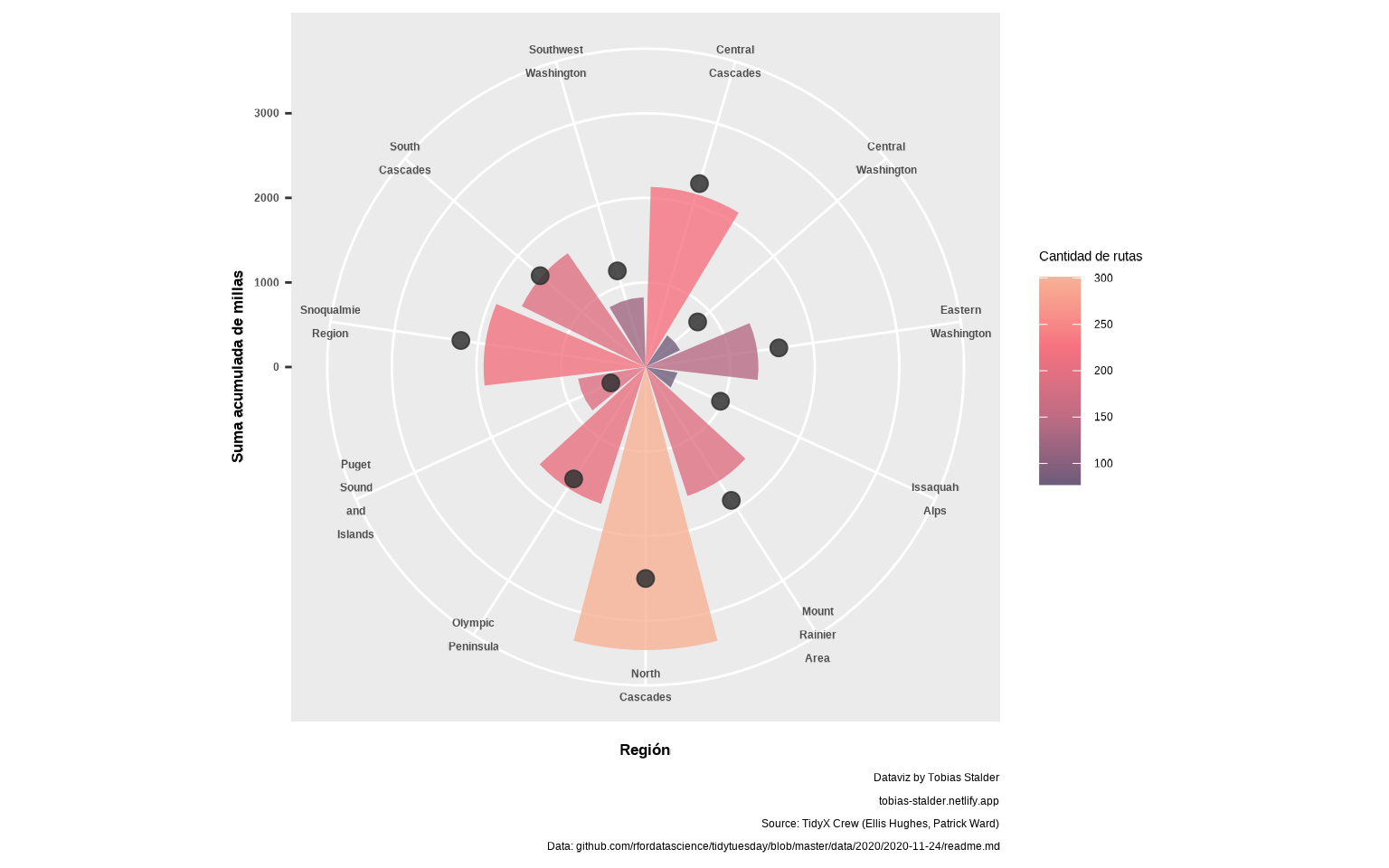
📝Ejercicio 10: usa
geom_segment() para añadir líneas que vayan del centro hacía fuera, pasando por los puntos de desnivel. Hay que pensar que lo tuviésemos en vertical, indicándole la posición inicial x y final xend del segmento (en este caso, para cada región, así que x = str_wrap(region, 7)), y la posición inicial y = 0 e yend un poco más que el máximo de desnivel.
- Solución:
gg <- gg +
geom_segment(aes(x = str_wrap(region, 7), y = 0,
xend = str_wrap(region, 7),
yend = max(mean_gain) * 1.2),
linetype = "dashed", color = "gray20")
gg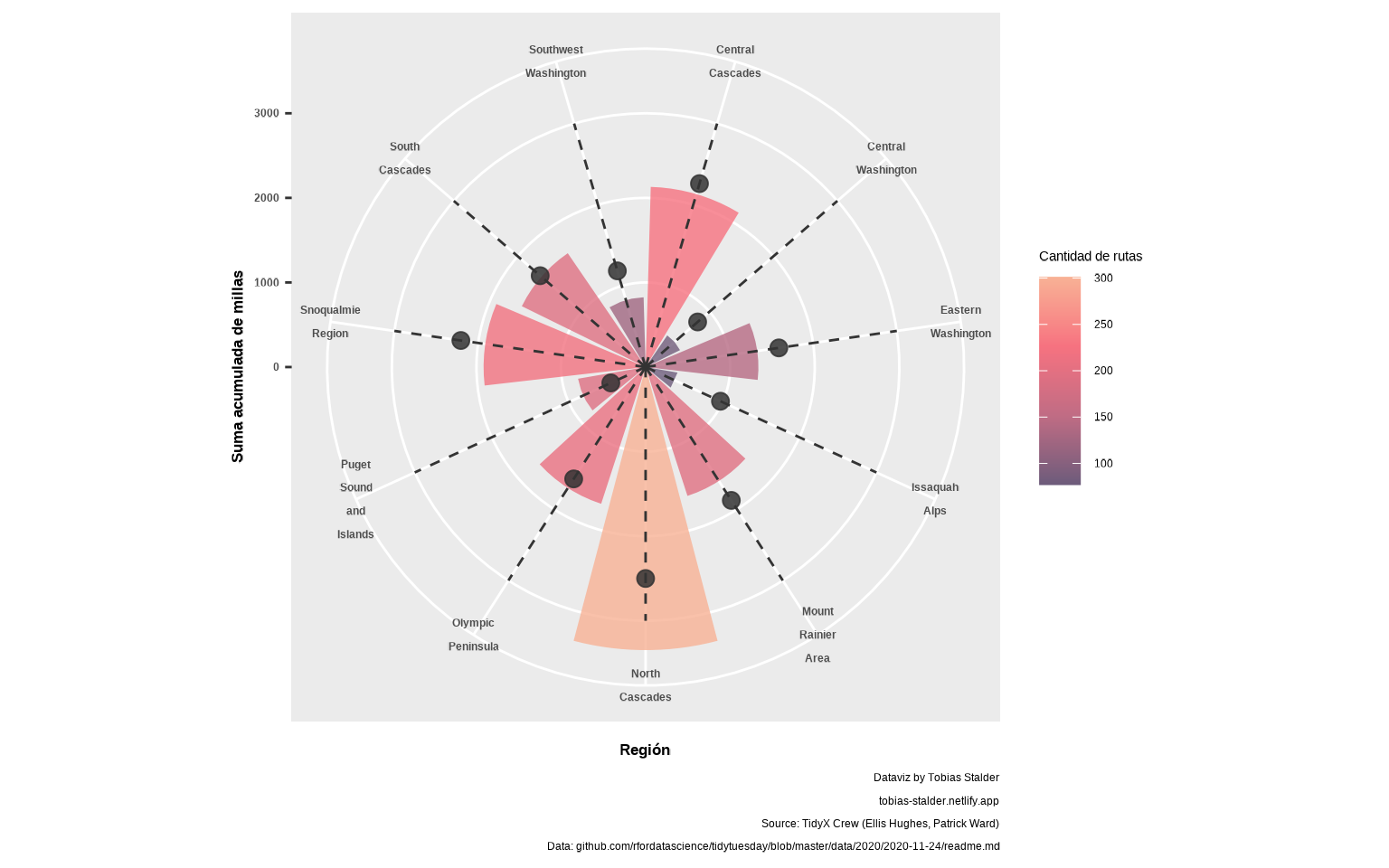
📝Ejercicio 11: ordena los gajos en orden ascendente con
reorder().
- Solución:
gg <-
ggplot(resumen,
aes(x = reorder(str_wrap(region, width = 7), sum_miles),
y = sum_miles, fill = n)) +
geom_col(alpha = 0.8) +
scale_fill_gradientn("Cantidad de rutas",
colours =
c("#6C5B7B", "#C06C84", "#F67280", "#F8B195")) +
labs(caption = caption_chart,
fill = "Nº de rutas",
y = "Suma acumulada de millas",
x = "Región") +
theme(axis.title.x = element_text(face = "bold", size = 10),
axis.title.y = element_text(face = "bold", size = 10),
axis.text.x = element_text(face = "bold", size = 7),
axis.text.y = element_text(face = "bold", size = 7)) +
geom_point(aes(x = reorder(str_wrap(region, 7), sum_miles),
y = mean_gain),
size = 3, color = "gray20", alpha = 0.85) +
coord_polar() +
geom_segment(aes(x = reorder(str_wrap(region, 7), sum_miles),
y = 0,
xend = str_wrap(region, 7),
yend = max(mean_gain) * 1.2),
linetype = "dashed", color = "gray20")
gg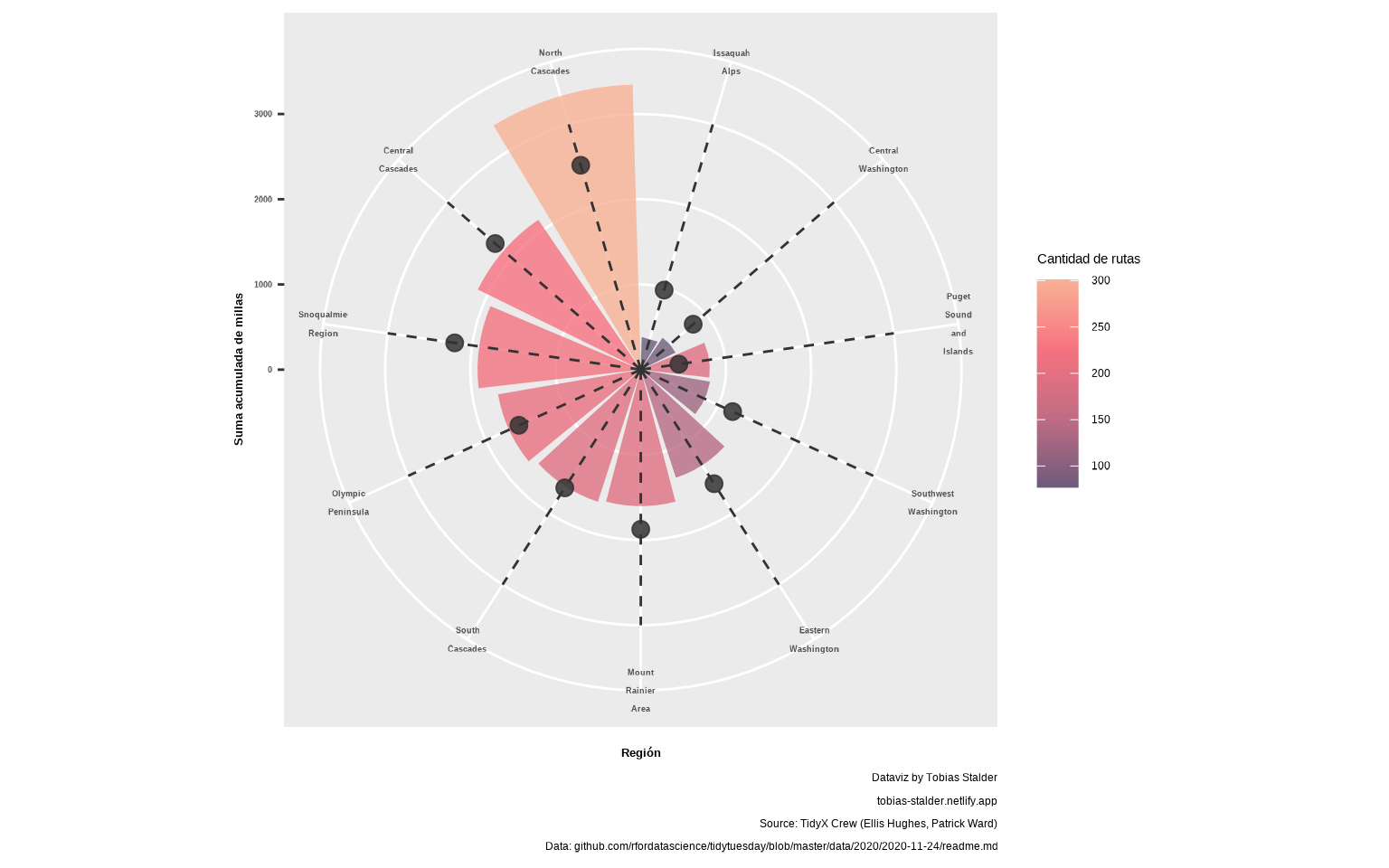
📝Ejercicio 12: con
annotate() añade en uno de los gajos la indicación de que la altura hasta el punto nos indica el desnivel medio. Usaremos además la fuente "Libre Caslon Text", muy similar a la del gráfico original
- Solución:
library(sysfonts)
library(showtext)
font_add_google(family = "Libre Caslon Text",
name = "Libre Caslon Text")
showtext_auto()
gg <- gg +
annotate(x = 11.2, y = 1500, label = "Desnivel medio",
geom = "text", angle = -78, color = "gray20",
size = 2, family = "Libre Caslon Text")
gg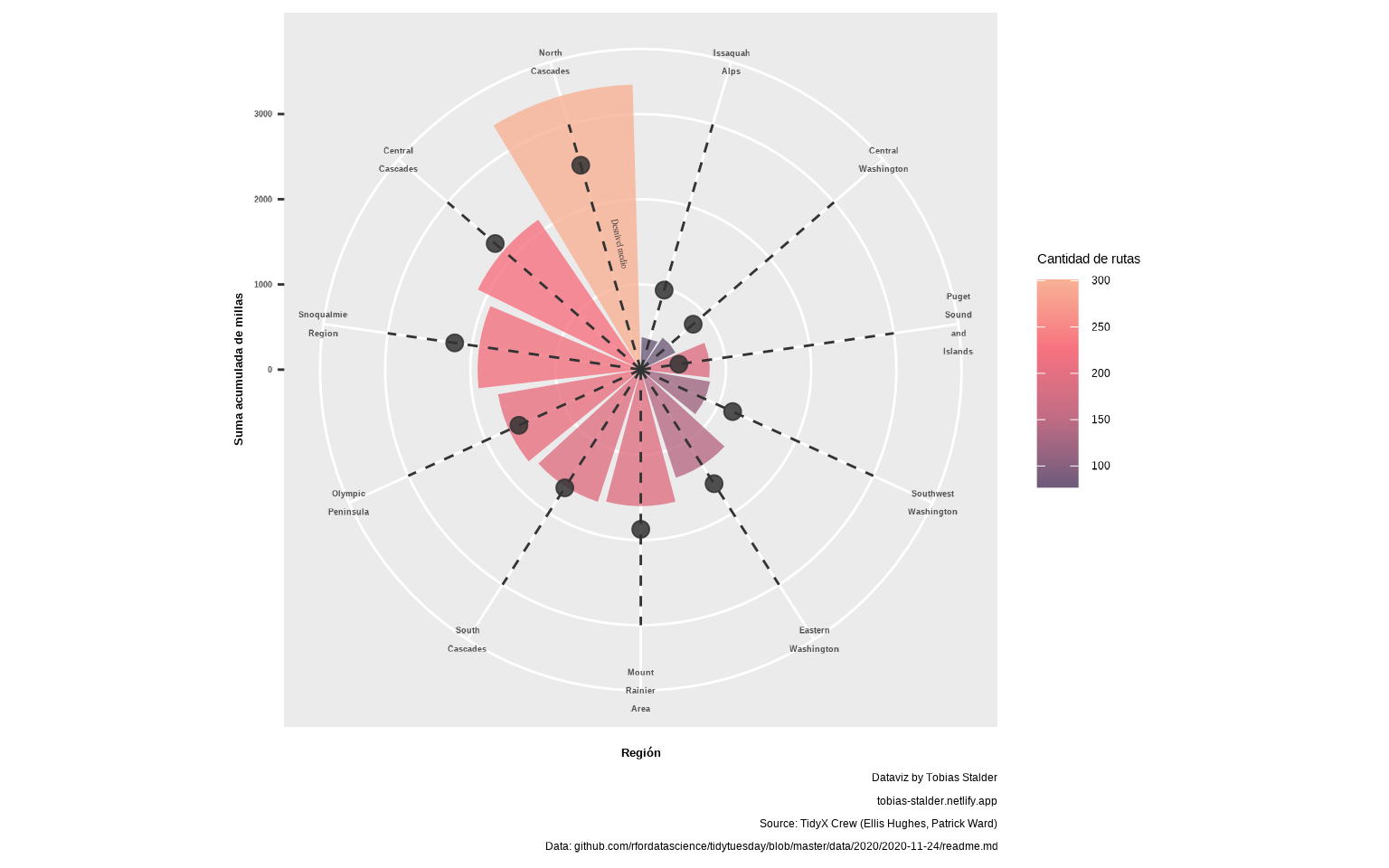
📝Ejercicio 13: con
annotate() añade en uno de los gajos la indicación de que el radio del gajo nos indica la longitud acumulada de las rutas de esa región. Usaremos además la fuente "Libre Caslon Text", muy similar a la del gráfico original
- Solución:
library(sysfonts)
library(showtext)
font_add_google(family = "Libre Caslon Text",
name = "Libre Caslon Text")
showtext_auto()
gg <- gg +
annotate(x = 11, y = 3200, label = "Longitud acum.",
geom = "text", angle = 18, color = "gray20",
size = 2, family = "Libre Caslon Text")
gg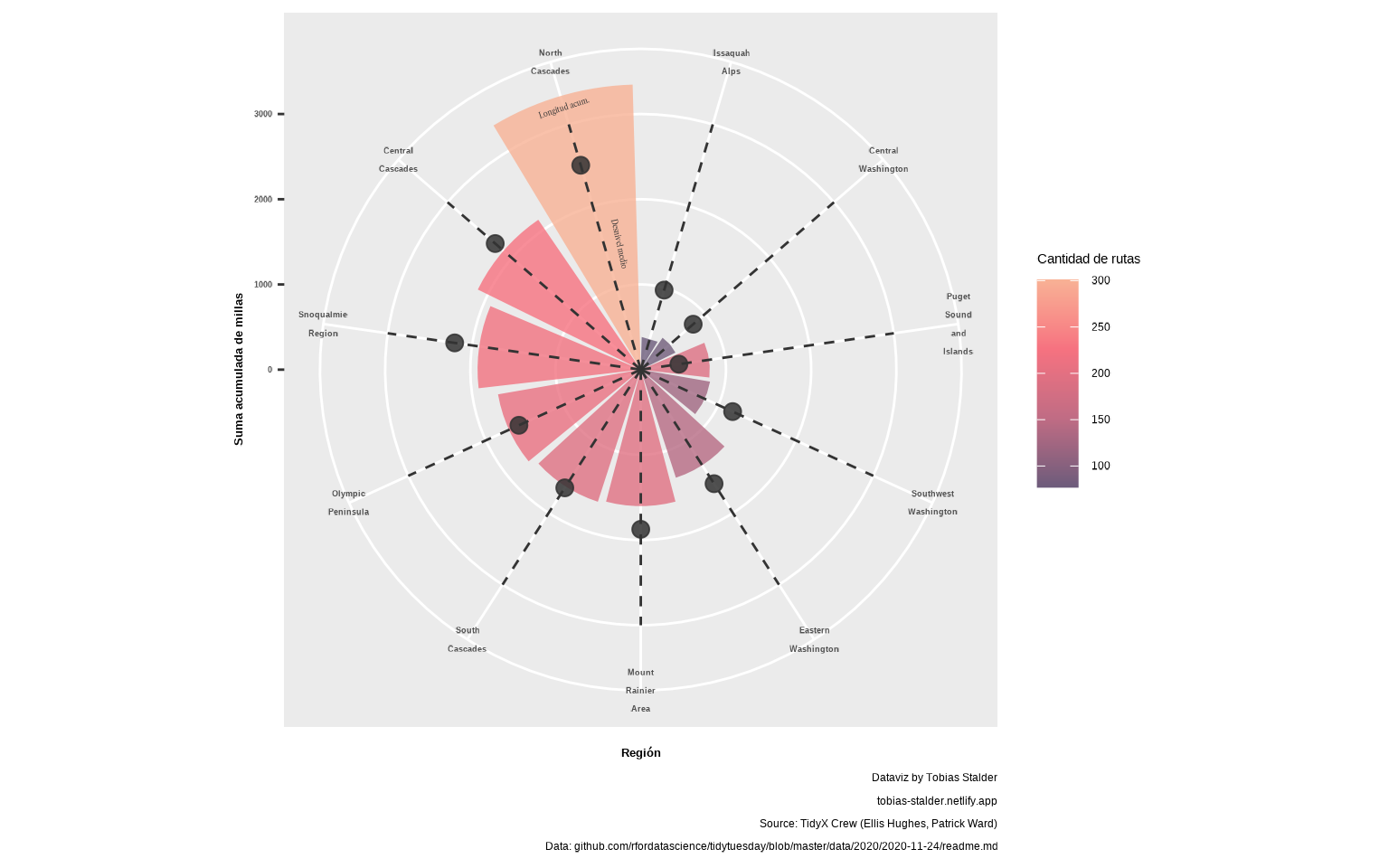
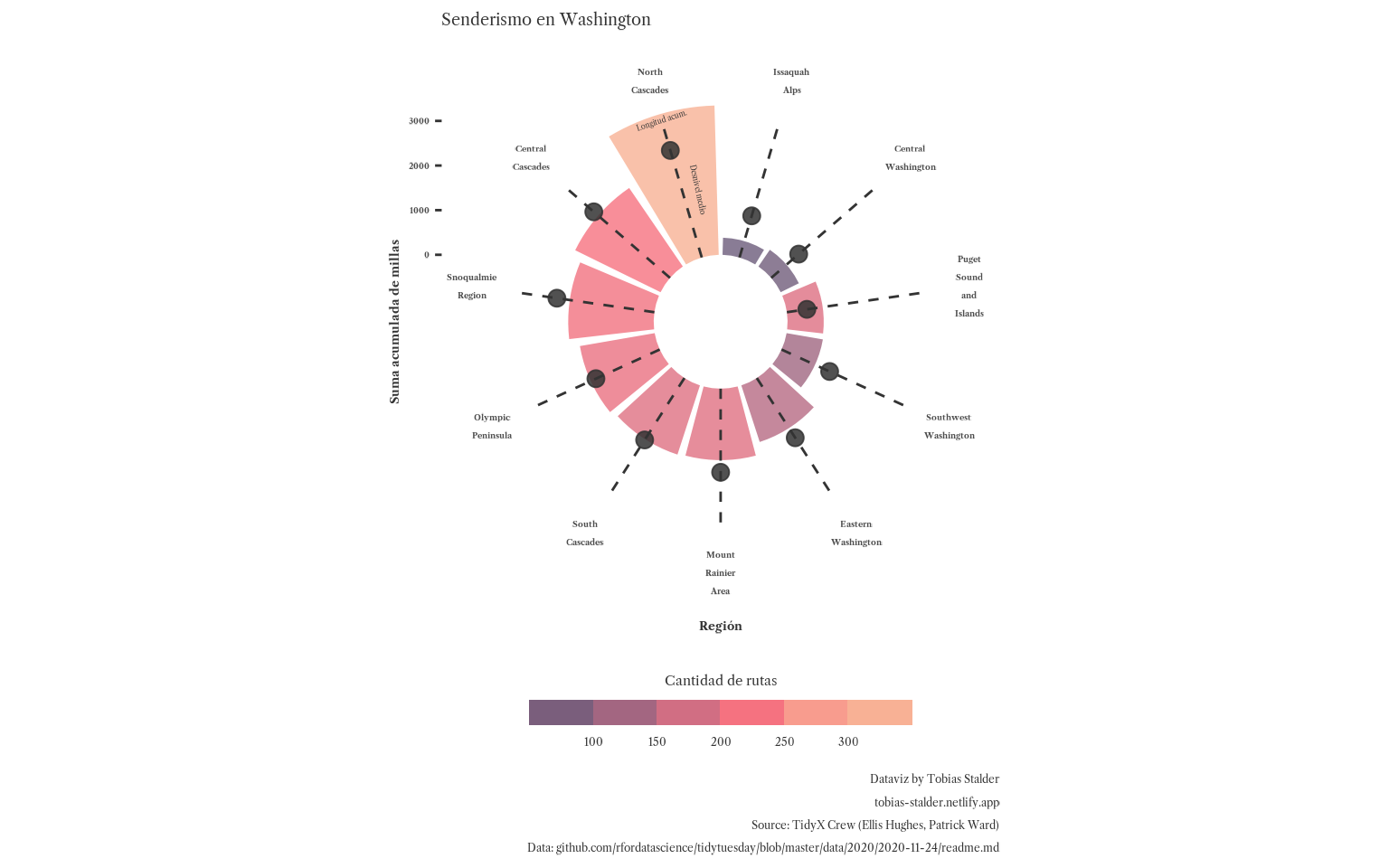
Por último hacemos que los gajos no empiecen del centro, y añadimos algún ajuste estético más (ver el post original)
gg +
scale_y_continuous(limits = c(-1500, 3500),
expand = c(0, 0),
breaks = c(0, 1000, 2000, 3000)) +
# Make the guide for the fill discrete
guides(fill =
guide_colorsteps(barwidth = 11, barheight = 0.7,
title.position = "top",
title.hjust = .5)) +
labs(title = "Senderismo en Washington",
caption = caption_chart) +
theme(text = element_text(color = "gray20",
family = "Libre Caslon Text"),
legend.position = "bottom",
panel.background =
element_rect(fill = "white", color = "white"),
panel.grid = element_blank(),
panel.grid.major.x = element_blank())