Capítulo 16 Tidy vs messy data: daticos ordenados
Scripts usados:
Tidy datasets are all alike, but every messy dataset is messy in its own way (Hadley Wickham, Chief Scientist en RStudio)
Hasta ahora solo le hemos dado importancia al «qué» pero no al «cómo» manejamos los datos. La organización de nuestros datos es fundamental para que su preparación y explotación sea lo más eficiente posible: la limpieza y preprocesamiento puede llevarnos hasta el 80% del tiempo en nuestro análisis si no se hace forma correcta (Dasu and Johnson 2003).
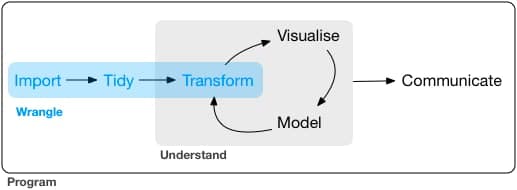
Imagen/gráfica 16.1: Flujo deseable de datos según Hadley Wickham, extraída de https://r4ds.had.co.nz/wrangle-intro.html
El concepto tidy data fue introducido por Hadley Wickham (Wickham 2014) como el primer paso del entorno de paquetes que posteriormente se fueron desarrollando bajo el nombre de tidyverse. Los conjuntos tidy o datos ordenados tienen tres objetivos
- Estandarización en su estructura.
- Sencillez en su manipulación.
- Listos para ser modelizados y visualizados.
Para ello, los datos ordenados o tidy data deben cumplir:
- Cada variable en una columna.
- Cada observación/registro/individuo en una fila diferente.
- Cada celda con un único valor.
- Cada conjunto o unidad observacional conforma una tabla.
- Si contamos con múltiples tablas, debemos tener una columna común en cada una que nos permita cruzarlas.

Imagen/gráfica 16.2: Infografía con datos ordenados (tidy data) extraída de https://r4ds.had.co.nz/tidy-data.html
16.1 Entorno tidyverse
Conocemos ya un formato amable de almacenar los datos como son los data.frame de tipo tibble. Sin embargo muchas veces los datos no los tenemos en el formato deseado, o directamente queremos realizar algunas transformaciones en los mismos, ordenarlos, crear nuevas variables u obtener resúmenes numéricos. Para trabajar con los datos vamos a cargar tidyverse, un entorno de paquetes para el manejo de datos (ver más detalles en Transformando los datos: incursión al universo tidyverse).
install.packages("tidyverse") # SOLO la primera vez
Imagen/gráfica 16.3: Imagen extraída de https://sporella.github.io/datos_espaciales_presentacion/#30
El entorno tidyverse es una de las herramientas más importantes en el manejo de datos en R, una colección de paquetes pensada para el manejo, la exploración, el análisis y la visualización de datos, compartiendo una misma filosofía y gramática.

Imagen/gráfica 16.4: Imagen extraída de https://www.storybench.org/getting-started-with-tidyverse-in-r/
tidyr: para adecuar los datos a tidy data
tibble: mejorando los
data.framepara un manejo más eficientePaquete readr para una carga rápida y eficaz de datos rectangulares (formatos
.csv,.tsv, etc). Paquete readxl para importar archivos.xlsy.xlsx. Paquete haven para importar archivos desde SPSS, Stata y SAS. Paquete httr para importar desde web. Paquete rvest para web scraping.dplyr: una gramática de manipulación de datos para facilitar su procesamiento.
ggplot2: una gramática para la visualización de datos.
Paquete stringr para un manejo sencillo de cadenas de texto. Paquete
{forcast}para un manejo de variables cualitativas (enRconocidas como factores). Paquete purrr para el manejo de listas y una programación funcional con las mismas. Paquete lubridate para el manejo de fechas.
Puedes ver su documentación completa en en https://www.tidyverse.org/.
En este entorno, tendremos un operador clave: el operador pipeline (%>%). Dicho operador lo debemos interpretar como una flecha que une nodos, y nos servirá para concatenar operaciones sobre un conjunto de datos de forma legible. Por ejemplo, si tuviésemos tres funciones first(), second() y third(), la opción más inmediata sería anidar las tres funciones.
El anidamiento es compacto pero dificulta la lectura posterior del código: con el pipeline %>% podremos escribir (y leer) la concetanción de acciones de izquierda a derecha:
Dicho operador viene heredado del paquete magrittr, lo que hace que muchos paquetes de tidyverse dependan de él. Para evitar esta dependencia (cuantos menos paquetes tengamos que cargar, mejor), desde la versión 4.1.0 de R, disponemos de un operador pipeline nativo de R, el operador |> (disponible además fuera del entorno tidyverse. En este manual seguiremos usando el operador %>%, pero es muy probable que en cada vez más códigos que busques por la red observes |> en detrimento de %>% (aunque el primero es más rápido, más eficiente y sin necesidad de cargar otros paquetes).
16.2 Messy data: valores en columnas en lugar de variables
Vamos a visualizar la tabla table4a del paquete tidyr (que ya lo tenemos cargado del entorno tidyverse).
table4a## # A tibble: 3 × 3
## country `1999` `2000`
## * <chr> <int> <int>
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766Si te fijas, tenemos una columna country, representando una variable con el nombre de los países, ¡pero las otras columnas no representan cada una a una sola variable! Ambas son la misma variable, solo que medida en años distintos (que debería ser a su vez otra variable): cada fila está representando dos observaciones (1999, 2000) en lugar de un solo registro. Lo que haremos será incluir una nueva columna llamada year que nos marque el año y otra values que nos diga el valor de la variable de interés en cada uno de esos años.
Con la función pivot_longer del mencionada paquete le indicaremos lo siguiente:
-
cols: el nombre de las columnas que vamos a pivotar (con comillas porque son números, no texto como nombre). -
names_to: el nombre de la columna a la que vamos a mandar los valores que figuran ahora en los nombres de las columnas. -
values_to: el nombre de la columna a la que vamos a mandar los valores.
library(tidyr)
table4a %>% pivot_longer(cols = c("1999", "2000"),
names_to = "year",
values_to = "values")## # A tibble: 6 × 3
## country year values
## <chr> <chr> <int>
## 1 Afghanistan 1999 745
## 2 Afghanistan 2000 2666
## 3 Brazil 1999 37737
## 4 Brazil 2000 80488
## 5 China 1999 212258
## 6 China 2000 213766Ahora tenemos un registro por fila, una variable por columna y cada celda representa un único valor. Este ejemplo de messy data lo podemos encontrar muy a menudo cuando construimos rangos de variables pensando que es mejor tener una tabla más compacta (alargar la tabla a lo ancho en lugar de a lo largo). Es el caso de la tabla relig_income.
relig_income## # A tibble: 18 × 11
## religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` `$75-100k`
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Agnostic 27 34 60 81 76 137 122
## 2 Atheist 12 27 37 52 35 70 73
## 3 Buddhist 27 21 30 34 33 58 62
## 4 Catholic 418 617 732 670 638 1116 949
## 5 Don’t k… 15 14 15 11 10 35 21
## 6 Evangel… 575 869 1064 982 881 1486 949
## 7 Hindu 1 9 7 9 11 34 47
## 8 Histori… 228 244 236 238 197 223 131
## 9 Jehovah… 20 27 24 24 21 30 15
## 10 Jewish 19 19 25 25 30 95 69
## 11 Mainlin… 289 495 619 655 651 1107 939
## 12 Mormon 29 40 48 51 56 112 85
## 13 Muslim 6 7 9 10 9 23 16
## 14 Orthodox 13 17 23 32 32 47 38
## 15 Other C… 9 7 11 13 13 14 18
## 16 Other F… 20 33 40 46 49 63 46
## 17 Other W… 5 2 3 4 2 7 3
## 18 Unaffil… 217 299 374 365 341 528 407
## # … with 3 more variables: $100-150k <dbl>, >150k <dbl>,
## # Don't know/refused <dbl>Salvo la primera, el resto de columnas tienen como nombre los valores de una variable en sí misma (ingresos). Para ordenar los datos vamos a razonar de la misma manera solo que ahora, en lugar de indicarle el nombre de todas las columnas que queremos usar de entrada, vamos a indicarle de forma más corta la columna que NO queremos seleccionar.
# No necesitamos las comillas en el nombre de columnas salvo que tengan caracteres que no sean letras
relig_income %>% pivot_longer(-religion, names_to = "ingresos",
values_to = "frecuencia")## # A tibble: 180 × 3
## religion ingresos frecuencia
## <chr> <chr> <dbl>
## 1 Agnostic <$10k 27
## 2 Agnostic $10-20k 34
## 3 Agnostic $20-30k 60
## 4 Agnostic $30-40k 81
## 5 Agnostic $40-50k 76
## 6 Agnostic $50-75k 137
## 7 Agnostic $75-100k 122
## 8 Agnostic $100-150k 109
## 9 Agnostic >150k 84
## 10 Agnostic Don't know/refused 96
## # … with 170 more rowsLo que hacemos con pivot_longer() es «ampliar» la tabla, haciéndola más larga (más filas) pero con menos columnas.
16.3 Messy data: una observación guardada en varias filas
Vamos a visualizar ahora la tabla table2 del paquete tidyr.
table2## # A tibble: 12 × 4
## country year type count
## <chr> <int> <chr> <int>
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583Fíjate en las cuatro primeras filas: los registros con el mismo año deberían ser el mismo, es la misma información, debería estar en la misma fila, pero está dividada en dos. Por un lado una fila para la variable cases y otra para population. Lo que haremos será lo opuesto a antes: con pivot_wider() «ampliaremos» la tabla a lo ancho, haciéndola menos (menos filas) pero con más columnas.
-
names_from: el nombre de la columna de la que vamos a sacar las nuevas columnas que vamos a crear (casesypopulation). -
values_from: el nombre de la columna de la que vamos a sacar los valores.
table2 %>% pivot_wider(names_from = type, values_from = count)## # A tibble: 6 × 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Ahora tenemos cada registro en una fila, que nos indica país-año-casos-población.
16.4 Messy data: una celda con múltiples valores
Por último vamos a visualizar la tabla table3 del paquete tidyr.
table3## # A tibble: 6 × 3
## country year rate
## * <chr> <int> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583En la variable rate hay guardados dos valores, separados por /, lo que hace que en una celda no tiene un único valor sino dos. La función separate() del paquete tidyr nos permitirá separar los múltiples valores de la columnarate simplemente indicándole el nombre de las nuevas columnas en el argumento into = ..., creando una nueva columna para cada uno de ellos.
## # A tibble: 6 × 4
## country year cases population
## <chr> <int> <chr> <chr>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Por defecto lo que hace es localizar como separador cualquier caracter que no sea alfa-numérico. Si queremos un caracter concreto para dividir podemos indicárselo explícitamente
## # A tibble: 6 × 4
## country year cases population
## <chr> <int> <chr> <chr>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Si usas un separador que no está en los datos te devolverá dichas columnas vacías ya que no ha podido dividirlas.
## Warning: Expected 2 pieces. Additional pieces discarded in 6 rows [1, 2, 3, 4,
## 5, 6].## # A tibble: 6 × 4
## country year cases population
## <chr> <int> <chr> <chr>
## 1 Afghanistan 1999 "" ""
## 2 Afghanistan 2000 "" ""
## 3 Brazil 1999 "" ""
## 4 Brazil 2000 "" ""
## 5 China 1999 "" ""
## 6 China 2000 "" ""De la misma manera que podemos separar columnas también podemos unirlas. Para ello vamos a usar la tabla table5 del ya mencionado paquete. Con la función unite() vamos a unir el siglo (en century) y el año (en year), y al inicio le indicaremos como se llamará la nueva variable (año_completo).
table5 %>% unite(año_completo, century, year)## # A tibble: 6 × 3
## country año_completo rate
## <chr> <chr> <chr>
## 1 Afghanistan 19_99 745/19987071
## 2 Afghanistan 20_00 2666/20595360
## 3 Brazil 19_99 37737/172006362
## 4 Brazil 20_00 80488/174504898
## 5 China 19_99 212258/1272915272
## 6 China 20_00 213766/1280428583Como pasaba en separate(), tiene un argumento de separador por defecto, en este caso sep = "_". Si queremos cambiarlo podemos hacerlo indicándoselo explícitamente.
table5 %>%
unite(año_completo, century, year, sep = "")## # A tibble: 6 × 3
## country año_completo rate
## <chr> <chr> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/128042858316.5 Consejos
CONSEJOS
Convertir variables al procesar
Una opción muy útil que podemos usar al aplicar la separación de los múltiples valores es convertir los datos al tipo adecuado. Los datos unidos en rate eran caracteres ya que tenía el separador / (no podían ser numéricos). Al separarlos, por defecto, aunque ahora ya son solo números, los separa como si fueran textos. Con convert = TRUE podemos indicarle que identifique el tipo de dato y lo convierta (fíjate en la cabecera de las columnas ahora).
## # A tibble: 6 × 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Dicha función también puede ser usada para dividir cifras, como por ejemplo el año
## # A tibble: 6 × 4
## country siglo año rate
## <chr> <chr> <chr> <chr>
## 1 Afghanistan 19 99 745/19987071
## 2 Afghanistan 20 00 2666/20595360
## 3 Brazil 19 99 37737/172006362
## 4 Brazil 20 00 80488/174504898
## 5 China 19 99 212258/1272915272
## 6 China 20 00 213766/128042858316.6 📝 Ejercicios
(haz click en las flechas para ver soluciones)
📝Ejercicio 1: convierte en tidy data el siguiente
data.frame.
- Solución:
El problema es que las dos columnas con nombres de año son en realidad valores que deberían pasar a ser variables, así que deberíamos disminuir aplicar pivot_longer()
# Aplicamos pivot_longer
tabla_tb %>% pivot_longer(cols = c("2020", "2021"),
names_to = "año", values_to = "valores")## # A tibble: 6 × 3
## trimestre año valores
## <chr> <chr> <dbl>
## 1 T1 2020 10
## 2 T1 2021 8
## 3 T2 2020 12
## 4 T2 2021 0
## 5 T3 2020 7.5
## 6 T3 2021 9
📝Ejercicio 2: convierte en tidy data el siguiente
data.frame.
tabla_tb <- tibble("año" = c(2019, 2019, 2020, 2020, 2021, 2021),
"variable" = c("A", "B", "A", "B", "A", "B"),
"valor" = c(10, 9383, 7.58, 10839, 9, 32949))- Solución:
El problema es que las filas que comparten año son el mismo registro (pero con dos características que tenemos divididas en dos filas), así que deberíamos disminuir aplicar pivot_wider()
# Aplicamos pivot_wider
tabla_tb %>% pivot_wider(names_from = "variable", values_from = "valor")## # A tibble: 3 × 3
## año A B
## <dbl> <dbl> <dbl>
## 1 2019 10 9383
## 2 2020 7.58 10839
## 3 2021 9 32949
📝Ejercicio 3: convierte en tidy data la tabla
table5 del paquete tidyr.
- Solución:
Primero uniremos el siglo y las dos últimas cifras del año para obtener el año completo (guardado en año)
table5 %>%
unite(año, century, year, sep = "")## # A tibble: 6 × 3
## country año rate
## <chr> <chr> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583Tras ello deberemos separar el valor del ratio en denominador y numerador (ya que ahora hay dos valores en una celda), y convertiremos el tipo de dato en la salida para que sea número.
table5 %>%
unite(año, century, year, sep = "") %>%
separate(rate, c("numerador", "denominador"), convert = TRUE)## # A tibble: 6 × 4
## country año numerador denominador
## <chr> <chr> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583