Capítulo 15 Mejorando los data.frame: datos tibble
Scripts usados:
- script15.R: datos tibble. Ver en https://github.com/dadosdelaplace/courses-ECI-2022/blob/main/scripts/script15.R
Empieza lo interesante :)
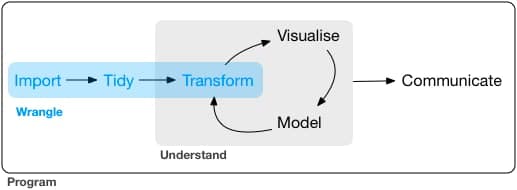
Imagen/gráfica 15.1: Flujo deseable de datos según Hadley Wickham, extraída de https://r4ds.had.co.nz/wrangle-intro.html
Fíjate bien en el anterior flujo de trabajo: vamos a intentar tener unas nociones básicas para preparar los datos, y después veremos distintas formas de importarlos y guardarlos. Antes vamos a repasar los tipos de datos que hemos hasta ahora. ¿Existen más tipos de datos de los que ya conocemos?
La respuesta te la estarás imaginando: sí. De hecho no es solo que existan más, sino que puedes crear tus propios tipos de datos, pero seguramente acabarán siendo, en su nivel más profundo, una combinación de alguna de las estructuras que ya conocemos. El objetivo de este curso es empezar a ser autónomo/a en el análisis de datos, así que (de momento) vamos a quedarnos como estamos.
GLOSARIO:
Si es importante entender las diferencias entre los datos que ya hemos definido.
Vectores: es el tipo de dato más simple, una colección de valores pero del mismo tipo. Los vectores pueden ser de longitud 1 (valores individuales a secas), una colección de números, una colección de cadenas de texto o una colección de valores lógicos (pudiendo tener dentro datos ausentes, o valores especiales como
InfoNaN)Matrices: se pueden entender como una especie de colección de vectores, una colección de colecciones, un tipo de dato bidimensional. Una matriz se conforma de filas y columnas pero, de nuevo, los datos deben ser del mismo tipo y longitud, los vectores concatenados que forma las filas y/o columnas.
data.frame: son datos estructurados, lo que comunmente conocemos como «tablas». A diferencia de las matrices, aunque deben seguir teniendo la misma longitud, las variables que lo conforman pueden ser de tipos diferentes, puediendo tener el mismo conjunto de datos numéricos, caracteres, lógicos, etc.
Listas: las listas son una concatenación de elementos, a secas, de forma que nos permite concatenar cualquier tipo de dato anterior, pudiendo ser de diferente longitud y diferente tipo.
WARNING: cuidado con las listas
Como hemos mencionado, una lista no se puede vectorizar de forma inmediata, por lo cualquier operación aritmética aplicada a una lista dará error. Para poder operar con ellas tenemos una opción que es aplicar la función lapply(), o directamente acudir al paquete purrr (te animo a investigar en dicho paquete).
Antes de preparar nuestros datos, vamos a ver un tipo de dato que quizás hayamos mencionado por encima: las tablas tibble. Los datos en formato tibble (del paquete tibble) son un tipo de data.frame mejorado, para una gestión más ágil, eficiente y coherente. Las tablas en formato tibble (su clase será tbl_df) tienen 4 ventajas principales frente a los ya vistos data.frame:
- Permiten imprimir por consola la tabla con mayor información de las variables, y solo imprime por defecto las primeras filas (todas si son 20 o menos, 10 si son más de 20 filas).
library(tibble)
# data.frame
tabla_df <-
data.frame("x" = 1:50,
"y" = rep(c("a", "b", "c", "d", "e"), 10),
"z" = 11:60,
"logica" = rep(c(TRUE, TRUE, FALSE, TRUE, FALSE), 10))
tabla_df## x y z logica
## 1 1 a 11 TRUE
## 2 2 b 12 TRUE
## 3 3 c 13 FALSE
## 4 4 d 14 TRUE
## 5 5 e 15 FALSE
## 6 6 a 16 TRUE
## 7 7 b 17 TRUE
## 8 8 c 18 FALSE
## 9 9 d 19 TRUE
## 10 10 e 20 FALSE
## 11 11 a 21 TRUE
## 12 12 b 22 TRUE
## 13 13 c 23 FALSE
## 14 14 d 24 TRUE
## 15 15 e 25 FALSE
## 16 16 a 26 TRUE
## 17 17 b 27 TRUE
## 18 18 c 28 FALSE
## 19 19 d 29 TRUE
## 20 20 e 30 FALSE
## 21 21 a 31 TRUE
## 22 22 b 32 TRUE
## 23 23 c 33 FALSE
## 24 24 d 34 TRUE
## 25 25 e 35 FALSE
## 26 26 a 36 TRUE
## 27 27 b 37 TRUE
## 28 28 c 38 FALSE
## 29 29 d 39 TRUE
## 30 30 e 40 FALSE
## 31 31 a 41 TRUE
## 32 32 b 42 TRUE
## 33 33 c 43 FALSE
## 34 34 d 44 TRUE
## 35 35 e 45 FALSE
## 36 36 a 46 TRUE
## 37 37 b 47 TRUE
## 38 38 c 48 FALSE
## 39 39 d 49 TRUE
## 40 40 e 50 FALSE
## 41 41 a 51 TRUE
## 42 42 b 52 TRUE
## 43 43 c 53 FALSE
## 44 44 d 54 TRUE
## 45 45 e 55 FALSE
## 46 46 a 56 TRUE
## 47 47 b 57 TRUE
## 48 48 c 58 FALSE
## 49 49 d 59 TRUE
## 50 50 e 60 FALSE
# tibble
tabla_tb <- tibble("x" = 1:50,
"y" = rep(c("a", "b", "c", "d", "e"), 10),
"z" = 11:60,
"logica" = rep(c(TRUE, TRUE, FALSE, TRUE, FALSE), 10))
tabla_tb## # A tibble: 50 × 4
## x y z logica
## <int> <chr> <int> <lgl>
## 1 1 a 11 TRUE
## 2 2 b 12 TRUE
## 3 3 c 13 FALSE
## 4 4 d 14 TRUE
## 5 5 e 15 FALSE
## 6 6 a 16 TRUE
## 7 7 b 17 TRUE
## 8 8 c 18 FALSE
## 9 9 d 19 TRUE
## 10 10 e 20 FALSE
## # … with 40 more rowsPuedes imprimir las filas y columnas que quieras con print(), pero por defecto te aseguras de no saturar la consola.
print(tabla_tb, n = 13, width = Inf)## # A tibble: 50 × 4
## x y z logica
## <int> <chr> <int> <lgl>
## 1 1 a 11 TRUE
## 2 2 b 12 TRUE
## 3 3 c 13 FALSE
## 4 4 d 14 TRUE
## 5 5 e 15 FALSE
## 6 6 a 16 TRUE
## 7 7 b 17 TRUE
## 8 8 c 18 FALSE
## 9 9 d 19 TRUE
## 10 10 e 20 FALSE
## 11 11 a 21 TRUE
## 12 12 b 22 TRUE
## 13 13 c 23 FALSE
## # … with 37 more rowsMantiene la integridad de los datos (no cambia los tipos de las variables y hace una carga de datos inteligente, interpretando las fechas como tal, por ejemplo).
La función
tibble()construye las variables secuencialmente, pudiendo hacer uso en la propia definición de variables recién definidas en dicha definición.
# data.frame
data.frame("x" = 1:5,
"y" = c("a", "b", "c", "d", "e"),
"z" = 11:15,
"logica" = c(TRUE, TRUE, FALSE, TRUE, FALSE),
"x*z" = x * z)## x y z logica x.z
## 1 1 a 11 TRUE 4
## 2 2 b 12 TRUE 5
## 3 3 c 13 FALSE 3
## 4 4 d 14 TRUE 2
## 5 5 e 15 FALSE 74
# tibble
tibble("x" = 1:5,
"y" = c("a", "b", "c", "d", "e"),
"z" = 11:15,
"logica" = c(TRUE, TRUE, FALSE, TRUE, FALSE),
"x*z" = x * z)## # A tibble: 5 × 5
## x y z logica `x*z`
## <int> <chr> <int> <lgl> <int>
## 1 1 a 11 TRUE 11
## 2 2 b 12 TRUE 24
## 3 3 c 13 FALSE 39
## 4 4 d 14 TRUE 56
## 5 5 e 15 FALSE 75- Si accedes a una columna que no existe avisa con un warning.
# data.frame
tabla_df$variable_inexistente## NULL
# tibble
tabla_tb$variable_inexistente## Warning: Unknown or uninitialised column: `variable_inexistente`.## NULL- No solo no te cambiará el tipo de datos sino que no te cambiará el nombre de las variables (los
data.frametransforma los caracteres que no sean letras).
# data.frame
data.frame(":)" = "emoticono", " " = "en blanco", "2000" = "número")## X.. X. X2000
## 1 emoticono en blanco número
# tibble
tibble(":)" = "emoticono", " " = "en blanco", "2000" = "número")## # A tibble: 1 × 3
## `:)` ` ` `2000`
## <chr> <chr> <chr>
## 1 emoticono en blanco número- Realiza una carga de los datos más ágil
Puedes consultar más funcionalidades de dichos datos en https://tibble.tidyverse.org/ pero están son las principales ventajas.
Una de ellas es la función glimpse(), que nos permite obtener el resumen de columnas (no es para tener un resumen de los datos sino para ver las variables que tenemos y su tipo).
glimpse(tabla_tb)## Rows: 50
## Columns: 4
## $ x <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, …
## $ y <chr> "a", "b", "c", "d", "e", "a", "b", "c", "d", "e", "a", "b", "c"…
## $ z <int> 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26,…
## $ logica <lgl> TRUE, TRUE, FALSE, TRUE, FALSE, TRUE, TRUE, FALSE, TRUE, FALSE,…15.1 Consejos
CONSEJOS
Convertir a tibble
Si ya tienes un data.frame es altamente recomendable convertirlo a tibble con as_tibble() (del paquete dplyr)
## # A tibble: 50 × 4
## x y z logica
## <int> <fct> <int> <lgl>
## 1 1 a 11 TRUE
## 2 2 b 12 TRUE
## 3 3 c 13 FALSE
## 4 4 d 14 TRUE
## 5 5 e 15 FALSE
## 6 6 a 16 TRUE
## 7 7 b 17 TRUE
## 8 8 c 18 FALSE
## 9 9 d 19 TRUE
## 10 10 e 20 FALSE
## # … with 40 more rows
15.2 📝 Ejercicios
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: ¿es el conjunto de datos
airquality (del paquete {datasets}) de tipo tibble?
- Solución:
Recuerda que podemos cargar elementos de un paquete (en este caso {datasets}) cargando library(datasets) y luego el elemento, o bien datasets::airquality (prefijo::nombre).
La respuesta: NO. Tienes muchas formas de comprobarlo si imprimes el conjunto por defecto.
library(datasets)
airquality## Ozone Solar.R Wind Temp Month Day
## 1 41 190 7.4 67 5 1
## 2 36 118 8.0 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6
## 7 23 299 8.6 65 5 7
## 8 19 99 13.8 59 5 8
## 9 8 19 20.1 61 5 9
## 10 NA 194 8.6 69 5 10
## 11 7 NA 6.9 74 5 11
## 12 16 256 9.7 69 5 12
## 13 11 290 9.2 66 5 13
## 14 14 274 10.9 68 5 14
## 15 18 65 13.2 58 5 15
## 16 14 334 11.5 64 5 16
## 17 34 307 12.0 66 5 17
## 18 6 78 18.4 57 5 18
## 19 30 322 11.5 68 5 19
## 20 11 44 9.7 62 5 20
## 21 1 8 9.7 59 5 21
## 22 11 320 16.6 73 5 22
## 23 4 25 9.7 61 5 23
## 24 32 92 12.0 61 5 24
## 25 NA 66 16.6 57 5 25
## 26 NA 266 14.9 58 5 26
## 27 NA NA 8.0 57 5 27
## 28 23 13 12.0 67 5 28
## 29 45 252 14.9 81 5 29
## 30 115 223 5.7 79 5 30
## 31 37 279 7.4 76 5 31
## 32 NA 286 8.6 78 6 1
## 33 NA 287 9.7 74 6 2
## 34 NA 242 16.1 67 6 3
## 35 NA 186 9.2 84 6 4
## 36 NA 220 8.6 85 6 5
## 37 NA 264 14.3 79 6 6
## 38 29 127 9.7 82 6 7
## 39 NA 273 6.9 87 6 8
## 40 71 291 13.8 90 6 9
## 41 39 323 11.5 87 6 10
## 42 NA 259 10.9 93 6 11
## 43 NA 250 9.2 92 6 12
## 44 23 148 8.0 82 6 13
## 45 NA 332 13.8 80 6 14
## 46 NA 322 11.5 79 6 15
## 47 21 191 14.9 77 6 16
## 48 37 284 20.7 72 6 17
## 49 20 37 9.2 65 6 18
## 50 12 120 11.5 73 6 19
## 51 13 137 10.3 76 6 20
## 52 NA 150 6.3 77 6 21
## 53 NA 59 1.7 76 6 22
## 54 NA 91 4.6 76 6 23
## 55 NA 250 6.3 76 6 24
## 56 NA 135 8.0 75 6 25
## 57 NA 127 8.0 78 6 26
## 58 NA 47 10.3 73 6 27
## 59 NA 98 11.5 80 6 28
## 60 NA 31 14.9 77 6 29
## 61 NA 138 8.0 83 6 30
## 62 135 269 4.1 84 7 1
## 63 49 248 9.2 85 7 2
## 64 32 236 9.2 81 7 3
## 65 NA 101 10.9 84 7 4
## 66 64 175 4.6 83 7 5
## 67 40 314 10.9 83 7 6
## 68 77 276 5.1 88 7 7
## 69 97 267 6.3 92 7 8
## 70 97 272 5.7 92 7 9
## 71 85 175 7.4 89 7 10
## 72 NA 139 8.6 82 7 11
## 73 10 264 14.3 73 7 12
## 74 27 175 14.9 81 7 13
## 75 NA 291 14.9 91 7 14
## 76 7 48 14.3 80 7 15
## 77 48 260 6.9 81 7 16
## 78 35 274 10.3 82 7 17
## 79 61 285 6.3 84 7 18
## 80 79 187 5.1 87 7 19
## 81 63 220 11.5 85 7 20
## 82 16 7 6.9 74 7 21
## 83 NA 258 9.7 81 7 22
## 84 NA 295 11.5 82 7 23
## 85 80 294 8.6 86 7 24
## 86 108 223 8.0 85 7 25
## 87 20 81 8.6 82 7 26
## 88 52 82 12.0 86 7 27
## 89 82 213 7.4 88 7 28
## 90 50 275 7.4 86 7 29
## 91 64 253 7.4 83 7 30
## 92 59 254 9.2 81 7 31
## 93 39 83 6.9 81 8 1
## 94 9 24 13.8 81 8 2
## 95 16 77 7.4 82 8 3
## 96 78 NA 6.9 86 8 4
## 97 35 NA 7.4 85 8 5
## 98 66 NA 4.6 87 8 6
## 99 122 255 4.0 89 8 7
## 100 89 229 10.3 90 8 8
## 101 110 207 8.0 90 8 9
## 102 NA 222 8.6 92 8 10
## 103 NA 137 11.5 86 8 11
## 104 44 192 11.5 86 8 12
## 105 28 273 11.5 82 8 13
## 106 65 157 9.7 80 8 14
## 107 NA 64 11.5 79 8 15
## 108 22 71 10.3 77 8 16
## 109 59 51 6.3 79 8 17
## 110 23 115 7.4 76 8 18
## 111 31 244 10.9 78 8 19
## 112 44 190 10.3 78 8 20
## 113 21 259 15.5 77 8 21
## 114 9 36 14.3 72 8 22
## 115 NA 255 12.6 75 8 23
## 116 45 212 9.7 79 8 24
## 117 168 238 3.4 81 8 25
## 118 73 215 8.0 86 8 26
## 119 NA 153 5.7 88 8 27
## 120 76 203 9.7 97 8 28
## 121 118 225 2.3 94 8 29
## 122 84 237 6.3 96 8 30
## 123 85 188 6.3 94 8 31
## 124 96 167 6.9 91 9 1
## 125 78 197 5.1 92 9 2
## 126 73 183 2.8 93 9 3
## 127 91 189 4.6 93 9 4
## 128 47 95 7.4 87 9 5
## 129 32 92 15.5 84 9 6
## 130 20 252 10.9 80 9 7
## 131 23 220 10.3 78 9 8
## 132 21 230 10.9 75 9 9
## 133 24 259 9.7 73 9 10
## 134 44 236 14.9 81 9 11
## 135 21 259 15.5 76 9 12
## 136 28 238 6.3 77 9 13
## 137 9 24 10.9 71 9 14
## 138 13 112 11.5 71 9 15
## 139 46 237 6.9 78 9 16
## 140 18 224 13.8 67 9 17
## 141 13 27 10.3 76 9 18
## 142 24 238 10.3 68 9 19
## 143 16 201 8.0 82 9 20
## 144 13 238 12.6 64 9 21
## 145 23 14 9.2 71 9 22
## 146 36 139 10.3 81 9 23
## 147 7 49 10.3 69 9 24
## 148 14 20 16.6 63 9 25
## 149 30 193 6.9 70 9 26
## 150 NA 145 13.2 77 9 27
## 151 14 191 14.3 75 9 28
## 152 18 131 8.0 76 9 29
## 153 20 223 11.5 68 9 30
class(airquality)## [1] "data.frame"- Imprime por defecto todas las filas (tiene 153 filas, debería imprimir solo 10 si fuese un tibble, para no saturar consola).
- No especifica al imprimir que es de tipo
tibble. - No especifica al imprimir el tipo de dato de las columnas.
- Imprime el nombre de las filas (el nombre de los modelos) como si fuera una variable (¡que no existe!).
📝Ejercicio 2: convierte el conjunto
airquality de data.frame a tibble.
- Solución:
Así debería de salir si fuera tibble.
## # A tibble: 153 × 6
## Ozone Solar.R Wind Temp Month Day
## <int> <int> <dbl> <int> <int> <int>
## 1 41 190 7.4 67 5 1
## 2 36 118 8 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6
## 7 23 299 8.6 65 5 7
## 8 19 99 13.8 59 5 8
## 9 8 19 20.1 61 5 9
## 10 NA 194 8.6 69 5 10
## # … with 143 more rows
class(airquality_tb)## [1] "tbl_df" "tbl" "data.frame"
📝Ejercicio 3: define un
tibble con tres variables numéricas a, b, c, tal que la tercera sea el producto de las dos primeras c = a * b. Inténtalo hacer con un data.frame
- Solución:
Un ejemplo:
tibble("a" = 1:7, "b" = 11:17, "c" = a * b)## # A tibble: 7 × 3
## a b c
## <int> <int> <int>
## 1 1 11 11
## 2 2 12 24
## 3 3 13 39
## 4 4 14 56
## 5 5 15 75
## 6 6 16 96
## 7 7 17 119Si lo intentamos con un data.frame, intentará buscar una variable real que tengamos guardada que se llame a y b, sin encontrarlas.
data.frame("a" = 1:7, "b" = 11:17, "c" = a * b)## a b c
## 1 1 11 -35
## 2 2 12 -35
## 3 3 13 -35
## 4 4 14 -35
## 5 5 15 -35
## 6 6 16 -35
## 7 7 17 -35
📝Ejercicio 4: define un
tibble con tres variables de nombres variable, 2, tercera :), e intenta acceder a ellas.
- Solución:
Las variables solo con caracteres del alfabeto se podrán acceder sin necesidad de comillas.
# Definimos el tibble
datos_tb <- tibble("variable" = 1:7, "tercera falsa :)" = 0,
"2" = 11:17)
# Accedemos a sus columnas
datos_tb$variable## [1] 1 2 3 4 5 6 7
datos_tb$`tercera falsa :)`## [1] 0 0 0 0 0 0 0
datos_tb$`2`## [1] 11 12 13 14 15 16 17También se puede acceder por el orden que ocupan:
datos_tb[1]## # A tibble: 7 × 1
## variable
## <int>
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7
datos_tb[2]## # A tibble: 7 × 1
## `tercera falsa :)`
## <dbl>
## 1 0
## 2 0
## 3 0
## 4 0
## 5 0
## 6 0
## 7 0
datos_tb[3]## # A tibble: 7 × 1
## `2`
## <int>
## 1 11
## 2 12
## 3 13
## 4 14
## 5 15
## 6 16
## 7 17Y también por el nombre entre corchetes (doble corchete extrae la variable fuera del tibble, corchete simple en formato tibble):
datos_tb["variable"]## # A tibble: 7 × 1
## variable
## <int>
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7
datos_tb[["variable"]]## [1] 1 2 3 4 5 6 7
datos_tb["tercera falsa :)"]## # A tibble: 7 × 1
## `tercera falsa :)`
## <dbl>
## 1 0
## 2 0
## 3 0
## 4 0
## 5 0
## 6 0
## 7 0
datos_tb["2"]## # A tibble: 7 × 1
## `2`
## <int>
## 1 11
## 2 12
## 3 13
## 4 14
## 5 15
## 6 16
## 7 17
📝Ejercicio 5: obten de los paquetes dplyr y gapminder los conjuntos de datos tibble
starwars y gapminder. Comprueba el número de variables, de registros e imprime los datos
- Solución:
## # A tibble: 87 × 14
## name height mass hair_color skin_color eye_color birth_year sex gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 Luke S… 172 77 blond fair blue 19 male mascu…
## 2 C-3PO 167 75 <NA> gold yellow 112 none mascu…
## 3 R2-D2 96 32 <NA> white, bl… red 33 none mascu…
## 4 Darth … 202 136 none white yellow 41.9 male mascu…
## 5 Leia O… 150 49 brown light brown 19 fema… femin…
## 6 Owen L… 178 120 brown, grey light blue 52 male mascu…
## 7 Beru W… 165 75 brown light blue 47 fema… femin…
## 8 R5-D4 97 32 <NA> white, red red NA none mascu…
## 9 Biggs … 183 84 black light brown 24 male mascu…
## 10 Obi-Wa… 182 77 auburn, wh… fair blue-gray 57 male mascu…
## # … with 77 more rows, and 5 more variables: homeworld <chr>, species <chr>,
## # films <list>, vehicles <list>, starships <list>
glimpse(starwars) # resumen de columnas## Rows: 87
## Columns: 14
## $ name <chr> "Luke Skywalker", "C-3PO", "R2-D2", "Darth Vader", "Leia Or…
## $ height <int> 172, 167, 96, 202, 150, 178, 165, 97, 183, 182, 188, 180, 2…
## $ mass <dbl> 77.0, 75.0, 32.0, 136.0, 49.0, 120.0, 75.0, 32.0, 84.0, 77.…
## $ hair_color <chr> "blond", NA, NA, "none", "brown", "brown, grey", "brown", N…
## $ skin_color <chr> "fair", "gold", "white, blue", "white", "light", "light", "…
## $ eye_color <chr> "blue", "yellow", "red", "yellow", "brown", "blue", "blue",…
## $ birth_year <dbl> 19.0, 112.0, 33.0, 41.9, 19.0, 52.0, 47.0, NA, 24.0, 57.0, …
## $ sex <chr> "male", "none", "none", "male", "female", "male", "female",…
## $ gender <chr> "masculine", "masculine", "masculine", "masculine", "femini…
## $ homeworld <chr> "Tatooine", "Tatooine", "Naboo", "Tatooine", "Alderaan", "T…
## $ species <chr> "Human", "Droid", "Droid", "Human", "Human", "Human", "Huma…
## $ films <list> <"The Empire Strikes Back", "Revenge of the Sith", "Return…
## $ vehicles <list> <"Snowspeeder", "Imperial Speeder Bike">, <>, <>, <>, "Imp…
## $ starships <list> <"X-wing", "Imperial shuttle">, <>, <>, "TIE Advanced x1",…
dim(starwars) # dimensiones## [1] 87 14## # A tibble: 1,704 × 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
## 4 Afghanistan Asia 1967 34.0 11537966 836.
## 5 Afghanistan Asia 1972 36.1 13079460 740.
## 6 Afghanistan Asia 1977 38.4 14880372 786.
## 7 Afghanistan Asia 1982 39.9 12881816 978.
## 8 Afghanistan Asia 1987 40.8 13867957 852.
## 9 Afghanistan Asia 1992 41.7 16317921 649.
## 10 Afghanistan Asia 1997 41.8 22227415 635.
## # … with 1,694 more rows
glimpse(gapminder) # resumen de columnas## Rows: 1,704
## Columns: 6
## $ country <fct> "Afghanistan", "Afghanistan", "Afghanistan", "Afghanistan", …
## $ continent <fct> Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, …
## $ year <int> 1952, 1957, 1962, 1967, 1972, 1977, 1982, 1987, 1992, 1997, …
## $ lifeExp <dbl> 28.801, 30.332, 31.997, 34.020, 36.088, 38.438, 39.854, 40.8…
## $ pop <int> 8425333, 9240934, 10267083, 11537966, 13079460, 14880372, 12…
## $ gdpPercap <dbl> 779.4453, 820.8530, 853.1007, 836.1971, 739.9811, 786.1134, …
dim(gapminder) # dimensiones## [1] 1704 6